CMU Database Systems - Database Recovery
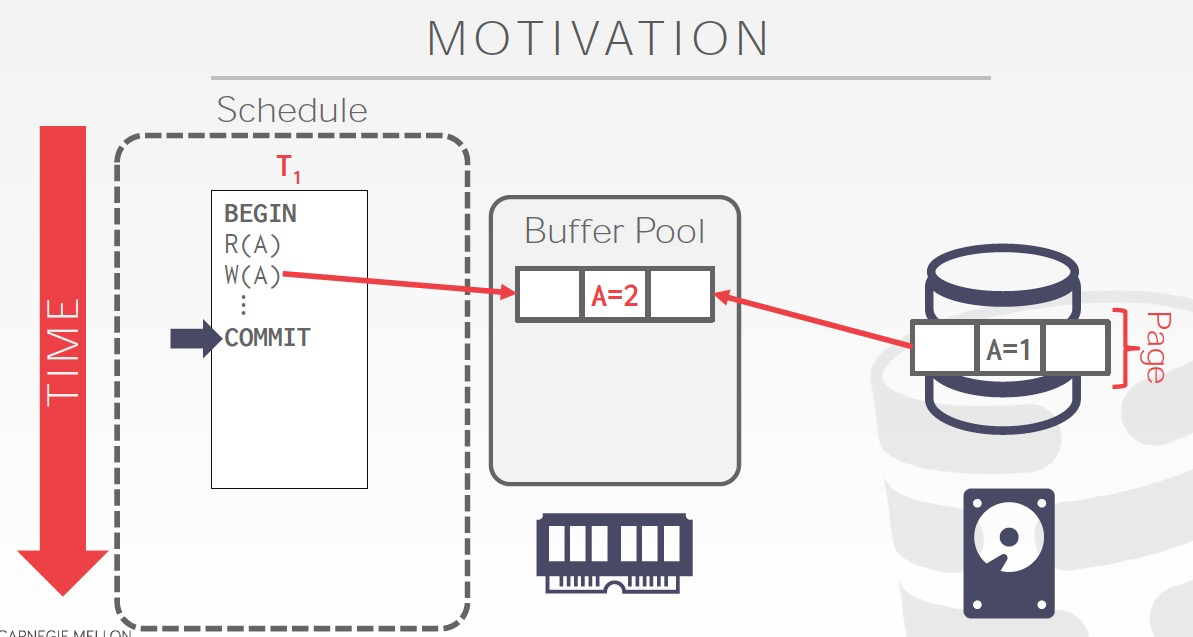
数据库数据丢失的典型场景如下,
数据commit后,还没有来得及flush到disk,这时候crash就会丢失数据
当然这只是fail的一种情况,DataBase Recovery要讨论的是,在各种fail的情况下,如何保证,
1. 已经commit的transaction的数据不丢失;2. 没有部分提交的情况,all or nothing
为了达成这个目的,需要在txn执行的过程中做一些actions保留当时状态,然后在failover后,再执行一系列actions去recover这些状态

Failure可以分为下面几种,
1. logical failure,数据库本身可以处理的failure 2. crash或重启 3. 介质永久性损坏
3. 单机无解,需要用分布式replicas的方式来解决
1和2,可以用下面介绍的方法解决




这里描述数据恢复中关键的两种操作,
Redo,保障commit的数据持久,有效
Undo,保障没有脏数据,写了一半的txn
大家看到Redo,Undo可能首先会想到,undo和redo日志,其实undo和redo是抽象操作,可以用多种方式实现,日志只是其中一种


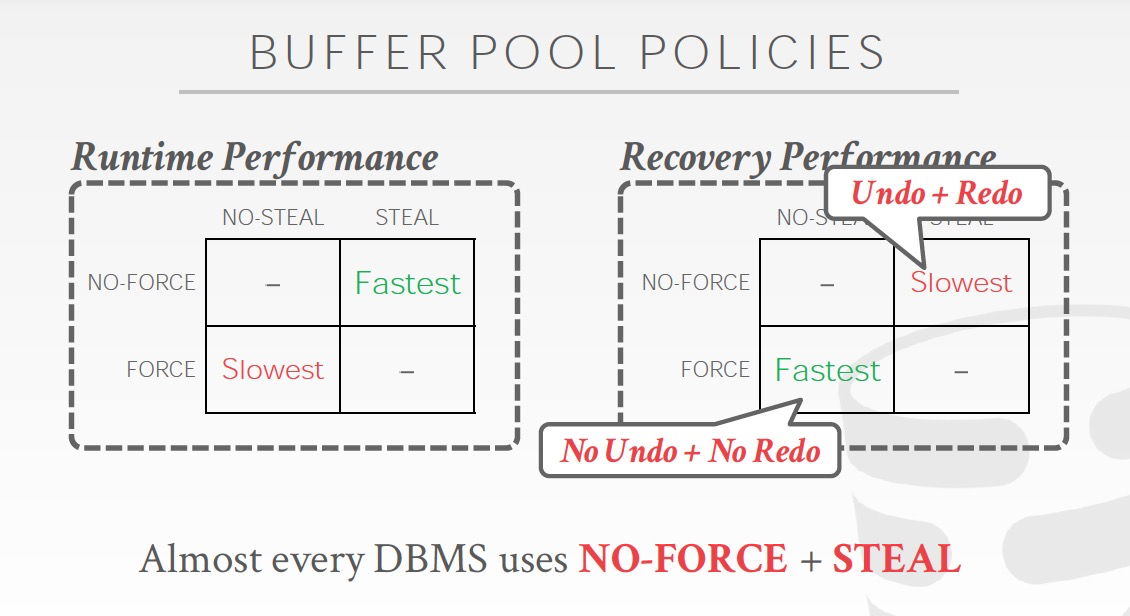
针对下面的两个问题,要引入两个重要的概念,steal和force
在设计上做不同的选择,所带来的recovery的设计是完全不同的



