

实验5
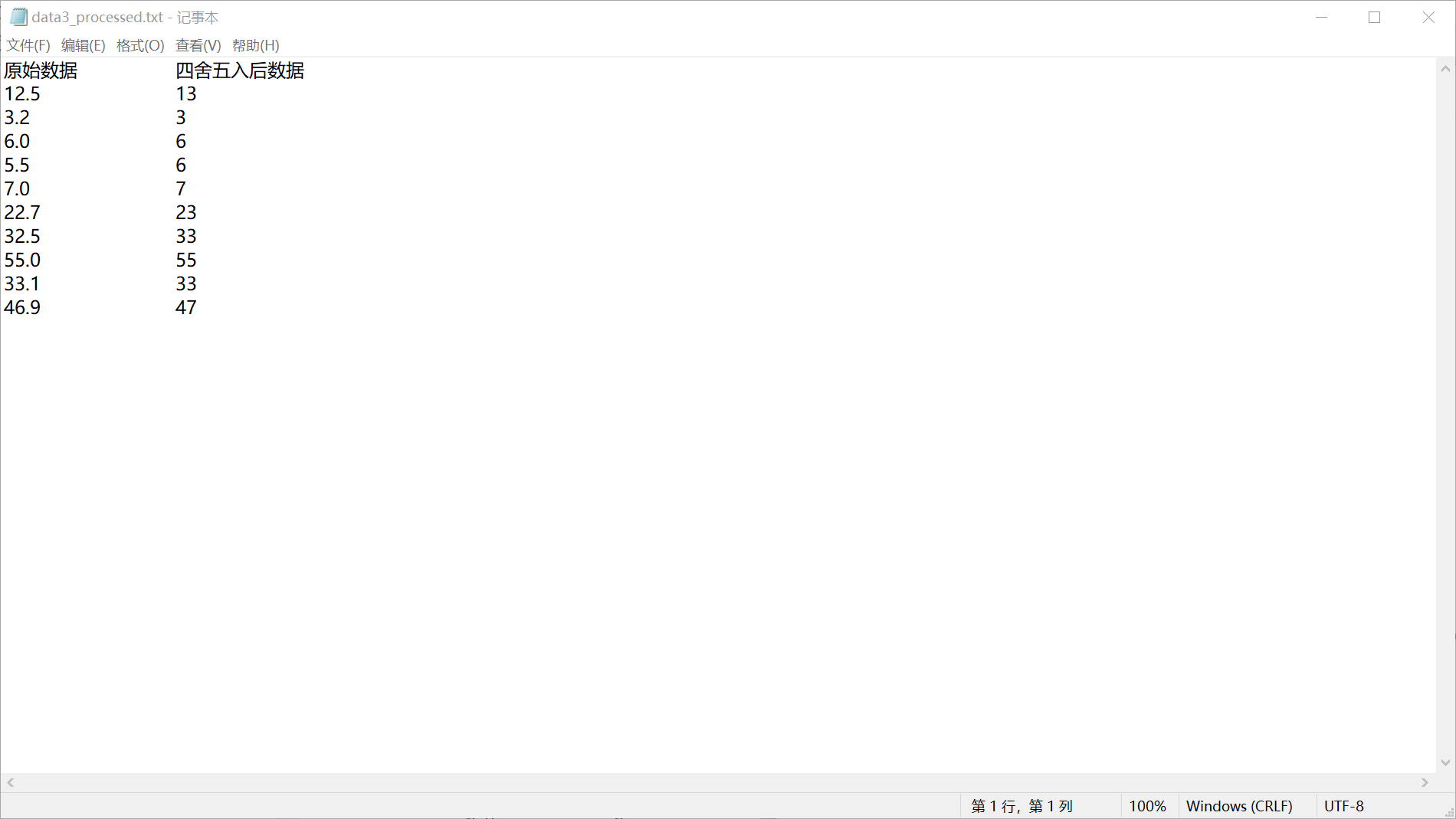
实验任务3 with open('data3.txt','r',encoding='utf-8')as f: data=f.read() with open('data3.txt','r',encoding='utf-8')as f: data1=f.readlines() data0=[line.split() for line in data1[1:]] data3=[float(line[0])for line in data0] print('原始数据:') print(data3) def myround(x): if(x-int(x)<0.5): return int(x) else: return int(x)+1 data2=[] for i in range(len(data3)): data2.append(myround(float(data3[i]))) print('四舍五入后数据:') print(data2) with open('data3_processed.txt','w',encoding='utf-8')as f: f.write('原始数据'+'\t'*2+'四舍五入后数据'+'\n') for i in range(len(data2)): f.write(str(data3[i])+'\t'*2+str(data2[i])+'\n')

