论文解析 -- An Empirical Evaluation of In-Memory Multi-Version Concurrency Control
ABSTRACT
(点题)Multi-version concurrency control (MVCC) is currently the most popular transaction management scheme in modern database management systems (DBMSs).
(现状)Although MVCC was discovered in the late 1970s, it is used in almost every major relational DBMS released in the last decade.
Maintaining multiple versions of data potentially increases parallelism without sacrificing serializability when processing transactions.
(问题)But scaling MVCC in a multi-core and in-memory setting is non-trivial:
when there are a large number of threads running in parallel, the synchronization overhead can outweigh the benefits of multi-versioning.
(本文做了啥)To understand how MVCC perform when processing transactions in modern hardware settings,
we conduct an extensive study of the scheme’s four key design decisions: concurrency control protocol, version storage, garbage collection, and index management.
We implemented state-of-the-art variants of all of these in an in-memory DBMS and evaluated them using OLTP workloads.
Our analysis identifies the fundamental bottlenecks of each design choice.
INTRODUCTION
(引出mvcc,什么是mvcc,好处)Computer architecture advancements has led to the rise of multicore, in-memory DBMSs that employ efficient transaction management mechanisms to maximize parallelism without sacrificing serializability.
The most popular scheme used in DBMSs developed in the last decade is multi-version concurrency control (MVCC).
The basic idea of MVCC is that the DBMS maintains multiple physical versions of each logical object in the database to allow operations on the same object to proceed in parallel.
These objects can be at any granularity, but almost every MVCC DBMS uses tuples because it provides a good balance between parallelism versus the overhead of version tracking.
Multi-versioning allows read-only transactions to access older versions of tuples without preventing read-write transactions from simultaneously generating newer versions.
Contrast this with a single-version system where transactions always overwrite a tuple with new information whenever they update it.
(MVCC的历史和现状)What is interesting about this trend of recent DBMSs using MVCC is that the scheme is not new.
The first mention of it appeared in a 1979 dissertation [38] and the first implementation started in 1981 [22] for the InterBase DBMS (now open-sourced as Firebird).
MVCC is also used in some of the most widely deployed disk-oriented DBMSs today, including Oracle (since 1984 [4]), Postgres(since 1985 [41]), and MySQL’s InnoDB engine (since 2001).
But while there are plenty of contemporaries(同辈) to these older systems that use a single-version scheme (e.g., IBM DB2, Sybase), almost every new transactional DBMS eschews(避开) this approach in favor of MVCC [37].
This includes both commercial (e.g., Microsoft Hekaton [16], SAP HANA [40], MemSQL [1], NuoDB [3]) and academic (e.g., HYRISE [21], HyPer [36]) systems.
(为何要研究,研究了什么)Despite all these newer systems using MVCC, there is no one “standard” implementation. There are several design choices that have different trade-offs and performance behaviors.
Until now, there has not been a comprehensive evaluation of MVCC in a modern DBMS operating environment.
The last extensive study was in the 1980s [13], but it used simulated workloads running in a disk-oriented DBMS with a single CPU core.
The design choices of legacy disk-oriented DBMSs are inappropriate for in-memory DBMSs running on a machine with a large number of CPU cores.
As such, this previous work does not reflect recent trends in latch-free[27] and serializable [20] concurrency control, as well as in-memory storage [36] and hybrid workloads [40].
In this paper, we perform such a study for key transaction management design decisions in of MVCC DBMSs:
(1) concurrency control protocol, (2) version storage, (3) garbage collection, and (4) index management.
For each of these topics, we describe the state-of-the-art implementations for in-memory DBMSs and discuss their trade-offs.
We also highlight the issues that prevent them from scaling to support larger thread counts and more complex workloads.
As part of this investigation, we implemented all of the approaches in the Peloton [5] in-memory MVCC DBMS.
This provides us with a uniform platform to compare implementations that is not encumbered(妨碍) by other architecture facets.
We deployed Peloton on a machine with 40 cores and evaluate it using two OLTP benchmarks.
Our analysis identifies the scenarios that stress the implementations and discuss ways to mitigate them (if it all possible).
这篇introduction的内容就是abstract的放大版,内容接近,很工整
BACKGROUND
We first provide an overview of the high-level concepts of MVCC.
We then discuss the meta-data that the DBMS uses to track transactions and maintain versioning information
MVCC Overview
A transaction management scheme permits end-users to access a database in a multi-programmed fashion while preserving the illusion(错觉) that each of them is executing alone on a dedicated system [9].
It ensures the atomicity and isolation guarantees of the DBMS.
(MVCC的好处,高并发,time-travel)There are several advantages of a multi-version system that are relevant to modern database applications.
Foremost is that it can potentially allow for greater concurrency than a single-version system.
For example, a MVCC DBMS allows a transaction to read an older version of an object at the same time that another transaction updates that same object.
This is important in that execute read-only queries on the database at the same time that read-write transactions continue to update it.
