

iOS底层原理(七)多线程(中)
多线程的安全隐患
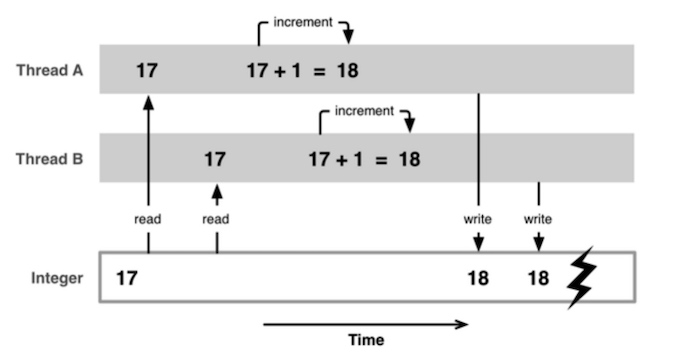
一块资源可能会被多个线程共享,也就是多个线程可能会访问同一块资源;当多个线程访问同一块资源时,很容易引发数据错乱和数据安全问题### 问题案例
卖票和存钱取钱的两个案例,具体见下面代码
@interface BaseDemo: NSObject
- (void)moneyTest;
- (void)ticketTest;
#pragma mark - 暴露给子类去使用
- (void)__saveMoney;
- (void)__drawMoney;
- (void)__saleTicket;
@end
@interface BaseDemo()
@property (assign, nonatomic) int money;
@property (assign, nonatomic) int ticketsCount;
@end
@implementation BaseDemo
/**
存钱、取钱演示
*/
- (void)moneyTest
{
self.money = 100;
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
dispatch_async(queue, ^{
for (int i = 0; i < 10; i++) {
[self __saveMoney];
}
});
dispatch_async(queue, ^{
for (int i = 0; i < 10; i++) {
[self __drawMoney];
}
});
}
/**
存钱
*/
- (void)__saveMoney
{
int oldMoney = self.money;
sleep(.2);
oldMoney += 50;
self.money = oldMoney;
NSLog(@"存50,还剩%d元 - %@", oldMoney, [NSThread currentThread]);
}
/**
取钱
*/
- (void)__drawMoney
{
int oldMoney = self.money;
sleep(.2);
oldMoney -= 20;
self.money = oldMoney;
NSLog(@"取20,还剩%d元 - %@", oldMoney, [NSThread currentThread]);
}
/**
卖1张票
*/
- (void)__saleTicket
{
int oldTicketsCount = self.ticketsCount;
sleep(.2);
oldTicketsCount--;
self.ticketsCount = oldTicketsCount;
NSLog(@"还剩%d张票 - %@", oldTicketsCount, [NSThread currentThread]);
