摘要:
 有一个数据库大概在700G左右,需要从服务器A搬迁到服务器B,两台服务器网络传输速度可以达到8MB/s,怎么做才能更快的搬迁并且宕机时间最短呢?
数据库业务逻辑概述:这个数据库只会插入数据,每天大概有300W条数据,不会对数据进行修改,只有一个表比较大,并且这个表是以自增ID作为分区依据列的,文件组会被重用,数据库为简单恢复模式,我定时会对表数据进行交换分区删除数据;三.解决方案(Solution)之前我也写过关于搬迁数据库的一些文章: 阅读全文
有一个数据库大概在700G左右,需要从服务器A搬迁到服务器B,两台服务器网络传输速度可以达到8MB/s,怎么做才能更快的搬迁并且宕机时间最短呢?
数据库业务逻辑概述:这个数据库只会插入数据,每天大概有300W条数据,不会对数据进行修改,只有一个表比较大,并且这个表是以自增ID作为分区依据列的,文件组会被重用,数据库为简单恢复模式,我定时会对表数据进行交换分区删除数据;三.解决方案(Solution)之前我也写过关于搬迁数据库的一些文章: 阅读全文
有一个数据库大概在700G左右,需要从服务器A搬迁到服务器B,两台服务器网络传输速度可以达到8MB/s,怎么做才能更快的搬迁并且宕机时间最短呢?
数据库业务逻辑概述:这个数据库只会插入数据,每天大概有300W条数据,不会对数据进行修改,只有一个表比较大,并且这个表是以自增ID作为分区依据列的,文件组会被重用,数据库为简单恢复模式,我定时会对表数据进行交换分区删除数据;三.解决方案(Solution)之前我也写过关于搬迁数据库的一些文章: 阅读全文
 一、前言在MSDN上看到一篇关于SQL Server 表分区的文档:已分区索引的特殊指导原则,如果你对表分区没有实战经验的话是比较难理解文档里面描述的意思。这里我就里面的一些概念进行讲解,方便大家的交流。(Figure0:索引与基表对齐)二、解读“索引要与其基表对齐,并不需要与基表参与相同的命名分区函数。但是,索引和基表的分区函数在实质上必须相同,即:1) 分区函数的参数具有相同的数据类型;2) 分区函数定义了相同数目的分区;3) 分区函数为分区定义了相同的边界值。
一、前言在MSDN上看到一篇关于SQL Server 表分区的文档:已分区索引的特殊指导原则,如果你对表分区没有实战经验的话是比较难理解文档里面描述的意思。这里我就里面的一些概念进行讲解,方便大家的交流。(Figure0:索引与基表对齐)二、解读“索引要与其基表对齐,并不需要与基表参与相同的命名分区函数。但是,索引和基表的分区函数在实质上必须相同,即:1) 分区函数的参数具有相同的数据类型;2) 分区函数定义了相同数目的分区;3) 分区函数为分区定义了相同的边界值。 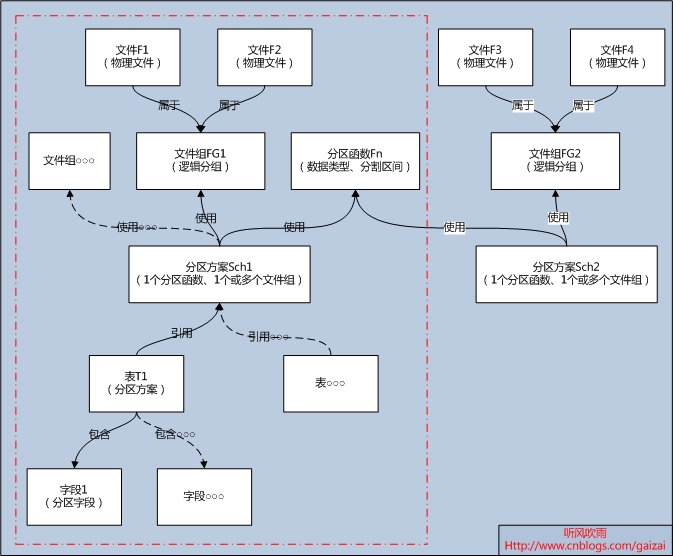 一、背景在线上系统中,如果我们发现存放数据库文件的磁盘空间不够,我们应该怎么办呢?新买一个硬盘挂载上去可以嘛?(linux下可以直接挂载硬盘进行扩容),但是我们的SQL Server是运行在Windows下的,有什么办法可以解决这燃眉之急呢?有两种方法可以解决上面的问题:第一种就是把数据库磁盘转换为【动态磁盘】,新增新的磁盘就可以解决了;第二种就是我今天要讲述的,使用SQL Server在其它磁盘(或者逻辑分区)中添加新的文件,添加完成后,SQL Server马上就能进新的数据了
一、背景在线上系统中,如果我们发现存放数据库文件的磁盘空间不够,我们应该怎么办呢?新买一个硬盘挂载上去可以嘛?(linux下可以直接挂载硬盘进行扩容),但是我们的SQL Server是运行在Windows下的,有什么办法可以解决这燃眉之急呢?有两种方法可以解决上面的问题:第一种就是把数据库磁盘转换为【动态磁盘】,新增新的磁盘就可以解决了;第二种就是我今天要讲述的,使用SQL Server在其它磁盘(或者逻辑分区)中添加新的文件,添加完成后,SQL Server马上就能进新的数据了  一、设计说明设计这个自动化的目的是想要交替、重复地使用固定的几个分区(分区编号01~05)来保存数据,当最后一个分区就是快满的时候,我们会把最旧数据的分区的数据清空出分区,新数据就可以使用老分区空间了。应用这个自动化管理分区的环境是有些限制的,其一:分区的数据是呈现递增的,比如分区字段是自增Id值,或者是以日期作为分区;其二:可以接受历史数据被移除分区表带来的问题。其三:一天进库的数量不应大于分区管理表
一、设计说明设计这个自动化的目的是想要交替、重复地使用固定的几个分区(分区编号01~05)来保存数据,当最后一个分区就是快满的时候,我们会把最旧数据的分区的数据清空出分区,新数据就可以使用老分区空间了。应用这个自动化管理分区的环境是有些限制的,其一:分区的数据是呈现递增的,比如分区字段是自增Id值,或者是以日期作为分区;其二:可以接受历史数据被移除分区表带来的问题。其三:一天进库的数量不应大于分区管理表  前段时间在忙数据库的表分区,经常会去上网找资料,但是在找到都是测试表分区的文章,没有实战经验的,所以在我把表分区运用到实际项目中的时候遇到了很多问题。
比如:如何确认分区字段?分区字段与聚集索引的区别与联系?如何存储分区索引?MSDN说交换分区是以秒计算,但执行40G交换分区超时?如何解决分区不断增长的问题?自动化交换分区的陷阱?