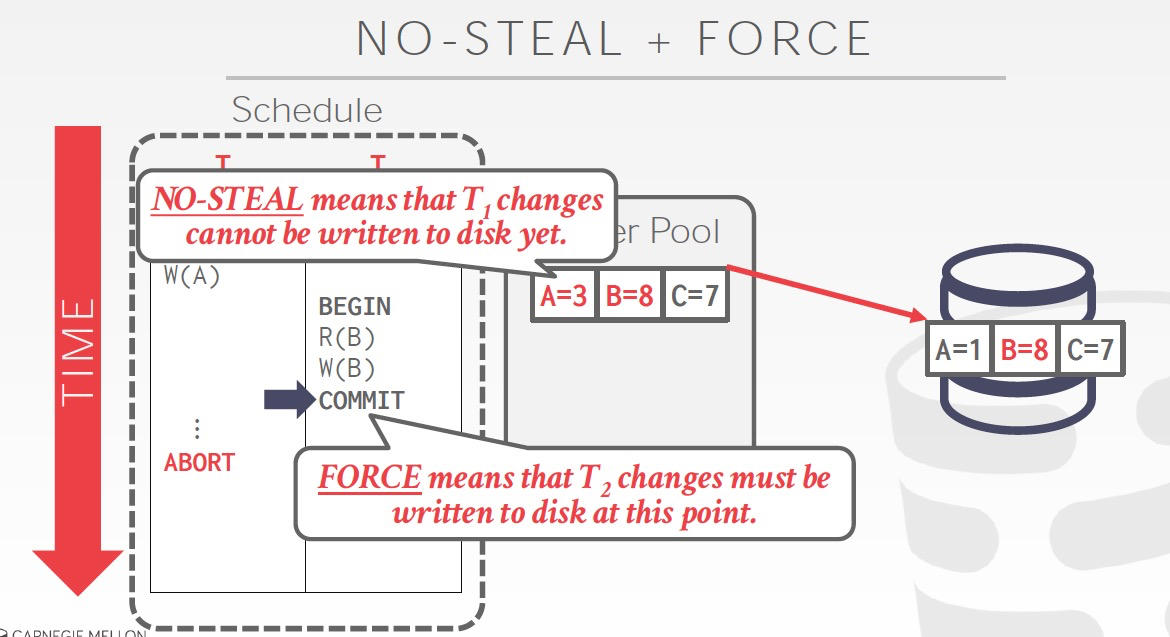
先看一种比较极端的策略,
No-steal,没有commit的数据,不会被flush到磁盘
force,txn commit的时候,数据需要先flush到磁盘
这种情况下,磁盘的数据精确等同于commit的数据,所以failover的时候,不需要做Redo或Undo操作
也就是这种情况下,recovery会非常简单,但是txn更新会比较麻烦和低效,比如底下的例子,B已经commit,但是A没有Commit,所以不能把整个page flush,只能单个更新B
从另一个角度说,如果Steal,failover的时候就需要undo;如果non-force,那么failover的时候,就需要Redo

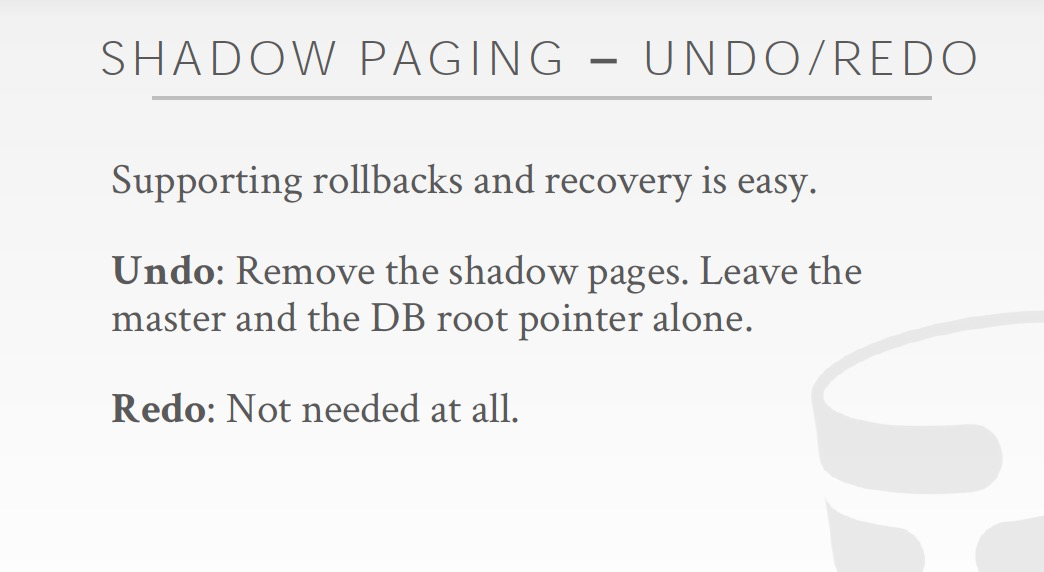
看下这个策略下的一种可行的实现,Shadow paging,有点类似copy on write机制