}
/**
卖票演示
*/
- (void)ticketTest
{
self.ticketsCount = 15;
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
dispatch_async(queue, ^{
for (int i = 0; i < 5; i++) {
[self __saleTicket];
}
});
dispatch_async(queue, ^{
for (int i = 0; i < 5; i++) {
[self __saleTicket];
}
});
dispatch_async(queue, ^{
for (int i = 0; i < 5; i++) {
[self __saleTicket];
}
});
}
@end
@interface ViewController ()
@property (strong, nonatomic) BaseDemo *demo;
@end
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
BaseDemo *demo = [[BaseDemo alloc] init];
[demo ticketTest];
[demo moneyTest];
}
@end
解决方案是使用线程同步技术(同步,就是协同步调,按预定的先后次序进行,常见的方案就是加锁
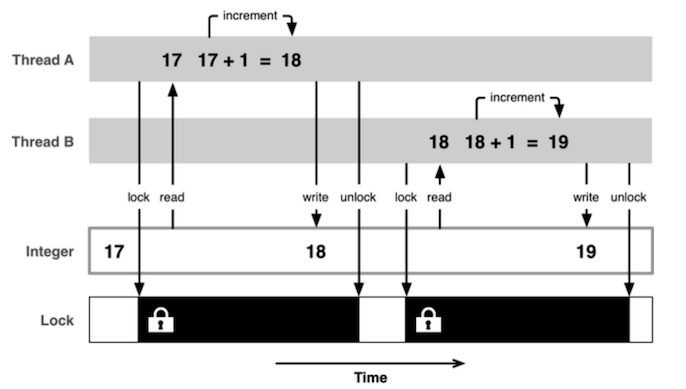
线程同步方案
iOS中的线程同步方案有以下这些
- OSSpinLock- os_unfair_lock- pthread_mutex- dispatch_semaphore- dispatch_queue(DISPATCH_QUEUE_SERIAL)- NSLock- NSRecursiveLock- NSCondition- NSConditionLock- @synchronized#### OSSpinLock
OSSpinLock叫做”自旋锁”,等待锁的线程会处于忙等(busy-wait)状态,一直占用着CPU资源用OSSpinLock来解决上述示例问题
@interface OSSpinLockDemo: BaseDemo
@end
#import "OSSpinLockDemo.h"
#import <libkern/OSAtomic.h>
@interface OSSpinLockDemo()
@property (assign, nonatomic) OSSpinLock moneyLock;
// @property (assign, nonatomic) OSSpinLock ticketLock;
@end
@implementation OSSpinLockDemo
