职位信息分析
数据来源
数据:https://pan.baidu.com/s/1DNoRDu-7IJAnY6NP7Slphg 提取码:vqxw
分析平台: jupyter lab
anaconda 版本: Anaconda3-2019.07-Linux-x86_64.sh 用了之前的版本发现绘图比较模糊,更换版本后可以设置图形显示为svg
读取数据
##导入包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
##读取数据文件
df=pd.read_csv(r'DataAnalyst.csv',encoding='gb2312') ##解码,防止乱码报错
原始数据显示:

读取数据后显示:

print(df.info()) #columns数据不一致,有缺失空白 部分字段为数字,其他为字符串
#获取数据帧的行列及数据类型信息
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6876 entries, 0 to 6875
Data columns (total 17 columns):
city 6876 non-null object
companyFullName 6876 non-null object
companyId 6876 non-null int64
companyLabelList 6170 non-null object
companyShortName 6876 non-null object
companySize 6876 non-null object
businessZones 4873 non-null object
firstType 6869 non-null object
secondType 6870 non-null object
education 6876 non-null object
industryField 6876 non-null object
positionId 6876 non-null int64
positionAdvantage 6876 non-null object
positionName 6876 non-null object
positionLables 6844 non-null object
salary 6876 non-null object
workYear 6876 non-null object
dtypes: int64(2), object(15)
memory usage: 913.3+ KB
None
去重操作
print(len(df.positionId.unique()))#以positionId 为准,查看不重复的职位id
df_duplicates=df.drop_duplicates(subset='positionId',keep='first').copy()
# 去重
# DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
# subset: 以哪个列为去重基准。
# keep: {‘first’, ‘last’, False}, 默认值 ‘first’。
# first: 保留第一次出现的重复项。
# last: 保留最后一次出现。
# False: 删除所有重复项。
# inplace:布尔值,默认为False,是否覆盖原数据。
print(df_duplicates.head())

查看帮助:
help(df.drop_duplicates(subset='positionId',keep='first').copy)
# 获取使用帮助
# 获取数据及索引的拷贝
# 任何对此拷贝索引及数据的修改都不会影响到原数据
处理薪资数据
主要是因为薪资数据一般为8k-12k 模式,需要拆解为数字类型
#处理薪资数据
def cut_word(word,method):
position=word.find('-')
length=len(word)
if position !=-1:
#如果薪资数据内存在-为真,执行本语句,获取-和k之前的数据和-及k之间的数据
bottomSalary=word[:position-1]
topSalary=word[position+1:length-1]
else:
#如果没有-, 将该数据全部转化为大写后截取数据
bottomSalary=word[:word.upper().find('K')]
topSalary=bottomSalary
if method =='bottom':
return bottomSalary
else:
return topSalary
# 添加新列,获取薪资的最低和最高
df_duplicates['topSalary']=df_duplicates.salary.apply(cut_word,method='top')
df_duplicates['bottomSalary']=df_duplicates.salary.apply(cut_word,method='bottom')
#调用函数,在Series值上调用函数 method='bottom' 为传递的参数,返回对每个数据的操作后的值
df_duplicates.salary.apply?
