processing data
获取有效数据
-
Scikit-learn will not accept categorical features by default
API里面不知使用默认的特征变量名,因此需要编码
这里我还是有疑问?
对于下载的数据集,一般的特征变量名,在进行分类的时候,机器是不能识别的,需要对特征名进行编码,因为计算机是二进制语言啊? -
Need to encode categorical features numerically
-
Convert to ‘dummy variables’
- 0: Observation was NOT that category
- 1: Observation was that category
Dealing with categorical features in Python
两种方式是一样的
- scikit-learn: OneHotEncoder()
- pandas: get_dummies()
pd.get_dummies
- 离散特征编码
- 可用来表示分类变量、非数量因素可能产生的影响
pandas加入虚拟变量的方式
get_dummies 是利用pandas实现one hot encode的方式。详细参数请查看官方文档
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False)[source]
- data 要处理的DataFrame
- prefix 列名的前缀,在多个列有相同的离散项时候使用
- prefix_sep 前缀和离散值的分隔符,默认为下划线,默认即可
- dummy_na 是否把NA值,作为一个离散值进行处理,默认为不处理
- columns 要处理的列名,如果不指定该列,那么默认处理所有列
- drop_first 是否从备选项中删除第一个,建模的时候为避免共线性使用
Pandas中的get_dummy()函数是将拥有不同值的变量转换为0/1数值。
举例说明:一群样本的年龄分别为19,32,56,94岁,19岁用1表示,32岁用2表示,56岁用3表示,94岁用4表示。1,2,3,4这些数值的大小本身没有意义,只是用来区分年龄。因此在实际问题中,需要将1,2,3,4转化为0/1,即如果是19岁,则为0,若不是则为1,以此类推。
- 举个例子
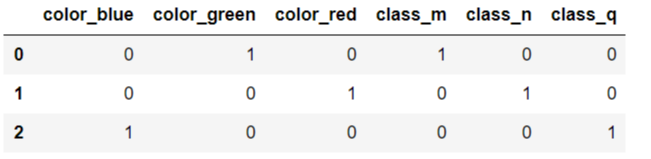
import pandas as pd
df = pd.DataFrame([
['green' , 'm'],
['red' , 'n'],
['blue' , 'q']])
df.columns = ['color', 'class']
pd.get_dummies(df)
# Create dummy variables: df_region
df_region = pd.get_dummies(df)
# Print the columns of df_region
print(df_region.columns)
# Drop 'Region_America' from df_region
df_region = pd.get_dummies(df, drop_first=True)
# Print the new columns of df_region
print(df_region)
处理缺失数据
Imputer()
- 填补缺失值:
sklearn.preprocessing.Imputer(missing_values=’NaN’, strategy=’mean’, axis=0, verbose=0, copy=True)
主要参数说明:
-
missing_values:缺失值,可以为整数或NaN(缺失值numpy.nan用字符串‘NaN’表示),默认为NaN
-
strategy:替换策略,字符串,默认用均值‘mean’替换
- 若为mean时,用特征列的均值替换
- 若为median时,用特征列的中位数替换
- 若为most_frequent时,用特征列的众数替换
-
axis:指定轴数,默认axis=0代表列,axis=1代表行
-
copy:设置为True代表不在原数据集上修改,设置为False时,就地修改,存在如下情况时,即使设置为False时,也不会就地修改
- X不是浮点值数组
- X是稀疏且missing_values=0
- axis=0且X为CRS矩阵
- axis=1且X为CSC矩阵
-
statistics_属性:axis设置为0时,每个特征的填充值数组,axis=1时,报没有该属性错误
参考
# Import the Imputer module
from sklearn.preprocessing import Imputer
from sklearn.svm import SVC
# Setup the Imputation transformer: imp
imp = Imputer(missing_values='NaN', strategy='most_frequent', axis=0)
# Instantiate the SVC classifier: clf
clf = SVC()
# Setup the pipeline with the required steps: steps
steps = [('imputation', imp),
('SVM', clf)]
dropna()
直接删除缺失值
pipline
官方文档
连接多个转换器和预测器在一起,形成一个机器学习工作流,这句解释太官方了,因此我没懂😢
The purpose of the pipeline is to assemble several steps that can be cross-validated together while setting different parameters.
class sklearn.pipeline.Pipeline(steps,memory = None,verbose = False )
参数说明
- step:slist
List of (name, transform) tuples (implementing fit/transform) that are chained, in the order in which they are chained, with the last object an estimator.
