


第一次个人编程作业
github地址
PSP表格
| Planning | 计划 | 预计耗时 | 实际耗时 |
|---|---|---|---|
| Planning | 计划 | 60 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 60 |
| Development | 开发 | 200 | 300 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 1500+ |
| · Design Spec | · 生成设计文档 | 30 | 20 |
| · Design Review | · 设计复审 | 120 | 80 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 120 | 180 |
| · Coding | · 具体编码 | 300 | 430 |
| · Code Review | · 代码复审 | 60 | 80 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 30 | 30 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · | · 合计 | 1530 | 2880+ |
解题思路
一、思考
第一反应是调在线API,但是测试了下效果不尽人意,分割效果不好。
然后想着用正则,之前写爬虫时候学过。然后爬了国家统计局的数据保存为json,在运行过程中逐层匹配。
二、查找资料
python的正则、json库之前都用过,在github上找到一个已经爬完的json四级地址文件,下下来直接用
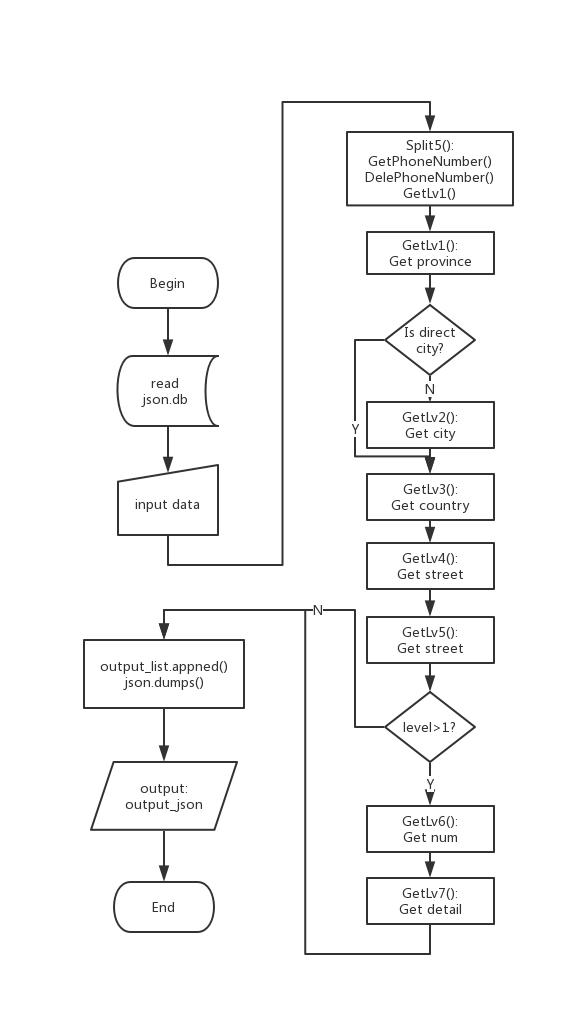
实现过程
主函数:
- 读入db.json文件,用json.loads转为list
- 读入文本,split()分段处理。对于每段,取第一个数字设为level,删除感叹号,逗号前设为名字,逗号后为地址,对于每段调用Split5()函数开始处理。
处理好的加入list里,最后调用json.dump()转成json,
GetPhoneNumber():