df_duplicates.bottomSalary.head()
df_duplicates.bottomSalary=df_duplicates.bottomSalary.astype('int')
df_duplicates.topSalary=df_duplicates.topSalary.astype('int')
df_duplicates.bottomSalary.head()
转化为数据类型,以便计算

另一种处理薪资的方式:
0 7k-9k
1 10k-15k
2 4k-6k
3 6k-8k
4 2k-3k
#拆分代码
df_clear1['salary_range']=df_clear1['salary'].str.split("-")
df_clear1['min_salary']=df_clear1['salary_range'].str.get(0)
df_clear1['max_salary']=df_clear1['salary_range'].str.get(1)
##这种也可以做
df_duplicates['min_salary'] = df_duplicates['salary'].str.split("-").str.get(0)
##
df_clear1['min_salary'] = df_clear1['min_salary'].map(unitchange)
df_clear1['max_salary']=df_clear1['max_salary'].fillna('unknown').map(unitchange)
0 [7k, 9k]
1 [10k, 15k]
2 [4k, 6k]
3 [6k, 8k]
4 [2k, 3k]
5 [10k, 15k]
6 [7k, 14k]
获取平均工资
#求平均薪资。
#lambda 详见:https://blog.csdn.net/BIT_SKY/article/details/50781806
df_duplicates['avgSalary']=df_duplicates.apply(lambda x:(x.bottomSalary+x.topSalary)/2,axis=1)
#axis是apply中的参数,axis=0表示将函数用在行,axis=1则是列。
df_clean=df_duplicates[['city','companyShortName','companySize','education','positionLables','workYear','avgSalary','positionName']].copy()
##copy 会返回一个数据帧,任何在该帧上的操作都不会对原始数据产生影响
df_clean.head

print(df_clean.describe())
# 用来正常显示中文标签。
plt.rcParams['font.sans-serif']=['SimHei']
df_clean.avgSalary.hist(bins=20)
plt.show()

#groupby()分组,median()中位数,sort_values(ascending=False)排序(降序)。
df_clean.groupby(df_clean.city).avgSalary.median().sort_values(ascending=False)
#根据某一列值对数据分组,分组的同时对指定的列(可计算的数)获取分组内指定列最大或最小的数,获取中位数,并排序(类似数据sql的group 操作)
help(df_clean.groupby(df_clean.city))

df_clean.groupby(df_clean.city).avgSalary.median()
分析每个城市的平均薪资水平
#转化成category格式,方便重新排序索引值,为了让箱体图中位数从高到低排列。
df_clean.city=df_clean.city.astype('category')
#转换类型,类似与枚举,一般为血型,性别
df_clean.city.cat.set_categories(['北京','深圳','杭州','上海','苏州','武汉','成都','西安','广州','厦门','长沙','南京','天津'],inplace=True)
df_clean.boxplot(column='avgSalary',by='city',figsize=(9,6))
