CMU15-445 POJECT#2 Index
书接上文,这次我来到了project2的学习,2021年第二个项目是要实现动态扩展索引(ExtendibleHash),2020年实现的是b+树,因为b+树用途更加广泛,故将2021年和2020年的project2都做了一下~
2021年:EXTENDIBLE HASH INDEX
1. hash方案
linear probe hashing
冲突:在遇到冲突后,线性的往后寻找空槽。
查找:为了查找到元素,必须从索引的位置想向后寻找,直到找到元素、到达表尾部或者到达空槽;
删除:从索引的位置想向后寻找找到元素并删除,删除的位置用需要字符占位(Tombstone),表示此处虽然没有元素,但不能算作空槽,防止查找是提前终止;
Separate Linked List(用于一对多情况)
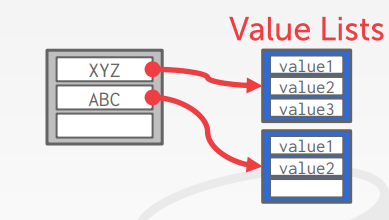
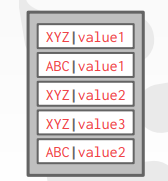
Redundant Keys (用于一对多情况)
Robin hood hashing(罗宾汉哈希)
顾名思义,要劫富济贫(Variant of linear probe hashing that steals slots from "rich" keys and give them to "poor" keys)
Each key tracks the number of positions they are from where its optimal position in the table.
On insert, a key takes the slot of another key if the first key is farther away from its optimal position than the second key.
插入和冲突:每一个key需要记录他们在表中原本的“最佳位置”,就是记录当前位置和原始位置的偏移量,如果在插入时遭遇冲突
1)和linear probe hashing 一样,首先需要开始向后寻找空槽,但不同的是,不一定一定要找到空槽。
2)如果在当前位置元素(a)的偏移量小于要插入元素(b)在此处的偏移量,则将元素(b)插入此处;
3)然后对元素a继续执行1)
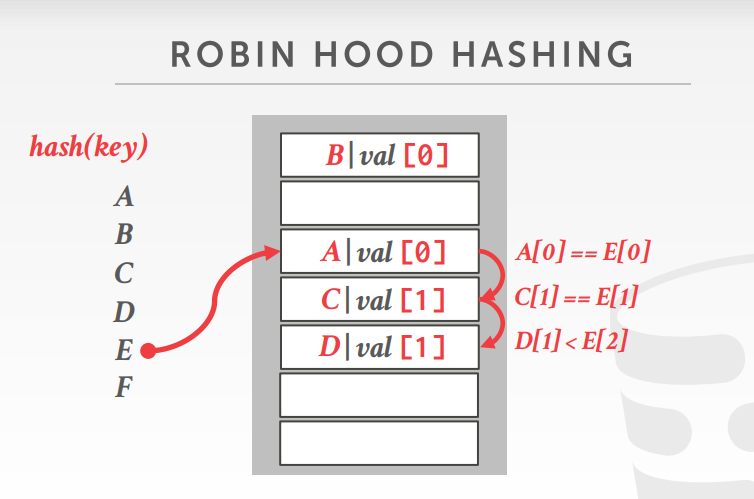
此时D[1]<E[2]故将E放在D的位置,将D移向下一位。
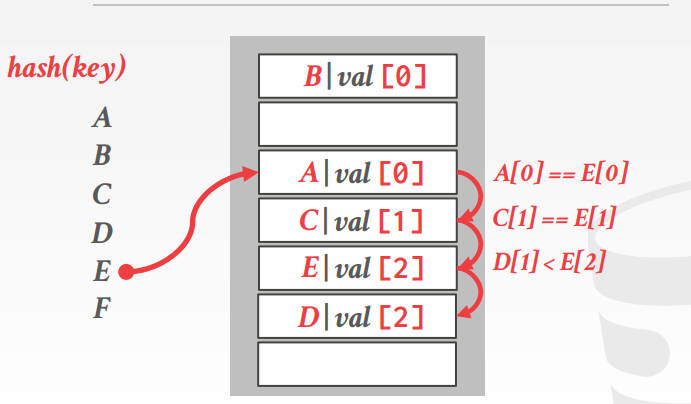
通过上述操作,可以使得每次查询时,需要遍历的元素尽量少。
Cuckoo hashing(布谷鸟哈希)
核心思想:使用的多个哈希表,每个表使用不同的哈希函数。(空间换时间)
If no table has a free slot, evict the element from one of them and then re-hash it find a new location.