- 功能:用正则匹配手机号,返回手机号
DelePhoneNumber():
- 功能:用正则匹配手机号,从地址中删除手机号返回
Split5():
- 功能:提取手机号GetPhoneNumber(),删除手机号DelePhoneNumber(),返回手机号
- 调用GetLv1()获取省份信息
GetLv1():
- 功能:用字典提取省份信息
- 如果是直辖市,转到GetLv3()处理
- 如果是自治区,填充完整自治区名字,转到GetLv2()处理
- 如果是其他省,转到GetLv2()处理
GetLv2():
- 功能:用字典提取城市信息,补齐"市"字,转到GetLv3()处理
GetLv3():
- 功能:用字典提取区信息,转到GetLv4()处理
GetLv4():
- 功能:用字典提取街道信息,转到GetLv5()处理
GetLv5():
- 功能:用正则取街道信息,如果level>1,转到GetLv6()处理
GetLv6():
- 功能:用正则提取门牌号信息,转到GetLv7()处理
GetLv7():
- 功能:将剩余信息加入ret
流程图
函数接口

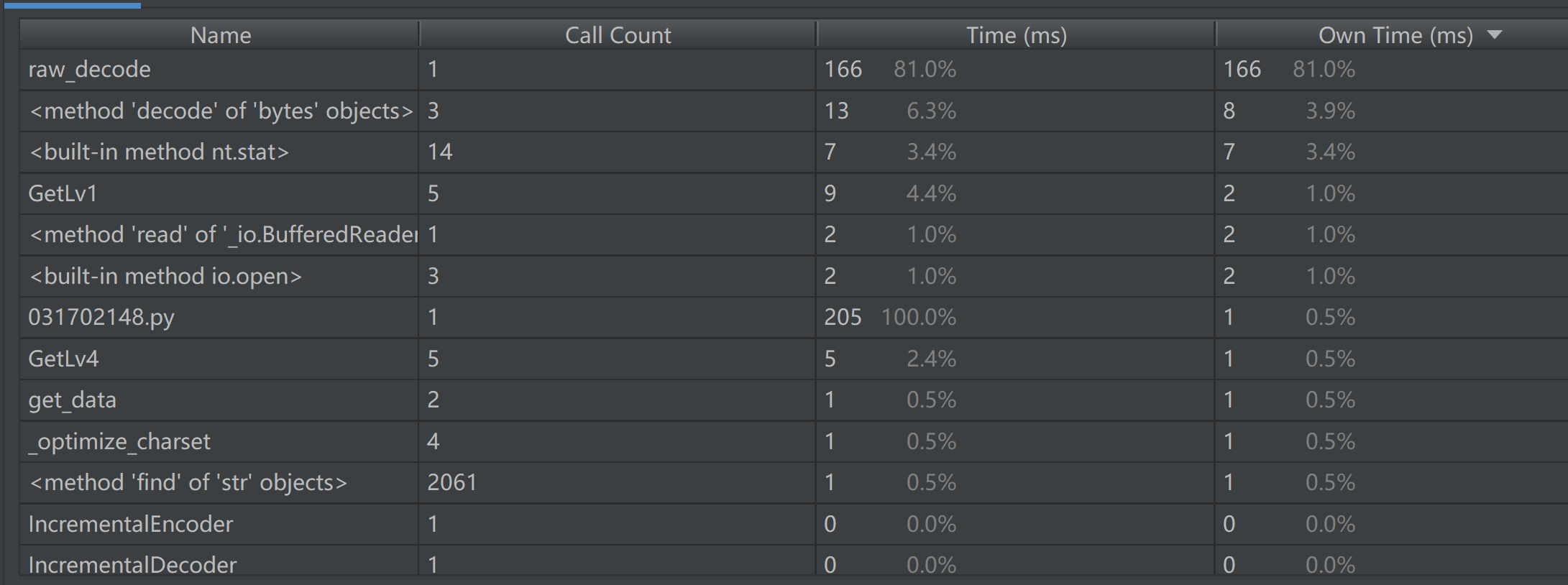
性能分析
使用Pycharm的profile功能进行性能分析 人生苦短我用Pycharm
整体效率自己还是挺满意的,主要花在json.loads上,测试5组数据Split5函数用时10ms,预计1000组数据用时2s
因为每次是把字典去匹配,每层最多20组 单条总复杂度预计也就O(7x30xlog30)
这也是相比正则直接匹配7级地址的优势吧

自行测试
第三级就没去做了,对于其他测试结果还是挺满意的,毕竟用字典匹配有天生优势,~还是怕博大精深就没了~
输入
2!李四,福建省福州13756899511市鼓楼区鼓西街道湖滨路110号湖滨大厦一层.
1!张三,福建福州闽13599622362侯县上街镇福州大学10#111.
2!王五,福建省福州市鼓楼18960221533区五一北路123号福州鼓楼医院.
3!小美,北京市东15822153326城区交道口东大街1号北京市东城区人民法院.
1!小陈,广东省东莞市凤岗13965231525镇凤平路13号.