plt.show()
#boxplot是调用箱线图函数,column选择箱线图的数值,by是选择分类变量,figsize是尺寸。
##熟悉箱线图

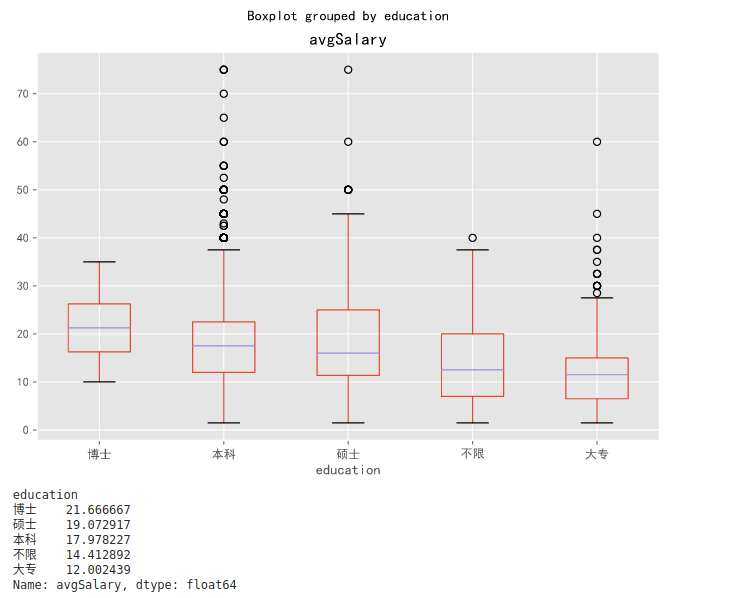
根据学历分析薪资水平
#此处上侧方法一致,详见上方解释。
df_clean.groupby(df_clean.education).avgSalary.median().sort_values(ascending=False)
df_clean.education=df_clean.education.astype('category')
df_clean.education.cat.set_categories(['博士','本科','硕士','不限','大专'],inplace=True)
ax=df_clean.boxplot(column='avgSalary',by='education',figsize=(9,6))
plt.show()
print(df_clean.groupby(df_clean.education).avgSalary.mean().sort_values(ascending=False))
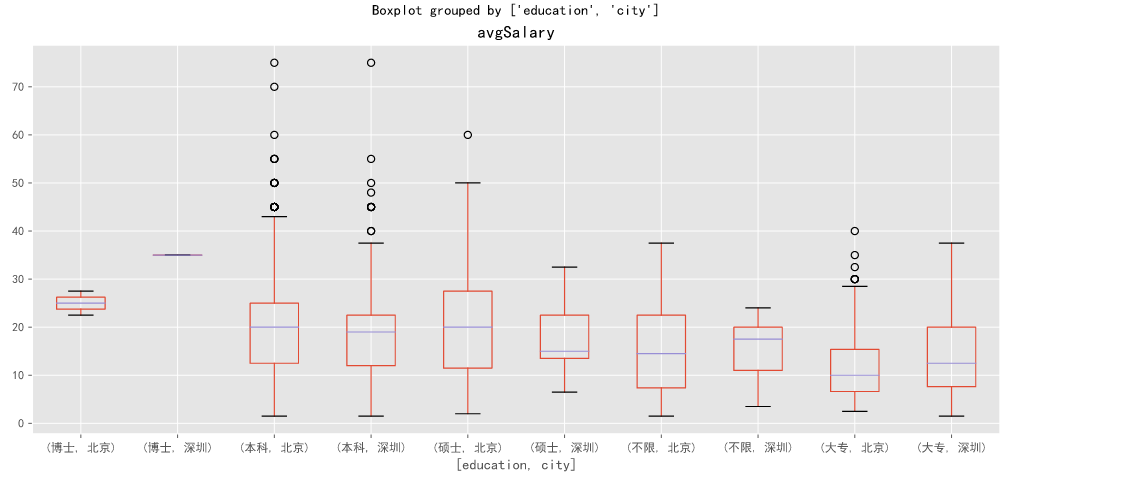
深圳和北京对比
df_sz_bj=df_clean[df_clean['city'].isin(['深圳','北京'])]
df_sz_bj.boxplot(column='avgSalary',by=['education','city'],figsize=[14,6])
plt.show()
#unstack()详见:https://www.cnblogs.com/bambipai/p/7658311.html
print(df_clean.groupby(['city','education']).avgSalary.mean().unstack())
education 博士 本科 硕士 不限 大专
city
北京 25.0 19.435802 19.759740 15.673387 12.339474
深圳 35.0 18.532911 18.029412 15.100000 13.898936
杭州 NaN 16.823432 20.710526 18.269231 12.327586
上海 15.0 17.987552 19.180000 14.051471 13.395455
苏州 NaN 14.310345 16.833333 NaN 14.600000
武汉 NaN 11.500000 7.000000 10.950000 11.214286
成都 NaN 13.520202 12.750000 10.562500 11.000000
西安 NaN 12.208333 5.000000 8.666667 8.150000
广州 NaN 14.170259 14.571429 9.250000 8.988095
厦门 NaN 11.805556 15.750000 12.500000 6.785714
长沙 NaN 10.633333 9.000000 7.642857 9.000000
南京 NaN 11.327869 13.500000 7.000000 9.272727
天津 NaN 9.300000 NaN 3.500000 5.500000
print(df_clean.groupby(['city','education']).avgSalary.count().unstack())
education 博士 本科 硕士 不限 大专
city
北京 2.0 1877.0 154.0 124.0 190.0
深圳 1.0 395.0 17.0 20.0 94.0
杭州 NaN 303.0 19.0 26.0 58.0
上海 3.0 723.0 75.0 68.0 110.0
苏州 NaN 29.0 3.0 NaN 5.0
武汉 NaN 44.0 1.0 10.0 14.0
成都 NaN 99.0 2.0 8.0 26.0
西安 NaN 24.0 1.0 3.0 10.0
广州 NaN 232.0 7.0 12.0 84.0
厦门 NaN 18.0 2.0 3.0 7.0
长沙 NaN 15.0 1.0 7.0 2.0
南京 NaN 61.0 6.0 5.0 11.0
天津 NaN 15.0 NaN 1.0 4.0