- (instancetype)init
{
if (self = [super init]) {
self.moneyLock = OS_SPINLOCK_INIT;
// self.ticketLock = OS_SPINLOCK_INIT;
}
return self;
}
- (void)__drawMoney
{
OSSpinLockLock(&_moneyLock);
[super __drawMoney];
OSSpinLockUnlock(&_moneyLock);
}
- (void)__saveMoney
{
OSSpinLockLock(&_moneyLock);
[super __saveMoney];
OSSpinLockUnlock(&_moneyLock);
}
- (void)__saleTicket
{
// 不用属性,用一个静态变量也可以
static OSSpinLock ticketLock = OS_SPINLOCK_INIT;
OSSpinLockLock(&ticketLock);
[super __saleTicket];
OSSpinLockUnlock(&ticketLock);
}
@end
static的问题
上面的ticketLock也可以用static来修饰作为内部静态变量来使用
#define OS_SPINLOCK_INIT 0
由于OS_SPINLOCK_INIT就是0,所以才可以用static来修饰;static只能在编译时赋值一个确定值,不能动态赋予一个函数值
// 这样赋值一个函数返回值是会报错的
static OSSpinLock ticketLock = [NSString stringWithFormat:@"haha"];
OSSpinLock的问题
OSSpinLock现在已经不再安全,可能会出现优先级反转问题
由于多线程的本质是在不同线程之间进行来回的调度,每个线程可能对应分配的资源优先级不同;如果优先级低的线程先进行了加锁并准备执行代码,这时优先级高的线程就会在外面循环等待加锁;但因为其优先级高,所以CPU可能会大量的给其分配任务,那么就没办法处理优先级低的线程;优先级低的线程就无法继续往下执行代码,那么也就没办法解锁,所以又会变成了互相等待的局面,造成死锁。这也是苹果现在废弃了OSSpinLock的原因
解决办法
用尝试加锁OSSpinLockTry来替换OSSpinLockLock,如果没有加锁才会进到判断里执行代码并加锁,避免了因上锁了一直在循环等待的问题
// 用卖票的函数来举例,其他几个加锁的方法也是同样
- (void)__saleTicket
{
if (OSSpinLockTry(&_ticketLock)) {
[super __saleTicket];
OSSpinLockUnlock(&_ticketLock);
}
}
通过汇编来分析
我们通过断点来分析加锁之后做了什么