异常处理
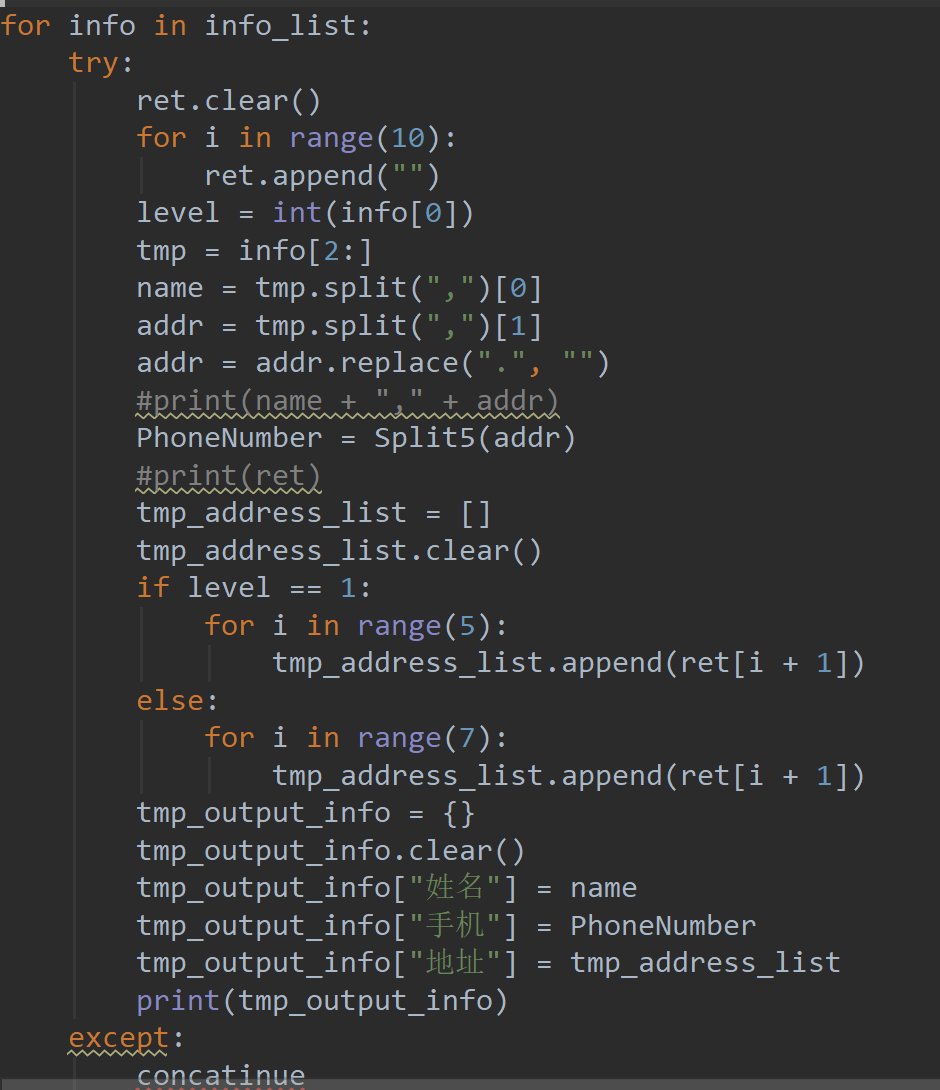
在主程序循环里,也有try...expcet...当前地址解析失败就continue
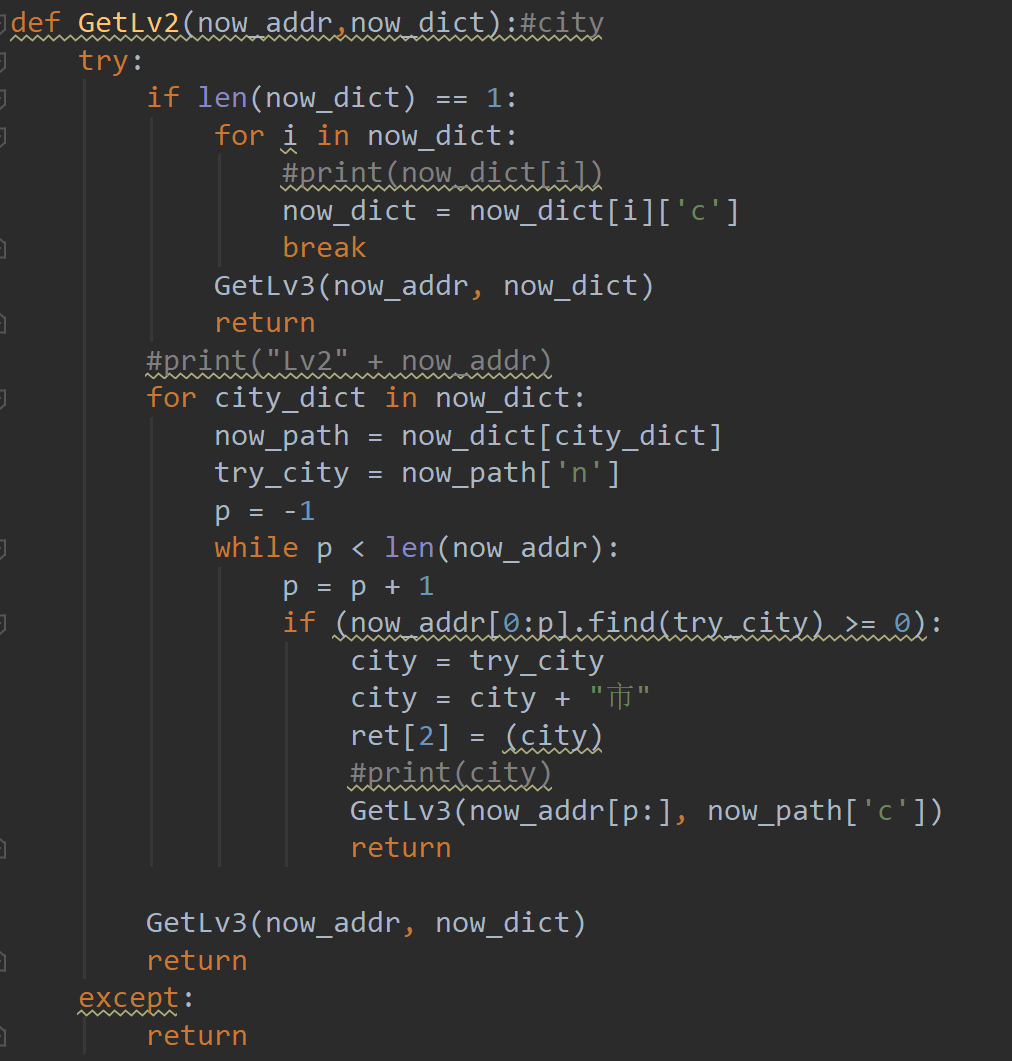
每一级解析(这里以lv2为例)都有异常捕获机制:try...except...
如果有异常,不继续向更深层级解析,而是返回直接输出
输出
[
{
"姓名": "李四",
"手机": "13756899511",
"地址": [
"福建省",
"福州市",
"鼓楼区",
"鼓西街道",
"湖滨路",
"110号",
"湖滨大厦一层"
]
},
{
"姓名": "张三",
"手机": "13599622362",
"地址": [
"福建省",
"福州市",
"闽侯县",
"上街镇",
"福州大学10#111"
]
},
{
"姓名": "王五",
"手机": "18960221533",
"地址": [
"福建省",
"福州市",
"鼓楼区",
"",
"五一北路",
"123号",
"福州鼓楼医院"
]
},
{
"姓名": "小美",
"手机": "15822153326",
"地址": [
"北京",
"北京市",
"东城区",
"交道口",
"东大街",
"1号",
"北京市东城区人民法院"
]
},
{
"姓名": "小陈",
"手机": "13965231525",
"地址": [
"广东省",
"东莞市",
"",
"凤岗镇",
"凤平路13号"
]
}
]
心路经历
中华文化博大精深
地址命名各领风骚
最开始骚操作一下,想用Trie树或者自动机做的,可中文字符集这么大...我认识的一位学长写过一篇:基于Aho-Corasick自动机中文分词,emmm....算了还是用正则吧
也是这次作业我才去了解到正则内部是DFA(确定有限状态自动机)
这次作业,挺多知识是以前学过的,比如json、正则的基本使用,但写的时候还是需要看材料。特别是正则的语法,运用还是不熟练。
按道理7级的地址匹配完全可以用一行正则写完,但学识疏浅,没办法做到,用了7个子函数,虽然代码长了点,但好调试 菜是原罪
Pycharm虽然好用,但太吃资源了,耗电也贼快,所幸内存没爆,16G内存用户感到一丝舒适
掐指一算这次作业好像做了30+小时???

 浙公网安备 33010602011771号
浙公网安备 33010602011771号