Base系列编码(基于RFC4648)
Base编码简介
Base系列更多的作用是使用可打印的字符进来表示给定的二进制字符串,Base编码可以用于在邮件等处传输图片等多媒体信息等场景。

以最简单的Base16为例,对于任意8位二进制字符,都可以使用两个十六进制字母进行表示:

Base编码与密码
在许多项目内(尤其是历史项目中),常见很多人将密码等字段使用Base编码后存入数据库,这种做法可以让人无法单凭肉眼看到用户的密码,但实际上和明文没有太多差别,这在RFC文档中也有明确指明。

虽然可以通过直接自定义码表实现类似替换密码的效果,但这与直接求出值后再进行加密的效果是一样的,从解耦的角度来不适宜在Base编码过程中进加密过程耦合。
Base编码的工作思路
所有的Base系列算法都遵循相同的工作模式,类似于分组密码算法的ECB模式(顺便一提,不影响后文),这里以Base64为例,为了方便说明,这里把输入的字符定为全1,也就是\xFF字符串:
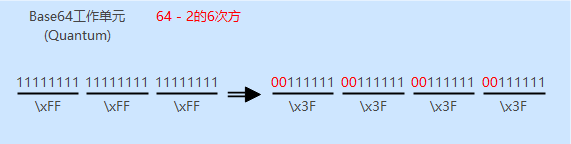
工作单元(Quantum)
首先,Base字符集是原字符集的子集,因此Base编码后字符串长度将膨胀,Base16指的是把8位二进制转换为由4位二进制组成的编码(恰好是十六进制);Base32是把8位转换为5位(2的5次方为32);Base64是把8位转换为6位,如下图所示:
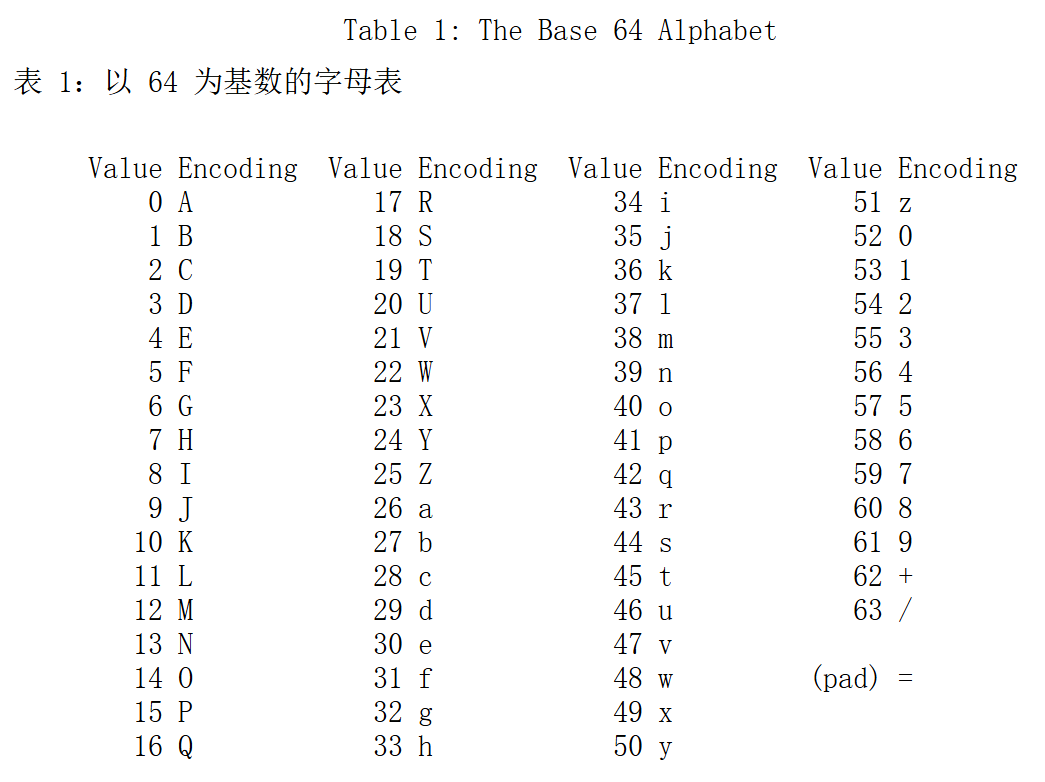
码表
转换后的值目前还不是可打印字符,因此还需要进行查表,这里RFC文档中有给出两种表,实际应用过程中,不同的组织可能还根据自己的情况定义新的码表

