2019寒假训练营寒假作业(三) 程序题部分
目录
文章状态:已完成!
# 热身题部分 ## *题目* - 1、安装虚拟机(可参考Vmware、Virtual Box等) - 2、安装ubuntu系统(推荐安装16.04版本) - 3、写一个helloworld程序,在ubuntu系统上编译运行(你可能需要了解linux系统的终端和一些基本命令、文本编辑工具nano、如何编译代码、运行程序)
### 作业实现 实验环境:VMware上的ubuntu系统 使用Linux指令创建main.c源代码: 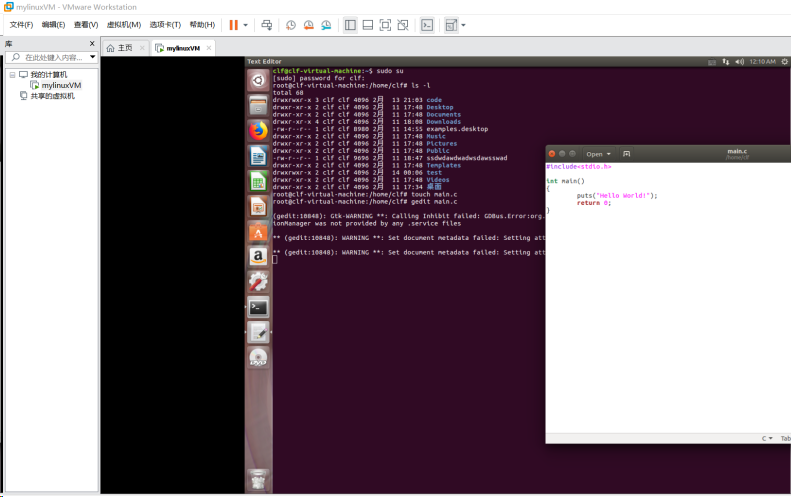 
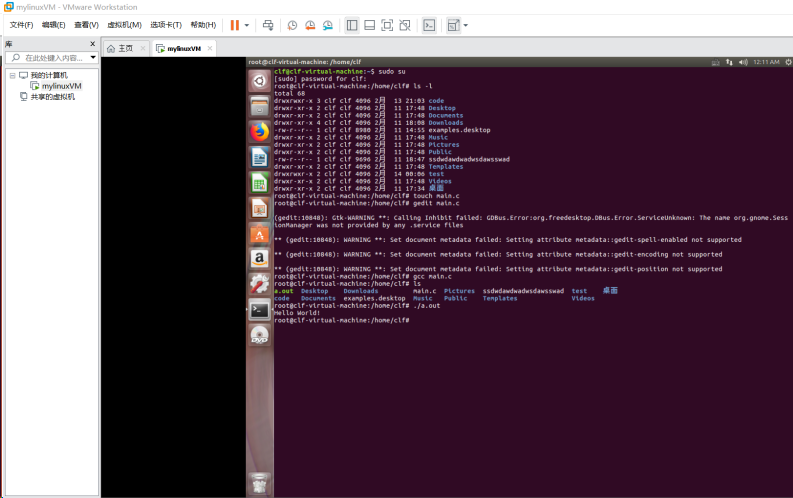
编译运行:

# 基本题
## *一、了解新技术*
众多sketch的技术中,Count-min sketch 常用也并不复杂,但你可能需要稍微了解一点点散列的知识。从它入手不失为一个好选择,把它记录在你的技术博客上:
- 1、简单描述什么是sketch
- 2、描述Count-min sketch的算法过程
### 作业实现 [理论题部分](https://www.cnblogs.com/fzu2018-clf-bky-blog/p/10391173.html) 代码:[测试时可跑通的代码](#测试时跑通的代码)【需要建立项目,手动输入请求,信息格式“
二、实现新技术
- 1、克隆一种版本(python或者c语言)的代码,大致了解如何使用这个代码,在ubuntu系统上编译。自己任意编写一个小测试,成功运行这个代码。