If the DBMS never removes old versions, then the system can also support “time-travel” operations that allow an application to query a consistent snapshot of the database as it existed at some point of time in the past [8].
(MVCC的实现各不相同,所以需要研究和甄别)The above benefits have made MVCC the most popular choice for new DBMS implemented in recent years.
Table 1 provides a summary of the MVCC implementations from the last three decades.
But there are different ways to implement multi-versioning in a DBMS that each creates additional computation and storage overhead.
These design decisions are also highly dependent on each other.
Thus, it is non-trivial to discern(distinguish) which ones are better than others and why.
This is especially true for in-memory DBMSs where disk is no longer the main bottleneck.

In the following sections, we discuss the implementation issues and performance trade-offs of these design decisions.
We then perform a comprehensive evaluation of them in Sect. 7.
We note that we only consider serializable transaction execution in this paper.
Although logging and recovery is another important aspect of a DBMS’s architecture,
we exclude it from our study because there is nothing about it that is different from a single-version system and in-memory DBMS logging is already covered elsewhere [33, 49].
DBMS MetaData
(讨论一些公关的meta,无论何种实现都会有这些meta)Regardless of its implementation, there is common meta-data that a MVCC DBMS maintains for transactions and database tuples.
Transactions: The DBMS assigns a transaction T a unique, monotonically increasing timestamp as its identifier (Tid) when they first enter the system.
The concurrency control protocols use this identifier to mark the tuple versions that a transaction accesses. Some protocols also use it for the serialization order of transactions.
Tuples: As shown in Fig. 1, each physical version contains four meta-data fields in its header that the DBMS uses to
coordinate the execution of concurrent transactions (some of the concurrency control protocols discussed in the next section include additional fields).

The txn-id field serves as the version’s write lock. Every tuple has this field set to zero when the tuple is not write-locked.
Most DBMSs use a 64-bit txn-id so that it can use a single compareand-swap (CaS) instruction to atomically update the value.
If a transaction T with identifier Tid wants to update a tuple A, then the DBMS checks whether A’s txn-id field is zero.
If it is, then DBMS will set the value of txn-id to Tid using a CaS instruction [27, 44]. Any transaction that attempts to update A is aborted if this txn-id field is neither zero or not equal to its Tid .
The next two meta-data fields are the begin-ts and end-ts timestamps that represent the lifetime of the tuple version.
Both fields are initially set to zero. The DBMS sets a tuple’s begin-ts to INF when the transaction deletes it.
The last meta-data field is the pointer that stores the address of the neighboring (previous or next) version (if any).
CONCURRENCYCONTROLPROTOCOL
Every DBMS includes a concurrency control protocol that coordinates the execution of concurrent transactions [11].
(并发控制什么,能不能读写,能不能提交)This protocol determines (1) whether to allow a transaction to access or modify a particular tuple version in the database at runtime,
and (2) whether to allow a transaction to commit its modifications.
Although the fundamentals of these protocols remain unchanged since the 1980s, their performance characteristics have changed drastically in a multi-core and main-memory setting due to the absence of disk operations [42].
As such, there are newer high-performance variants that remove locks/latches and centralized data structures, and are optimized for byte-addressable storage.
In this section, we describe the four core concurrency control protocols for MVCC DBMSs.
We only consider protocols that use tuple-level locking as this is sufficient to ensure serializable execution.
(MVCC的局限,如果需要serializable,需要特殊的机制保障)We omit range queries because multi-versioning does not bring any benefits to phantom prevention [17].
Existing approaches to provide serializable transaction processing use either (1) additional latches in the index [35, 44] or (2) extra validation steps when transactions commit [27].
Timestamp Ordering (MVTO)
The MVTO algorithm from 1979 is considered to be the original multi-version concurrency control protocol [38, 39].
The crux(key) of this approach is to use the transactions’ identifiers (Tid) to precompute their serialization order. (悲观锁)
(增加meta,read-ts)In addition to the fields described in Sect. 2.2, the version headers also contain the identifier of the last transaction that read it (read-ts).
The DBMS aborts a transaction that attempts to read or update a version whose write lock is held by another transaction.
When transaction T invokes a read operation on logical tuple A, the DBMS searches for a physical version where Tid is in between the range of the begin-ts and end-ts fields.
As shown in Fig. 2a, T is allowed to read version Ax if its write lock is not held by another active transaction (i.e., value of txn-id is zero or equal to Tid) because MVTO never allows a transaction to read uncommitted versions.

Upon reading Ax, the DBMS sets Ax’s read-ts field to Tid if its current value is less than Tid . Otherwise, the transaction reads an older version without updating this field.
With MVTO, a transaction always updates the latest version of a tuple.
Transaction T creates a new version Bx+1 if (1) no active transaction holds Bx’s write lock and (2) Tid is larger than Bx’s read-ts field.