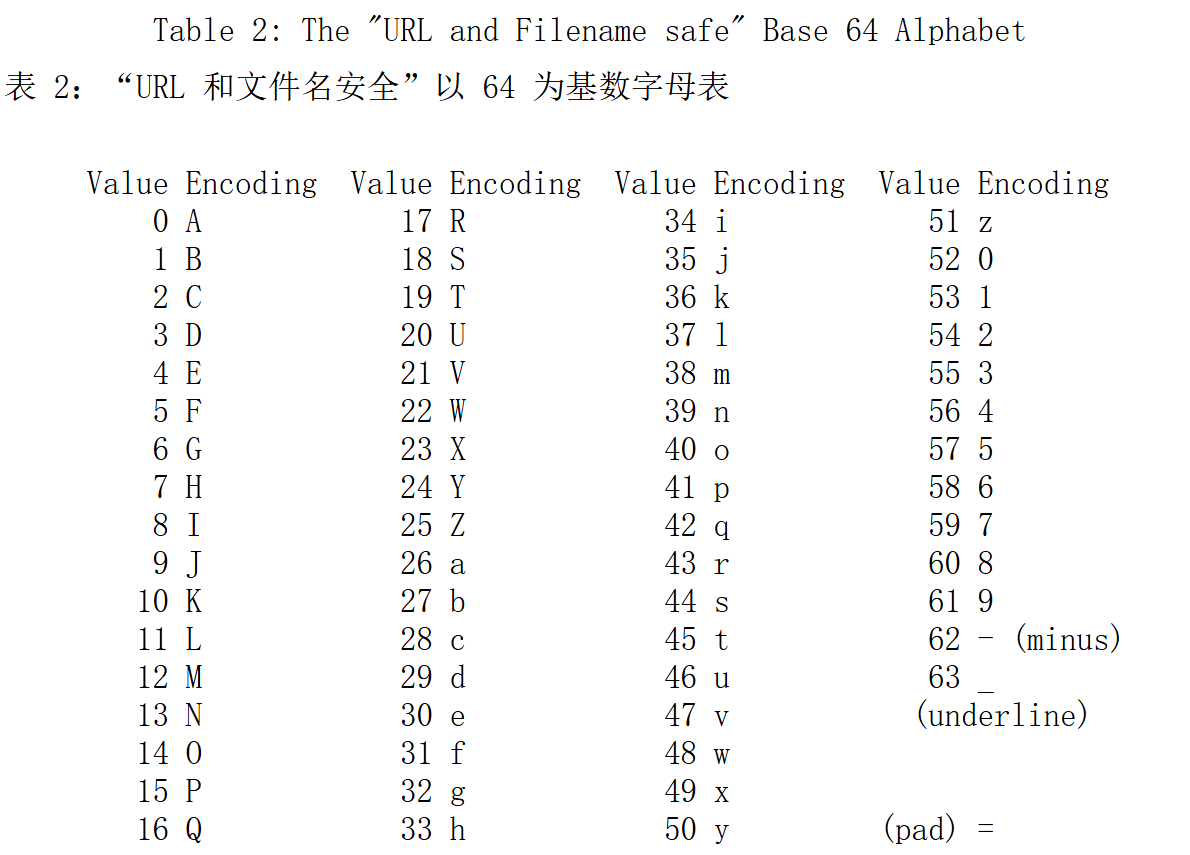
表二中使用下划线( _ )代替了URL和文件系统中常用的斜杠 ( / )因此称为"URL和文件名安全的Base64"
填充符
从上面的工作机制可以看到,Base64的工作原理就是通过把3个8位字符(总共24个二进制位),转换成4个以00开头的字符(总共24个有效二进制位)。
目前还有最后一个问题需要解决:如果输入字符的总长度不是3的倍数,那么若干个工作单元后,会剩下一至两个字符无法组成Quantum(工作单元),如下图所示:

