PYTHON爬虫
1. 作品展示
1.1 爬取贝壳二手房进行时
https://v.youku.com/v_show/id_XNTg0ODI1Njg1Mg==.html
1.2 爬取美团商家进行时
https://v.youku.com/v_show/id_XNTg0ODI1ODQ3Ng==.html
1.3 爬虫编写成GUI程序
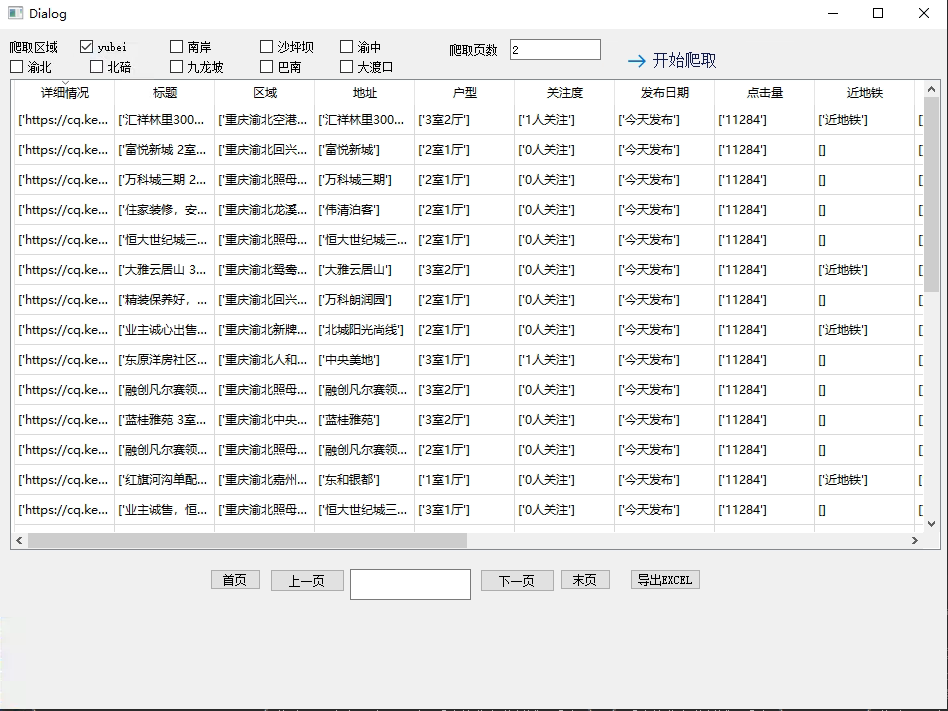
2. 编程思路
1.分析网页源代码
2.编写主函数,访问网页的主循环
3.定义函数
3.1 模拟用户登陆
3.2 反爬
3.2.1 虚拟IP
3.2.2 通过验证
3.2.3 设置访问延迟
3.2.4 设置验证码通过
3.3 通过正则或xpath 提取需要的信息
3.4 输出数据(csv,pandas)
3.5 数据处理,存入数据库
3.6 编写简单脚本,每天定时更新
4.加入gui程序
3. 爬虫代码
3.1 爬取贝壳二手房
import requests
from lxml import etree
import re
## 作者:付博
## 用途:爬取二手房信息
# 存放重庆的市区拼写的列表
regions = ['yubei']
# 自定义一个爬虫函数
def findInfo(url):
with open(r'C:\Users\Administrator\Desktop\python爬虫\HouseData.csv', "a", encoding='utf-8') as f: # 打开一个csv文件将爬取的数据存放到文件中
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ' \
'(KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
headers = {'User-Agent': user_agent}
resp = requests.get(url, headers=headers).text
# print(resp) # 打印网页代码内容
# 对网页进行解析,解析为Element对象,可以使用xpath方法
tree = etree.HTML(resp, etree.HTMLParser())
print("tree:", tree)
# 将找到的li标签(一套房子的信息)内容存放到列表中
infos = tree.xpath('//li[@class="clear"]')
print("infos:" , infos)
for info in infos:
# 详情页
# xpath("//a/@href") # www.some.com
Detail= str(info.xpath('./a/@href'))
print("Detail:",Detail)
# 一层一层的找到每条信息对应的标签
title = info.xpath('./a/img/@alt')
title = str(title).replace(",","")
print("title:",title)
RegionA = re.findall(r'重庆.*二手房',str(title))
print("RegionA:",RegionA)
# 爬取房屋地段信息,并去除房屋地段信息中的空格符
address = info.xpath('./div[@class="info clear"]/div[@class="address"]/div[@class="flood"]/div[@class="positionInfo"]/a/text()')
print("address:",address)
# 其他房屋基本信息,使用正则表达式把爬到的一整串信息分割成多条
otherInfo = info.xpath('./div[@class="info clear"]/div[@class="address"]/div[@class="houseInfo"]/text()[2]')
otherInfo = str(otherInfo[0]).split()
print("otherInfo:", otherInfo)
houseType = list(filter(lambda x: re.search(r'.*室.*厅', x) != None, otherInfo))
houseFloorA = list(filter(lambda x: re.search(r'.*楼层', x) != None, otherInfo))
houseFloorB = list(filter(lambda x: re.search(r'.*共.*层.*', x) != None, otherInfo))
BuildingYear = list(filter(lambda x: re.search(r'.*年建', x) != None, otherInfo))
houseArea = list(filter(lambda x: re.search(r'.*平米', x) != None, otherInfo))
houseOrientation = list(filter(lambda x: re.search(r'东|南|西|北', x) != None, otherInfo))
