
文件的操作
一、基本操作
1、读操作
(1)“r”
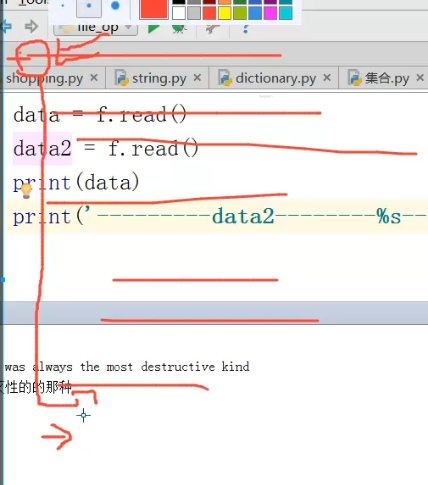
1 f=open("yesterday",r",encoding='utf-8')#文件句柄,r代表读模式 2 data=f.read() 3 data1=f.read() 4 print(data) 5 print("----data1---%s-"%data1)#注意点1:data1没有打印出来,原因文件读的顺序
6 f.close()
运行结果:(data1后没有数据,原因文件读写顺序从头到尾,读完一遍,指针停留在末尾)

(2)“r+”因为光标定位在开始,如果先写他就会直接覆盖,如果先读后写就会追加到最后
1 f=open("yesterday","r+",encoding="utf-8") 2 print(f.readline()) 3 print(f.tell()) 4 print(f.readline()) 5 print(f.tell()) 6 print(f.readline()) 7 print(f.tell()) 8 f.write("---我的天---") 9 f.close()
2、写操作
(1)“w”错误示例:(只写不能读)
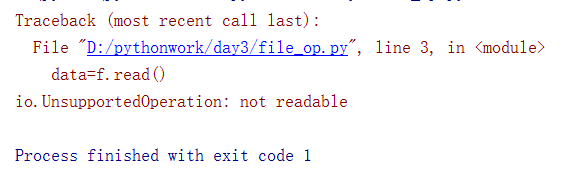
1 f=open("yesterday",'w',encoding='utf-8')#文件句柄 2 data=f.read() 3 data1=f.read() 4 print(data) 5 print("----data1---%s-"%data1)#注意点1:data1没有打印出来,原因文件读的顺序 6 f.write("我们一个像夏天,一个像秋天")
运行结果:
(2)“w+”还是会先创建文件,重新定位后,要追加还是从最后面写
1 f=open("yesterday2",'w+',encoding="utf-8") 2 f.write("---我的天1---\n") 3 f.write("---我的天2---\n") 4 f.write("---我的天4---") 5 print(f.tell()) 6 f.seek(10) 7 print(f.readline()) 8 f.write("---我的天0---") 9 f.close()
注意:(1)r“只读”;rb“二进制只读”;r+“先读可写”,文件指针放在文件开头(也是覆盖,但是前提是该文件必须存在,他不能创建文件),写的内容是在后面追加,不能写到中间;
(2)w“只写”:如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件(千万注意,要不然之前文档中的内容就没了),写的内容在后面追加,也不能写到中间
wb“二进制只写”;w+“先写后读,如果该文件如果该文件已存在则将其覆盖,不存在,创建新文件”
读写比写读重要
(3)[ a=append追加] a“追加”;ab“二进制追加”;a+“可读可写追加” ;ab+“二进制可读可写”
3、文件的增删改查
(1)
1 f=open("yesterday2","r",encoding="utf-8") 2 ''' 3 print(f.readline())#读取第一行 4 print(f.readline(2))#读取第二行的前两个字符; 5 ''' 6 # for i in range(5):#读取五行 7 # print(f.readline()) 8 for i in range(5): 9 print(f.readline(2))#里面的数字是每次限制读的字数,读五次,读完一行才会进入下一行 10 f.close()
(2)读文件时,将每一行读取打印出来,只有第五行不打印换成(---我是分割线---)
1 f=open("yesterday2","r",encoding="utf-8") 2 for index,line in enumerate (f.readlines()): 3 if index==4: 4 print ("---我是分割线---") 5 continue 6 print(line.strip())#因为有默认的换行符会打印出来,去掉\n
7 f.close()
这种方法循环效率是比较低的,他会将读取的数据都存储到内存,下面这种将是高效的,因为每次只读取一行存到内存中
1 f=open("yesterday2","r",encoding="utf-8") 2 count=0 3 for line in f: 4 print(line) 5 count+=1 6 if count==4: 7 print("---我是分割线---") 8 continue 9 f.close()
(3)seek()和tell()