参数steps是一个list,list里面是一个个(name,transform)格式的tuple。最后一个tuple是估计函数(就是我们训练的模型类型)。而前面的tuple就是交叉验证的步骤 - Pipeline of transforms with a final estimator.
- 依次应用变换列表和最终估计量。管道的中间步骤必须是“transforms”,即它们必须实现fit和transform方法。最终的估计器只需要实现拟合。可以使用内存参数缓存管道中的转换器。
😢
没太懂
**看了一个小demo,突然就明白了,pipline稍微有点类似于R里面的%>%,层层嵌套
#coding=gbk
#sklearn 中pipeline管道机制的使用
demo
'''
流水线的功能:
跟踪记录各步骤的操作(以方便地重现实验结果)
对各步骤进行一个封装
确保代码的复杂程度不至于超出掌控范围
'''
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelEncoder
data = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/'
'breast-cancer-wisconsin/wdbc.data', header=None)
print(data.shape)
x, y = data.values[:,2:],data.values[:,1]
encoder = LabelEncoder()
y= encoder.fit_transform(y) #将 标签 'm', 'b' 转换成1,0
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size= 0.2,random_state= 666)
from sklearn.preprocessing import StandardScaler #规范化,使各特征的均值为1,方差为0
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
使用pipeline管道机制
数据处理:标准化->主成分分析->逻辑回归
每一步处理都会进行fit和transform,
from sklearn.pipeline import Pipeline
pipe = Pipeline([('sc',StandardScaler()),
('pca',PCA(n_components=2)),
('clf',LogisticRegression(random_state=666)) #设置随机种子,使测试结果复现
])
因此,最后只需要拟合训练集即可
pipe.fit(x_train, y_train)
print('Test accuracy is %.3f' % pipe.score(x_test, y_test))
Test accuracy is 0.921
- Python的sklearn.pipeline.Pipeline()函数可以把多个“处理数据的节点”按顺序打包在一起,数据在前一个节点处理之后的结果,转到下一个节点处理。除了最后一个节点外,其他节点都必须实现'fit()'和'transform()'方法, 最后一个节点需要实现fit()方法即可。当训练样本数据送进Pipeline进行处理时, 它会逐个调用节点的fit()和transform()方法,然后点用最后一个节点的fit()方法来拟合数据。
### 结合Imputer使用
```python
# Import necessary modules
from sklearn.preprocessing import Imputer
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
# Setup the pipeline steps: steps
steps = [('imputation', Imputer(missing_values='NaN', strategy='most_frequent', axis=0)),
('SVM', SVC())]
# Create the pipeline: pipeline
pipeline = Pipeline(steps)
# Create training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Fit the pipeline to the train set
pipeline.fit(X_train, y_train)
# Predict the labels of the test set
y_pred = pipeline.predict(X_test)
# Compute metrics
print(classification_report(y_test, y_pred))
<script.py> output:
precision recall f1-score support
democrat 0.99 0.96 0.98 85
republican 0.94 0.98 0.96 46
avg / total 0.97 0.97 0.97 131
make_pipline()
- 通过make_pipeline函数实现:它是Pipeline类的简单实现,只需传入每个step的类实例即可,不需自己命名,自动将类的小写设为该step的名
结合GridsearchCV使用
进行超参数搜索
# Setup the pipeline
steps = [('scaler', StandardScaler()),
('SVM', SVC())]
pipeline = Pipeline(steps)
# Specify the hyperparameter space
parameters = {'SVM__C':[1, 10, 100],
'SVM__gamma':[0.1, 0.01]}
# Create train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=21)
# Instantiate the GridSearchCV object: cv
cv = GridSearchCV(pipeline, parameters)
# Fit to the training set
cv.fit(X_train, y_train)
# Predict the labels of the test set: y_pred
y_pred = cv.predict(X_test)
# Compute and print metrics
print("Accuracy: {}".format(cv.score(X_test, y_test)))
print(classification_report(y_test, y_pred))
print("Tuned Model Parameters: {}".format(cv.best_params_))
<script.py> output:
Accuracy: 0.7795918367346939
precision recall f1-score support
False 0.83 0.85 0.84 662
True 0.67 0.63 0.65 318
avg / total 0.78 0.78 0.78 980
Tuned Model Parameters: {'SVM__C': 10, 'SVM__gamma': 0.1}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号