


PostgreSQL timeline
磨砺技术珠矶,践行数据之道,追求卓越价值
回到上一级页面: PostgreSQL基础知识与基本操作索引页 回到顶级页面:PostgreSQL索引页
关于timeline,有如下的说法
http://www.postgresql.org/docs/current/static/continuous-archiving.html
24.3.5. Timelines The ability to restore the database to a previous point in time creates some complexities that are akin to science-fiction stories about time travel and parallel universes. For example, in the original history of the database, suppose you dropped a critical table at 5:15PM on Tuesday evening, but didn't realize your mistake until Wednesday noon. Unfazed, you get out your backup, restore to the point-in-time 5:14PM Tuesday evening, and are up and running. In this history of the database universe, you never dropped the table. But suppose you later realize this wasn't such a great idea, and would like to return to sometime Wednesday morning in the original history. You won't be able to if, while your database was up-and-running, it overwrote some of the WAL segment files that led up to the time you now wish you could get back to. Thus, to avoid this, you need to distinguish the series of WAL records generated after you've done a point-in-time recovery from those that were generated in the original database history. To deal with this problem, PostgreSQL has a notion of timelines. Whenever an archive recovery completes, a new timeline is created to identify the series of WAL records generated after that recovery. The timeline ID number is part of WAL segment file names so a new timeline does not overwrite the WAL data generated by previous timelines. It is in fact possible to archive many different timelines. While that might seem like a useless feature, it's often a lifesaver. Consider the situation where you aren't quite sure what point-in-time to recover to, and so have to do several point-in-time recoveries by trial and error until you find the best place to branch off from the old history. Without timelines this process would soon generate an unmanageable mess. With timelines, you can recover to any prior state, including states in timeline branches that you abandoned earlier. Every time a new timeline is created, PostgreSQL creates a "timeline history" file that shows which timeline it branched off from and when. These history files are necessary to allow the system to pick the right WAL segment files when recovering from an archive that contains multiple timelines. Therefore, they are archived into the WAL archive area just like WAL segment files. The history files are just small text files, so it's cheap and appropriate to keep them around indefinitely (unlike the segment files which are large). You can, if you like, add comments to a history file to record your own notes about how and why this particular timeline was created. Such comments will be especially valuable when you have a thicket of different timelines as a result of experimentation. The default behavior of recovery is to recover along the same timeline that was current when the base backup was taken. If you wish to recover into some child timeline (that is, you want to return to some state that was itself generated after a recovery attempt), you need to specify the target timeline ID in recovery.conf. You cannot recover into timelines that branched off earlier than the base backup.
经过我的实验,发现是这样的,一旦开始第一次的restore,那么就产生了一个交叉点,于是"平行宇宙"诞生了。但是还有一个问题:
参见下图:
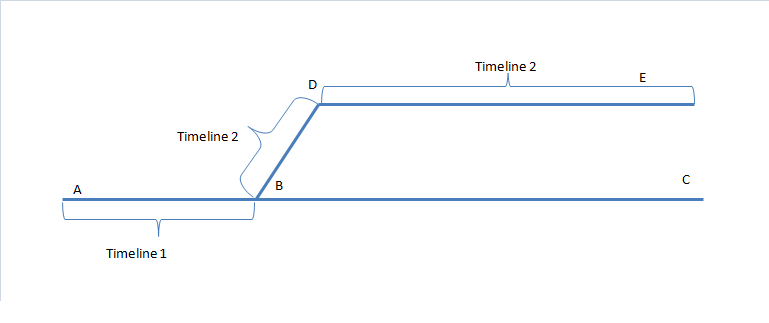
如果我当初在A点与B点之间插入数据,又在B点和C点之间插入数据。
然后,在B点所在的时间点处Restore,那么,Timeline2就产生了。
我可以接着在B点和D点至今插入数据,又在D点和E点之间插入数据。
可以说A到B是 timeline2, B到D到E是timeline1。
到达了D点或E点后,我是无法再次Restore到 B点和C点之间了。
这是因为:
B点到C点已经成为不存在了。
(虽然所有的archive wal log我都有,但是某些数据是保留在online wal log中,这部分的数据变化,经过timeline2的处理后,其实是永远失去了)
回到上一级页面: PostgreSQL基础知识与基本操作索引页 回到顶级页面:PostgreSQL索引页
磨砺技术珠矶,践行数据之道,追求卓越价值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号