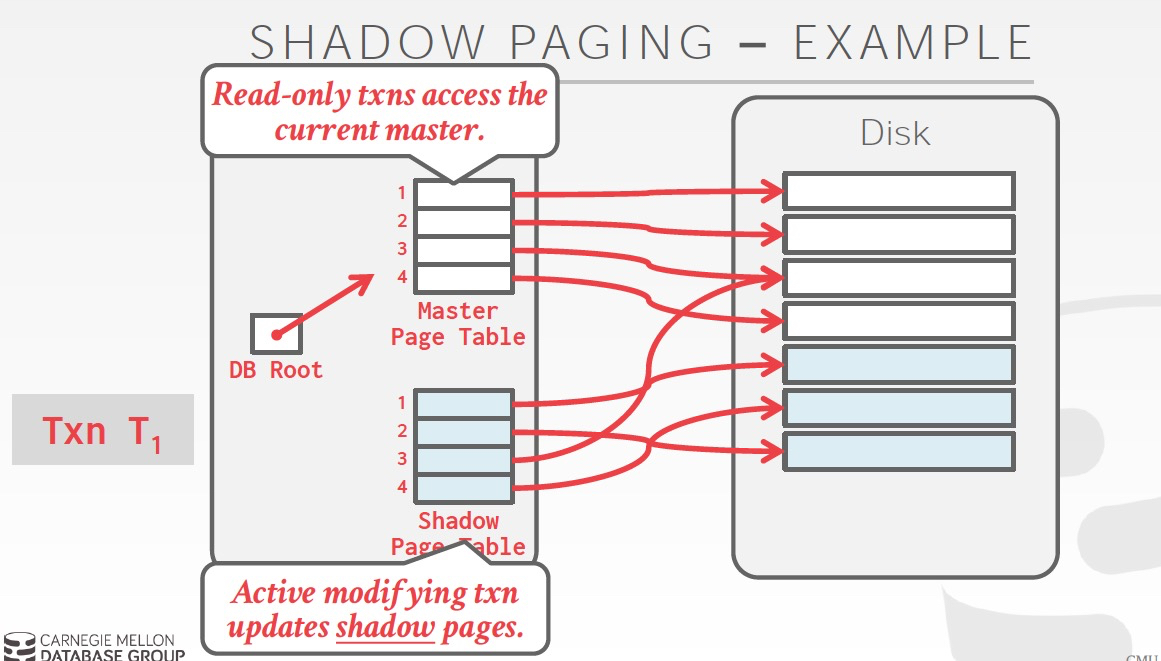
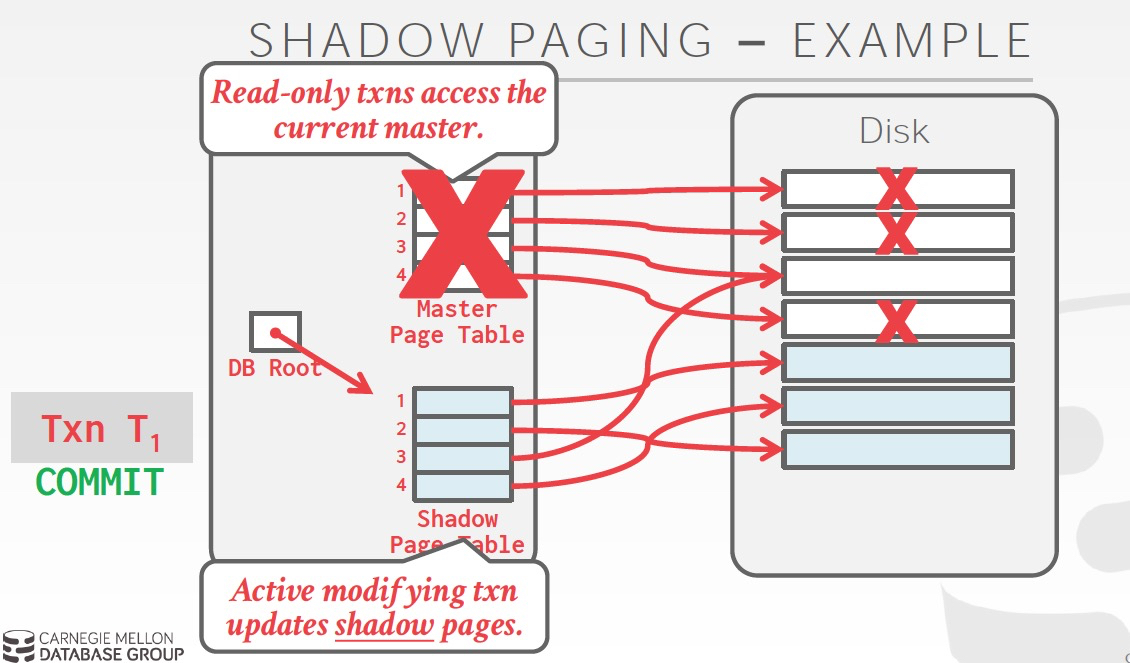
这个方法问题,
首先overhead太高,每次需要copy page table,和需要更改的page,还会有大量垃圾回收的负担
更严重的是,会导致page碎片化,page不连续很要命,因为这样如果做range query就会非常的低效

其实我们在实际生产中,用的机制是WAL,这是一种和上面描述的完全相反的机制,Steal + No-Force
这里关键是要理解,为何写日志,比更新真实的数据更高效,答案是,把随机写变成顺序写


这里描述WAL的具体机制,



这里是例子,可以看到commit时,log已经落盘,但是数据仍然没有flush
但数据已经不会丢失了,因为如果内存的数据丢了,我们可以从磁盘的log里面恢复出来

这里将的是如果可以non-steal,那么在log里面就不需要记录undo值,只需要redo值
听起来是不错,但是问题,如果txn的变更set如果要大于memory就不行了,因为memory的数据因为没有commit,所以不能flush到磁盘,那么就无法处理更多的数据