If these conditions are satisfied, then the DBMS creates a new version Bx+1 and sets its txn-id to Tid .
When T commits, the DBMS sets Bx+1’s begin-ts and end-ts fields to Tid and INF (respectively), and Bx’s end-ts field to Tid .
Optimistic Concurrency Control (MVOCC)
The next protocol is based on the optimistic concurrency control (OCC) scheme proposed in 1981 [26]. (乐观锁)
The motivation behind OCC is that the DBMS assumes that transactions are unlikely to conflict, and thus a transaction does not have to acquire locks on tuples when it reads or updates them.
This reduces the amount of time that a transaction holds locks. There are changes to the original OCC protocol to adapt it for multi-versioning [27].
Foremost(First) is that the DBMS does not maintain a private workspace for transactions, since the tuples’ versioning information already prevents transactions from reading or updating versions that should not be visible to them.
The MVOCC protocol splits a transaction into three phases.
When the transaction starts, it is in the read phase.
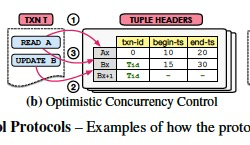
This is where the transaction invokes read and update operations on the database. Like MVTO, to perform a read operation on a tuple A, the DBMS first searches for a visible version Ax based on begin-ts and end-ts fields.
T is allowed to update version Ax if its write lock is not acquired.
In a multi-version setting, if the transaction updates version Bx, then the DBMS creates version Bx+1 with its txn-id set to Tid .
When a transaction instructs the DBMS that it wants to commit, it then enters the validation phase.
First, the DBMS assigns the transaction another timestamp (Tcommit) to determine the serialization order of transactions.
The DBMS then determines whether the tuples in the transaction’s read set was updated by a transaction that already committed.
If the transaction passes these checks, it then enters the write phase where the DBMS installs all the new versions and sets their begin-ts to Tcommit and end-ts to INF.
Transactions can only update the latest version of a tuple.
But a transaction cannot read a new version until the other transaction that created it commits.
A transaction that reads an outdated version will only find out that it should abort in the validation phase.
Two-phase Locking (MV2PL)
This protocol uses the two-phase locking (2PL) method [11] to guarantee the transaction serializability.
Every transaction acquires the proper lock on the current version of logical tuple before it is allowed to read or modify it.
In a disk-based DBMS, locks are stored separately from tuples so that they are never swapped to disk.
This separation is unnecessary in an in-memory DBMS, thus with MV2PL the locks are embedded in the tuple headers. (和传统的锁的不同,锁本身嵌入在tuple header中)
The tuple’s write lock is the txn-id field.
(增加Meta,read-cnt作为读锁)For the read lock, the DBMS uses a read-cnt field to count the number of active transactions that have read the tuple.
Although it is not necessary, the DBMS can pack txn-id and read-cnt into contiguous 64-bit word so that the DBMS can use a single CaS to update them at the same time.
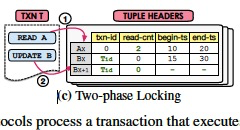
(读操作,写锁为0,读锁加1)To perform a read operation on a tuple A, the DBMS searches for a visible version by comparing a transaction’s Tid with the tuples’ begin-ts field.
If it finds a valid version, then the DBMS increments that tuple’s read-cnt field if its txn-id field is equal to zero (meaning that no other transaction holds the write lock).
(写操作,读写锁都为0)Similarly, a transaction is allowed to update a version Bx only if both read-cnt and txn-id are set to zero.
(commit操作,设置Tcommit,释放锁)When a transaction commits, the DBMS assigns it a unique timestamp (Tcommit) that is used to update the begin-ts field for the versions created by that transaction and then releases all of the transaction’s locks.
(死锁的处理)The key difference among 2PL protocols is in how they handle deadlocks.
Previous research has shown that the no-wait policy [9] is the most scalable deadlock prevention technique [48].
With this, the DBMS immediately aborts a transaction if it is unable to acquire a lock on a tuple (as opposed to waiting to see whether the lock is released).
Since transactions never wait, the DBMS does not have to employ a background thread to detect and break deadlocks.
Serialization Certifier
In this last protocol, the DBMS maintains a serialization graph for detecting and removing “dangerous structures” formed by concurrent transactions [12, 20, 45].
One can employ certifier-based approaches on top of weaker isolation levels that offer better performance but allow certain anomalies. (在弱的隔离级别上,加上certifier来保障serializable)
The first certifier proposed was serializable snapshot isolation (SSI) [12]; this approach guarantees serializability by avoiding write-skew anomalies for snapshot isolation.
