

深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10811587.html
目录
1. 存在问题
2. 解决方案
3. 神经网络结构
4. 实现代码分析
5. 运行结果
6. 参考文献
1. 存在问题
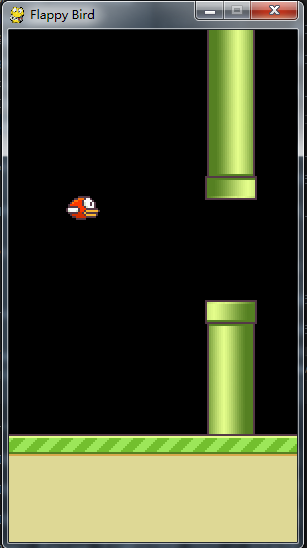
游戏场景:障碍物以一定速度往左前行,小鸟拍打翅膀向上或向下飞翔来避开障碍物,如果碰到障碍物,游戏就GAME OVER!
规则:
图片大小:80 * 80
4 帧作为一组
小鸟行为:向上跳跃或没有任何动作
目标:小鸟如何实现自动躲避障碍物 ?
小鸟飞翔的难点是如何准确判断下一步的动作( up or do nothing),而这正是强化学习想要解决的问题。
因为上一节案例网格的所有状态(state)数目只有 16 种,是一种有限的集合,所以可以先求状态最大价值表 V-Table,后求最优策略表 Q-Table。
但是本节的应用场景有所不同,如果以图片中的像素作为状态,那么状态的种类数:

注:每个像素值范围是 0-255,有 256 种可能,图片大小是 80 * 80,4 帧作为一组。
那么这个状态的总量是非常庞大的,几乎可以认为是一种无限的集合,对于这种情况,该如何处理呢 ?
2. 解决方案
解决这个问题的方案有如下几点:
1> 确定状态:以连续的 4 帧作为一个状态;
2> 采用卷积神经网络来预测状态的每个行为的价值;
3> 神经网络的目标值是通过贝尔曼最优化方程计算状态的最大价值;
第 2>,3> 结合起来就是深度强化学习 DQN(Deep Q Network),也就是强化学习中引入深度学习。
