1. 创建maven项目
使用IDEA创建maven工程,步骤:File-》New-》Project-》Maven-》maven-archetype-quickstart-》输入maven坐标完成maven工程创建
2. 添加POM文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>UDF</artifactId>
<version>1.0-SNAPSHOT</version>
<name>UDF</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>3.0.0-cdh6.3.1</hadoop.version>
<hive.version>2.1.1</hive.version>
</properties>
<!--CDH版本需要添加repository,apache版本不需要-->
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<!--添加Hadoop依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!--添加Hive依赖-->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
</dependency>
</dependencies>
<build>
<pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
<plugins>
<!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle -->
<plugin>
<artifactId>maven-clean-plugin</artifactId>
<version>3.1.0</version>
</plugin>
<!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging -->
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
</plugin>
<plugin>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-install-plugin</artifactId>
<version>2.5.2</version>
</plugin>
<plugin>
<artifactId>maven-deploy-plugin</artifactId>
<version>2.8.2</version>
</plugin>
<!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle -->
<plugin>
<artifactId>maven-site-plugin</artifactId>
<version>3.7.1</version>
</plugin>
<plugin>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.0.0</version>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
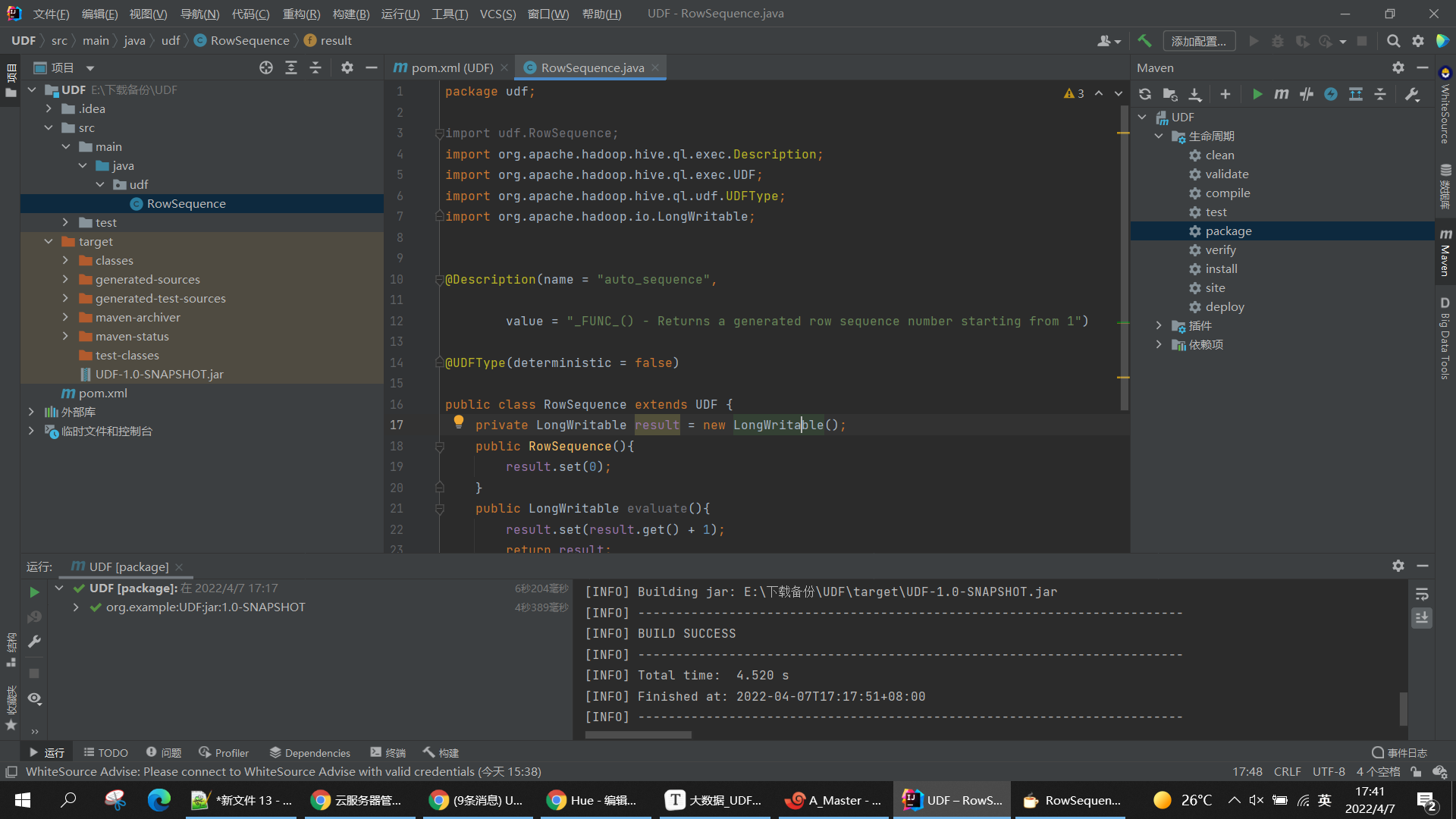
3. 编写UDF函数,并打成JAR包
package udf;
import udf.RowSequence;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.ql.udf.UDFType;
import org.apache.hadoop.io.LongWritable;
@Description(name = "auto_sequence",
value = "_FUNC_() - Returns a generated row sequence number starting from 1")
@UDFType(deterministic = false)
public class RowSequence extends UDF {
private LongWritable result = new LongWritable();
public RowSequence(){
result.set(0);
}
public LongWritable evaluate(){
result.set(result.get() + 1);
return result;
}
}
![]()
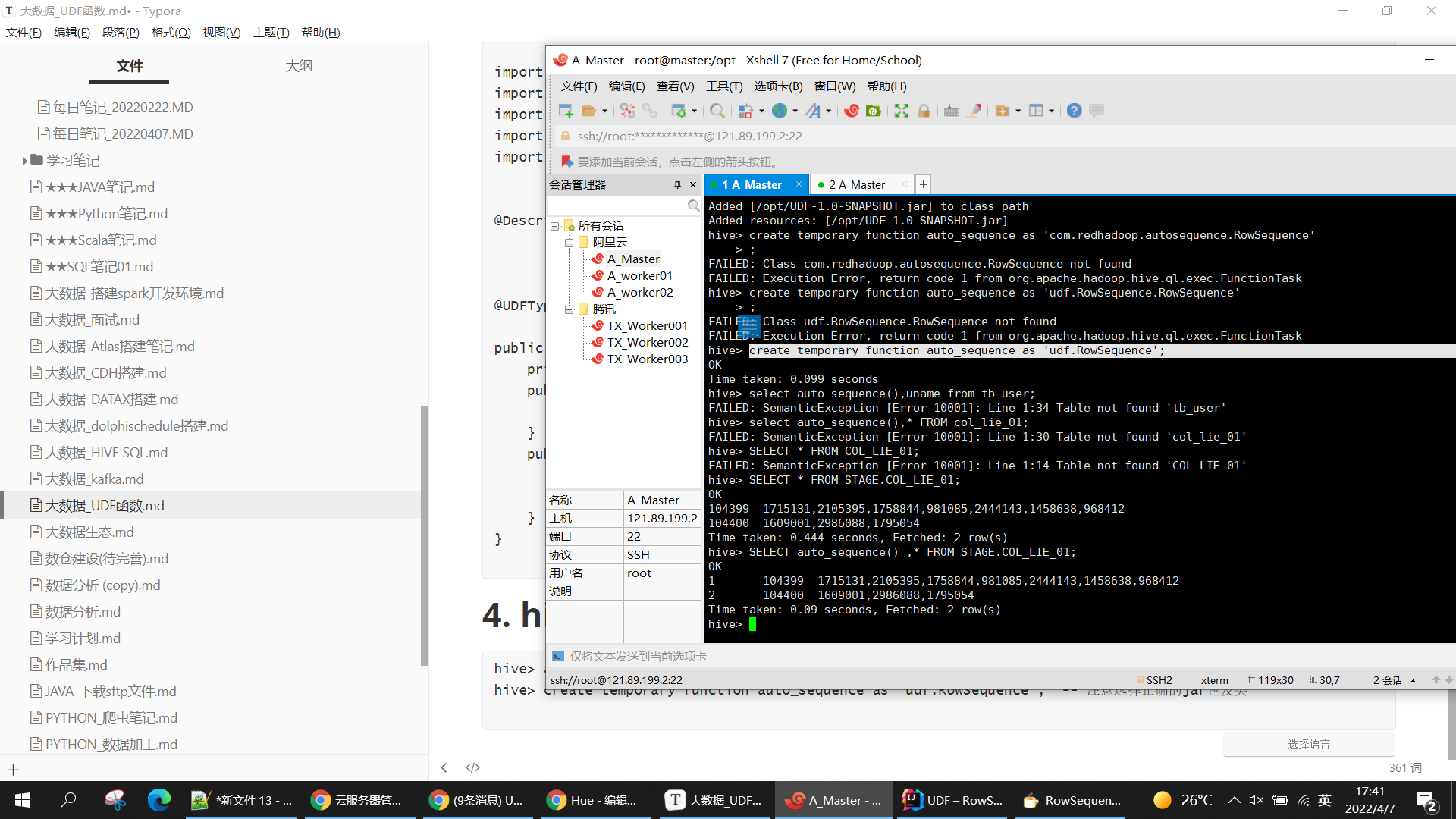
4. hive添加UDF 函数
hive> add jar /opt/UDF-1.0-SNAPSHOT.jar;
hive> create temporary function auto_sequence as 'udf.RowSequence'; -- 注意选择正确的jar包及类
hive> SELECT auto_sequence() ,* FROM STAGE.COL_LIE_01; -- 测试结果
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号