列存格式
https://zhuanlan.zhihu.com/p/35622907
https://blog.csdn.net/yu616568/article/details/51868447
为什么要用列存这里就不聊了,直接看格式的演变
NSM (N-ary Storage Model) ,按行存储
DSM (Decomposition Storage Model) ,按列分页;这样有个问题是,对于应用最终返回还是要按行的,这种方式,检索一行数据的代价会比较高
PAX (Partition Attributes Cross),2001提出,结合两者,其实就是Row Group的概念,一个Page会包含一组row的所有数据,在page内,用miniPage集中存储每个列的数据;这样既可以利用列存的优点,又可以比较方便的找到一行的其他数据

这里明显有个优化是, column group,
如果应用确定,有某些列会经常被一起访问,那么这几个列可以一起存储
Cstore的Projection,或者HBase的column family都是这个思路
下面看下当前流行的两个列存格式,ORC和Parquet
存储格式
Parquet,
HDFS File,由HDFS Block组成(256M或512M)
Row Group,对应于HDFS block,是Parquet的数据加载和处理单元
Column Chunk,Row Group中每一个Column存成一个Column Chunk,每个column可以用不同的编码方式
Page,Column Chunk分成page,page是最小的编码单位,包含数据页、字典页和索引页
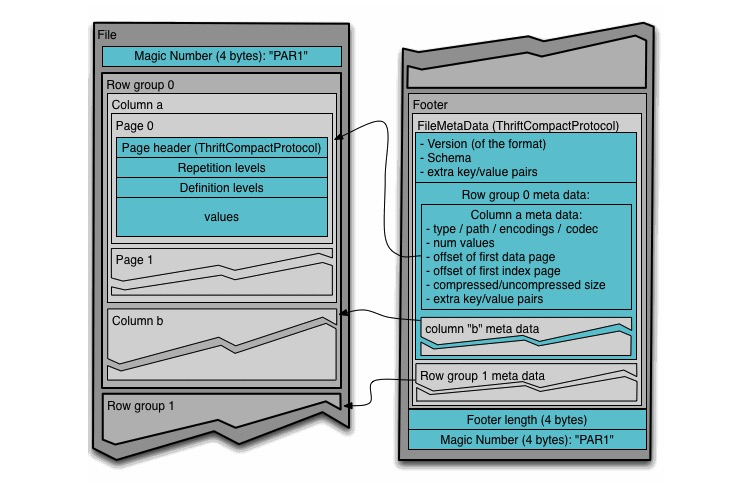
Parquet的meta也是放在一个File的最后,因为append方式,只有写到最后才可以知道所有的meta
首先,Magic Number,表明是Parquet格式
FooterLength,表示整个Meta整个占的空间大小,
Footer,以Thrift格式编码,里面分为,
File Meta,文件级别Meta
RowGroup Meta,关键是记录,每个index page,data page的offset,和对应的codec
Column Meta,记录column的offset
ORC,Optimized Row Column
ORC的文件分成Stripe,对应于Parquet的Row group,一般对应于一个HDFS的block
Stripe的数据分段存储,分成Footer,Index data,Row data
这里ORC嫌Stripe太粗,所以引入一个Row Group的概念,10000行,所以Stripe分为Row Group
Index中记录了所有Row Group的offset,Statistics等数据
然后每个Row Group再按照Column去分开存储
底下的图比较confuse,引用一里面的图,感觉也不太对
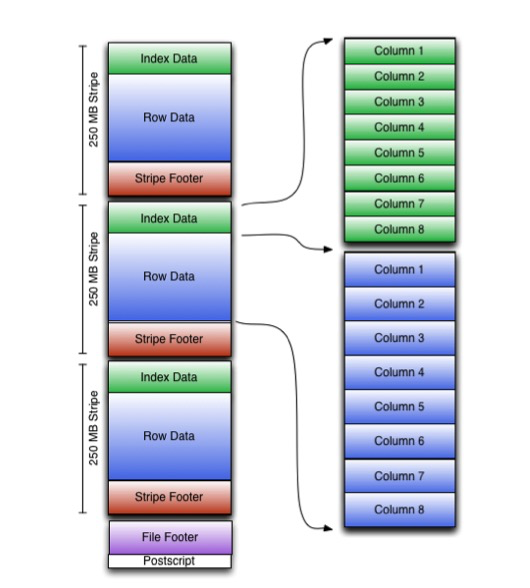
ORC的Meta也是存储在文件的尾部,
首先是Postscript,保存文件级别的Meta,整个文件的压缩格式,版本信息,Footer的长度等;
然后是Footer,记录每个Stripe的offset和长度;文件级别的统计信息,Striper级别的统计信息
接着是Stripe,Stripe也带着Footer,记录index,row data的offset和长度
从Stripe Index中可以读出每个Row Group的offset和统计信息
在Row Group里面分成column chunk
可以看出其实Parquet和ORC的存储结构大同小异,都是基于PAX
Parquet的定义更加清晰一些,ORC的命名和定义比较confuse,ORC的文档看着也比较混乱
ORC的优势是,在FIle,Stripe,row group3层做了统计信息,可以细粒度的skip,所以效率更高一些;做的更细一些
数据类型
Parquet设计的时候,主要是为了处理和存储Protobuffer,Json这种嵌套结构,针对optional和repeat,提出一种高效的存储方式;