3. 神经网络结构
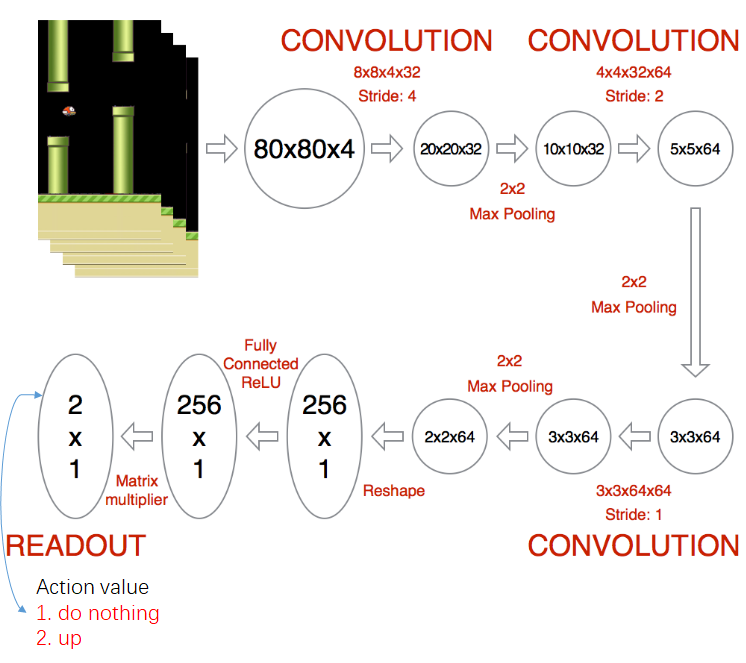
神经网络结构是由 3 个卷积层 + 3 个池化层 + 2 个全连接层组成,这里要注意两点:
1> 特征图输出尺寸和深度的变化
特征图输出尺寸根据如下公式计算:
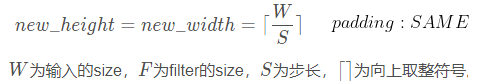
特征图输出深度是由卷积核的深度决定的。
2> 神经网络的输出含义
1 * 2 表示当前状态每个行为产生的价值
4. 代码实现分析
4.1 图片处理
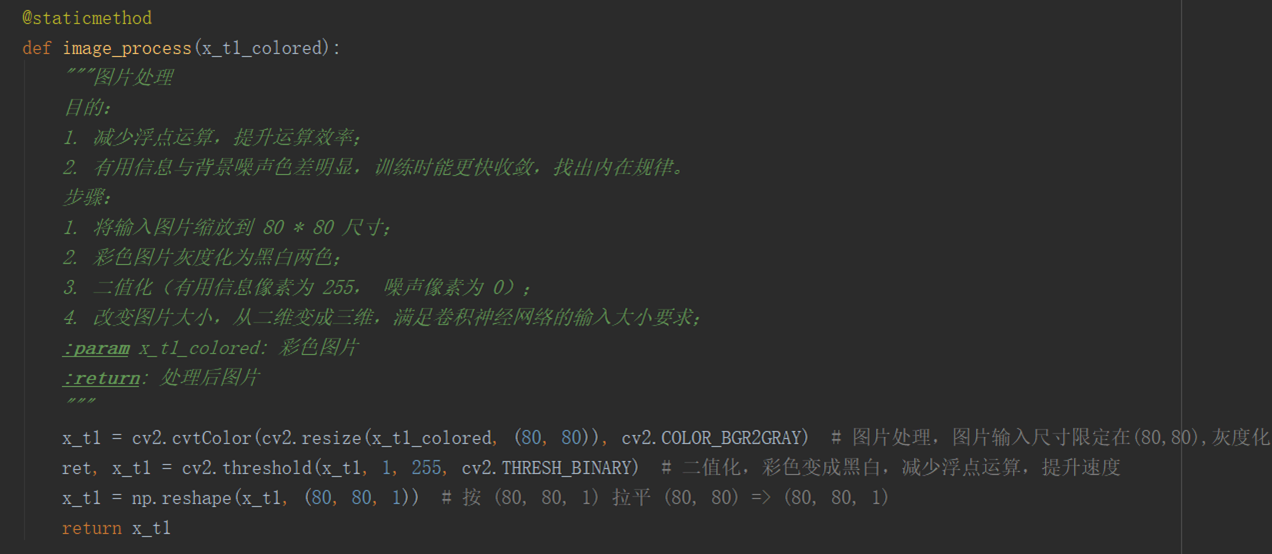
在进入神经网络运算之前,需要对图片进行处理,上面的代码功能是对图片 resize 到 80 * 80 大小,灰度化,二值化,拉平处理,目的有两个:
1> 减少神经网络中的浮点运算(二值化后背景噪声的像素值都为 0, 0 * 任何数 = 0),提升运算效率;
2> 有用信息与背景噪声色差明显(二值化后有用信息像素值都为 255,背景噪声为 0),神经网络在训练时能更快收敛,找出内在规律。
4.2 创建卷积神经网络
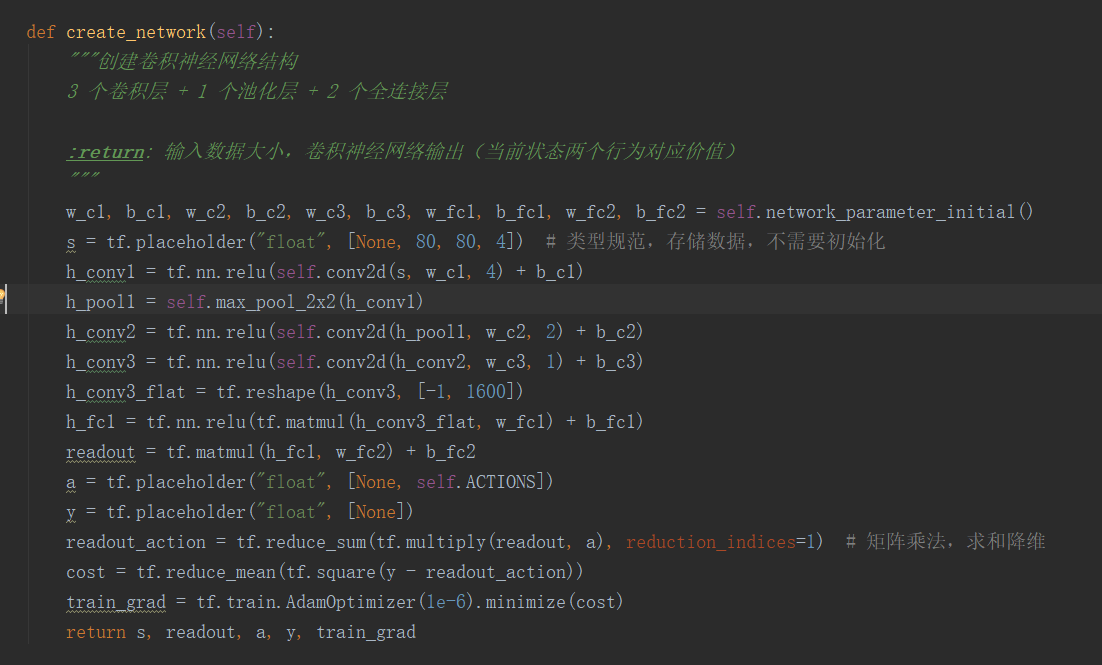
神经网络结构是由 3 个卷积层 + 1 个池化层 + 2 个全连接层组成,跟之前介绍的神经网络结构稍微不一样,之前是 3 个卷积层 + 3 个池化层 + 2 个全连接层组成,
这不影响结果,只要输出都是 1 * 2 就可以了。
注意点:每层运算后输出特征图大小的变化,注意参数大小的设定(卷积核参数,全连接参数);
