How to Architect a Query Compiler
这个有两篇论文
How to Architect a Query Compiler
How to Architect a Query Compiler, Revisited
是完全不同的两拨人写的,内容也不尽相同,我们的重点是Revisited这篇
How to Architect a Query Compiler
首先,现在很热门的query compilation其实是个很old的topic,System R就在比较早的原型中使用过,因为这确实是很直觉的优化
但是最终还是被,interpretation替代,因为那个时代的瓶颈是IO,所以你怎么执行不关键
最近是因为硬件的发展,使得内存数据库兴起,那么这个时候瓶颈在CPU,那么怎么执行就是关键了

这文章是16年的,query compiler是落后于通用编译器领域的,因为之前没人用
主要的方式,template expander,用过macro的就知道啥意思

缺点是,
很难维护,
很难进行复杂优化,跨operator优化,
容易导致编译代码膨胀

尤其是对于代码膨胀,给出例子,理解一下

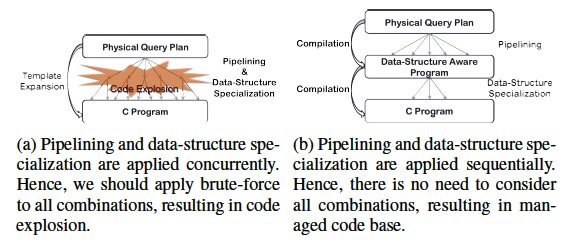
这篇论文的核心思想,就是既然把high-level的执行计划一下转化成low-level的code很复杂,那我们分而治之
一步步来,慢慢的转换,
we propose progressively lowering the level of abstraction
这样做的好处,
模块化,更容易设计compiler
分层优化,很多优化在high-level或low-level都不好做,但是在某个中间层就可以比较简单的做
抑制代码膨胀,因为相当于剪枝了
再回到刚刚的例子,添加一个data-strcture aware DSL

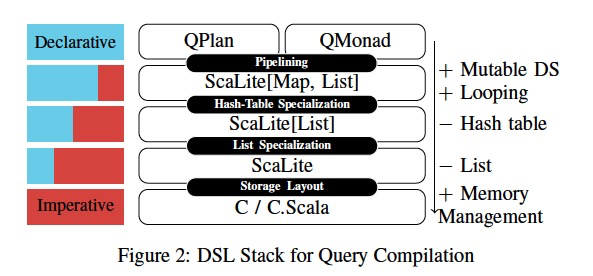
论文后面就是描述如何选择和构建这个DSL stack
最终得到的DSL stack,
这里看到,high-level的plan是declarative的,因为只会告诉你要什么,但是不告诉你怎么做,所以需要interpretor,所以叫解释执行,因为不解释,机器没法执行
往下,每层IR都是逐渐向Imperative靠近,成为完全的Imperative就是确定性的执行逻辑,机器可以直接执行
这个方案看着挺合理的,但是那么多层的IR,很难落地实际应用,所以也不多说了
How to Architect a Query Compiler, Revisited
现在数据库大体使用解释执行,
所以数据库和compiler相比,也具有parser,前端,优化器,后端,最大的区别是,generation of machine code

renaissance用的很有意思,但其实对于数据库不存在,大家并没有失去过往的辉煌要重新找回,数据库的技术这么多年基本没有太大的变化
query compiler被扔在角落那么多年,无人问津,现在又突然称为香饽饽了,真是风水轮流转

这张图,画的非常的好,
当前基本所有的执行的架构都囊括了,
传统的db,是解释执行,Plan直接通过Interpretor进行解释执行,生成结果
而Query Compiler,在Physical Plan后面,没有Interpretor,
有3种case,比如Hyper,用IR去编写算子,然后用LLVM将IR编译成机器代码
LB2,直接用C编写算子,用GCC编译成机器代码
DBLAB,通过多层的IR不断的转换,最终生成C,然后用GCC编译成机器代码,这个就是上面的Paper的方式
这些方案看着是不是都很复杂
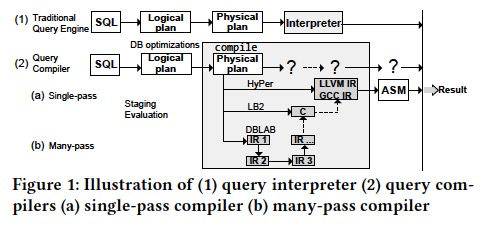
这篇文章说,我们不需要做low-level的coding,也不需要复杂的多层compiler,我们可以通过query interpreters来生成query compiler

先来个上世纪70年代的理论,二村投影,那是日本在各方面都很辉煌的时期

关键就是怎么理解,Specialization,看个例子,
对于两个参数的函数power,我们固定一个参数,称为partial evaluation
这个在FP中,可以用闭包实现

那么根据这个理论,如何应用到compiler上?
如果把Interpreter看成有两个参数,一个是query,一个是input data
那么如果,对于query和interpreter先用mix compile成一个target,保持不变,那么参数就剩下input data,这就实现了从interpreter生成compiler
这称为the first Futamura projection,还有第二,第三,但是可以先不关心

图中,c是paper里面给出的Specialization的一种实现方式,我看了一下,没太明白干嘛要这样实现
上面说了在FP中,用闭包就可以简单实现
下面看下,实际的对于Interpretor如何实际的去做Specialization
对于数据的执行方式,有两种,
一种是valcano,一种是data-centric
下面看下对于下面的例子中,不同的模式下,对于一个operator是如何实现的,这里选的是Select
可以看到对于valcano,pull-based,核心的接口是next,这里是自顶而下的递归调用,比如传入的是scan,那么调用Scan的next获取rec
如果rec不为null,执行prec进行筛选
再看下data-centric,push-based,所以核心的接口是produce和consume,生产和消费者模式
produce接口,直接调用的是传入op的produce,自底向上,所以下面的要先produce
consume接口,首先执行select的筛选逻辑,然后用rec调用parent的consume向上回溯

那我们看看,如何对两种模式做Specialization,
先看,volcano模式,明显是将rank<10,partial evaluation到逻辑中

问题就是,其中的这个条件判断是无法specialized的

再看,data-centric,就可以完美的specialized,因为其中没有基于input的条件判断
然后paper说,可以改进data-centric的接口,他们的第一个contribution

例子,我不太get到这个好在哪,接口更少?

到这里论文的核心思路基本就清楚了
paper后面给出一系列实现相关的章节,跳过
最后这个Paper的Related work很不错,尤其这个图,
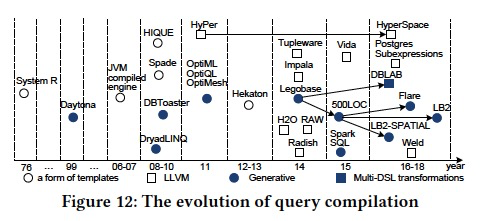
第一阶段,origin

第二阶段,Compiled


第三阶段,codeGen?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号