大数据学习09_HDFS3
HDFS 的 API 操作
配置Windows下Hadoop环境
在windows系统需要配置hadoop运行环境,否则直接运行代码会出现以下问题:
- 缺少winutils.exe
Could not locate executable null \bin\winutils.exe in the hadoop binaries
- 缺少hadoop.dll
Unable to load native-hadoop library for your platform… using builtin-Java classes where applicable
- 第一步:将hadoop2.7.5文件夹拷贝到一个没有中文没有空格的路径下面
- 第二步:在windows上面配置hadoop的环境变量: HADOOP_HOME,并 将%HADOOP_HOME%\bin添加到path中
- 第三步:把hadoop2.7.5文件夹中bin目录下的hadoop.dll文件放到系统盘: C:\Windows\System32 目录
- 第四步:关闭windows重启
导入 Maven 依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
使用url方式访问数据
@Test
public void demo1()throws Exception{
//第一步:注册hdfs 的url
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
//获取文件输入流
InputStream inputStream = new
URL("hdfs://node01:8020/a.txt").openStream();
//获取文件输出流
FileOutputStream outputStream = new FileOutputStream(new
File("D:\\hello.txt"));
//实现文件的拷贝
IOUtils.copy(inputStream, outputStream);
//关闭流
IOUtils.closeQuietly(inputStream);
IOUtils.closeQuietly(outputStream);
}
使用文件系统方式访问数据(重要)
涉及的主要类
在 Java 中操作 HDFS, 主要涉及以下 Class:
- Configuration 该类的对象封转了客户端或者服务器的配置
- FileSystem 该类的对象是一个文件系统对象, 可以用该对象的一些方法来对文件进行操作, 通过 FileSystem 的静态方法 get 获得该对象
FileSystem fs = FileSystem.get(conf)
- get 方法从 conf 中的一个参数 fs.defaultFS 的配置值判断具体是什么类 型的文件系统
- 如果我们的代码中没有指定 fs.defaultFS , 并且工程 ClassPath 下也没有给定 相应的配置, conf 中的默认值就来自于 Hadoop 的 Jar 包中的 coredefault.xml
- 默认值为 file:/// , 则获取的不是一个 DistributedFileSystem 的实例, 而是一个 本地文件系统的客户端对象
获取 FileSystem 的几种方式
第一种方式
@Test
public void getFileSystem1() throws IOException {
Configuration configuration = new Configuration();
//指定我们使用的文件系统类型:
configuration.set("fs.defaultFS", "hdfs://node01:8020/");
//获取指定的文件系统
FileSystem fileSystem = FileSystem.get(configuration);
System.out.println(fileSystem.toString());
}
第二种方式
@Test
public void getFileSystem2() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"),