我们在卖票的加锁代码处打上断点,并通过转汇编的方式一步步调用分析

转成汇编后调用OSSpinLockLock

内部会调用_OSSpinLockLockSlow

核心部分,在_OSSpinLockLockSlow会进行比较,然后执行到断点处又会再次跳回0x7fff5e73326f再次执行代码

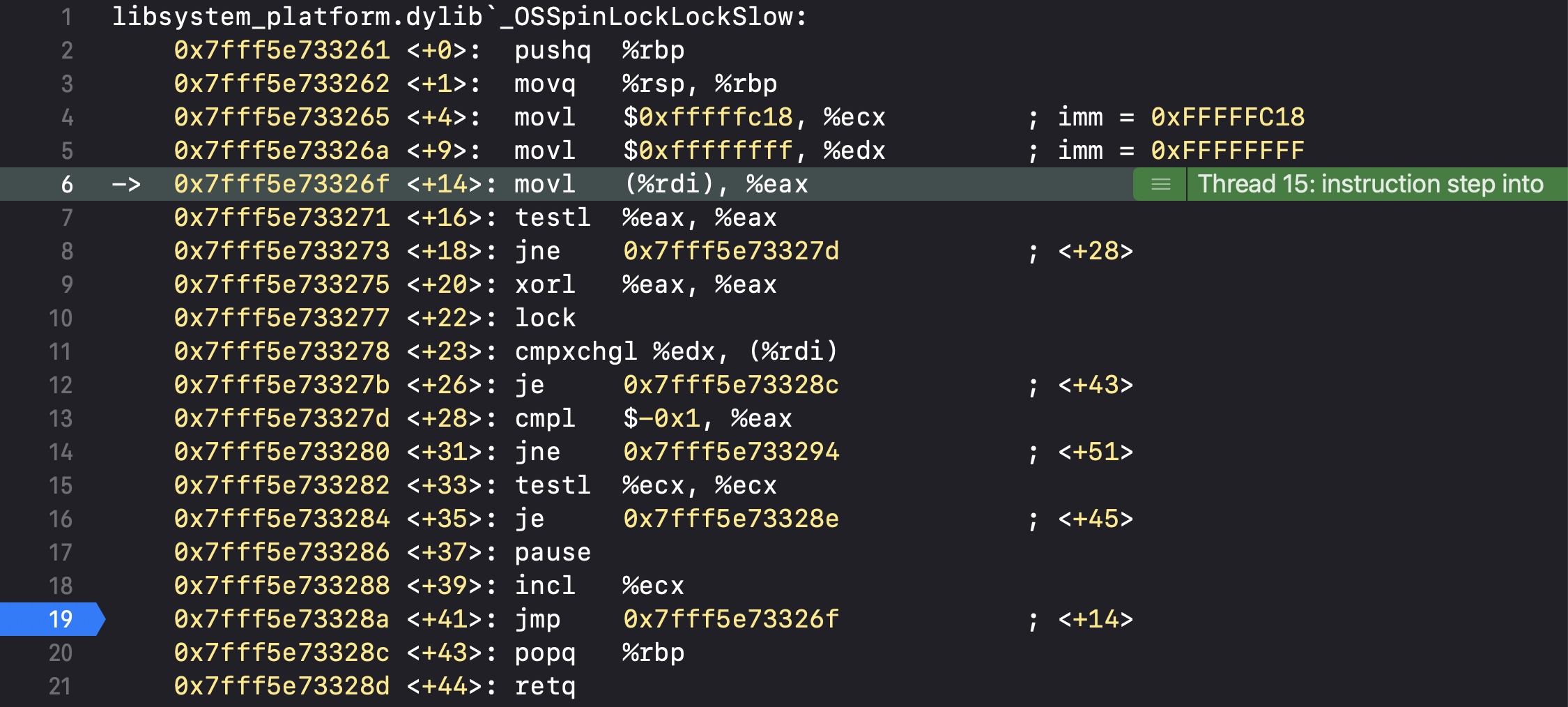
所以通过汇编底层执行逻辑,我们能看出OSSpinLock是会不断循环去调用判断的,只有解锁之后才会往下执行代码
锁的等级
OSSpinLock自旋锁是高等级的锁(High-level lock),因为会一直循环调用
os_unfair_lock
苹果现在用os_unfair_lock用于取代不安全的OSSpinLock ,从iOS10开始才支持
从底层调用看,等待os_unfair_lock锁的线程会处于休眠状态,并非忙等
修改示例代码如下
#import "BaseDemo.h"
@interface OSUnfairLockDemo: BaseDemo
@end
#import "OSUnfairLockDemo.h"
#import <os/lock.h>
@interface OSUnfairLockDemo()
@property (assign, nonatomic) os_unfair_lock moneyLock;
@property (assign, nonatomic) os_unfair_lock ticketLock;
@end
@implementation OSUnfairLockDemo
- (instancetype)init
{
if (self = [super init]) {
self.moneyLock = OS_UNFAIR_LOCK_INIT;
self.ticketLock = OS_UNFAIR_LOCK_INIT;
}
return self;
}
- (void)__saleTicket
{
os_unfair_lock_lock(&_ticketLock);
[super __saleTicket];
os_unfair_lock_unlock(&_ticketLock);
}
- (void)__saveMoney
{
os_unfair_lock_lock(&_moneyLock);
[super __saveMoney];
os_unfair_lock_unlock(&_moneyLock);
}
- (void)__drawMoney
{
os_unfair_lock_lock(&_moneyLock);
[super __drawMoney];
os_unfair_lock_unlock(&_moneyLock);
}
@end
如果不写os_unfair_lock_unlock,那么所有的线程都会卡在os_unfair_lock_lock进入睡眠,不会再继续执行代码,这种情况叫做死锁