这里采用各种策略下,Runtime和Recovery的代价比较,
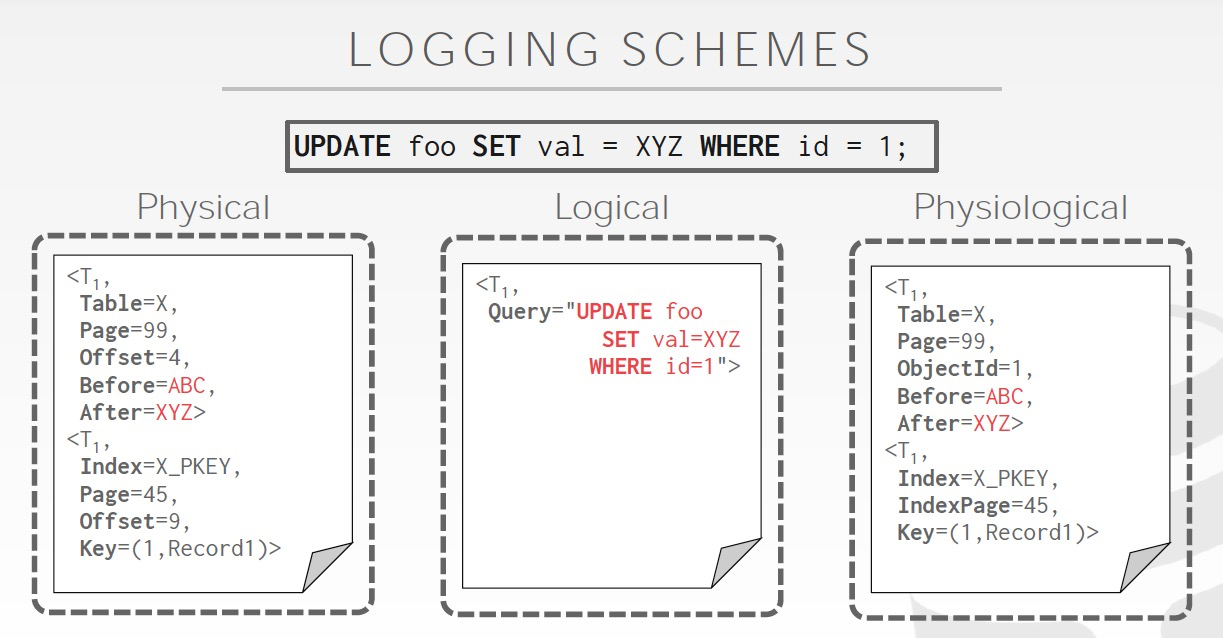
这里说log分为两种,
undo和redo日志,属于物理的日志,因为记录的是具体的数据变化;逻辑日志,只会记录执行的SQL
物理日志,高效,但是如果一下执行 1 billion行,是不是崩溃了;逻辑日志的特点是占用空间少,执行1 billion行,也是一条SQL,但问题就是比较难于用于recovery,你不知道crash前执行到哪儿了;所以可以用一直hybrid的方式,Physiological
逻辑日志,典型应用是Binlog,但是Binlog不是用于recovery,而且用于主备同步,或数据回放等


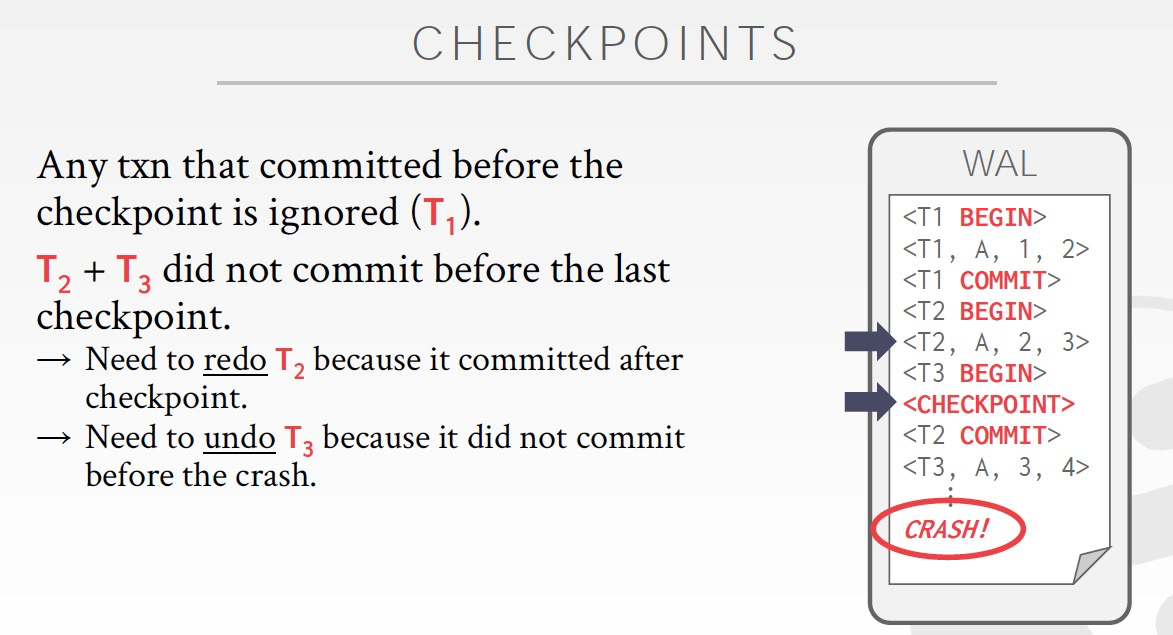
checkpoint机制,避免log replay时间过长,checkpoint过的数据直接加载就可以,只需要replay增量的数据
关键理解,checkpoint后面的数据,哪些是Redo,哪些是Undo
完成commit的Txn,需要redo
未完成commit的Txn,需要undo


Checkpoint的问题就是需要stop world;还有多久checkpoint一次,需要balance checkpoint的代价和recovery的时间代价