#这里使用了agg函数,同时传入count和mean方法,然后返回了不同公司的计数和平均值两个结果。所以前文的mean,count,其实都省略了agg。agg除了系统自带的几个函数,它也支持自定义函数。
print(df_clean.groupby('companyShortName').avgSalary.agg(['count','mean']).sort_values(by='count',ascending=False))
count mean
companyShortName
美团点评 175 21.862857
滴滴出行 64 27.351562
百度 44 19.136364
网易 36 18.208333
今日头条 32 17.125000
腾讯 32 22.437500
京东 32 20.390625
百度外卖 31 17.774194
个推 31 14.516129
TalkingData 28 16.160714
宜信 27 22.851852
搜狐媒体 23 25.739130
饿了么 23 19.391304
Gridsum 国双 23 19.086957
去哪儿网 22 17.863636
汽车之家 21 18.952381
乐视 19 21.052632
京东商城 19 23.763158
滴滴出行(小桔科技) 18 34.722222
人人行(借贷宝) 17 21.088235
链家网 16 17.250000
嘉琪科技 16 24.625000
百融金服 16 17.500000
易到用车 16 16.156250
通联数据 16 8.843750
星河互联集团 16 29.062500
陌陌 15 18.566667
买单侠 15 18.600000
有数金服 15 13.700000
返利网 15 23.833333
... ... ...
图灵机器人 1 32.500000
国金证券 1 37.500000
大观资本 1 4.500000
大麦网 1 55.000000
天会创投 1 5.000000
天会皓闻 1 3.500000
太子龙 1 4.000000
天骄尚学 1 10.000000
天阳科技 1 11.500000
天闻数媒 1 15.000000
天融互联 1 20.000000
天育 1 7.000000
天翼阅读文化传播有限公司 1 15.000000
天眼互联 1 7.500000
天相瑞通 1 7.500000
天玑科技 1 15.000000
天源迪科 1 31.500000
天津赛维斯科技有限公司 1 5.000000
天津航空 1 9.000000
天津美源星 1 3.500000
天津小猫 1 11.500000
天气宝 1 15.000000
天星资本 1 11.000000
天弘基金 1 25.000000
天尧信息 1 15.000000
天宝 1 22.500000
天天果园 1 17.500000
天地汇 1 14.000000
天同 1 15.000000
龙浩通信 1 5.000000
[2243 rows x 2 columns]
根据地区获取其前五数据
#自定义了函数topN,将传入的数据计数,并且从大到小返回前五的数据。然后以city聚合分组,因为求的是前5的公司,所以对companyShortName调用topN函数。
df_clean.groupby('companyShortName').avgSalary.agg(lambda x:max(x)-min(x))
def topN(df,n=5):
counts=df.value_counts()
return counts.sort_values(ascending=False)[:n]
print(df_clean.groupby('city').companyShortName.apply(topN))
city
北京 美团点评 156
滴滴出行 60
百度 39
今日头条 32
百度外卖 31
深圳 腾讯 25
金蝶 14
华为技术有限公司 12
香港康宏金融集团 12
顺丰科技有限公司 9
杭州 个推 22
有数金服 15
网易 15
同花顺 14
51信用卡管家 11
上海 饿了么 23
美团点评 19
买单侠 15
返利网 15
点融网 11
苏州 同程旅游 10
朗动网络科技 3
智慧芽 3
思必驰科技 2
食行生鲜 2
武汉 斗鱼直播 5
卷皮 4
武汉物易云通网络科技 4
榆钱金融 3
远光软件武汉研发中心 2
...