神经网络的输出是 readout ( 1 * 2),readout_action 是 readout 进行了一个矩阵内积运算,得到结果还是 1* 2 矩阵,然后求和降维,变成 1 * 1,便于后面用 MSE
计算 cost。
4.3 核心方法
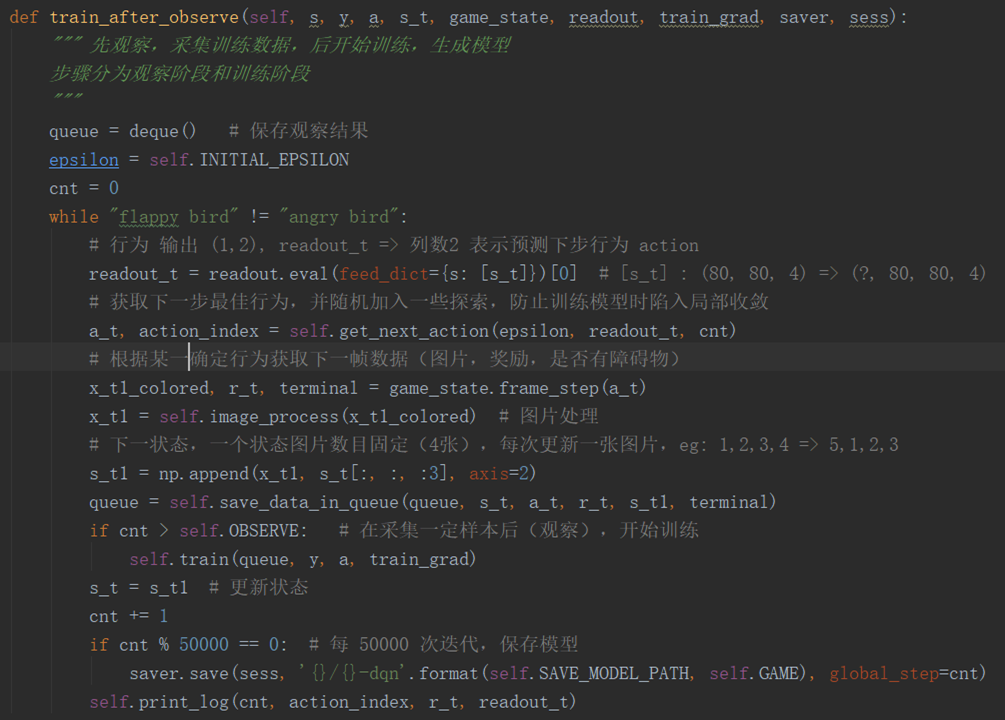
在训练之前,先观察一段时间,采集数据,作为训练时的样本数据。
queue 是保存观察结果的队列,超出设定的最大长度会将最早存入数据丢弃(一段进,另一端出)。
readout.eval 是神经网络运算过程,输入参数是状态(连续 4 帧),输出是状态每个行为对应的回报,
通过 get_next_action 方法获取当前状态下一步最佳行为以及对应索引,当然,在这过程中随机的加入一些探索,
防止训练时陷入局部收敛。
取得最佳行为后,与环境进行交互(game_state.frame_step),获取下一帧图片,即时奖励,是否碰到障碍物这些信息。
然后对下一帧图片进行处理(image_process),缩放尺寸到 80 * 80,灰度化,二值化,拉平处理。
更新图片,组装 4 张图片作为下一个状态s_t1(np.append(x_t1, s_t[:, :, :3]), axis = 2),具体过程如下图:
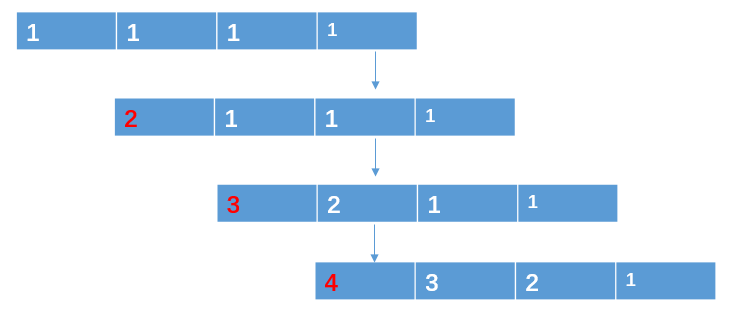
注意:第一个状态的 4 帧图片是将第一张图片复制 3 次,组合 4 张图片。
用 s_t1 更新当前状态 s_t,然后继续循环,当观察的次数超过设定的阈值(self.OBSERVE),就进入训练阶段。