- 2、你也可以自己实现Count-min sketch。
作业实现
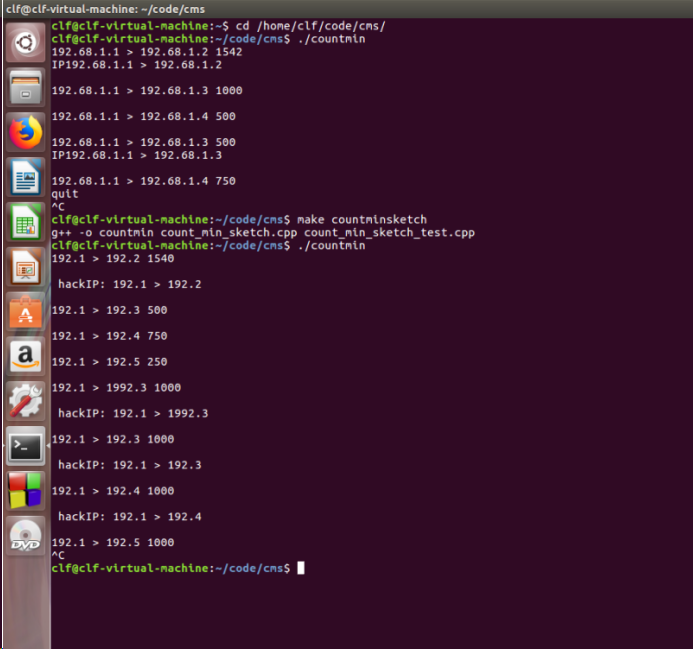
备注
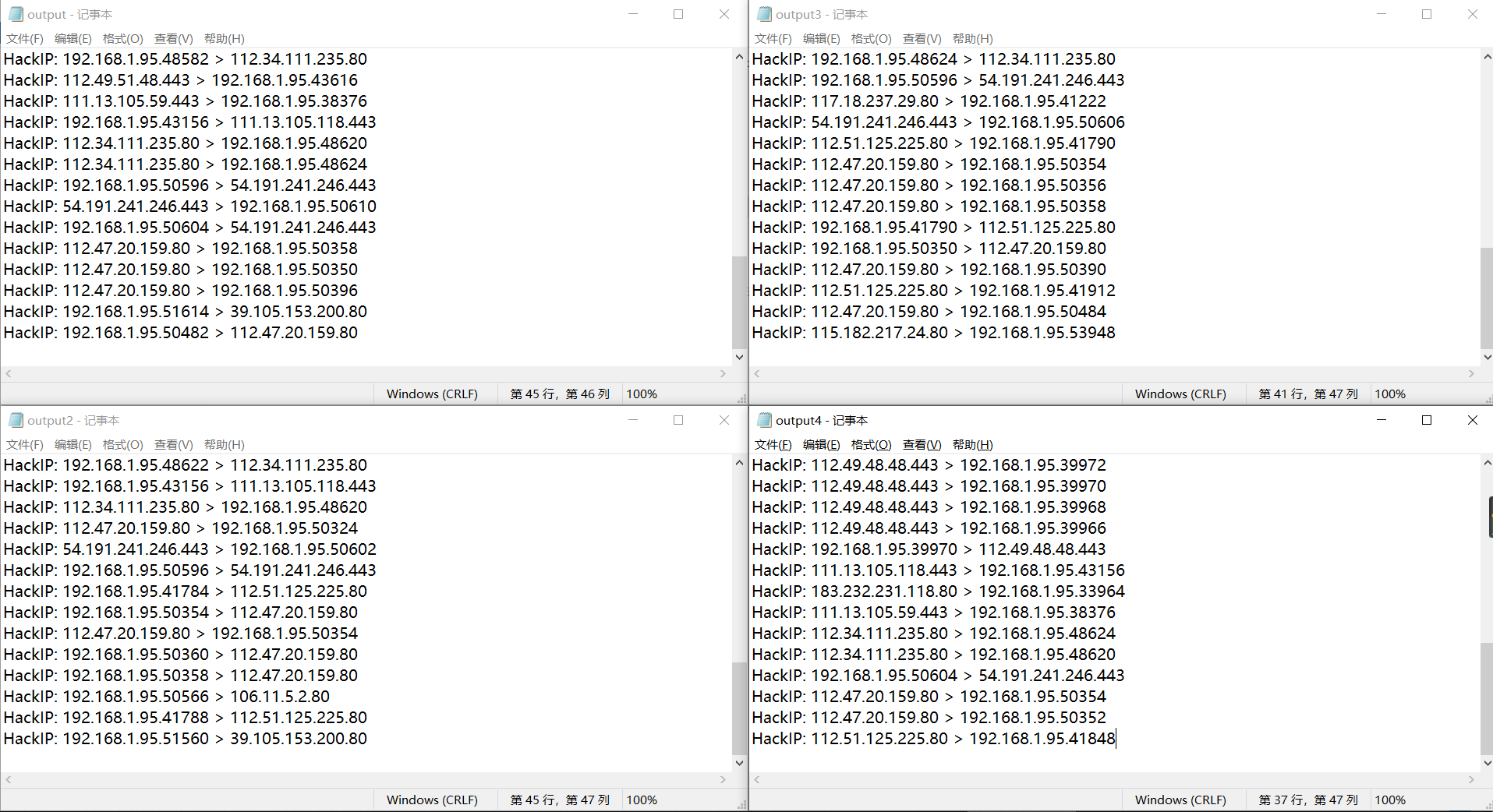
- 其中,上面的部分是修改以前的测试数据(“IPxxx格式”输出的即为超过阈值1500的);
- 下面的部分是改进以后的测试数据(“hackIP:xxx格式”输出的即为超过阈值1500的请求)。
- 为了方便起见,IP并未按照规范输入,但是也区分开了
- 可以看出,低频的数据是存在估计偏差的(而且其实还挺大的)
测试问题:
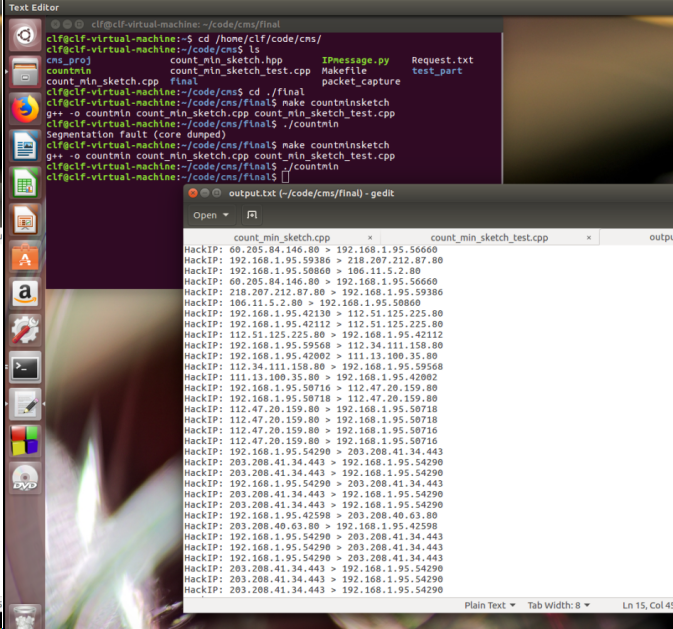
- 在windows上可以跑动,但是在虚拟机上出现Segmentation fault(core dumped)问题,一般是内存操作有误(例如数组越界,空指针解引用);
- 大数运算操作,最好分开;(调试了好久)
- 虚拟机会崩~(短暂性无响应状态,让它自己再运行一会儿就恢复了);
- 这个代码的原核心是C++我也是用C++修改和调试,测试部分自己用C重写,不知道可不可行。
## *三、获取用户请求*
- 1、安装并使用抓包工具tcpdump
- 2、输入tcpdump -n 获取数据包的信息
- 3、使用linux 重定向的方法把该信息用文本文件存起来,文件命名为 pakcet_capture.txt。