实验任务4 with open('data4.txt','r',encoding='utf-8')as f: data=f.readlines() data0=[line.split()for line in data[1:]] for i in range(len(data0)): data0[i]=tuple(data0[i]) data1=sorted(data0,key=lambda x:(x[2],-int(x[3]))) data2=[] for i in range(len(data1)): data2.append(data1[i][0]+'\t'+data1[i][1]+'\t'+data1[i][2]+'\t'+data1[i][3]+'\n') print('学号'+'\t'+'姓名'+'\t'+'专业'+'\t'+'分数') print(''.join(data2)) with open('data4_processed.txt','w',encoding='utf-8')as f: f.write('学号'+'\t'+'姓名'+'\t'+'专业'+'\t'+'分数'+'\n') f.write(''.join(data2))


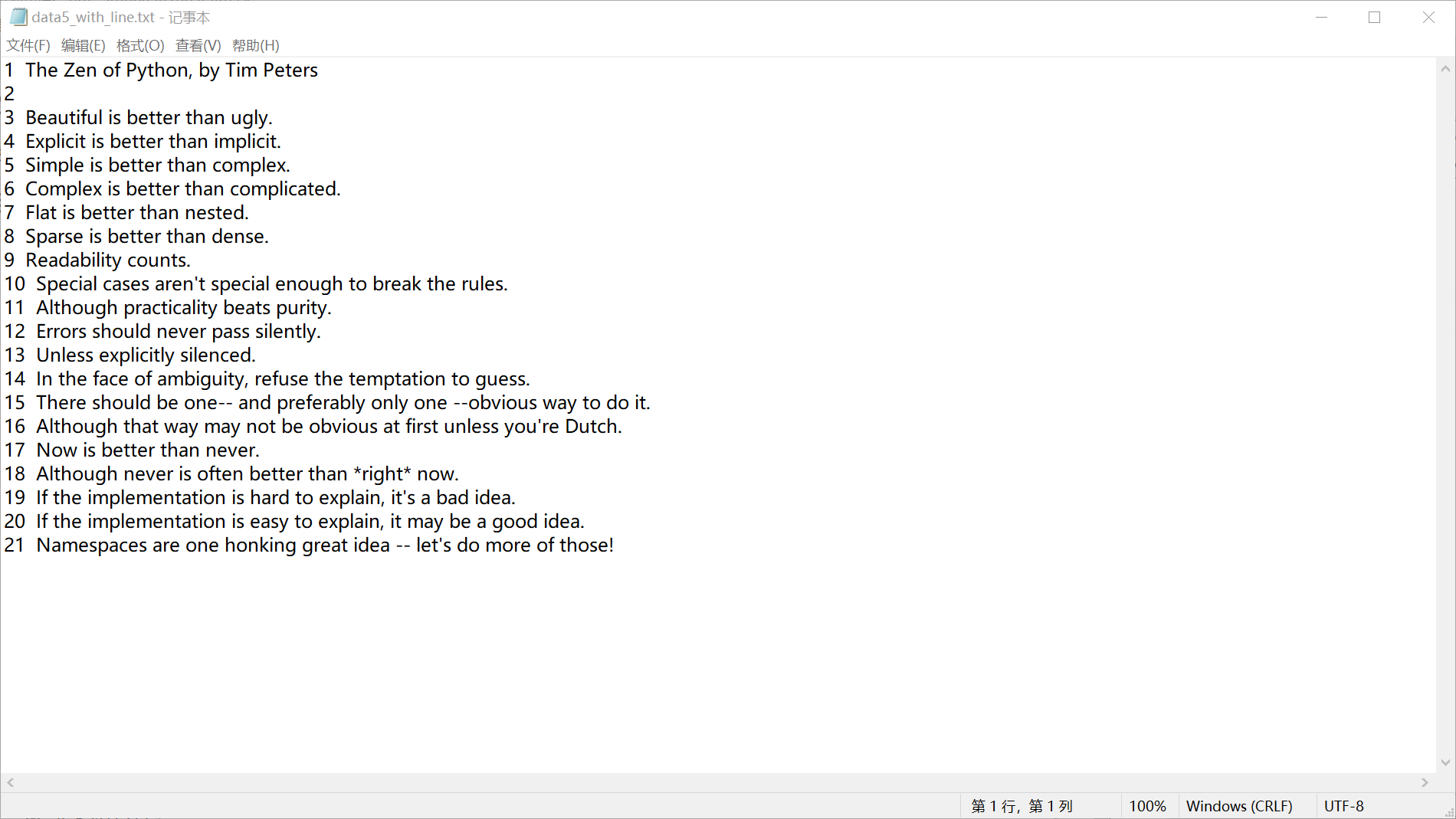
实验任务5 with open('data5.txt','r',encoding='utf-8')as f: text=f.read() l=text.splitlines() print('行数:'+str(len(l))) print('单词数:'+str(len(text.split()))) print('空格数:'+str(text.count(' '))) print('字符数:'+str(len(text))) with open('data5_with_line.txt','w',encoding='utf-8')as f: for i in range(len(l)): f.write(str(i+1)+' '+l[i]+'\n')

此次实验中,我进一步掌握了文件的内容,特别是第一次实践了lambda的用法,安装了everything。但是这也暴露出一些问题,比如在一些实验任务中我不能立即想到课上讲的相关知识点,下次我要多加注意。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号