new Configuration());
System.out.println("fileSystem:"+fileSystem);
}
第三种方式
@Test
public void getFileSystem3() throws Exception{
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://node01:8020");
FileSystem fileSystem = FileSystem.newInstance(configuration);
System.out.println(fileSystem.toString());
}
第四种方式
//@Test
public void getFileSystem4() throws Exception{
FileSystem fileSystem = FileSystem.newInstance(new
URI("hdfs://node01:8020") ,new Configuration());
System.out.println(fileSystem.toString());
}
遍历 HDFS 中所有文件
@Test
public void listFiles() throws URISyntaxException, IOException {
//1:获取FileSystem实例
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.28.128:8020"), new Configuration());
//2:调用方法listFiles 获取 /目录下所有的文件信息
RemoteIterator<LocatedFileStatus> iterator = fileSystem.listFiles(new Path("/"), true);
//3:遍历迭代器
while (iterator.hasNext()){
LocatedFileStatus fileStatus = iterator.next();
//获取文件的绝对路径 : hdfs://xxx.xxx.xxx.xxx:8020/xxx
System.out.println(fileStatus.getPath() + "----" +fileStatus.getPath().getName());
//文件的block信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println("block数:"+blockLocations.length);
}
}
运行结果如下:


HDFS 上创建文件夹
@Test
public void mkdirsTest() throws URISyntaxException, IOException {
//1:获取FileSystem实例
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.28.128:8020"), new Configuration());
//2:创建文件夹
fileSystem.create(new Path("/gaoshuai.txt"));
//3: 关闭FileSystem
fileSystem.close();
}
运行结果如下:

下载文件
@Test
public void downloadFile() throws URISyntaxException, IOException {
//1:获取FileSystem
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.28.128:8020"), new Configuration());
//2:获取hdfs的输入流
FSDataInputStream inputStream = fileSystem.open(new Path("/aaa/bbb/ccc/a.txt"));
//3:获取本地路径的输出流
FileOutputStream outputStream = new FileOutputStream("F://hadoop.txt");