这些问题都只能自己在实战中摸索答案,后来我写了几篇关于这些问题的博文,希望对那些需要实战帮助的童鞋有一点提示和帮助。希望大家拍砖。
前段时间在忙数据库的表分区,经常会去上网找资料,但是在找到都是测试表分区的文章,没有实战经验的,所以在我把表分区运用到实际项目中的时候遇到了很多问题。
比如:如何确认分区字段?分区字段与聚集索引的区别与联系?如何存储分区索引?MSDN说交换分区是以秒计算,但执行40G交换分区超时?如何解决分区不断增长的问题?自动化交换分区的陷阱?
这些问题都只能自己在实战中摸索答案,后来我写了几篇关于这些问题的博文,希望对那些需要实战帮助的童鞋有一点提示和帮助。希望大家拍砖。 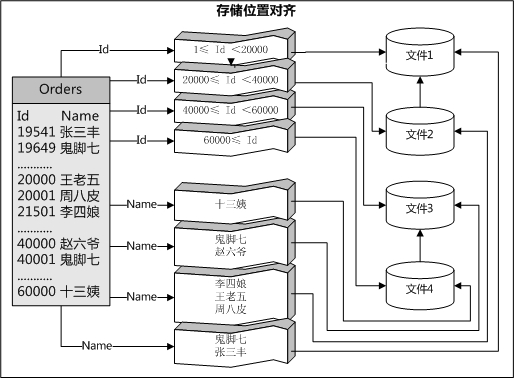 一、场景这一段时间使用SQL Server 2005 对几个系统进行表分区,这几个系统都有一些特点,比如数据库某张表持续增长,给数据库带来了很大的压力。现在假如提供一台新的服务器,那么我们应该如何规划这个数据库呢?应该如何进行最小宕机时间的数据库转移呢?如果规划数据库呢?二、环境准备要搭建一个好的系统,首先要从硬件和操作系统出发,好的设置和好的规划是高性能的前提,下面我就来说说自己的一些看法,欢迎大家提出异议;1) 对磁盘做RAID0(比如3*300G)
一、场景这一段时间使用SQL Server 2005 对几个系统进行表分区,这几个系统都有一些特点,比如数据库某张表持续增长,给数据库带来了很大的压力。现在假如提供一台新的服务器,那么我们应该如何规划这个数据库呢?应该如何进行最小宕机时间的数据库转移呢?如果规划数据库呢?二、环境准备要搭建一个好的系统,首先要从硬件和操作系统出发,好的设置和好的规划是高性能的前提,下面我就来说说自己的一些看法,欢迎大家提出异议;1) 对磁盘做RAID0(比如3*300G)  一、准备在SQL Server 2005版本之后就有了表分区的概念与应用,在分区操作里面有一个叫做合并分区的功能,也被称为删除分区。分区所处的文件组和文件是不会被删除的,只会对数据进行转移合并。合并分区时需要注意所带来的IO问题。合并分区常见情景:发现某个分区的数据很少,为了方便管理可以考虑合并分区。需要进行统计、四则运算的时候也可以考虑合并分区,这种情形下并没有对比合并与分区之间的性能,如果某位童鞋有兴趣和环境的话可以提供这方面的数据
一、准备在SQL Server 2005版本之后就有了表分区的概念与应用,在分区操作里面有一个叫做合并分区的功能,也被称为删除分区。分区所处的文件组和文件是不会被删除的,只会对数据进行转移合并。合并分区时需要注意所带来的IO问题。合并分区常见情景:发现某个分区的数据很少,为了方便管理可以考虑合并分区。需要进行统计、四则运算的时候也可以考虑合并分区,这种情形下并没有对比合并与分区之间的性能,如果某位童鞋有兴趣和环境的话可以提供这方面的数据  浙公网安备 33010602011771号
浙公网安备 33010602011771号