西安 思特奇Si-tech 4
天晓科技 3
绿盟科技 3
全景数据 2
海航生态科技 2
广州 探迹 11
唯品会 9
广东亿迅 8
阿里巴巴移动事业群-UC 7
聚房宝 6
厦门 美图公司 4
厦门融通信息技术有限责任公司 2
Datartisan 数据工匠 2
财经智库网 1
光鱼全景 1
长沙 芒果tv 4
惠农 3
思特奇Si-tech 2
益丰大药房 1
五八到家有限公司 1
南京 途牛旅游网 8
通联数据 7
中地控股 6
创景咨询 5
南京领添 3
天津 神州商龙 2
丰赢未来 1
瑞达恒RCC 1
三汇数字天津分公司 1
58到家 1
Name: companyShortName, Length: 65, dtype: int64
print(df_clean.groupby('city').positionName.apply(topN))
city
北京 数据分析师 238
数据产品经理 121
大数据开发工程师 69
分析师 49
数据分析 42
深圳 数据分析师 52
大数据开发工程师 32
数据产品经理 24
需求分析师 21
大数据架构师 11
杭州 数据分析师 44
大数据开发工程师 22
数据产品经理 15
数据仓库工程师 11
数据分析 10
上海 数据分析师 79
大数据开发工程师 37
数据产品经理 31
大数据工程师 26
需求分析师 20
苏州 数据分析师 8
需求分析师 2
数据产品经理 2
专利检索分析师 1
商业数据分析 1
武汉 大数据开发工程师 6
数据分析师 5
大数据架构师 2
分析师 2
Hadoop大数据开发工程师 2
...
西安 需求分析师 5
大数据开发工程师 3
数据分析师 3
大数据工程师 2
云计算、大数据(Hadoop\Spark) 高级软件工程师 1
广州 数据分析师 31
需求分析师 23
大数据开发工程师 13
数据分析专员 10
数据分析 9
厦门 数据分析专员 3
数据分析师 3
大数据开发工程师 2
需求分析师 1
证券分析师 1
长沙 数据开发工程师 2
数据工程师 2
数据应用开发工程师 1
PHP高级研发工程师(数据分析类产品) 1
数据质量工程师(技术中心) 1
南京 大数据开发工程师 5
数据分析师 5
大数据架构师 3
大数据工程师 3
数据规划 2
天津 数据分析师 3
数据工程师 2
数据分析专员(运营) 1
商业数据录入员 1
数据专员 1
Name: positionName, Length: 65, dtype: int64
词云处理
print(df_clean.positionLables)
print(df_clean.positionLables.str[1:-1]) #获取去除中括号的数据
word=df_clean.positionLables.str[1:-1].str.replace(' ','') #去除空格
print(word)
df_word=word.dropna().str.split(',').apply(pd.value_counts) #对词的次数计算
print(df_word)
####产生词云,以某个图片为准,
from PIL import Image
piccc = np.array(Image.open(r"y.png"))
df_word_counts=df_word.unstack().dropna().reset_index().groupby('level_0').count()
from wordcloud import WordCloud
df_word_counts.index=df_word_counts.index.str.replace("'","")
wc=WordCloud(font_path=r'simhei.ttf',width=900,height=400,background_color='white',mask=piccc)
fig,ax=plt.subplots(figsize=(20,15))
wc.fit_words(df_word_counts.level_1)
ax=plt.imshow(wc)
plt.axis('off')
plt.show()
####无图片显示
df_word_counts=df_word.unstack().dropna().reset_index().groupby('level_0').count()
from wordcloud import WordCloud
df_word_counts.index=df_word_counts.index.str.replace("'","")
wc=WordCloud(font_path=r'C:\Windows\Fonts\FZSTK.TTF',width=900,height=400,background_color='white')
fig,ax=plt.subplots(figsize=(20,15))
wc.fit_words(df_word_counts.level_1)
ax=plt.imshow(wc)
plt.axis('off')
plt.show()

绘制饼图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
plt.rcParams['font.family'] = ['simhei']
plt.rcParams['font.size']=10
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_json("zl.json", lines=True, encoding='utf-8') #熟悉读取文件的方法
edu = df["eduLevel"]
pic = edu.value_counts()
pic.plot.pie(title="学历分布", figsize=(6, 6),autopct='%.2f',label="学历分布") ##title 表示图表名称, autopct 分布百分比 label 取代了eduLevel进行显示
###数据包含任何NaN,它们将自动填满0.如果数据中有任何负值,则会引发ValueError
导入数据
pd.read_csv(filename):从CSV文件导入数据
pd.read_table(filename):从限定分隔符的文本文件导入数据
pd.read_excel(filename):从Excel文件导入数据
pd.read_sql(query, connection_object):从SQL表/库导入数据
pd.read_json(json_string):从JSON格式的字符串导入数据