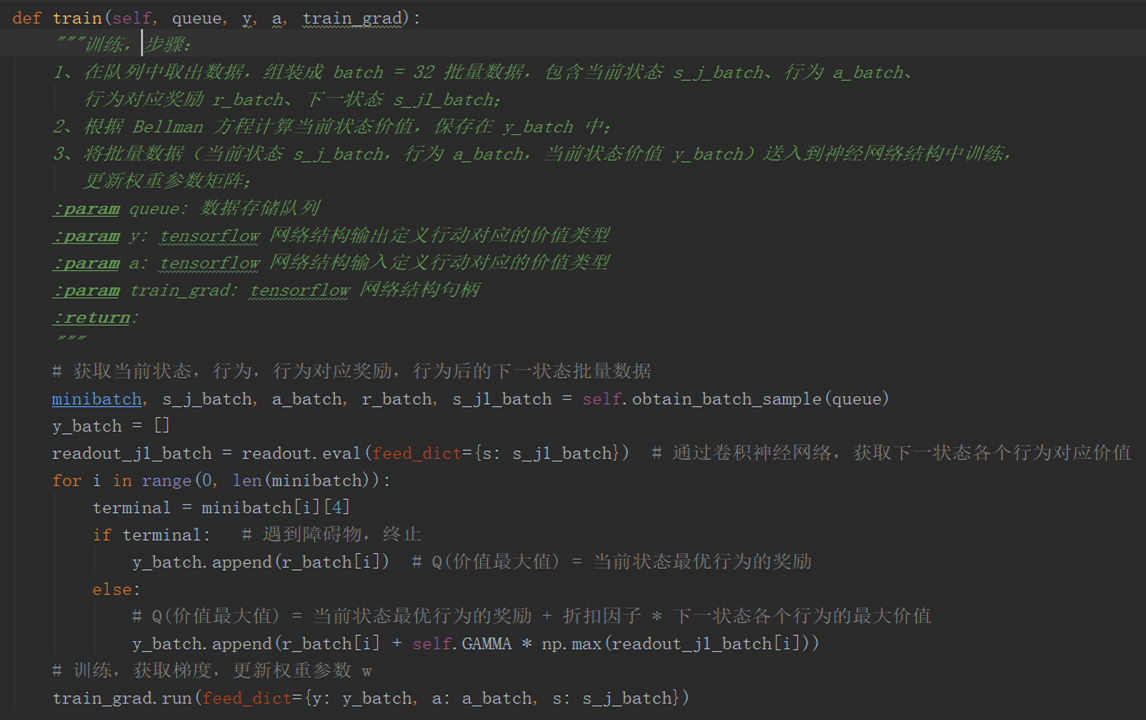
self.obtain_batch_sample 在保存数据队列 queue 中随机提取 batch = 32 批量的数据信息。
s_j_batch: 当前状态的批量数据
a_batch: 行为批量数据
r_batch: 行为对应即时奖励的批量数据
s_j1_batch: 下一状态批量数据
readout.eval: 神经网络的运算过程,这里注意输入是下一状态的数据,那么对应输出是下一状态各个行为的回报。
for 循环内代码目的是求神经网络目标值,通过贝尔曼最优化方程计算状态的最大价值,然后保存在 y_batch 中。

注意,y_batch 也需要满足 batch = 32 的批量数据结果。
将 y_batch, a_batch, s_j_batch 送入到神经网络中,进行训练(train_grad.run),每 50000 次迭代,保存一次模型。
说明:tensorflow saver.save 方法只保存最近 5 次生成的模型
训练好模型之后,就进入到预测阶段:
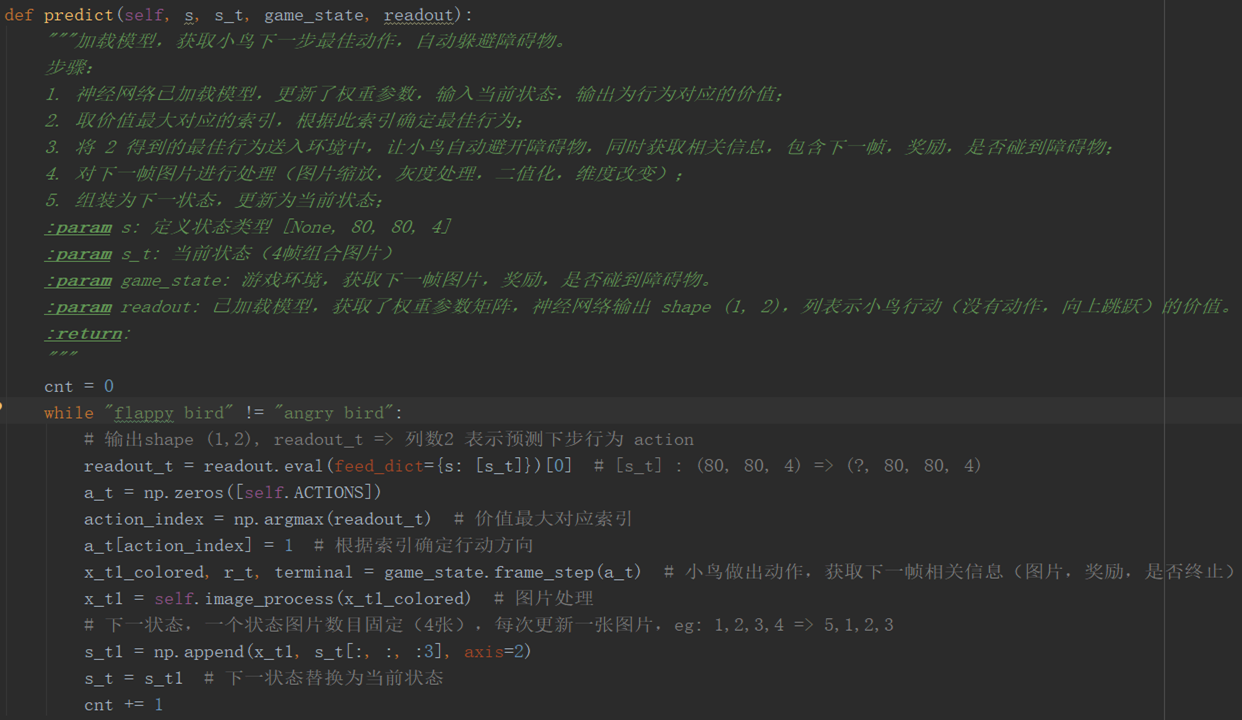
readout.eval 获取当前状态每个行为对应的价值
np.argmax 获取状态最大价值对应的行为索引
根据行为索引,确定最佳行动方向,与环境进行交互(frame_step),小鸟就能做出一个动作,并获取下一帧相关信息,
对下一帧进行图片处理(image_process),更新图片,组装成 4 帧图片作为下一状态,并更新当前状态。