//4:文件的拷贝
IOUtils.copy(inputStream, outputStream);
//5:关闭流
IOUtils.closeQuietly(inputStream);
IOUtils.closeQuietly(outputStream);
fileSystem.close();
}
运行结果如下:

HDFS 文件上传
@Test
public void uploadFile() throws URISyntaxException, IOException {
//1:获取FileSystem
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.28.128:8020"), new Configuration());
//2:调用方法,实现上传
fileSystem.copyFromLocalFile(new Path("F://123.txt"), new Path("/"));
//3:关闭FileSystem
fileSystem.close();
}
运行结果如下:
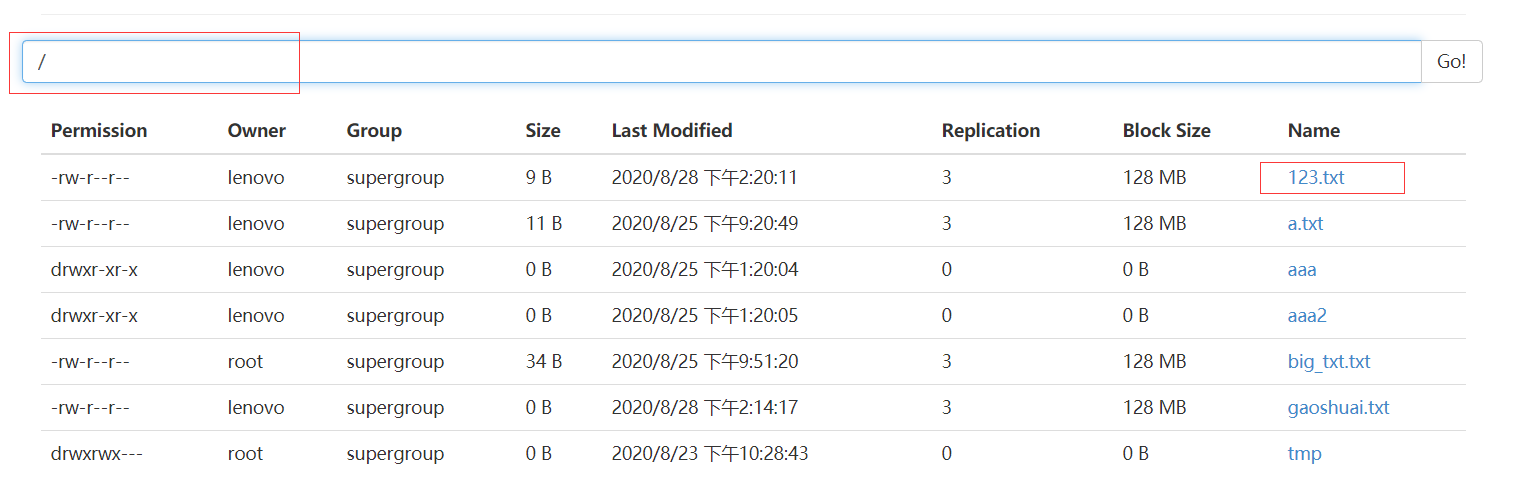
HDFS小文件合并
@Test
public void mergeFile() throws URISyntaxException, IOException, InterruptedException {
//1:获取FileSystem(分布式文件系统)
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.28.128:8020"), new Configuration(),"root");
//2:获取hdfs大文件的输出流
FSDataOutputStream outputStream = fileSystem.create(new Path("/big_txt.txt"));
//3:获取一个本地文件系统
LocalFileSystem localFileSystem = FileSystem.getLocal(new Configuration());
//4:获取本地文件夹下所有文件的详情
FileStatus[] fileStatuses = localFileSystem.listStatus(new Path("F:\\input"));
//5:遍历每个文件,获取每个文件的输入流
for (FileStatus fileStatus : fileStatuses) {
FSDataInputStream inputStream = localFileSystem.open(fileStatus.getPath());
//6:将小文件的数据复制到大文件
IOUtils.copy(inputStream, outputStream);
IOUtils.closeQuietly(inputStream);
}
//7:关闭流
IOUtils.closeQuietly(outputStream);
localFileSystem.close();
fileSystem.close();
}
运行结果如下:
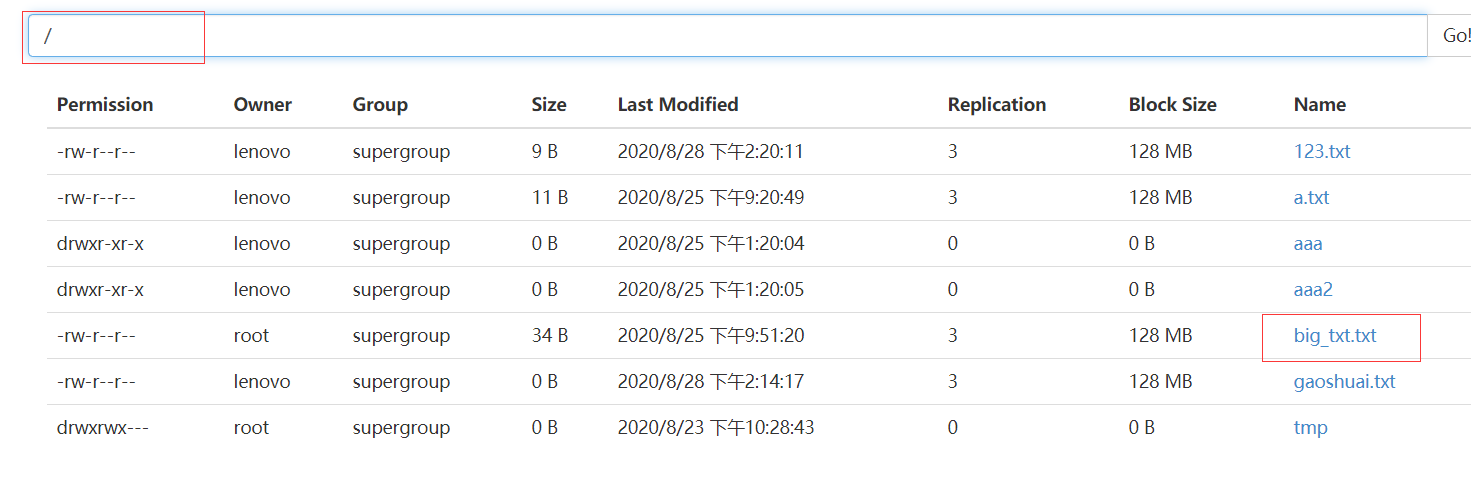
HDFS访问权限控制
停止hdfs集群,在1号机器上执行以下命令
cd /export/servers/hadoop-2.7.5 sbin/stop-dfs.sh
修改1号机器上的hdfs-site.xml当中的配置文件(重要)
cd /export/servers/hadoop-2.7.5/etc/hadoop vim hdfs-site.xml
修改如下:
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
</property>
修改完成之后配置文件发送到其他机器上面去
scp hdfs-site.xml node02:$PWD scp hdfs-site.xml node03:$PWD
OK配置完成!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号