这里开始讨论具体的恢复机制,主要参考Aries这篇论文



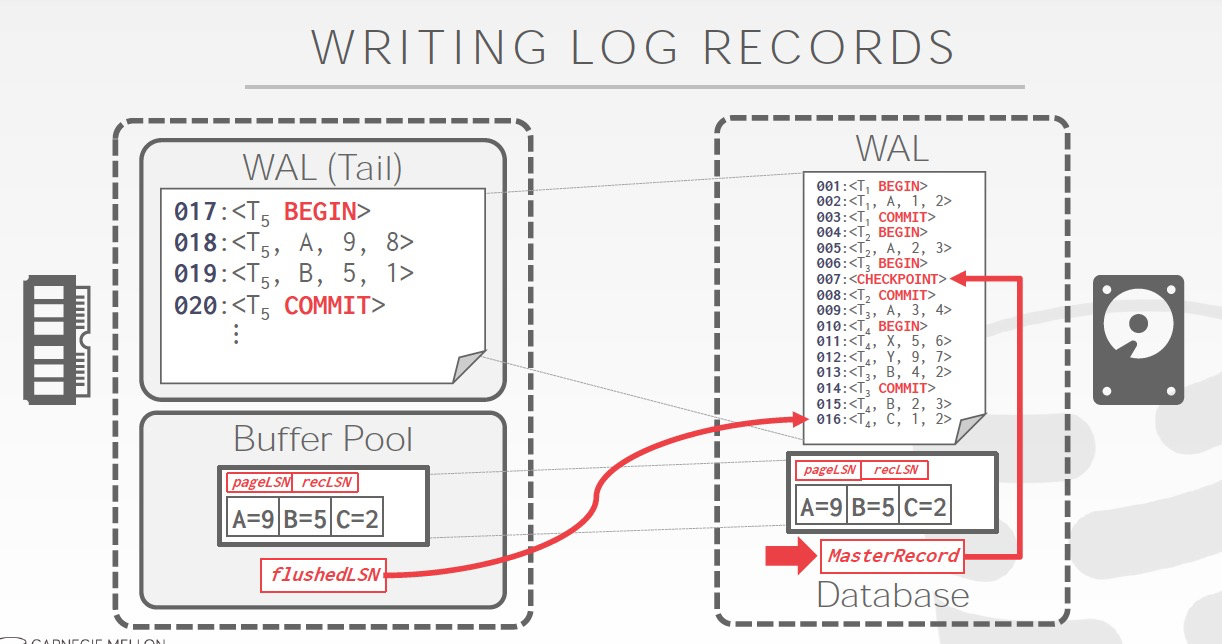
这里最关键的一个实现是增加,LSN,每个log都会有一个number
flushedLSN,哪些log已经flush到磁盘的WAL文件,不是指数据,是指log
pageLSN,page的最新更新log
recLSN,使得page变成dirty的那一条log


这里需要注意的是,在log被flush前,数据不允许先被flush到disk


看这个例子,理解上面的哪些LSN
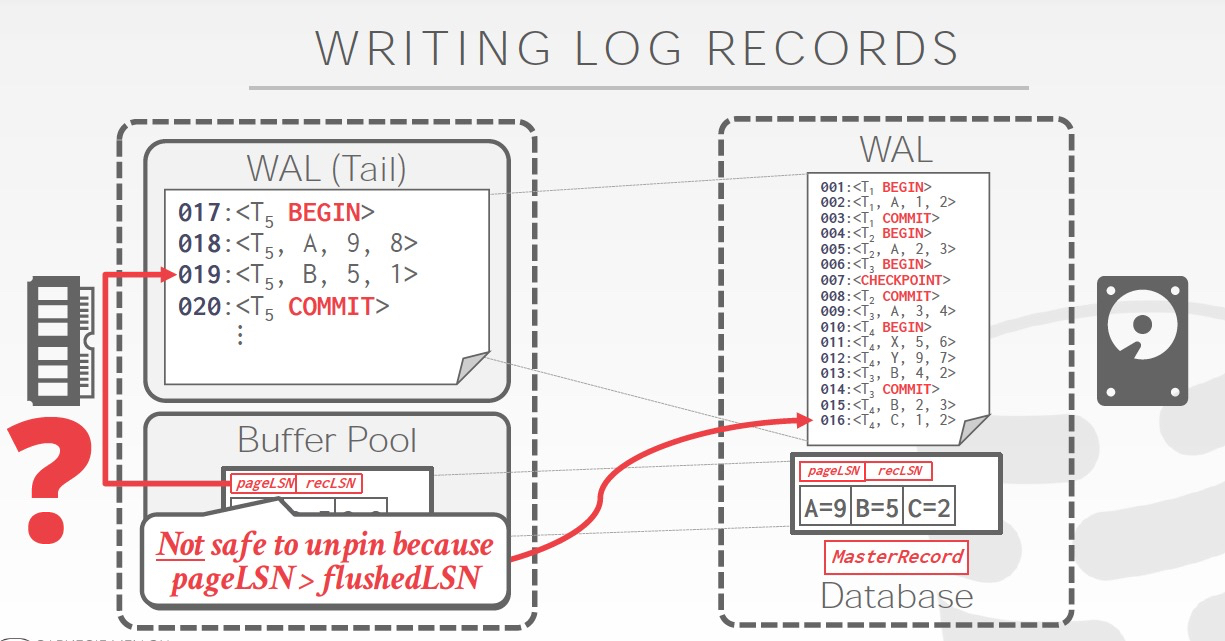
第二张图,可以flush page,因为pageLSN小于flushedLSN,因为有很多page,所以这个page从12往后没有更新
第三张图,不可用flush page,因为pageLSN大于flushedLSN,这部分更新的log还没有落盘