### 作业实现 抓取数据包并且重定向: 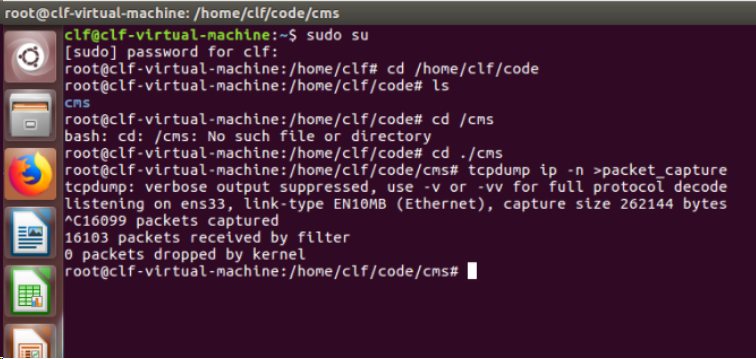 结果: 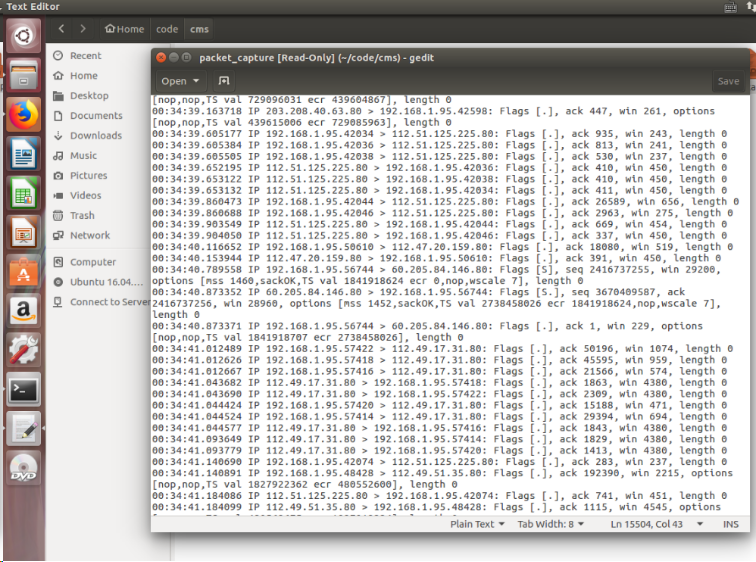
问题
- 1、直接tcpdump -n还会得到除了IP协议之外的数据包,例如arp协议,因此为了格式上的统一使用了tcpdump ip -n
- 2、ctrl+c才可以停止当前终端的运行并将数据重定向入文本文件中,否则使用”$ tcpdump ip -c + <需要抓取的数据包的数量>”,可以抓取指定数量的数据包
## *四、请求格式处理*
- 1、使用程序把第一条请求处理成第二条请求的格式
- 2、使用linux 重定向的方法把该信息用文本文件存起来,命名为Request.txt。
作业实现
IPmessage.py实现文件处理:
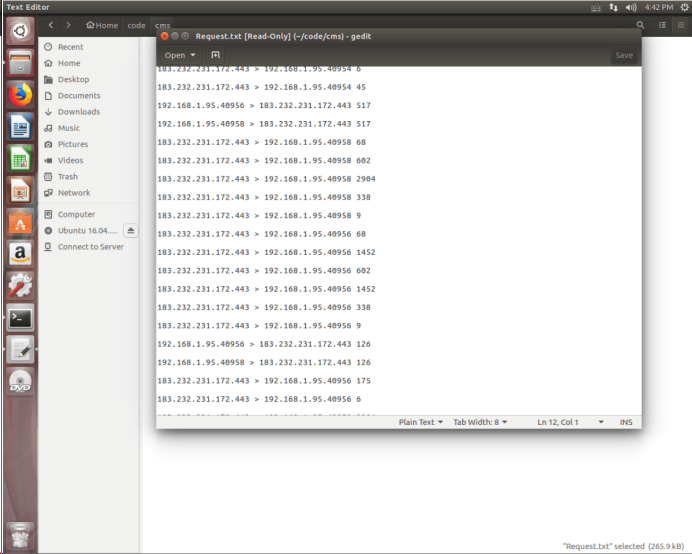
得到处理以后的Request文件:
代码:处理数据包格式的代码
各种问题
- 1、“request denied”,在unix/linux上若要直接运行.py文件:需要对.py文件添加特殊注释->执行权限
- 2、“syntax error near unexpected token ‘<字符>’ ”、“$'\r': command not found”等shell脚本执行问题,由windows文件某些字符与Unix文件格式不兼容造,需要转成unix格式:
安装dos2unix-> $ dos2unix <文件名> - 3、发现获取的IP传输数据包有的length为0,有的甚至不包含length(竟然是一堆网址和杂乱的字母?),因此在代码中过滤了这部分的信息,以减少后续的处理。