pd.read_html(url):解析URL、字符串或者HTML文件,抽取其中的tables表格
pd.read_clipboard():从你的粘贴板获取内容,并传给read_table()
pd.DataFrame(dict):从字典对象导入数据,Key是列名,Value是数据
导出数据
df.to_csv(filename):导出数据到CSV文件
df.to_excel(filename):导出数据到Excel文件
df.to_sql(table_name, connection_object):导出数据到SQL表
df.to_json(filename):以Json格式导出数据到文本文件
创建测试对象
pd.DataFrame(np.random.rand(20,5)):创建20行5列的随机数组成的DataFrame对象
pd.Series(my_list):从可迭代对象my_list创建一个Series对象
df.index = pd.date_range('1900/1/30', periods=df.shape[0]):增加一个日期索引
查看、检查数据
df.head(n):查看DataFrame对象的前n行
df.tail(n):查看DataFrame对象的最后n行
df.shape():查看行数和列数
http://df.info():查看索引、数据类型和内存信息
df.describe():查看数值型列的汇总统计
s.value_counts(dropna=False):查看Series对象的唯一值和计数
df.apply(pd.Series.value_counts):查看DataFrame对象中每一列的唯一值和计数
数据选取
df[col]:根据列名,并以Series的形式返回列
df[[col1, col2]]:以DataFrame形式返回多列
s.iloc[0]:按位置选取数据
s.loc['index_one']:按索引选取数据
df.iloc[0,:]:返回第一行
df.iloc[0,0]:返回第一列的第一个元素
数据清理
df.columns = ['a','b','c']:重命名列名
pd.isnull():检查DataFrame对象中的空值,并返回一个Boolean数组
pd.notnull():检查DataFrame对象中的非空值,并返回一个Boolean数组
df.dropna():删除所有包含空值的行
df.dropna(axis=1):删除所有包含空值的列
df.dropna(axis=1,thresh=n):删除所有小于n个非空值的行
df.fillna(x):用x替换DataFrame对象中所有的空值
s.astype(float):将Series中的数据类型更改为float类型
s.replace(1,'one'):用‘one’代替所有等于1的值
s.replace([1,3],['one','three']):用'one'代替1,用'three'代替3
df.rename(columns=lambda x: x + 1):批量更改列名
df.rename(columns={'old_name': 'new_ name'}):选择性更改列名
df.set_index('column_one'):更改索引列
df.rename(index=lambda x: x + 1):批量重命名索引
数据处理:Filter、Sort和GroupBy
df[df[col] > 0.5]:选择col列的值大于0.5的行
df.sort_values(col1):按照列col1排序数据,默认升序排列
df.sort_values(col2, ascending=False):按照列col1降序排列数据
df.sort_values([col1,col2], ascending=[True,False]):先按列col1升序排列,后按col2降序排列数据
df.groupby(col):返回一个按列col进行分组的Groupby对象
df.groupby([col1,col2]):返回一个按多列进行分组的Groupby对象
df.groupby(col1)[col2]:返回按列col1进行分组后,列col2的均值
df.pivot_table(index=col1, values=[col2,col3], aggfunc=max):创建一个按列col1进行分组,并计算col2和col3的最大值的数据透视表
df.groupby(col1).agg(np.mean):返回按列col1分组的所有列的均值
data.apply(np.mean):对DataFrame中的每一列应用函数np.mean
data.apply(np.max,axis=1):对DataFrame中的每一行应用函数np.max
数据合并
df1.append(df2):将df2中的行添加到df1的尾部
df.concat([df1, df2],axis=1):将df2中的列添加到df1的尾部
df1.join(df2,on=col1,how='inner'):对df1的列和df2的列执行SQL形式的join
数据统计
df.describe():查看数据值列的汇总统计
df.mean():返回所有列的均值
df.corr():返回列与列之间的相关系数
df.count():返回每一列中的非空值的个数
df.max():返回每一列的最大值
df.min():返回每一列的最小值
df.median():返回每一列的中位数
df.std():返回每一列的标准差
感谢自:
https://www.jianshu.com/p/1e1081ca13b5
xxz联数据分析
连接mongodb 获取数据
##转换格式并写入文件
import pymongo
myclient = pymongo.MongoClient('mongodb://10.20.200.4:27017/')
mydb = myclient.zhilian
mydocs = mydb.new1
import json
all = mydocs.find({},{ "_id": 0})
with open("zlnew1.json", 'a+') as f:
for i in all:
dumpjson = json.dumps(i)
loadjson = json.loads(dumpjson)
job_address = loadjson["company"]["job_address"]
company_name = loadjson["company"]["name"]
company_size = loadjson["company"]["size"]