这时候就需要涉及到填充符的概念,在码表中存在的pad字符,就用来表示“输入的字符串长度不正好是工作单元长度的倍数”这种情况:


示例
以RFC文档后的示例来说明:

通查询ASCII码表(UTF-8编码并未改变字符的编码值)
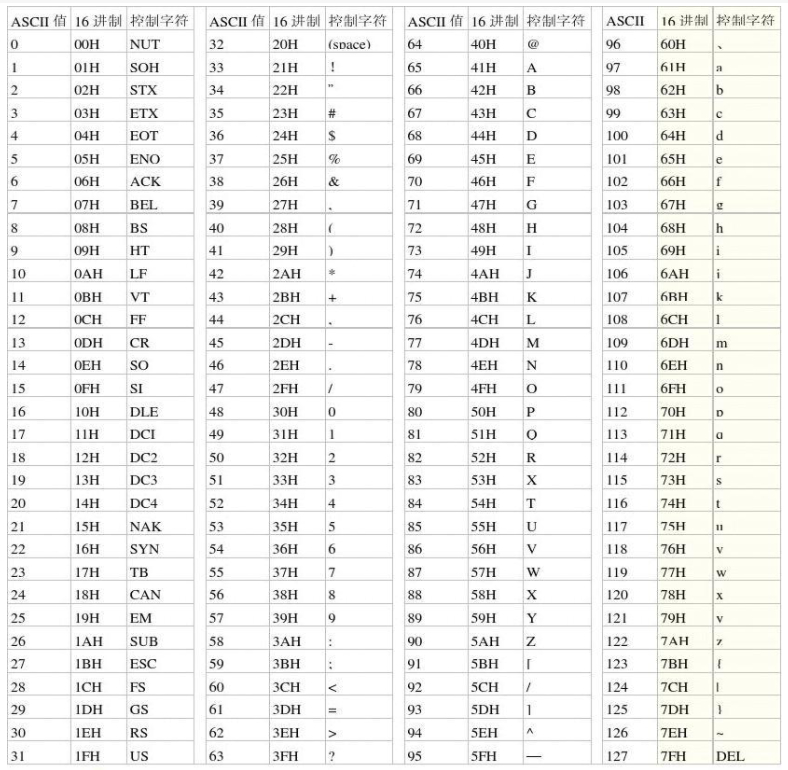
foob的ASCII码值为\x66\x6F\x6F\x62,转换为二进制为01100110 01101111 01101111 01100010
按照每3个分组:
(01100110 01101111 01101111)(01100010 )
转换
( 00011001 00100110 00111101 00101111)(00011000 00100000 pad pad)
将转换后的二进制值转换为十进制并查表
| Base64值 | 十进制 | 字符 |
|---|---|---|
| 00011001 | 25 | Z |
| 00100110 | 38 | m |
| 00111101 | 61 | 9 |
| 00101111 | 47 | v |
| 00011000 | 24 | Y |
| 00100000 | 32 | g |
| pad | = | |
| pad | = | |
| 最终结果:Zm9vYg== |
编程实现
-
Base系列编码的本质上是把N个8为变换成M个x位编码的过程,因此本质上是在求8和x的最小公倍数LCM, N=LCM(8,x)/8,M=LCM(8,x)/x。
-
将需要编码的字符串切分成若干个N位的字串分别独立进行转换,对最后一个字串进行判断,假设子串长为L,由于L*8肯定不可能是x的整数倍,因此需要末尾补零,至x的整数倍长,并进行填充字符的判断。
-
通过查表获取出最终的字符,并补上填充符,得到结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号