Snapshot Isolation,来自于paper “ A Critique of ANSI SQL Isolation Levels ”,由于便于理解和实现,通过mvcc,所以大部分数据库会用于替代Serializable Isolation。
但是SI会有write skew问题,这个名字起的比较tricky,意思其实是,你完成读,计算,写入这个过程时,由于读的值被其他事务改变,导致写回的值是不正确的
SSI用于解决这个问题,“Serializable Isolation for Snapshot Databases”,文中给的例子是,更新医生的工作状态
但是有个约束是每个shift,至少有一个医生是ready的,不能都reserve
所以在SI级别下,如果同时有两个医生执行下面的sql,并且此时系统中只有两个医生是reserve,那么是会执行成功的,因为这两个sql修改的不是同一个object,不构成冲突
但是却违反了约束,破坏了serializable

SSI uses a transaction’s identifier to search for a visible version of a tuple. A transaction can update a version only if the tuple’s txn-id field is set to zero.
To ensure serializability, the DBMS tracks anti-dependency edges in its internal graph; these occur when a transaction creates a new version of a tuple where its previous version was read by another transaction.(该事务创新新版本,同时老版本被其他事务读到)
The DBMS maintains flags for each transaction that keeps track of the number of in-bound and out-bound anti-dependency edges.
When the DBMS detects two consecutive(连续的) anti-dependency edges between transactions, it aborts one of them. (SSI的原理,当存在连续的反向依赖边的时候,就abort其中的一个事务,会有误杀,如果充分必要的需要判断是否有环,这个代价太高)
The serial safety net (SSN) is a newer certifier-based protocol [45].
Unlike with SSI, which is only applicable to snapshot isolation, SSN works with any isolation level that is at least as strong as READ COMMITTED. (可以用于RC以上的所有隔离级别)
It also uses a more more precise anomaly detection mechanism that reduces the number of unnecessary aborts.
SSN encodes the transaction dependency information into metadata fields and validates a transaction T’s consistency by computing a low watermark that summarizes “dangerous” transactions that committed before the T but must be serialized after T [45].
Reducing the number of false aborts makes SSN more amenable to workloads with read-only or read-mostly transactions.
Discussion
(简单总结)These protocols handle conflicts differently, and thus are better for some workloads more than others.
MV2PL records reads with its read lock for each version. Hence, a transaction performing a read/write on a tuple version will cause another transaction to abort if it attempts to do the same thing on that version.
MVTO instead uses the read-ts field to record reads on each version.
MVOCC does not update any fields on a tuple’s version header during read/operations.
This avoids unnecessary coordination between threads, and a transaction reading one version will not lead to an abort other transactions that update the same version.
But MVOCC requires the DBMS to examine a transaction’s read set to validate the correctness of that transaction’s read operations.
This can cause starvation of long-running read-only transactions [24].
Certifier protocols reduce aborts because they do not validate reads, but their anti-dependency checking scheme may bring additional overheads.
(一些优化,但是都会导致级联abort,并且需要维护额外的数据结构记录事务间的依赖关系,会成为性能瓶颈)
There are some proposals for optimizing the above protocols to improve their efficacy for MVCC DBMSs [10, 27].
One approach is to allow a transaction to speculatively(投机) read uncommitted versions created by other transactions.
The trade-off is that the protocols must track the transactions’ read dependencies to guarantee serializable ordering.
Each worker thread maintains a dependency counter of the number of transactions that it read their uncommitted data.
A transaction is allowed to commit only when its dependency counter is zero, whereupon(于是) the DBMS traverses its dependency list and decrements the counters for all the transactions that are waiting for it to finish.
Similarly, another optimization mechanism is to allow transactions to eagerly update versions that are read by uncommitted transactions.
This optimization also requires the DBMS to maintain a centralized data structure to track the dependencies between transactions.
A transaction can commit only when all of the transactions that it depends on have committed.
Both optimizations described above can reduce the number of unnecessary aborts for some workloads, but they also suffer from cascading aborts.
Moreover, we find that the maintenance of a centralized data structure can become a major performance bottleneck, which prevents the DBMS from scaling towards dozens of cores.
VERSION STORAGE
Under MVCC, the DBMS always constructs a new physical version of a tuple when a transaction updates it.
The DBMS’s version storage scheme specifies how the system stores these versions and what information each version contains.
The DBMS uses the tuples’ pointer field to create a latch-free linked list called a version chain.
This version chain allows the DBMS to locate the desired version of a tuple that is visible to a transaction.
As we discuss below, the chain’s HEAD is either the newest or oldest version.
We now describe these schemes in more detail.
Our discussion focuses on the schemes’ trade-offs for UPDATE operations because this is where the DBMS handles versioning.
A DBMS inserts new tuples into a table without having to update other versions.
Likewise(also, in addition, besides, furthermore, moreover), a DBMS deletes tuples by setting a flag in the current version’s begin-ts field.
In subsequent sections, we will discuss the implications(隐含的) of these storage schemes on how the DBMS performs garbage collection and how it maintains pointers in indexes.
Append-only Storage
(多版本放在一张主表内,直接的mvcc方式,偏利于AP,问题就是主表会膨胀)
In this first scheme, all of the tuple versions for a table are stored in the same storage space.