通过汇编来分析
我们也通过断点来分析加锁之后做了什么
首先会调用os_unfair_lock_lock

然后会调用os_unfair_lock_lock_slow

然后在os_unfair_lock_lock_slow中会执行__ulock_wait
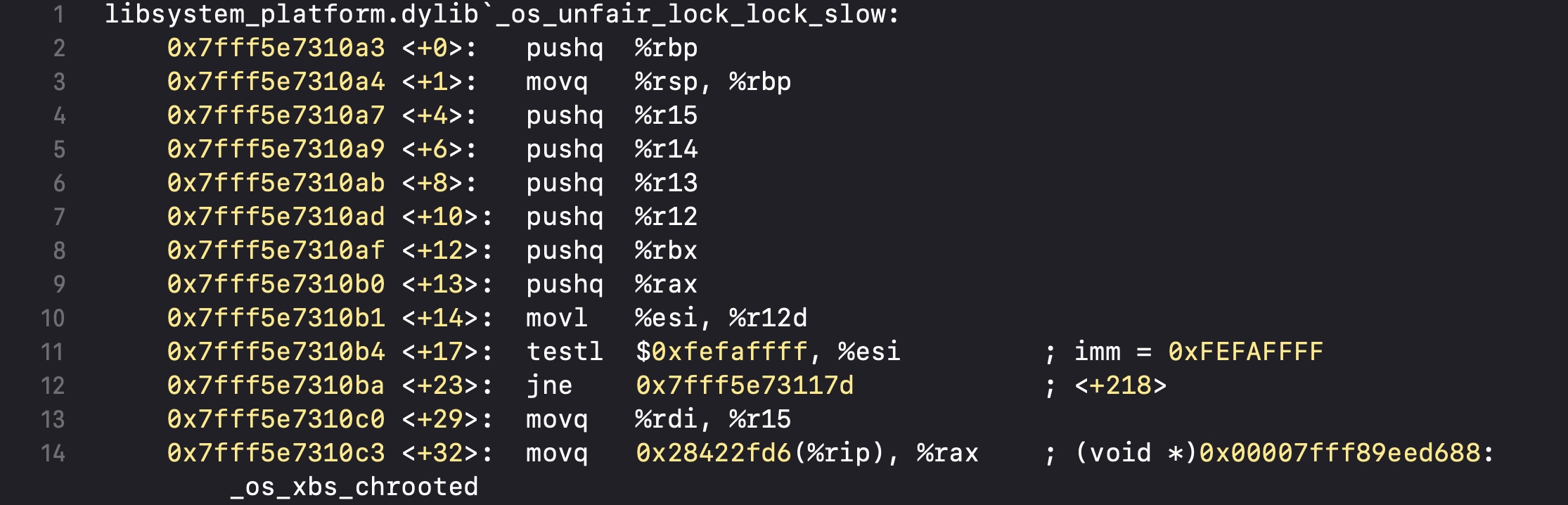
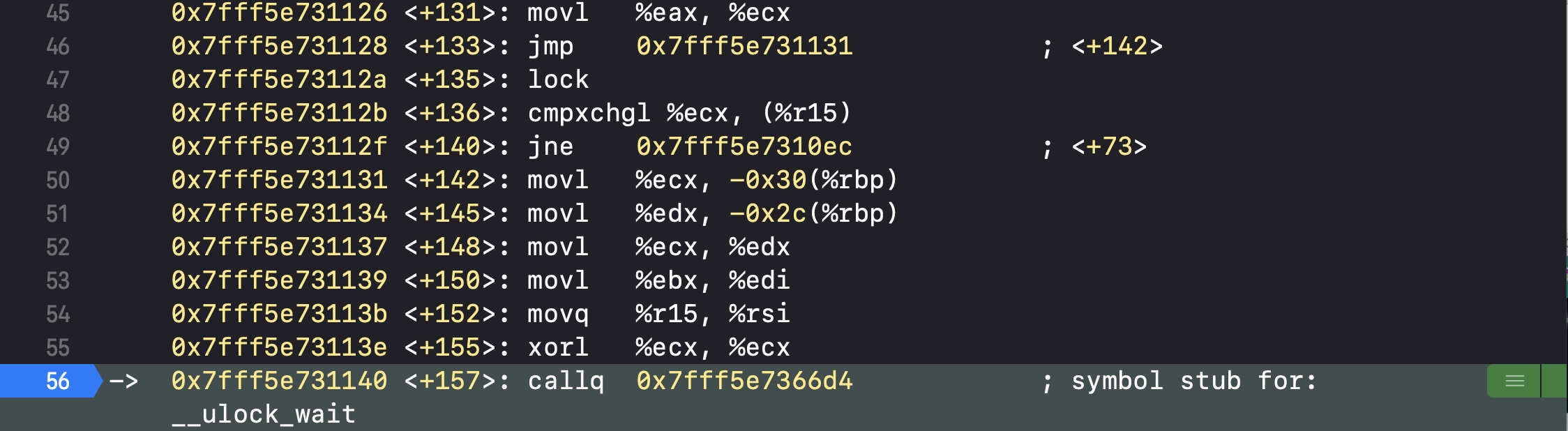
核心部分,代码执行到syscall会直接跳出断点,不再执行代码,也就是进入了睡眠


所以通过汇编底层执行逻辑,我们能看出os_unfair_lock一旦进行了加锁,就会直接进入休眠,等待解锁后唤醒再继续执行代码,也由此可以认为os_unfair_lock是互斥锁
syscall的调用可以理解为系统级别的调用进入睡眠,会直接卡住线程,不再执行代码
锁的等级
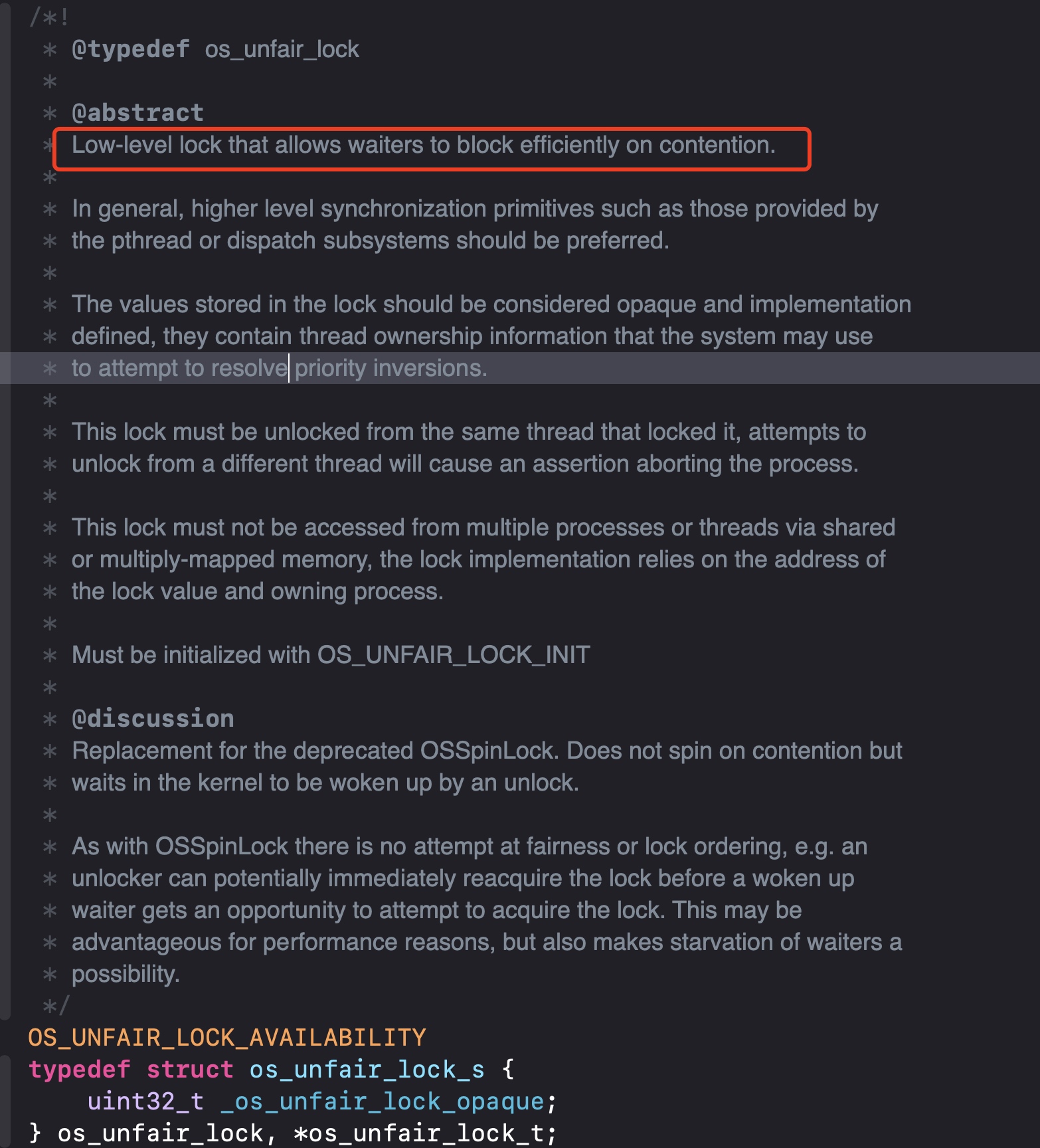
我们进到os_unfair_lock的头文件lock.h,可以看到注释说明os_unfair_lock是一个低等级的锁(Low-level lock),因为一旦发现加锁后就会自动进入睡眠
pthread_mutex
互斥锁
mutex叫做”互斥锁”,等待锁的线程会处于休眠状态
使用代码如下
@interface MutexDemo: BaseDemo
@end
#import "MutexDemo.h"
#import <pthread.h>
@interface MutexDemo()
@property (assign, nonatomic) pthread_mutex_t ticketMutex;
@property (assign, nonatomic) pthread_mutex_t moneyMutex;
@end
@implementation MutexDemo
- (void)__initMutex:(pthread_mutex_t *)mutex
{
// 静态初始化
// 需要在定义这个变量时给予值才可以这么写
// pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
// // 初始化属性
// pthread_mutexattr_t attr;
// pthread_mutexattr_init(&attr);
// pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_DEFAULT);
// // 初始化锁
// pthread_mutex_init(mutex, &attr);
// &attr传NULL默认就是PTHREAD_MUTEX_DEFAULT
pthread_mutex_init(mutex, NULL);
}
- (instancetype)init