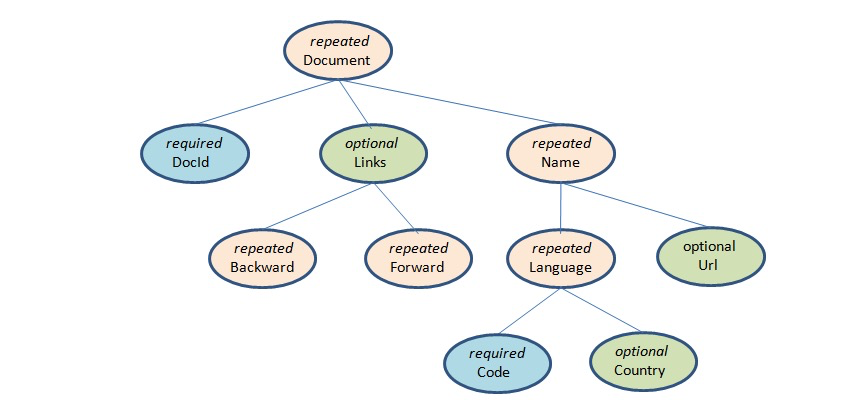
无论如何嵌套,最终存储的时候是要拉平的,因为数据库是二维关系表
但是拉平以后,最大的问题是如何对齐,简单的方式是用行号,但是对于嵌套结构,光行号搞不定的
比如这里language是repeat,所以需要区分,存的language是在当前name repeat,还是在下一个name中,所以需要一个flag来标识,就是rl
同样optional就意味着有null,但是如果要知道在哪一层就是null,比如对于country,是光country是null,还是连language就是null,也需要一个flag来标识,就是dl
这个设计非常的精巧,但是也是比较复杂
ORC相对就简单的多,

他本身不直接支持嵌套结构,但是通过复杂类型可以间接支持
一样的思路,所有column都是要拉平存储,但是在类型树上,先按照中序遍历进行编号
实际存储只存叶子节点,上面的例子只会存储5个column
他在结构的设计上不像parquet那么精巧,
用bitset来表示是否为null,类型树上每一个类型都可以有一个bitset来表示
用list或array类型来实现repeat,list和array的实现都是通过记录一个大buffer里面的offset来实现,和string这种变长的数据结构的实现一样
所以如果普通使用ORC的结构应该是够用的,但是如果就是要针对嵌套结构,那么Parquet更好些,代价就是更复杂
压缩方式
压缩分成,按类型编码,和通用压缩
其实对于列存,列数据大量重复,直接用通用压缩的效果也应该不错,
按类型编码,可以进一步压缩,比如在Cstore中,给出一系列编码方式,有序稀疏,无序稀疏等;对字符串用字典编码;
Parquet和ORC也分别对应于不同的类型提供这个的编码方式,Parquet提供的压缩方式更多一些
当然编码过后,仍然可以用通用的压缩算法进行进一步压缩

 浙公网安备 33010602011771号
浙公网安备 33010602011771号