This approach is used in Postgres, as well as in-memory DBMSs like Hekaton, NuoDB, and MemSQL.
To update an existing tuple, the DBMS first acquires(obtain, get, gain) an empty slot from the table for the new tuple version.
It then copies the content of the current version to the new version.
Finally, it applies the modifications to the tuple in the newly allocated version slot.
The key(fundamental, basic, essential, prime, cardinal) decision with the append-only scheme is how the DBMS orders the tuples’ version chains.
Since it is not possible to maintain a latch-free doubly linked list, the version chain only points in one direction. (只能单向,否则无法latch free,因为改两个指针就有原子性问题)
This ordering has implications on how often the DBMS updates indexes whenever transactions modify tuples.
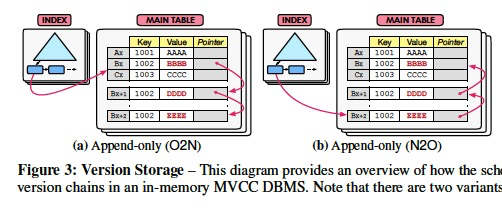
Oldest-to-Newest (O2N): With this ordering, the chain’s HEAD is the oldest extant version of a tuple (see Fig. 3a). (O2N,好处Head指针不会变化,但查最新的数据需要pointer chasing)
This version might not be visible to any active transaction but the DBMS has yet to reclaim it.
The advantage(merit, virtue, strong point) of O2N is that the DBMS need not update the indexes to point to a newer version of the tuple whenever it is modified.
But the DBMS potentially traverses a long version chain to find the latest version during query processing.
This is slow because of pointer chasing and it pollutes CPU caches by reading unneeded versions.
Thus, achieving good performance with O2N is highly dependent on the system’s ability to prune old versions.
Newest-to-Oldest (N2O): The alternative is to store the newest version of the tuple as the version chain’s HEAD (see Fig. 3b). (N2O,每次更新都会改变head指针,导致所有用到的地方都需要改,优化方法就是用逻辑指针,维护一个逻辑到物理的map,每次只需要改map)
Since most transactions access the latest version of a tuple, the DBMS does not have to traverse the chain.
The downside(drawback, malady, disadvantage,malpractice), however, is that the chain’s HEAD changes whenever a tuple is modified.
The DBMS then updates all of the table’s indexes (both primary and secondary) to point to the new version.
As we discuss in Sect. 6.1, one can avoid this problem through an indirection layer that provides a single location that maps the tuple’s latest version to physical address.
With this setup, the indexes point to tuples’ mapping entry instead of their physical locations.
This works well for tables with many secondary indexes but increases the storage overhead.
Another issue with append-only storage is how to deal with noninline attributes (e.g., BLOBs). (noninline的问题,这个的解决很直觉,用reference指向同一个object,避免反复copy)
Consider a table that has two attributes (one integer, one BLOB).
When a transaction updates a tuple in this table, under the append-only scheme the DBMS creates a copy of the BLOB attributes (even if the transaction did not modify it), and then the new version will point to this copy.
This is wasteful because it creates redundant copies.
To avoid this problem, one optimization is to allow the multiple physical versions of the same tuple to point to the same non-inline data.
The DBMS maintains reference counters for this data to ensure that values are deleted only when they are no longer referenced by any version.
Time-Travel Storage
(主表只放最新的数据,历史版本放在另一张time-travel表中,这个比较便于传统的本身不支持mvcc数据库,增加mvcc特性,比如SQL Server。好处,适合TP,主表和原先没有变化,不会膨胀,需要多版本的时候再去回溯time-travel表)
The next storage scheme(program, plan, proposal) is similar to the append-only approach except that the older versions are stored in a separate table.
The DBMS maintain a master version of each tuple in the main table and multiple versions of the same tuple in a separate time-travel table.
In some DBMSs, like SQL Server, the master version is the current version of the tuple.
Other systems, like SAP HANA, store the oldest version of a tuple as the master version to provide snapshot isolation [29]. (Hana这个比较奇葩,把最老的数据放在主表中)
This incurs additional maintenance costs during GC because the DBMS copies the data from the time-travel table back to the main table when it prunes the current master version.
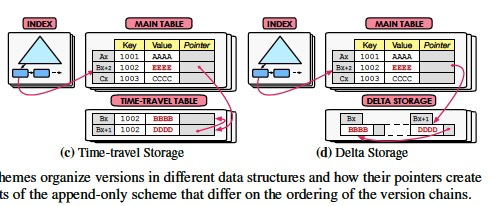
For simplicity, we only consider the first time-travel approach where the master version is always in the main table.
To update a tuple, the DBMS first acquires a slot in the time-travel table and then copies the master version to this location.
It then modifies the master version stored in the main table.
Indexes are not affected by version chain updates because they always point to the master version.
As such(因此), it avoids the overhead of maintaining the database’s indexes whenever a transaction updates a tuple and is ideal for queries that access the current version of a tuple.