每一次循环,就会产生一个最佳行为,然后与环境交互,小鸟就做出一个最佳的动作,将这些动作串联起来,小鸟就能自动躲避障碍物。
5.运行结果
因为不能上传视频,所以只能截取几张典型图片了。我训练了5650000 次生成的模型,以这个模型预测,小鸟能够自动识别障碍物,不会发生碰撞。
完整样例代码放在百度网盘 :
链接:https://pan.baidu.com/s/1Q68Ono4sSSFpihwcEOr4aw
提取码:p5qz
每个方法都做了比较详细的注释,操作步骤见 .md 文档,感兴趣的话可以下载下来亲自体验一下。
小鸟运行结果图片



在观察,训练时运行代码相关参数打印:

7. 参考文献
[1] https://zhuanlan.zhihu.com/p/35134789
[2] https://github.com/yenchenlin/DeepLearningFlappyBird
[3] https://leovan.me/cn/2020/05/introduction-of-reinforcement-learning/
[4] https://www.leiphone.com/category/academic/y5nyxtWsNUrm37a9.html
[5] https://zhuanlan.zhihu.com/p/25498081
不要让懒惰占据你的大脑,不要让妥协拖垮了你的人生。青春就是一张票,能不能赶上时代的快车,你的步伐就掌握在你的脚下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号