{
if (self = [super init]) {
[self __initMutex:&_ticketMutex];
[self __initMutex:&_moneyMutex];
}
return self;
}
- (void)__saleTicket
{
pthread_mutex_lock(&_ticketMutex);
[super __saleTicket];
pthread_mutex_unlock(&_ticketMutex);
}
- (void)__saveMoney
{
pthread_mutex_lock(&_moneyMutex);
[super __saveMoney];
pthread_mutex_unlock(&_moneyMutex);
}
- (void)__drawMoney
{
pthread_mutex_lock(&_moneyMutex);
[super __drawMoney];
pthread_mutex_unlock(&_moneyMutex);
}
- (void)dealloc
{
// 对象销毁时调用
pthread_mutex_destroy(&_moneyMutex);
pthread_mutex_destroy(&_ticketMutex);
}
pthread_mutex_t实际就是pthread_mutex *类型
递归锁
当属性设置为PTHREAD_MUTEX_RECURSIVE时,就可以作为递归锁来使用
递归锁允许同一个线程对一把锁进行重复加锁;多个线程不可以用递归锁
- (void)__initMutex:(pthread_mutex_t *)mutex
{
// 初始化属性
pthread_mutexattr_t attr;
pthread_mutexattr_init(&attr);
pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE);
// 初始化锁
pthread_mutex_init(mutex, &attr);
}
- (void)otherTest
{
pthread_mutex_lock(&_mutex);
NSLog(@"%s", __func__);
static int count = 0;
if (count < 10) {
count++;
[self otherTest];
}
pthread_mutex_unlock(&_mutex);
}
根据条件来进行加锁
我们可以设定一定的条件来选择线程之间的调用进行加锁解锁,示例如下
@interface MutexDemo()
@property (assign, nonatomic) pthread_mutex_t mutex;
@property (assign, nonatomic) pthread_cond_t cond;