- 4、python的readlines()函数自带'\n',所以在判断最后一个数字是否是零的时候要考虑‘0\n’
## *五、测试新技术*
- 用跑通的Count-min sketch程序读文件,获得最后的处理结果,请求大小超过阈值T认定为黑客,此处T自己定义。
作业实现
windows实现:
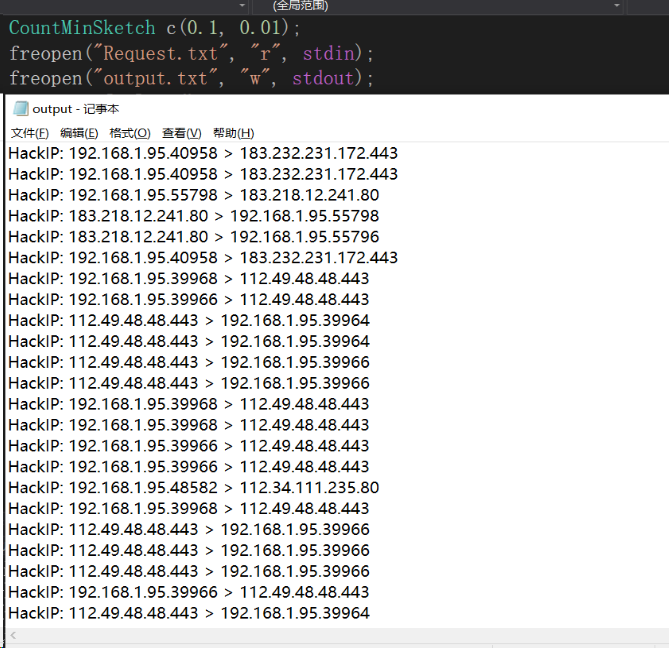
Ubuntu实现:
代码:最终代码
备注:
- 该实现的阈值T=1500
- 本次代码有多个文件:有packet_capture, Request, output三个文本文件,以及其他代码(包括测试代码和最终代码);
- 从由于是边存边算,所以实现该方法时,并未考虑对于重复IP的处理,所以如图所示,输出了多次相同HackIP;
- ubuntu实现中,有一次core dumped错误出现是因为,我不小心贴了没修改过的错误代码,后来重新链接编译了正确的代码才完成。
# 开放题
## 理论题部分
作业实现
## 实验题部分
作业实现
暂时有些个改进想法:
1、使用多线程能否会更快(这个靠现阶段的知识暂时不可能实现了,一个线程读,一个线程写);
2、参照上一次的“建立一个黑名单名录”,加速过滤。(这个还是可以实现的,但是开辟名单、查询名单也算是一部分开销吧)(二更:该点已实现)