下面开始真正将恢复机制,先明白这里的机制基于如下假设,

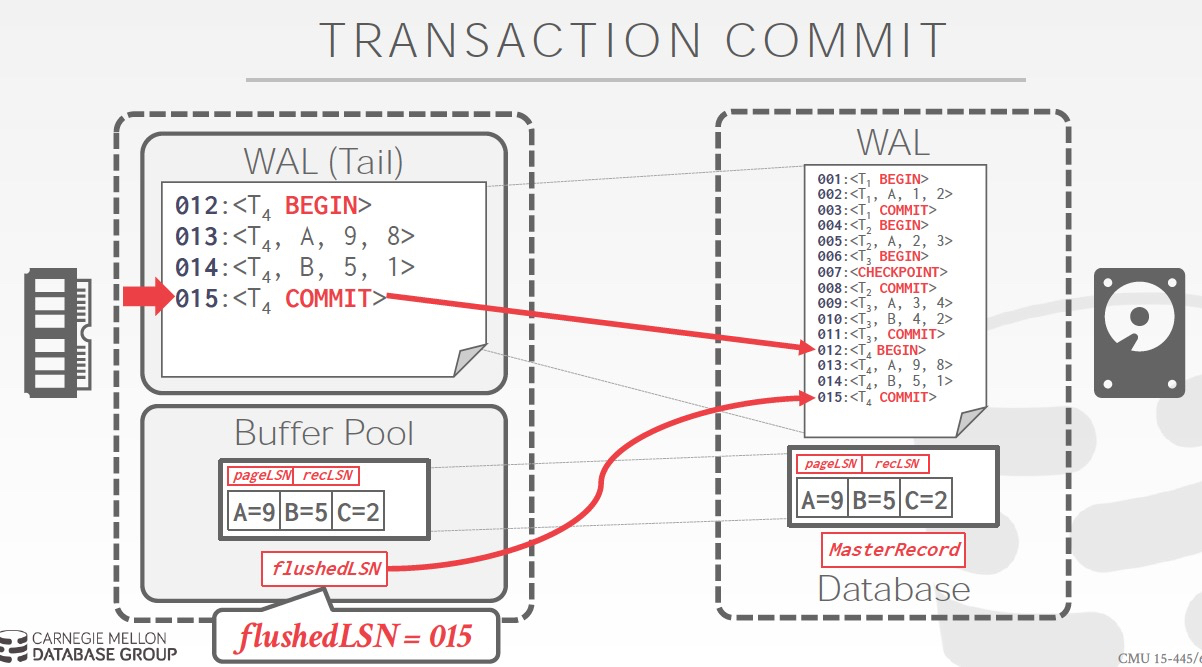
Commit的过程,关键理解,为何要加一个TXN-END
因为Commit这条log,需要先被写入,才能开始Commit过程,所以需要一个标志表明,这个TXN已经完成commit了
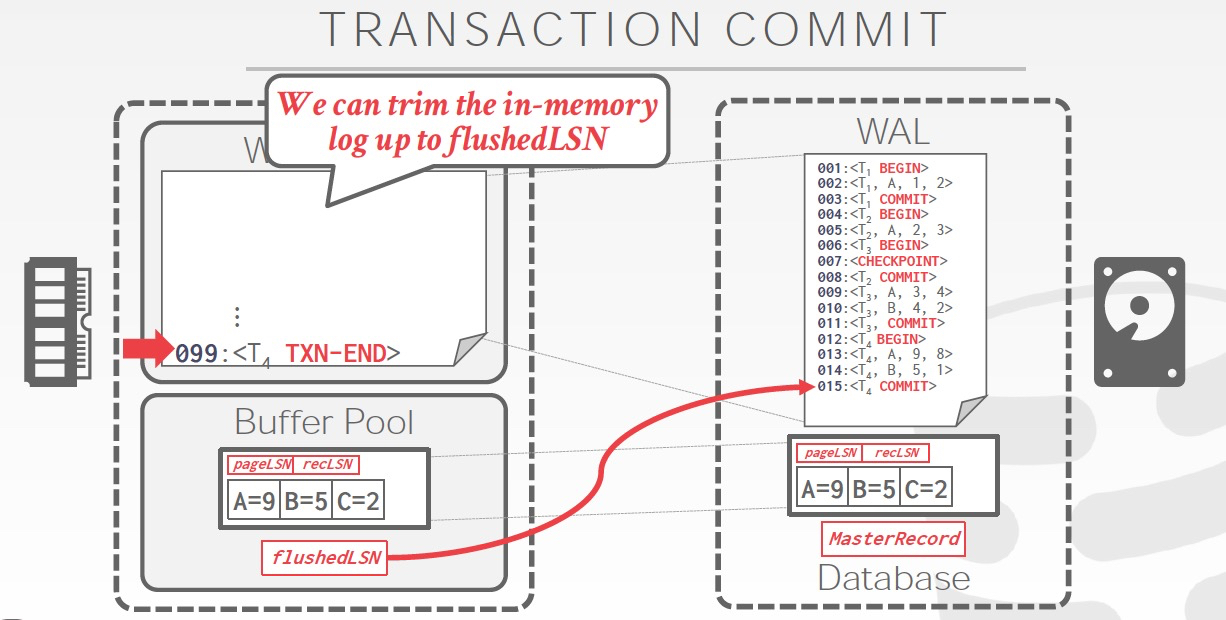
这个就是TXN-END,看到这个就可以把和这个TXN相关的log从内存里面trim掉,因为已经落盘了,如果没有TXN-END,你不知道commit过程是否完成
注意的是,TXN-END只是个内部标识,不是关键,对于TXN只要有Log里面有commit就认为事务成功,所以END不需要实时写入

