
大文件分片上传
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<input type="file" class="file">
</body>
<script src="./spark-md5.min.js"></script>
<script src="./spark-md5Test.js"></script>
<script type="module">
const inpFile = document.querySelector('.file')
inpFile.onchange = async (e) => {
const file = e.target.files[0]
console.time('cutFile')
await cutFile(file)
console.timeEnd('cutFile')
console.log(file)
}
async function cutFile(file) {
const CHUNK_SIZE = 1 * 1024 * 1024
const chunkList = []
const chunkCount = Math.ceil(file.size / CHUNK_SIZE)
for (let i = 0; i <= chunkCount - 1; i++) {
const c = await createChunk(file, i, CHUNK_SIZE)
chunkList.push(c)
}
console.log(chunkList)
console.log(chunkCount)
}
</script>
</html>
async function createChunk(file, index, chunkSize) {
return new Promise(resolve => {
const start = index * chunkSize
const end = start + chunkSize
const blob = file.slice(start, end)
const spark = new SparkMD5.ArrayBuffer()
const fileReader = new FileReader()
fileReader.readAsArrayBuffer(blob)
fileReader.onload = (e) => {
spark.append(e.target.result)
resolve({
start,
end,
index,
spark:spark.end(),
blob,
})
}
})
}
直接分片进行上传,
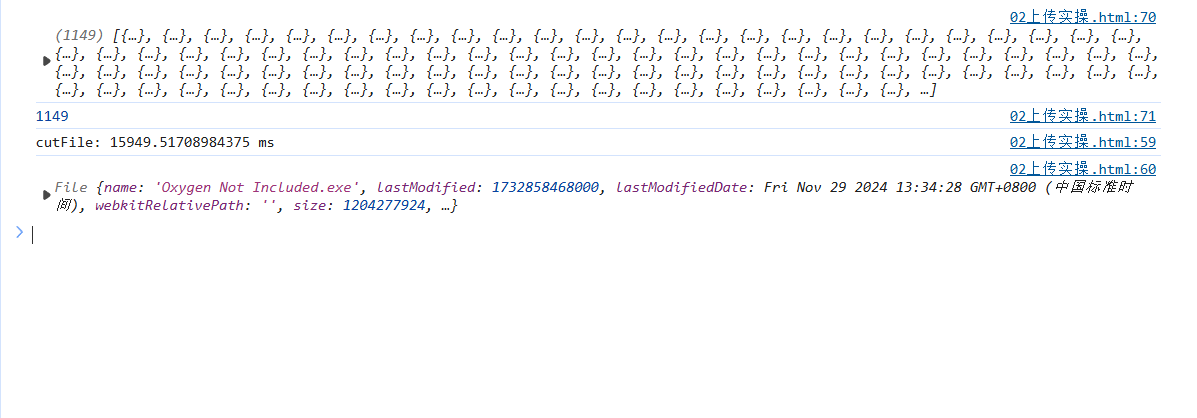
发现耗时长,将文件分片操作改成并发
async function cutFile(file) {
const CHUNK_SIZE = 1 * 1024 * 1024
const chunkList = []
const chunkCount = Math.ceil(file.size / CHUNK_SIZE)
for (let i = 0; i <= chunkCount - 1; i++) {
const c = createChunk(file, i, CHUNK_SIZE)
chunkList.push(c)
}
await Promise.all(chunkList)
console.log(chunkList)
console.log(chunkCount)
}
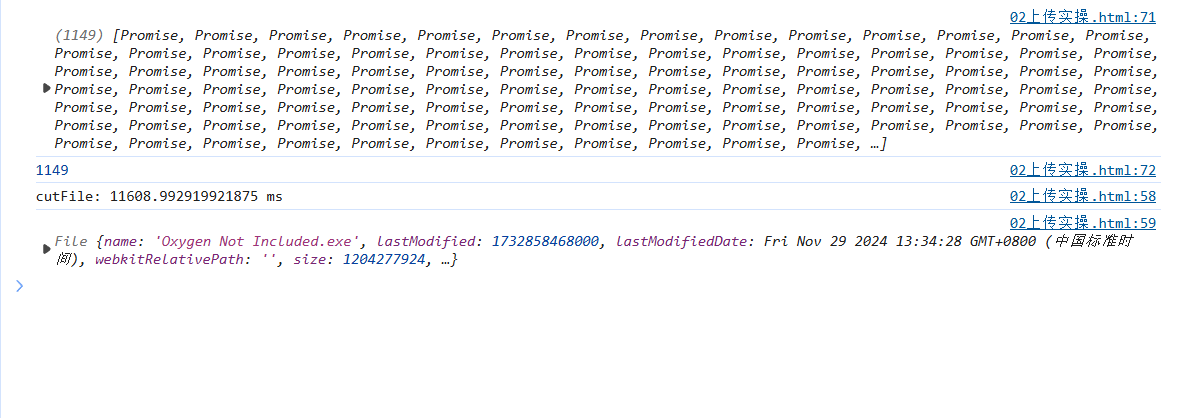