@property (strong, nonatomic) NSMutableArray *data;
@end
@implementation MutexDemo
- (instancetype)init
{
if (self = [super init]) {
// 初始化锁
pthread_mutex_init(&_mutex, NULL);
// 初始化条件
pthread_cond_init(&_cond, NULL);
self.data = [NSMutableArray array];
}
return self;
}
- (void)otherTest
{
[[[NSThread alloc] initWithTarget:self selector:@selector(__remove) object:nil] start];
[[[NSThread alloc] initWithTarget:self selector:@selector(__add) object:nil] start];
}
// 线程1
// 删除数组中的元素
- (void)__remove
{
pthread_mutex_lock(&_mutex);
NSLog(@"__remove - begin");
// 如果数据为空,那么设置条件等待唤醒
// 等待期间会先解锁,让其他线程执行代码
if (self.data.count == 0) {
pthread_cond_wait(&_cond, &_mutex);
}
[self.data removeLastObject];
NSLog(@"删除了元素");
pthread_mutex_unlock(&_mutex);
}
// 线程2
// 往数组中添加元素
- (void)__add
{
pthread_mutex_lock(&_mutex);
sleep(1);
[self.data addObject:@"Test"];
NSLog(@"添加了元素");
// 一旦添加了元素,变发送条件信号,让等待删除的条件继续执行代码,并再次加锁
// 信号(通知一个条件)
pthread_cond_signal(&_cond);
// 广播(通知所有条件)
// pthread_cond_broadcast(&_cond);
pthread_mutex_unlock(&_mutex);
}
- (void)dealloc
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_cond);
}
@end
通过汇编来分析
我们通过断点来分析加锁之后做了什么
首先会执行pthread_mutex_lock

然后会执行pthread_mutex_firstfit_lock_slow

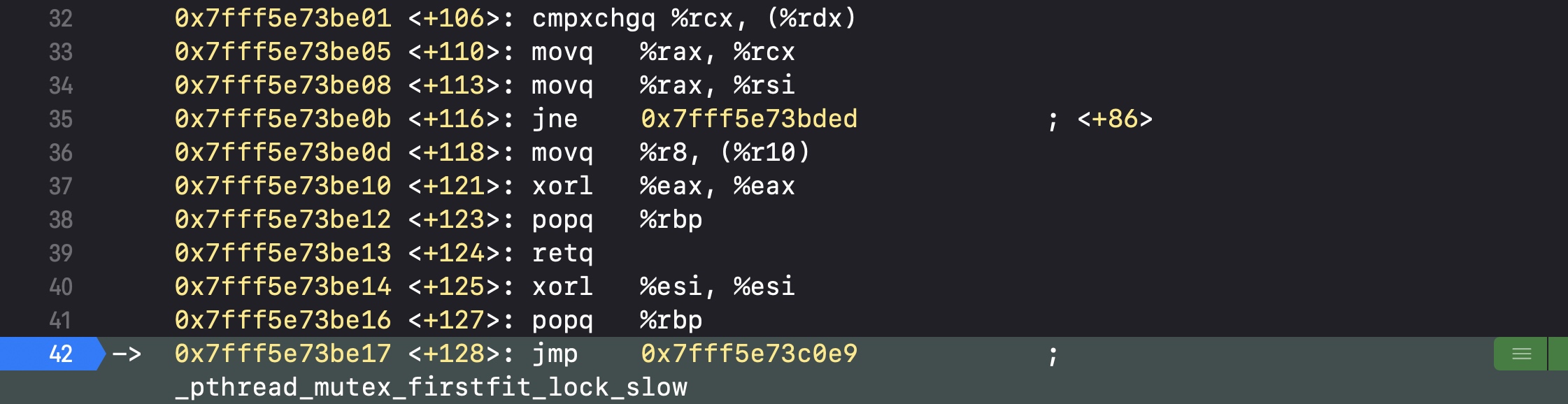
然后会执行pthread_mutex_firstfit_lock_wait