Abort需要逆着做,所以为了快速找到同一个txn的上一条log,每条日志增加一个prevLSN

为了记录下abort后undo的过程,增加CLR日志,如果不加CLR有啥问题?我觉得比较难看出abort后,当前的值变成啥了
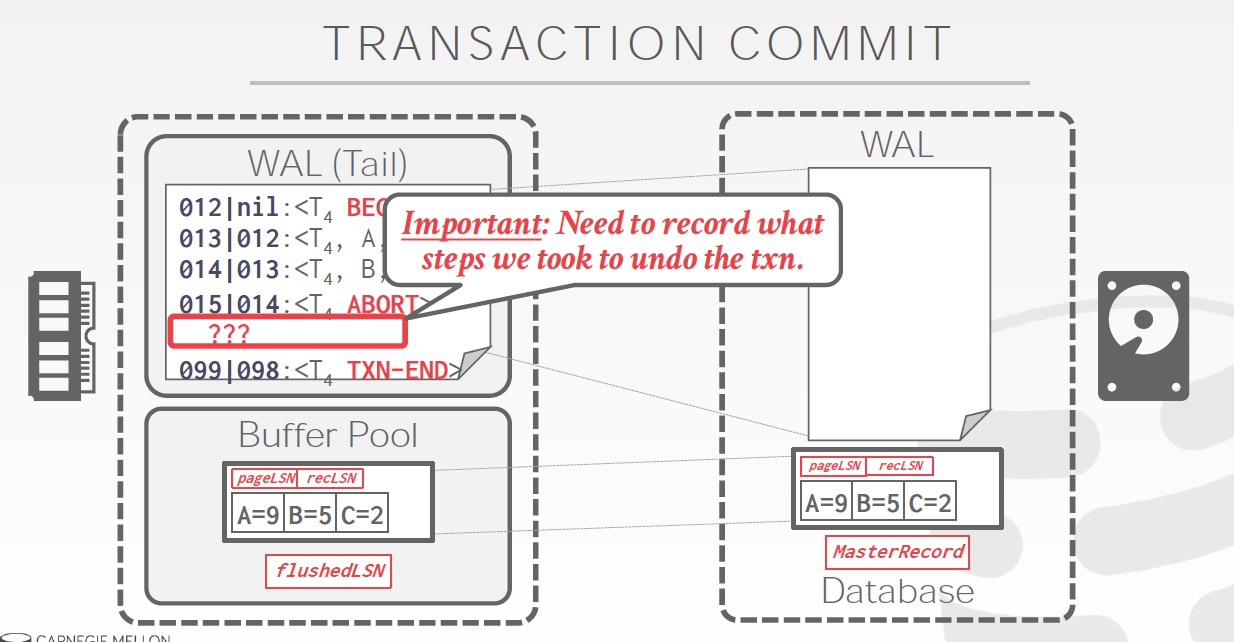

这里是Abort的过程,
写入abort日志后,写入CLR日志
CLR日志中,关键的有,
prevLSN,011指向abort无需操作跳过,所以实际指向002
before,after,可以看到和002相反,起到undo的效果
undonext,下一条需要undo的log,001是begin也无需操作,并且001的preLSN是nil,说明txn已经结束
所以写入txn-end


Checkpoint
Non-fuzzy,停止新的TXN,等旧的TXN都结束,把dirty page写回disk
这样这些txn的更新数据都已经落盘了,那这时redo,undo日志也就没用了,可以删除,也就完成了checkpoint,因为后面replay从checkpoint开始
但是non-fuzzy太暴力了
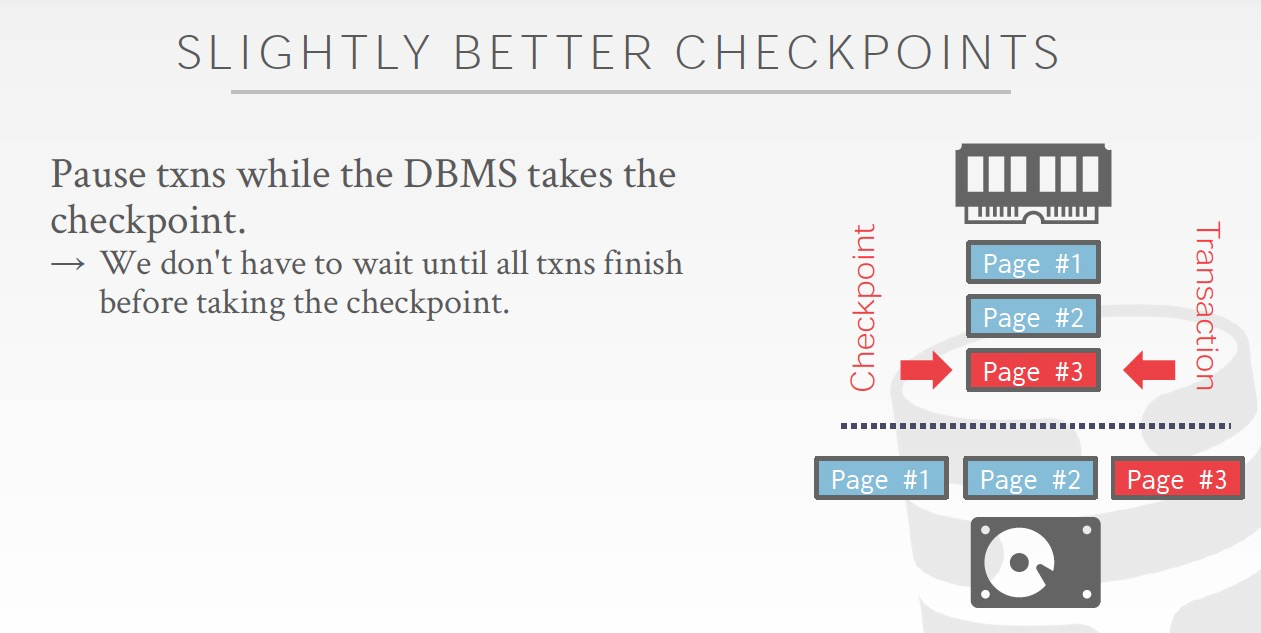
稍微好些的方案,虽然需要暂定当前的txns做checkpoint,但是不用等当前active的transactions结束
由于现在transaction还在进行,所以有部分数据更新在memory中,所以cp需要把memory中的page也保存到磁盘上(由于不用更新原先的page,应该可以顺序写下去),应该只需要保存dirty的page
这里在dirty page有个recLSN,来表示page从哪一条log开始变的dirty的,很关键