houseOrientation = str(houseOrientation).replace(",","")
# houseOrientation = otherInfo[2]
#关注及发布日期
followinfo = info.xpath('./div[@class="info clear"]/div[@class="address"]/div[@class="followInfo"]/text()')
followinfo = str(followinfo[1]).split()
followinfoA = list(filter(lambda x: re.search(r'.*关注', x) != None, followinfo))
issueDate = list(filter(lambda x: re.search(r'.*发布', x) != None, followinfo))
clickData = info.xpath('./div[@class="info clear"]/div[@class="listButtonContainer"]/div/@data-click-evtid')
print("followinfo:",followinfo)
print("followinfoA:", followinfoA,"issueDate:", issueDate,"clickData:",clickData)
#地铁信息
subway = info.xpath('./div[@class="info clear"]/div[@class="address"]/div[@class="tag"]/span[@class="subway"]/text()')
print("subway:", subway)
# 税收
tax = info.xpath('./div[@class="info clear"]/div[@class="address"]/div[@class="tag"]/span[@class="taxfree"]/text()')
print("tax:", tax)
# 房屋的总价/单价/ID
price = info.xpath('./div[@class="info clear"]/div[@class="address"]/div[@class="priceInfo"]/div[@class="totalPrice"]/span/text()')
price = str(price[0]).split()
print("price:",price)
UnitPrice = info.xpath('./div[@class="info clear"]/div[@class="address"]/div[@class="priceInfo"]/div[@class="unitPrice"]/@data-price')
print("UnitPrice:",UnitPrice)
HouseID = info.xpath('./div[@class="info clear"]/div[@class="address"]/div[@class="priceInfo"]/div[@class="unitPrice"]/@data-hid')
print("HouseID:", HouseID)
print("houseType:",houseType,"houseFloorA:",houseFloorA,"houseFloorB:",houseFloorB,"BuildingYear:",BuildingYear,"houseArea:",houseArea,"houseOrientation:",houseOrientation)
# 把爬到的信息依次写入文件中
f.write("{0},{1},{2},{3},{4},{5},{6},{7},{8},{9},{10},{11},{12},{13},{14},{15},{16},{17}\n".format(Detail, title, RegionA, address, houseType, followinfoA,issueDate, clickData, subway, tax,price,UnitPrice,HouseID,houseFloorA, houseFloorB, BuildingYear, houseArea, houseOrientation))
#访问地址
#伪装用户
#读取网页信息并解析,转换成可读形式
#数据清洗,整理,输出
if __name__ == '__main__':
print("现在开始爬取贝壳找房重庆市二手房信息,请耐心等候!")
for region in regions:
for i in range(1,100): # 每个区爬取100页信息
url = 'https://cq.ke.com/ershoufang/' + region + '/pg' +str(i) + '/' # 拼接URL地址
findInfo(url)
# 每爬取一个区一个网页的信息就输出一句提示
print('{} has been writen.'.format(region))
print("爬取结束!")