company_type = loadjson["company"]["type"]
company_url = loadjson["company"]["url"]
crawltime = loadjson["crawltime"]
eduLevel = loadjson["eduLevel"]
job_detail = loadjson["job_detail"]
job_highlights = loadjson["job_highlights"]
job_skills = loadjson["job_skills"]
jobarea = loadjson["jobarea"]
jobname = loadjson["jobname"]
joburl = loadjson["joburl"]
plan = loadjson["plan"]
salary = loadjson["salary"]
welfare = loadjson["welfare"]
workingExp = loadjson["workingExp"]
template = {
"job_address": job_address,
"name": company_name,
"size": company_size,
"type": company_type,
"url": company_url,
"crawltime": crawltime,
"eduLevel": eduLevel,
"job_detail": job_detail,
"job_highlights": job_highlights,
"job_skills": job_skills,
"jobarea": jobarea,
"jobname": jobname,
"joburl": joburl,
"plan": plan,
"salary": salary,
"welfare": welfare,
"workingExp": workingExp
}
json.dump(template, f, ensure_ascii=False) #写入汉字
f.write('\n')
##打印并展示
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import json
df = pd.read_json('zlnew1.json', lines=True)
df.info
df[['workingExp','salary']].head(30)
https://zhuanlan.zhihu.com/p/32983898
同类型参考:
https://blog.csdn.net/g6U8W7p06dCO99fQ3/article/details/100070109
https://www.jianshu.com/p/1e1081ca13b5
https://blog.csdn.net/qq_41562377/article/details/90049442
https://blog.csdn.net/qq_28584559/article/details/89475474
https://blog.csdn.net/qq_41199755/article/details/81105655
https://blog.csdn.net/qq_36523839/article/details/80949963
https://zhuanlan.zhihu.com/p/25630700
自己抓取的招聘数据进行分析
使用jupyter lab 测试
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
df = pd.read_json("zl.json", lines=True, encoding='utf-8')
df.describe()
x = df.type
y= x.value_counts()
plt.rcParams['font.family'] = ['simhei']
plt.rcParams['font.size']=10
plt.rcParams['axes.unicode_minus'] = False
y.plot.pie(title="企业类型分布百分比", figsize=(6, 6),autopct='%.2f',label="类型")
df.info()
df.columns
df.head(4)
salary = df['salary']
salary
sal = salary[ salary != "薪资面议"]
sa = sal.value_counts()
sa.plot.barh(title="薪资发布区间分布", figsize=(10, 10))
def cut_word(word,method):
position=word.find('-')
length=len(word)
if position !=-1:
#如果薪资数据内存在-为真,执行本语句,获取-和k之前的数据和-及k之间的数据
bottomSalary=word[:position-1]
topSalary=word[position+1:length-1]
else:
#如果没有-, 将该数据全部转化为大写后截取数据
bottomSalary=word[:]
topSalary=bottomSalary
if method =='bottom':
return bottomSalary
else:
return topSalary
# 添加新列,获取薪资的最低和最高
df['topSalary']=salary.apply(cut_word,method='top')
df['bottomSalary']=salary.apply(cut_word,method='bottom')
# 函数作用:
# 将薪资示例: 20k-30k分割成20 30 样子,便于分析平均工资
df['topSalary'] = df['topSalary'].astype('int')
df['bottomSalary'] = df['bottomSalary'].astype('int')
# 将薪资的数据类型转换为可计算类型
df['average'] = (df['topSalary'] + df['bottomSalary']) / 2
aver = df['average'].value_counts()
aver.plot.barh(title="平均薪资", figsize=(8, 8))
aver.plot?