这里是个例子,
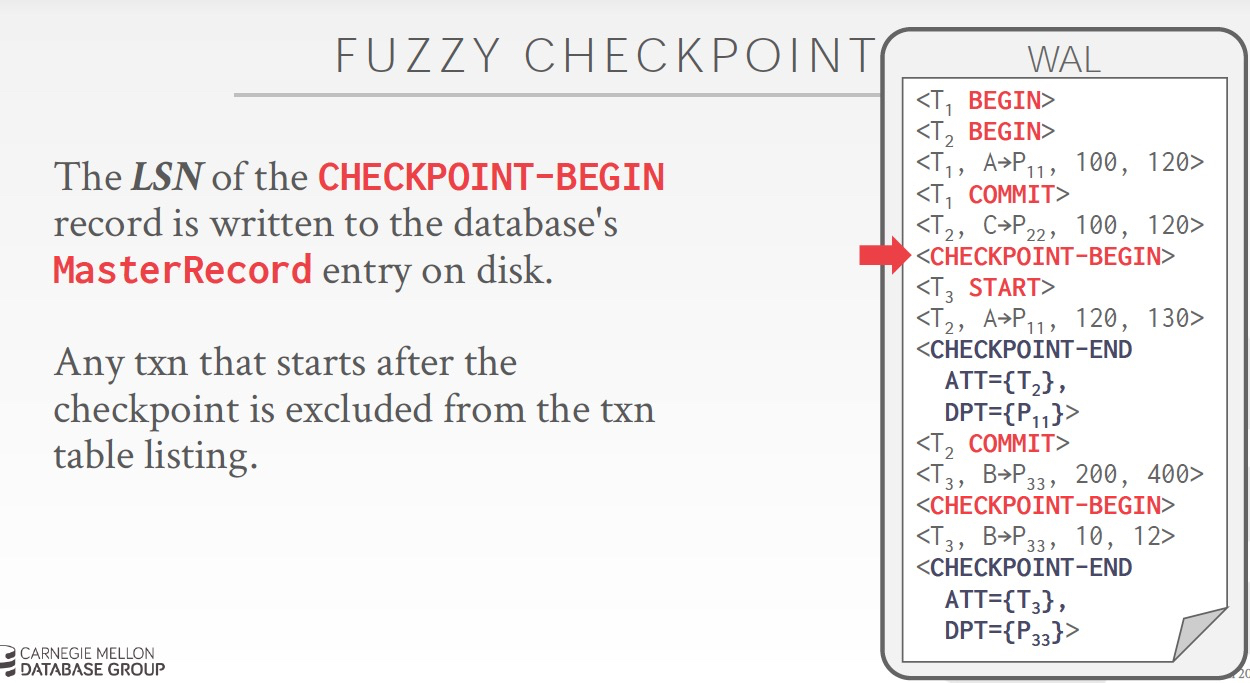
做checkpoint的时候需要stop world,checkpoint做完需求往日志里面记录一条checkpoint log,并且附带ATT,表示cp时仍活跃的txn,DPT,表示cp时dirty的page
对于第一个cp,
ATT = T2,因为T2还没有commit
T2更新了P22,所以P22在DPT中
DPT中还有P11,因为T1虽然commit了,但是数据页P11仍然还在内存中,所以也是dirty

最理想的方式,是checkpoint的时候,不会stop world,txns正常执行
所以这样checkpoint就不是一个点,而是一个过程,和txn一样,需要“Checkpoint-Begin”,“Checkpoint-End”
Master Record是用来记录上一次的checkpoint的LSN,记录的是“Checkpoint-Begin”时间
并且,任何在“Checkpoint-Begin”后,start的txn不会被记录到当前的cp中,很合理

Aries的recovery机制分为3个阶段,

这图,关键是理解Redo和Undo分别做到哪儿
recovery的时候,从磁盘把DPT中的dirty page都读到内存中,由于crash,所以当时数据可能并没有保存到磁盘,所以要从recLSN把log回放redo一遍,来恢复到时的数据
undo,只要cp后fail或abort的txn,就需要把txn完整的undo掉,所以是一直到这个txn最老的log

先看看分析的过程,
分析的目的是找到,在crash的时候,还有哪些txn是active的,还有哪些page是dirty的
所以如果在cp和crash之间看到Txn-end,所以txn已经完全完成,可以从ATT中去掉
cp和crash之间的其他txn,默认设为undo,如果后面看到commit log,改完commit
如果看到DPT中没有的page被更新,加入DPT,并设置recLSN


左图,看到020,所以把T96加入ATT,默认设为undo,P33加入DPT,resLSN设为020
030,根据cp做完的结果,补全ATT和DPT
040,更改T96的状态到Commit
050,因为T96,txn-end,所以从ATT中去掉


从DPT中最小的recLSN开始,每一条log进行Redo,
除非,
1. log更新的page不在DPT,说明已经flush到disk了,不需要redo
2. page虽然在DPT,但是log的LSN比pageLSN大?(这有错,视频他说应该是pageLSN,不理解)
3. 也是说明磁盘上已经有这个更新了,不用redo

做Redo的时候更新pageLSN,并且不会产生额外的log,也不用forcing,比较好理解
对于状态是commit的,写入一条TXN-END,这个就是刚为什么要留着状态为commit的txn在ATT,其实这里TXN-END也不起什么作用
只要有commit log的txn,都会通过redo log被恢复出来

对于,Undo,把ATT中所有状态为Undo的都从最后一条开始,逆序开始undo,undo需要参数CLR log


下面的例子,比较清晰
ATT中有T2,T3,所以会产生两条CLR
T3,undo一次就结束了,所以等WAL flush到dish后,写入TXN-END
T2,要undo 2次才能完成



 浙公网安备 33010602011771号
浙公网安备 33010602011771号