插入:在插入一个元素的时候,检查每一个表,看是否有空槽(不需要偏移的,就是hash到的位置),如果没有的话,选择一个表中冲突的元素将其驱逐并占据该位置,将他在别的表中重新哈希插入,不断迭代下去,直到有个元素可以一步到位~
Chained hashing
冲突:把冲突的元素(同一hash value的)元素用链表链起来~
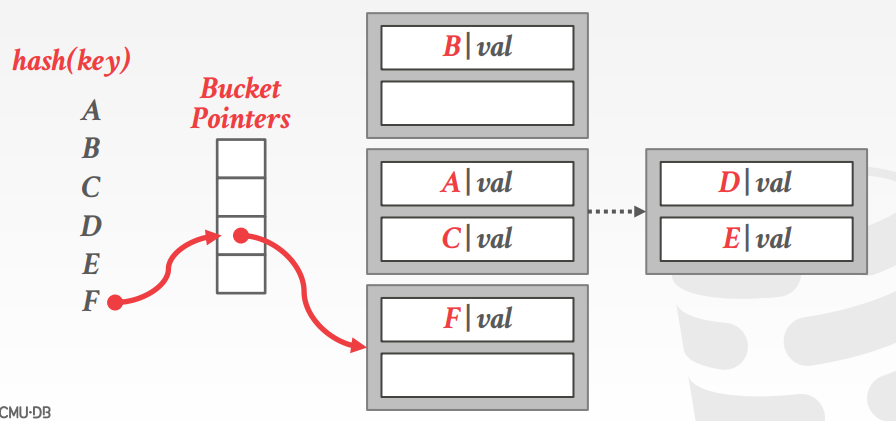
Extendible hashing(本project使用的)
对比于chained hashing,chained hashing容易产生这种现象,某一bucket pointer中包含大量的元素,每次其他bucket pointer没什么元素,这样会导致查找速度变慢(在长长的链表上遍历)。
这时候我们就需要劫富济贫,共同富裕,所以需要对bucket动态扩展,像下图所示:
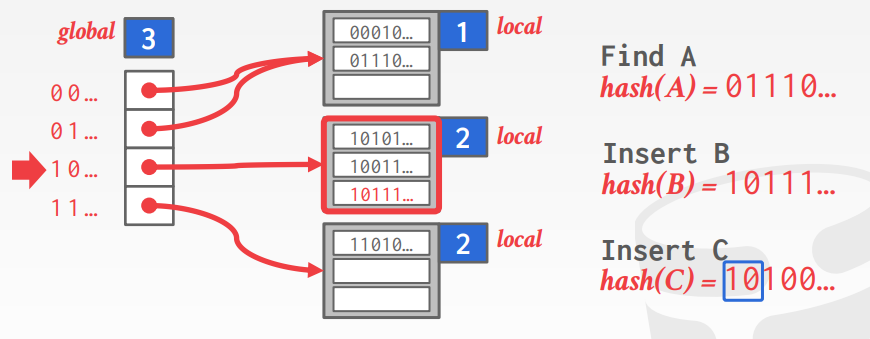
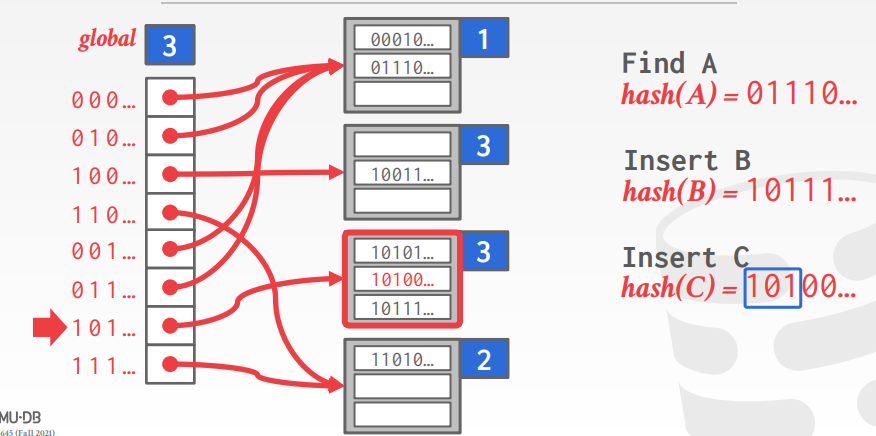
把长长的链表分成两部分。这就是Extendible hashing要做的。
2. 实现
这里就不详细说了,把大概思路和遇到的难点问题在此阐述一下。
ExtendibleHashTable
这个类对上层提供三个主要接口,GetValue、Insert和Remove。
这个类主要干的事就是:
- 1.创建和管理目录页;
- 2.对于给定key的查找,在目录页中通过hash找到这个key位于哪一页,再交由下层去该页中查找数据value,并将value返回;
- 3.对于给定key的插入,在目录页中通过hash找到这个key应该位于哪一页,如果该页未满,则将数据直接插入,否则需要将页中内容划分到一个新的页中,并设置新的页在目录页中内容,如果此时目录中索引已满,需要先扩展索引(翻倍),这里主要通过对local_depth和global_depth设置来完成。
- 4.对于给定key的删除,在目录页中通过hash找到这个key应该位于哪一页,再交由下层去该页中查找数据value并删除,删除后,判断该页是否为空,如果为空,则需要将该页merge到相应页中(通过local_depth决定)。
- 5.其中,页是由上一个实验的buffer pool manager 那里得到的。
HashTableDirectoryPage
这个类主要用于管理目录页,主要是记录hash值(bucket id)和页号的对应关系、设置local depth和global_depth。
HASH_TABLE_BUCKET_TYPE
这个类用于管理数据页的页内查找、插入和删除等操作。
* Bucket page format (keys are stored in order):
* ----------------------------------------------------------------
* | KEY(1) + VALUE(1) | KEY(2) + VALUE(2) | ... | KEY(n) + VALUE(n)
* ----------------------------------------------------------------
其中,有两个数组比较关键,occupied_和readable_