1 #文件的定位: 2 # tell():文件光标的当前位置 3 # seek(offset [,from]):重新定位,第一个参数是要移动几个字节数,第二个是从那开始:0从头开始,1从当前位置,2从末位 4 #对于非二进制的文本文件,不允许使用偏移定位。 5 f=open("yesterday","r",encoding="utf-8") 6 print(f.tell()) 7 print(f.readline().strip()) 8 print(f.tell()) 9 print(f.seek(0,1))#定位到当前位置 10 print(f.readline().strip()) 11 print(f.seek(0,2))#定位到文件末尾 12 print(f.readline().strip()) 13 print(f.seek(0,0))#定位到文件开头 14 print(f.readline().strip())
运行结果:
D:\python\python.exe D:/pythonwork/day3/file_op.py 0 yesterday one i was young 27 27 i stand on the mountain 165 0 yesterday one i was young Process finished with exit code 0
(4)f.flush()
作用1:刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件
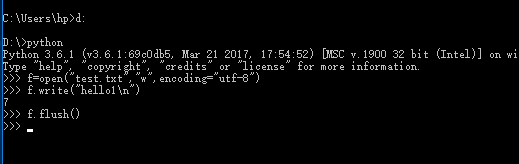
只有写了f.flush()时才可以将hello1写进去
作用2:可以用做进度条打印
import sys,time for i in range (20): sys.stdout.write("【")#以标准格式输出 sys.stdout.flush() time.sleep(0.1)
(5)f.truncate()把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。
1 f=open("yesterday","a",encoding="utf-8") 2 f.seek(10) 3 print(f.tell()) 4 f.truncate(10)
(6)修改文件
1 f=open("yesterday","r",encoding="utf-8") 2 f_new=open("yesterday.bar","w",encoding="utf-8") 3 #把文件中第三行改为陪晓红把眼泪擦干 4 for line in f: 5 if "陪你把眼泪擦干"in line: 6 line=line.replace("陪你把眼泪擦干","陪晓红把眼泪擦干") 7 f_new.write(line) 8 f.close()
(7)重命名和删除文件
1 import os 2 os.rename( "old.txt", "new.txt" )# 重命名文件old.txt到new.txt。
1 import os 2 # 删除一个已经存在的文件new.txt 3 os.remove("new.txt")
扩展知识:关于目录
1 import os 2 os.mkdir("test1")#在当前目录下创建一个叫test1的文件夹 3 os.chdir("test")#将当前目录改为test 4 print(os.getcwd())#获得当前的目录 5 os.rmdir("test1")#删除该文件
(8)实现简单的shell sed功能
1 #修改文件(打开两个文件,一个用来读,一个用来写) 2 import sys 3 f=open("yesterday","r",encoding="utf-8") 4 f_new=open("yesterday.bar","w",encoding="utf-8") 5 find_str=sys.avg[1] 6 replace_str=sys.avg[2] 7 #把文件中第三行改为陪晓红把眼泪擦干 8 for line in f: 9 if find_str in line: 10 line=line.replace(find_str,replace_str) 11 f_new.write(line) 12 f.close() 13 f_new.close()
(9)对于我们经常忘记关闭文件,所以可以用with语句来解决这个问题:
1 with open ("yesterday",'r',encoding='utf-8')as f:#打开一个文件 2 for line in f: 3 print(line)
1 with open ("yesterday",'r',encoding="utf-8")as f,\ 2 open("yesterday.bar","r",encoding="utf-8")as f1:#同时打开多个文件,并且交替打印每一行;根据python规则,一行通常不超过80字符,所以换行 3 for line,line1 in zip(f,f1): 4 print(line,line1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号