3、边读边写,不必等它全部读完再写,算不算实时?还是说,可以模拟真实的网络流环境,原始数据“接收、处理、判断、拉黑”一条龙在线服务?实时的具体含义是什么暂时没搞懂。(后者可能可以通过tcpdump -n + 直接多次重定向,省略掉中间的packet_capture和Request文件的生成,直接实时性写入output.txt中)
实验部分:代码改进
对于第二点——达成了中间处理过程的精简但是容错率上升
代码:实现名单过滤的改进代码
无需另外开辟名单,直接利用hash函数检索,估计上一次是否超过阈值即可。
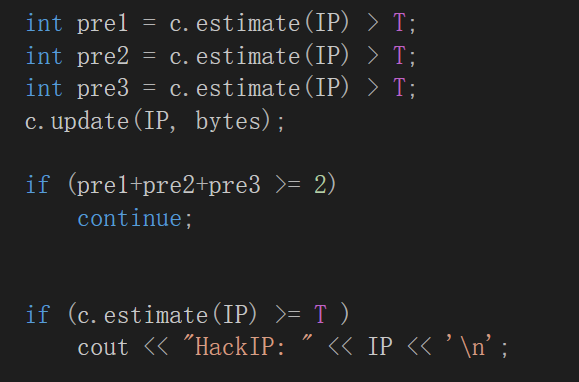
- 考虑到仅仅一次估测会出错,不妨取三次估测值,如果至少两次超过阈值,才会跳过该IP的输入,尽可能提高已经降低的容错率。如果增加前的估计已经超过阈值,那么考虑到接下来还会继续增加数据大小,绝大多数数据可以和估计的误差相抵消。(四次随机文件读取可以看出对于低频数据的误差依旧难以抵消)
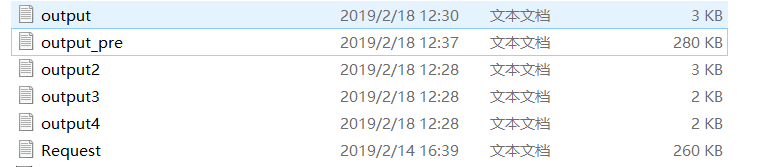
- 该点改进很重要,对比改进前后文件大小可以看出:之前数据重复写入的数量之多(output_pre是未改进的结果中文件,大小远远高出二次过滤以后的文件)。
# Github_address
github上使用的源文件
测试时跑通的代码
(需要手动输入,C++/C混编)
处理数据包格式
(python)
需要读取文件的代码
(只需要Request.txt文件即可,C++/C混编)
实现名单过滤的改进代码
文章状态:已完成! P.s. 若有各种其他问题,还望指教。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号