occupied_:表示该位置之前的数据是使用过的(每次遍历occupied_[i]==false之后的数据就可以不同遍历了)
readable_:表示该位置是包含可用的实际数据的。
如GetValue:
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_BUCKET_TYPE::GetValue(KeyType key, KeyComparator cmp, std::vector<ValueType> *result) {
bool is_find = false;
for (uint32_t i = 0; i < BUCKET_ARRAY_SIZE; ++i) {
if (!IsOccupied(i)) {
break;
}
if (IsReadable(i) && cmp(KeyAt(i), key) == 0) {
result->emplace_back(ValueAt(i));
is_find = true;
}
}
return is_find;
}
难点:
对于锁的使用,我的理解是一般要先释放锁,再将该页unpin,否则如果先unpin了,并被buffer pool给换出内存了,那该页的lock字段也无效了。此外,该项目本来读锁和写锁的实现很经典,贴在此处~(方便我以后回顾)
class ReaderWriterLatch {
using mutex_t = std::mutex;
using cond_t = std::condition_variable;
static const uint32_t MAX_READERS = UINT_MAX;
public:
ReaderWriterLatch() = default;
~ReaderWriterLatch() { std::lock_guard<mutex_t> guard(mutex_); }
DISALLOW_COPY(ReaderWriterLatch);
/**
* Acquire a write latch.
*/
void WLock() {
std::unique_lock<mutex_t> latch(mutex_);
while (writer_entered_) {
reader_.wait(latch);
}
writer_entered_ = true;
while (reader_count_ > 0) {
writer_.wait(latch);
}
}
/**
* Release a write latch.
*/
void WUnlock() {
std::lock_guard<mutex_t> guard(mutex_);
writer_entered_ = false;
reader_.notify_all();
}
/**
* Acquire a read latch.
*/
void RLock() {
std::unique_lock<mutex_t> latch(mutex_);
while (writer_entered_ || reader_count_ == MAX_READERS) {
reader_.wait(latch);
}
reader_count_++;
}
/**
* Release a read latch.