This scheme also suffers from the same non-inline attribute problem as the append-only approach.
The data sharing optimization that we describe above is applicable here as well.
Delta Storage
(其实就是Time travel的variant版本,只存delta,比如undo,节省空间,但travel的成本更高,需要计算才能得到历史版本,这个对于传统数据库就更友好了,因为读历史版本的机会并不高频,但有具备了Mvcc的特性)
With this last scheme, the DBMS maintains the master versions of tuples in the main table and a sequence of delta versions in a separate delta storage.
This storage is referred to as the rollback segment in MySQL and Oracle, and is also used in HyPer.
Most existing DBMSs store the current version of a tuple in the main table.
To update an existing tuple, the DBMS acquires a continuous space from the delta storage for creating a new delta version.
This delta version contains the original values of modified attributes rather than the entire tuple.
The DBMS then directly performs in-place update to the master version in the main table.
This scheme is ideal for UPDATE operations that modify a subset of a tuple’s attributes because it reduces memory allocations.
This approach, however, leads to higher overhead for read-intensive workloads.
To perform a read operation that accesses multiple attributes of a single tuple, the DBMS has to traverse the version chain to fetch the data for each single attribute that is accessed by the operation.
Discussion
These schemes have different characteristics that affect their behavior for OLTP workloads.
As such, none of them achieve optimal performance for either workload type.
The append-only scheme is better for analytical queries that perform large scans because versions are stored contiguously in memory, which minimizes CPU cache misses and is ideal for hardware prefetching.
But queries that access an older version of a tuple suffer from higher overhead because the DBMS follows the tuple’s chain to find the proper version.
The append-only scheme also exposes physical versions to the index structures, which enables additional index management options.
All of the storage schemes require the DBMS to allocate memory for each transaction from centralized data structures (i.e., tables, delta storage).
Multiple threads will access and update this centralized storage at the same time, thereby causing access contention.
To avoid this problem, the DBMS can maintain separate memory spaces for each centralized structure (i.e., tables, delta storage) and expand them in fixed-size increments.
Each worker thread then acquires memory from a single space. This essentially partitions the database, thereby eliminating centralized contention points.
GARBAGE COLLECTION
(对于MVCC,GC是个核心问题,因为MVCC会天然的导致版本膨胀,GC策略不合理会导致查询性能下降,因为查询依赖version traverse)
Since MVCC creates new versions when transactions update tuples, the system will run out of space unless it reclaims the versions that are no longer needed.
This also increases the execution time of queries because the DBMS spends more time traversing long version chains.
As such, the performance of a MVCC DBMS is highly dependent on the ability of its garbage collection (GC) component to reclaim memory in a transactionally safe manner.
The GC process is divided into three steps: (1) detect expired versions, (2) unlink those versions from their associated chains and indexes, and (3) reclaim their storage space.
(如何判断一个version可以回收,可以按version级别和所有active事务的tid比较判断,也可以采用epoch的粗粒度的方式)
The DBMS considers a version as expired if it is either an invalid version (i.e., created by an aborted transaction) or it is not visible to any active transaction.
For the latter, the DBMS checks whether a version’s end-ts is less than the Tid of all active transactions.
The DBMS maintains a centralized data structure to track this information, but this is a scalability bottleneck in a multi-core system [27, 48].
An in-memory DBMS can avoid this problem with coarse-grained epoch-based memory management that tracks the versions created by transactions [44].
There is always one active epoch and an FIFO queue of prior epochs. After some amount of time, the DBMS moves the current active epoch to the prior epoch queue and then creates a new active one.
This transition is performed either by a background thread or in a cooperative manner by the DBMS’s worker threads.
Each epoch contains a count of the number of transactions that are assigned to it.
The DBMS registers each new transaction into the active epoch and increments this counter.
When a transaction finishes, the DBMS removes it from its epoch (which may no longer be the current active one) and decrements this counter.
If a non-active epoch’s counter reaches zero and all of the previous epochs also do not contain active transactions, then it is safe for the DBMS to reclaim expired versions that were updated in this epoch.
There are two GC implementations for a MVCC that differ on how the DBMS looks for expired versions.
The first approach is tuple-level GC wherein the DBMS examines the visibility of individual tuples.
The second is transaction-level GC that checks whether any version created by a finished transaction is visible.
One important thing to note is that not all of the GC schemes that we discuss below are compatible with every version storage scheme.
Tuple-level Garbage Collection
With this approach, the DBMS checks the visibility of each individual tuple version in one of two ways:
(最直觉的方式,回收的效率比较低,要一个个找)
Background Vacuuming (VAC): The DBMS uses background threads that periodically scan the database for expired versions.
As shown in Table 1, this is the most common approach in MVCC DBMSs as it is easier to implement and works with all version storage schemes.
But this mechanism does not scale for large databases, especially with a small number of GC threads.