嗯。。。优化了3s,怎么不算优化呢
说明问题不在文件分片上,查阅资料发现,spark的计算是一个cpu密集型的操作任务,并发操作并没有什么作用,这个时候,就该开始多线程了
function cutFile(file) {
return new Promise(resolve => {
const CHUNK_SIZE = 1 * 1024 * 1024
const chunkList = []
const result = []
const THREAD_COUNT = navigator.hardwareConcurrency || 4
let finished = 0
const chunkCount = Math.ceil(file.size / CHUNK_SIZE)
const threadChunkCount = Math.ceil(chunkCount / THREAD_COUNT)
for (let i = 0; i <= THREAD_COUNT - 1; i++) {
const worker = new Worker('./work.js', {
type: 'module'
})
const start = i * threadChunkCount
const end = Math.min((i + 1) * threadChunkCount, chunkCount)
worker.postMessage({
file,
start,
end,
CHUNK_SIZE,
})
worker.onmessage = e => {
result[i] = e.data
worker.terminate()
finished++
if (finished === THREAD_COUNT) {
resolve(result.flat())
}
}
}
})
}
work.js文件
import { createChunk } from "./spark-md5Test.js"
onmessage = async (e) => {
const { file, start, end, CHUNK_SIZE } = e.data
const result = []
for (let i = start; i < end; i++) {
const c = createChunk(file, i, CHUNK_SIZE)
result.push(c)
}
const chunks = await Promise.all(result)
postMessage(chunks)
}
效果也是显著
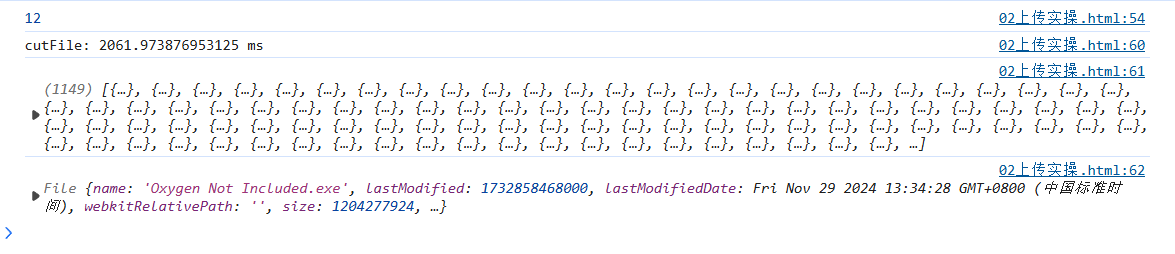
从16秒到11秒再到2秒,perfect!
遇到的问题:
1.对原生html中外部js文件的导入导出理解不透彻,如果要将js文件在其他js文件中导入,要在html中引入,并将其script标签type设置为module,在导入spark-md5.min.js文件时,使用vscode的自动补全,
import SparkMD5 from 'spark-md5'
然后问题一是spark-md5应该是路径的形式,二是该文件并不是使用导出的形式,内部是一个立即执行函数,查看网络上的资料,结果没有找到相似的问题,后面自己思索了一番,突然就想到了
import './spark-md5.min.js'
也是成功解决了这个问题
2.使用ai搜索原因,结果一直给我提供错误的思路,所以遇到问题还是要多思考,而不应该一昧把问题丢给ai

 浙公网安备 33010602011771号
浙公网安备 33010602011771号