*/
void RUnlock() {
std::lock_guard<mutex_t> guard(mutex_);
reader_count_--;
if (writer_entered_) {
if (reader_count_ == 0) {
writer_.notify_one();
}
} else {
if (reader_count_ == MAX_READERS - 1) {
reader_.notify_one();
}
}
}
private:
mutex_t mutex_;
cond_t writer_;
cond_t reader_;
uint32_t reader_count_{0};
bool writer_entered_{false};
};
2021年:B+ tree
B+树
B+树是一棵M叉平衡树,并确保树中数据是有序的,使得查询、顺序遍历、插入和删除的时间复杂度为O(logn);并且具有以下属性:
- 1.完全平衡树,即他的所有叶节点都在相同的深度;
- 2.每一个非根的节点保存的key的个数#key满足:
M/2-1<=#key<=M-1 - 每一个内部节点(非叶节点)如果有k个key,则他就有k+1个非空孩子;
他的每个节点又包含如下性质:
- 1.包含着key/value对数组(保持key有序);
- 2.内部节点和叶节点的value是不同的,一个是子节点的指针,一个是真正的value;
实现
和动态扩展哈希一样,我的实现方式也是自底向上的,即先实现单个节点内的各类操作,再实现上层的查询、插入、删除以及页之间的各种操作。
1. 页内操作
和上一个project各个页之间是独立的不同,B+树的页之间有继承关系,即LeafPage和InternalPage继承自BPlusTreePage,因为B+树的页面有一部分的数据布局是相同的,可以复用;
BPlusTreePage中定义了LeafPage和InternalPage都包含的信息,如页面类型、日志记录项、当前大小、最大容量等等
InternalPage中主要做的事有:
- 定义key/value(page_id)数组;(与叶节点不同,0的位置没有key值只有value)
- 定义了页面内部的插入、删除和查询操纵;
- 定义了页面间管理的一些辅助函数,如把一组key/value移入到兄弟节点等
LeafPage中做的事和InternalPage差不多;
2. 上层实现
查询:从根节点开始向下找到叶节点,并通过叶节点找到目标值;
插入:比较复杂,主要分为两部分;
- 1.对于空树,创建新页面,并将根页面指向它,初始化根节点,将数据插入;
- 2.对于非空树,首先找到key对应的叶节点;然后将数据插入叶节点中,此时如果叶节点未满则直接返回即可;
如果叶节点已满,则需要将叶节点划分为两部分,将新划分出的叶节点插入到父节点中;此时有可能父节点也满了,则需要进一步划分;
最后有可能导致根节点也满了,此时需要将根节点划分,并生成新的根节点。- 这里需要注意的是: 1. 在划分叶子节点时候,在原节点的右边产生新的叶节点,方便更新sibling指针;2.在划分根节点的时候,需要判断此时根节点是否为叶节点;
删除:(大致过程)
- 找到叶节点p,进入2;
- 删除p中元素,如果p不为根,进入3;如果p为根,若p为叶且p中无元素,删除根节点,更新树为空树;如果p为根且p不为叶且p中元素小于等于1,说明树中只有一个叶节点在记录数据,将根节点更新为p的唯一子节点;进入6;
- 如果p大小小于容量的一半,进入4,否则进入6;
- 判断p的左右兄弟p1(如果有的话),如果能将p的元素并p1中,则将p并入,并将p更新为p的父节点,进入2;否则进入5;
- 此时说明p1中元素较多,无法将p并入,这时只须将p1中的一个元素拿过来一个放入p中即可,进入6;
- 结束。
- 其中需要注意的是,在4时,需要始终将右边节点并入左边节点中(便于更新sibling),如果p1位于p右边,只swap(p1,p)即可~(指针互换)
迭代器:由于B+树支持顺序遍历,所以实现迭代器,以提供顺序遍历的接口。为了从头顺序遍历,需要提供找到最小元素的接口(只需要找到最左边叶节点即可)。
- 这里的难点在于,何时应该取出一页,即何时从缓存池中Fetch和Pin页(即告诉缓存这一页正在被cpu使用),如果过于频繁,可能导致缓存池不断从磁盘中取数据;但如果过少,可能导致页长期存在与缓存中且处于不能被换出的状态,导致缓存被占。
- 主要做的事是重载了++;
3. 并发实现
为了使得可以进行索引,使用crabbing technique,使得尽可能少的页被上锁,提高效率;
Search: Starting with root page, grab read (R) latch on child Then release latch on parent as soon as you land on the child page.
Insert: Starting with root page, grab write (W) latch on child. Once child is locked, check if it is safe, in this case, not full. If child is safe, release all locks on ancestors.
Delete: Starting with root page, grab write (W) latch on child. Once child is locked, check if it is safe, in this case, at least half-full. (NOTE: for root page, we need to check with different standards) If child is safe, release all locks on ancestors.
上述safe判断是关键。
由于锁是从根节点开始遍历时就开始添加,所以需要针对与不同的操作,在寻找叶节点时就开始加锁和放锁;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号