edulevel = df["eduLevel"]
educount = edulevel.value_counts()
educount.plot.pie(title="学历要求分布百分比", figsize=(8, 8),autopct='%.2f',label="学历")
df.head()
csize = df["size"].value_counts()
csize.plot.barh(title="公司一般规模", figsize=(6, 6))
hotjob = df["jobname"].value_counts()
hotjob.plot.barh(title="热门职位名称", figsize=(25, 25))
#福利词云
df.columns
data = pd.DataFrame(df['job_highlights'])
data.to_csv("jobhighlights.csv",index=False,header=False)
df['job_highlights']
data = pd.DataFrame(df['job_detail'])
data.to_csv("job_detail.csv",index=False,header=False)
福利频率
使用结巴分词获取福利的词频之后,对福利进行分析
##通过结巴获取分词
import jieba
import jieba.posseg as pseg
from collections import Counter
import os, codecs
##使用字典,内容为一些自定义的有意义的词
#五险一金 年底双薪 绩效奖金 带薪年假 补充医疗保险 等
jieba.load_userdict("dict.txt")
with codecs.open('jobwelfare.csv', 'r', 'utf8') as f:
txt = f.read()
# words = jieba.cut(txt)
seg_list = jieba.cut(txt)
c = Counter()
for x in seg_list:
if len(x)>1 and x != '\r\n':
c[x] += 1
print('常用词频度统计结果')
for (k,v) in c.most_common():
print(k, v)
##将获取的分词的频率转化为datafame
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
wel = pd.DataFrame(c.most_common(), columns=("福利", "数量"))
重新设置索引
wel = wel.set_index("福利")
wel
##使用数据画图
plt.rcParams['font.family'] = ['simhei']
plt.rcParams['font.size']=10
plt.rcParams['axes.unicode_minus'] = False
wel.plot.barh(title="热门福利", figsize=(20, 20))
转换格式写入json
##转换格式并写入文件
import pymongo
myclient = pymongo.MongoClient('mongodb://10.20.200.4:27017/')
mydb = myclient.zhilian
mydocs = mydb.new1
import json
all = mydocs.find({},{ "_id": 0})
with open("zlnew1.json", 'a+') as f:
for i in all:
dumpjson = json.dumps(i)
loadjson = json.loads(dumpjson)
job_address = loadjson["company"]["job_address"]
company_name = loadjson["company"]["name"]
company_size = loadjson["company"]["size"]
company_type = loadjson["company"]["type"]
company_url = loadjson["company"]["url"]
crawltime = loadjson["crawltime"]
eduLevel = loadjson["eduLevel"]
job_detail = loadjson["job_detail"]
job_highlights = loadjson["job_highlights"]
job_skills = loadjson["job_skills"]
jobarea = loadjson["jobarea"]
jobname = loadjson["jobname"]
joburl = loadjson["joburl"]
plan = loadjson["plan"]
salary = loadjson["salary"]
welfare = loadjson["welfare"]
workingExp = loadjson["workingExp"]
template = {
"job_address": job_address,
"name": company_name,
"size": company_size,
"type": company_type,
"url": company_url,
"crawltime": crawltime,
"eduLevel": eduLevel,
"job_detail": job_detail,
"job_highlights": job_highlights,
"job_skills": job_skills,
"jobarea": jobarea,
"jobname": jobname,
"joburl": joburl,
"plan": plan,
"salary": salary,
"welfare": welfare,
"workingExp": workingExp
}
json.dump(template, f, ensure_ascii=False) #写入汉字
f.write('\n')
##打印并展示
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import json
df = pd.read_json('zlnew1.json', lines=True)
df.info
df[['workingExp','salary']].head(30)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号