#难点1:理解if__main__
#难点2:理解函数的参数传递
3.2 爬取美团商家
import requests
from lxml import etree
import re
## 作者:付博
## 用途:爬取美团商家信息
# 存放重庆的市区拼写的列表
regions = ['b5','b2','b4','b6','b3','b12','b10','b7','b9','b13','b4737','b4738','b665','b4739','b664','b666']
# 自定义一个爬虫函数
def findInfo(url):
with open(r'C:\Users\Administrator\Desktop\python爬虫\美团\StroeData.csv', "a", encoding='utf-8') as f: # 打开一个csv文件将爬取的数据存放到文件中
# cookie是登陆自己账号后,复制的浏览器中的cookie,目的是为了模拟用户登陆
cookie = 'uuid=ad817e8c85ae4cdea591.1623375282.1.0.0; _lxsdk_cuid=179f8b4de48c8-0a53fb0183e15d-36664c08-1fa400-179f8b4de48c8; mtcdn=K; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; userTicket=yXiAvKzcWxsbnwjVZCQGSEPmYQPKqIMRqXSRlpzb; lsu=; _lxsdk=179f8b4de48c8-0a53fb0183e15d-36664c08-1fa400-179f8b4de48c8; client-id=48637857-7092-4204-84e8-1e38b6599e49; _hc.v=f464619d-db04-082a-e568-098da159afd5.1623377436; ci=10; rvct=10%2C114; lat=31.24371; lng=121.55373; lt=hDTHILygZDkadh7mL1gnidJtaqAAAAAAyQ0AABocWb_CkWshOqoOZ8m9WAKih2botyE-h1PX3DqbLaZHxKHnGvBhsDU6e_V_NAixiA; u=847871187; n=Qrg508006223; token2=hDTHILygZDkadh7mL1gnidJtaqAAAAAAyQ0AABocWb_CkWshOqoOZ8m9WAKih2botyE-h1PX3DqbLaZHxKHnGvBhsDU6e_V_NAixiA; unc=Qrg508006223; __mta=244038330.1623377269994.1623387755650.1623391097668.4; firstTime=1623393772891; _lxsdk_s=179f9c98bda-93d-3c-af4%7C%7C6'
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
headers = {'User-Agent': user_agent,'Cookie':cookie}
# 用requests获取网页源代码
resp = requests.get(url, headers=headers).text
print('resp:',resp) # 打印网页代码内容
# 运用正则表达式,截取源代码中需要的那一部分
infos = re.findall(r'"poiInfos":.*"comHeader":',resp)
print("infos:" , infos)
# 在截取的代码中,循环再截取
for i in range(0,15):
# 找出ID
StoreID = re.findall(r'"poiId":\d{0,30}',str(infos))[i]
print("StoreID:", StoreID)
StoreID = re.split('"poiId":',StoreID)[1]
print("StoreID:", StoreID)
# 找出商家名称
title = re.findall(r'","title":".*?","avgScore"',str(infos))[i]
print("title:", title)
title = title.replace('"title":"','')
title = title.replace('","avgScore"', '')
print("title:", title)
# 找出商家评分
avgScore = re.findall(r'"avgScore":.*?,"allCommentNum"', str(infos))[i]
print("avgScore:", avgScore)
avgScore = avgScore.replace('"avgScore":', '')
avgScore = avgScore.replace(',"allCommentNum"', '')
print("avgScore:", avgScore)
# 找出商家地址
address = re.findall(r'"address":".*?","avgPrice', str(infos))[i]
print("address:", address)
address = address.replace('"address":"','')
address = address.replace('","avgPrice','')
print("address:", address)
# 找出商家地址,商家名称、客单价
avgPrice = re.findall(r'"avgPrice":.*?,"dealList"', str(infos))[i]
print("avgPrice:", avgPrice)
avgPrice = avgPrice.replace('"avgPrice":','')
avgPrice = avgPrice.replace(',"dealList"', '')
print("avgPrice:", avgPrice)
# 把爬到的信息依次写入文件中
f.write("{0},{1},{2},{3},{4}\n".format(StoreID, title, avgScore, address, avgPrice))
#访问地址
#伪装用户
#读取网页信息并解析,转换成可读形式
#数据清洗,整理,输出
if __name__ == '__main__':
print("现在开始美团商家信息,请耐心等候!")
for region in regions:
for i in range(1,67): # 每个区爬取100页信息
url = 'https://sh.meituan.com/meishi/' + region + '/pn' +str(i) + '/' # 拼接URL地址
print("url:",url)
findInfo(url)
# 每爬取一个区一个网页的信息就输出一句提示
print('{} has been writen.'.format(region))
print("爬取结束!")
#:理解函数的参数传递

 浙公网安备 33010602011771号
浙公网安备 33010602011771号