(优化的方式,采用粗粒度的epoch-based的方法,或是使用bitmap来降低需要扫描的block数目)
A more scalable approach is where transactions register the invalidated versions in a latch-free data structure [27].
The GC threads then reclaim these expired versions using the epoch-based scheme described above.
Another optimization is where the DBMS maintains a bitmap of dirty blocks so that the vacuum threads do not examine blocks that were not modified since the last GC pass.
(Traverses的时候顺便标记,只能用于O2N,并且对于没有被访问的object不管用,所以还是要结合VAC的方式做全量Cleaning)
Cooperative Cleaning (COOP): When executing a transaction, the DBMS traverses the version chain to locate the visible version.
During this traversal, it identifies the expired versions and records them in a global data structure.
This approach scales well as the GC threads no longer needs to detect expired versions, but it only works for the O2N append-only storage.
One additional challenge is that if transactions do not traverse a version chain for a particular tuple, then the system will never remove its expired versions.
This problem is called “dusty corners” in Hekaton [16].
The DBMS overcomes this by periodically performing a complete GC pass with a separate thread like in VAC.
Transaction-level Garbage Collection
(看起来比按照Tuple去GC要更合理,overhead是在每个Epoch中,要记录每个事务的r/w sets,用作比较)
In this GC mechanism, the DBMS reclaims storage space at transaction-level granularity.
It is compatible with all of the version storage schemes.
The DBMS considers a transaction as expired when the versions that it generated are not visible to any active transaction.
After an epoch ends, all of the versions that were generated by the transactions belonging to that epoch can be safely removed.
This is simpler than the tuple-level GC scheme, and thus it works well with the transaction-local storage optimization (Sect. 4.4) because the DBMS reclaims a transaction’s storage space all at once.
The downside of this approach, however, is that the DBMS tracks the read/write sets of transactions for each epoch instead of just using the epoch’s membership counter.
Discussion
Tuple-level GC with background vacuuming is the most common implementation in MVCC DBMSs.
In either scheme, increasing the number of dedicated GC threads speeds up the GC process.
The DBMS’s performance drops in the presence of long-running transactions.
This is because all the versions generated during the lifetime of such a transaction cannot be removed until it completes.
INDEX MANAGEMENT
All MVCC DBMSs keep the database’s versioning information separate from its indexes.
That is, the existence of a key in an index means that some version exists with that key but the index entry does not contain information about which versions of the tuple match.
We define an index entry as a key/value pair, where the key is a tuple’s indexed attribute(s) and the value is a pointer to that tuple.
The DBMS follows this pointer to a tuple’s version chain and then scans the chain to locate the version that is visible for a transaction.
The DBMS will never incur(lead to) a false negative from an index, but it may get false positive matches because the index can point to a version for a key that may not be visible to a particular transaction.
(主键的问题就是change)Primary key indexes always point to the current version of a tuple.
But how often the DBMS updates a primary key index depends on whether or not its version storage scheme creates new versions when a tuple is updated.
For example, a primary key index in the delta scheme always points to the master version for a tuple in the main table, thus the index does not need to be updated.
For append-only, it depends on the version chain ordering: N2O requires the DBMS to update the primary key index every time a new version is created.
If a tuple’s primary key is modified, then the DBMS applies this to the index as a DELETE followed by an INSERT.
For secondary indexes, it is more complicated because an index entry’s keys and pointers can both change.
The two management schemes for secondary indexes in a MVCC DBMS differ on the contents of these pointers.
The first approach uses logical pointers that use indirection to map to the location of the physical version.
Contrast this with the physical pointers approach where the value is the location of an exact version of the tuple.
Logical Pointers
The main idea of using logical pointers is that the DBMS uses a fixed identifier that does not change for each tuple in its index entry.
Then, as shown in Fig. 5a, the DBMS uses an indirection layer that maps a tuple’s identifier to the HEAD of its version chain.
This avoids the problem of having to update all of a table’s indexes to point to a new physical location whenever a tuple is modified (even if the indexed attributes were not changed).
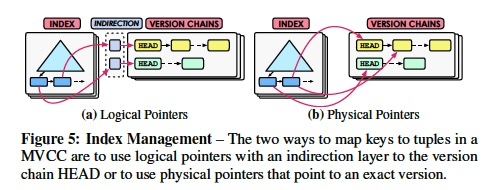
Only the mapping entry needs to change each time. But since the index does not point to the exact version, the DBMS traverses the version chain from the HEAD to find the visible version.
This approach is compatible with any version storage scheme.
As we now discuss, there are two implementation choices for this mapping:
Primary Key (PKey): With this, the identifier is the same as the corresponding tuple’s primary key.
When the DBMS retrieves an entry from a secondary index, it performs another look-up in the table’s primary key index to locate the version chain HEAD.
If a secondary index’s attributes overlap with the primary key, then the DBMS does not have to store the entire primary key in each entry.
Tuple Id (TupleId): One drawback of the PKey pointers is that the database’s storage overhead increases as the size of a tuple’s primary key increases, since each secondary index has an entire copy of it.
In addition to this, since most DBMSs use an order-preserving data structure for its primary key indexes, the cost of performing the additional look-up depends on the number of entries.
An alternative is to use a unique 64-bit tuple identifier instead of the primary key and a separate latch-free hash table to maintain the mapping information to the tuple’s version chain HEAD.
(逻辑指针本身很直觉的想法,
这里有两种选择,一直是用PKey做逻辑指针,那么所有的Secondary Index中都记录Pkey,这样每次只要改PKey就行,问题就是PKey如果很大就不经济,而且多一次主键查询
或是单独用tupleid,这样就需要一个map来维护tupleid和物理指针的关系)
Physical Pointers
With this second scheme, the DBMS stores the physical address of versions in the index entries.
This approach is only applicable for append-only storage, since the DBMS stores the versions in the same table and therefore all of the indexes can point to them.
When updating any tuple in a table, the DBMS inserts the newly created version into all the secondary indexes.
In this manner, the DBMS can search for a tuple from a secondary index without comparing the secondary key with all of the indexed versions.
Several MVCC DBMSs, including MemSQL and Hekaton, employ this scheme.
Discussion
(逻辑指针适用于写密集,物理指针适用于读密集)
Like the other design decisions, these index management schemes perform differently on varying workloads.
The logical pointer approach is better for write-intensive workloads, as the DBMS updates the secondary indexes only when a transaction modifies the indexes attributes.
Reads are potentially slower, however, because the DBMS traverses version chains and perform additional key comparisons.
Likewise, using physical pointers is better for read-intensive workloads because an index entry points to the exact version.
But it is slower for update operations because this scheme requires the DBMS to insert an entry into every secondary index for each new version, which makes update operations slower.
(因为MVCC在index中没有记录version信息,所以一般无法做index-only scan,必须要回表)
One last interesting point is that index-only scans are not possible in a MVCC DBMS unless the tuples’ versioning information is embedded in each index.
The system has to always retrieve this information from the tuples themselves to determine whether each tuple version is visible to a transaction.
NuoDB reduces the amount of data read to check versions by storing the header meta-data separately from the tuple data.
RELATED WORK
The first mention of MVCC appeared in Reed’s 1979 dissertation [38].
After that, researchers focused on understanding the theory and performance of MVCC in single-core disk-based DBMSs [9, 11, 13].
We highlight the more recent research efforts.
Concurrency Control Protocol:
There exist several works proposing new techniques for optimizing in-memory transaction processing [46, 47].
Larson et al. [27] compare pessimistic (MV2PL) and optimistic (MVOCC) protocols in an early version of the Microsoft Hekaton DBMS [16].
Lomet et al. [31] proposed a scheme that uses ranges of timestamps for resolving conflicts among transactions,
and Faleiro et al. [18] decouple MVCC’s concurrency control protocol and version management from the DBMS’s transaction execution.
Given the challenges in guaranteeing MVCC serializability, many DBMSs instead support a weaker isolation level called snapshot isolation [8] that does not preclude the write-skew anomaly.
Serializable snapshot isolation (SSI) ensures serializability by eliminating anomalies that can happen in snapshot isolation [12, 20].
Kim et al. [24] use SSN to scale MVCC on heterogeneous workloads.
Our study here is broader in its scope.
Version Storage:
Another important design choice in MVCC DBMSs is the version storage scheme.
Herman et al. [23] propose a differential structure for transaction management to achieve high write throughput without compromising the read performance.
Neumann et al. [36] improved the performance of MVCC DBMSs with the transaction-local storage optimization to reduce the synchronization cost.
These schemes differ from the conventional append-only version storage scheme that suffers from higher memory allocation overhead in main-memory DBMSs.
Arulraj et al. [7] examine the impact of physical design on the performance of a hybrid DBMS while running heterogeneous workloads.
Garbage Collection:
Most DBMSs adopt a tuple-level background vacuuming garbage collection scheme.
Lee et al. [29] evaluate a set of different garbage collection schemes used in modern DBMSs.
They propose a new hybrid scheme for shrinking the memory footprint in SAP HANA.
Silo’s epoch-based memory management approach allows a DBMS to scale to larger thread counts [44].
This approach reclaims versions only after an epoch (and preceding epochs) no longer contain an active transaction.
Index Management:
Recently, new index data structures have been proposed to support scalable main-memory DBMSs.
Lomet et al. [32] introduced a latch-free, order preserving index, called the Bw-Tree, which is currently used in several Microsoft products.
Leis et al. [30] and Mao et al. [34] respectively proposed ART and Masstree, which are scalable index structures based on tries.
Instead of examining the performance of different index structures, this work focuses on how different secondary index management schemes impact the performance of MVCC DBMSs.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号