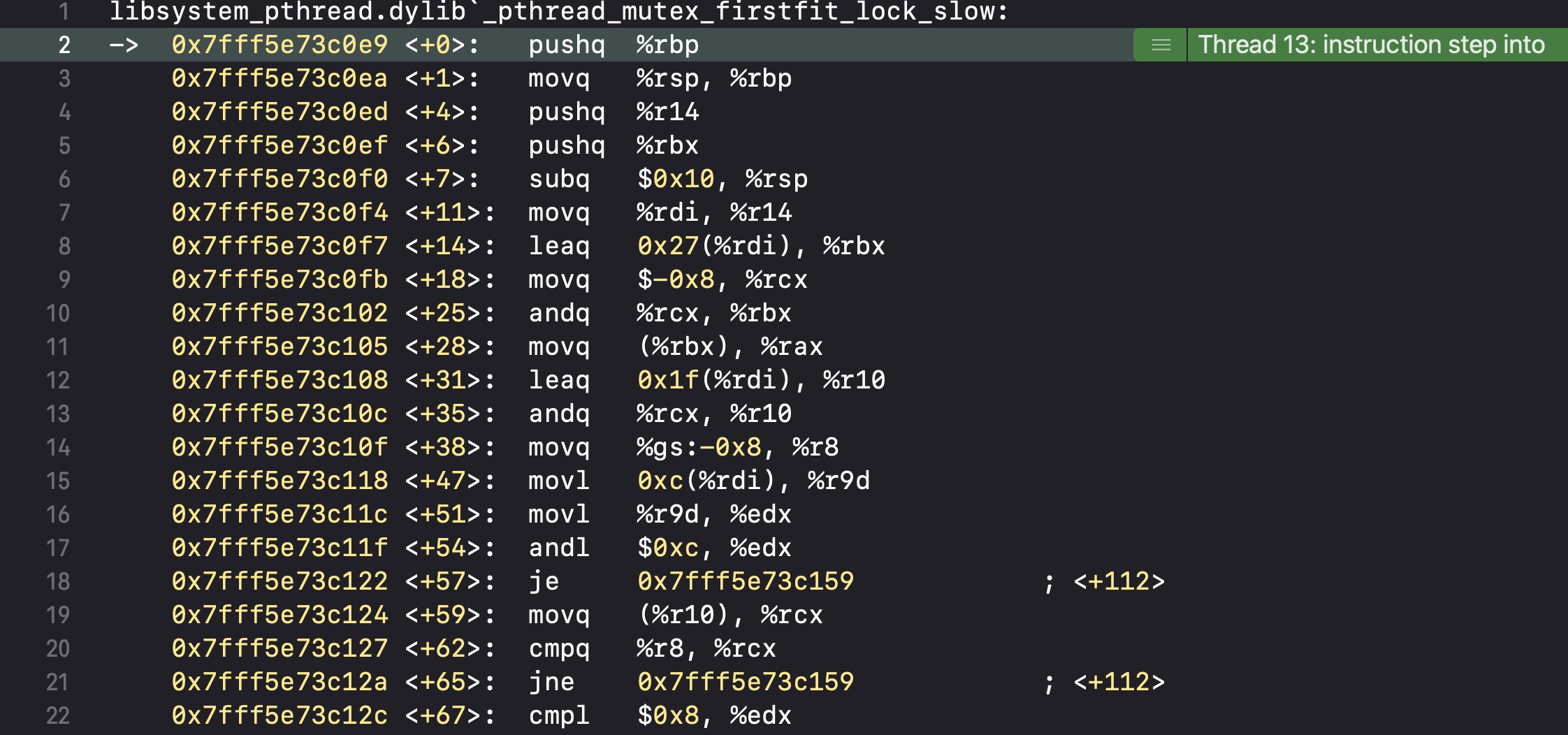
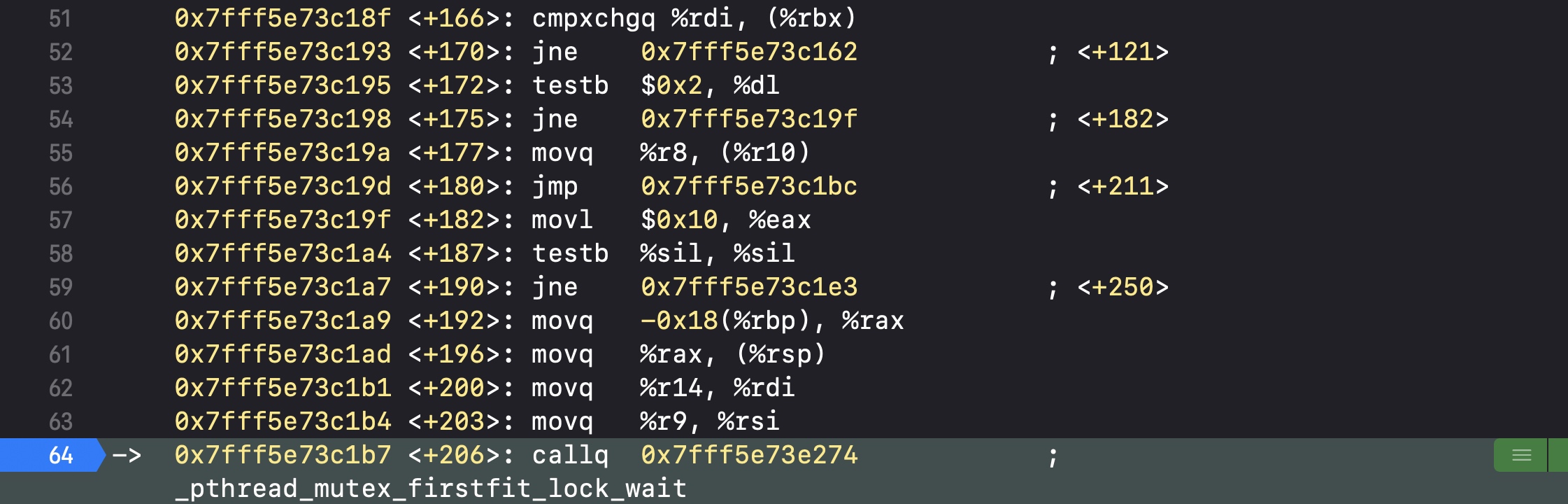
然后会执行__psynch_mutexwait
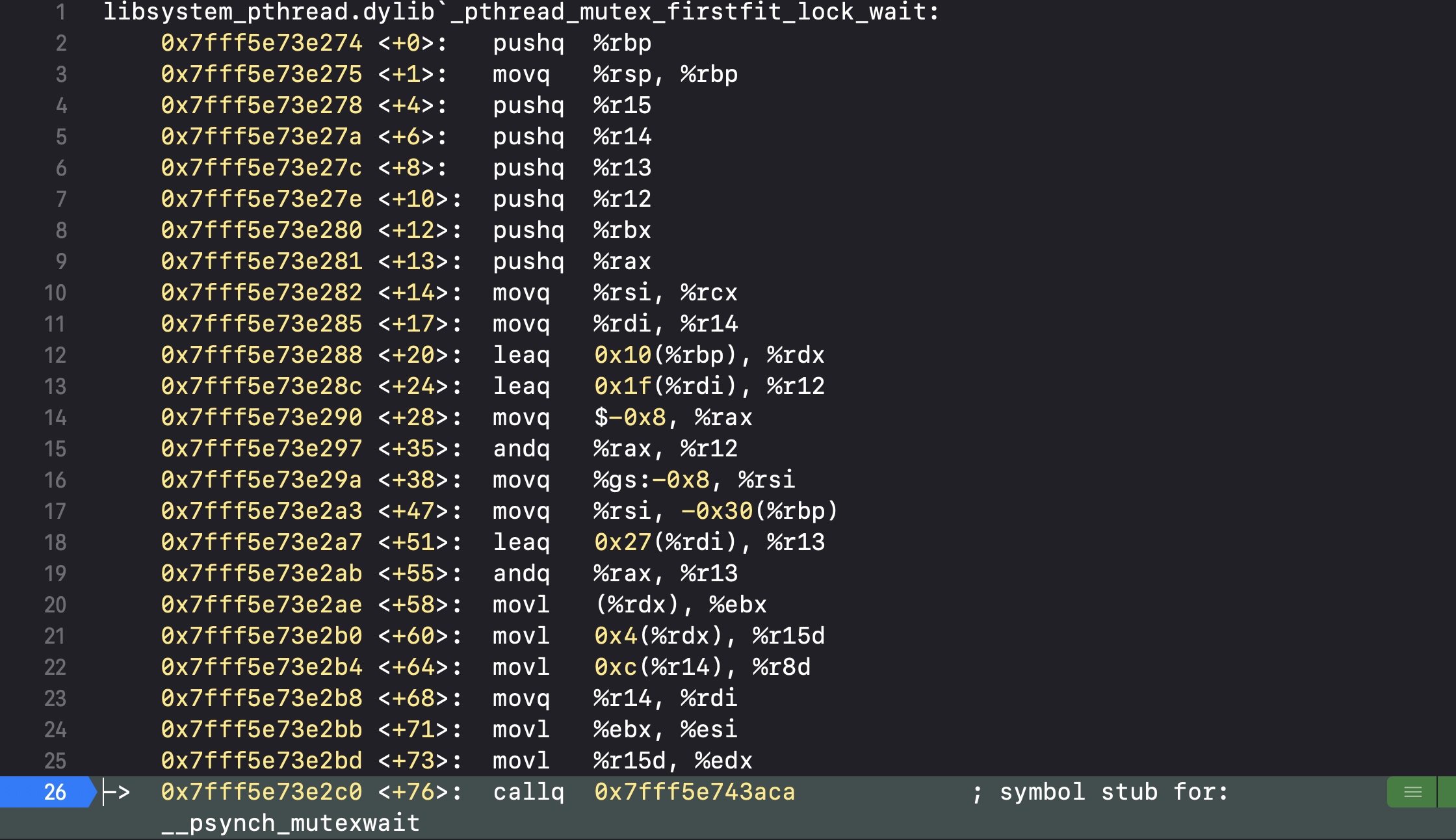
核心部分,在__psynch_mutexwait里,代码执行到syscall会直接跳出断点,不再执行代码,也就是进入了睡眠


所以pthread_mutex和os_unfair_lock一样,都是在加锁之后会进入到睡眠
锁的等级
pthread_mutex和os_unfair_lock一样,都是低等级的锁(Low-level lock)
NSLock
NSLock是对mutex普通锁的封装
NSLock遵守了<NSLocking>协议,支持以下两个方法
@protocol NSLocking
- (void)lock;
- (void)unlock;
@end
其他常用方法
// 尝试解锁
- (BOOL)tryLock;
// 设定一个时间等待加锁,时间到了如果还不能成功加锁就返回NO
- (BOOL)lockBeforeDate:(NSDate *)limit;
具体使用看下面代码
@interface NSLockDemo: BaseDemo
@end
@interface NSLockDemo()
@property (strong, nonatomic) NSLock *ticketLock;
@property (strong, nonatomic) NSLock *moneyLock;
@end
@implementation NSLockDemo
- (instancetype)init
{
if (self = [super init]) {
self.ticketLock = [[NSLock alloc] init];
self.moneyLock = [[NSLock alloc] init];
}
return self;
}
- (void)__saleTicket
{
[self.ticketLock lock];
[super __saleTicket];
[self.ticketLock unlock];
}
- (void)__saveMoney
{
[self.moneyLock lock];
[super __saveMoney];
[self.moneyLock unlock];
}
- (void)__drawMoney
{
[self.moneyLock lock];
[super __drawMoney];
[self.moneyLock unlock];
}
@end
分析底层实现
由于NSLock是不开源的,我们可以通过GNUstep Base来分析具体实现
找到NSLock.m可以看到initialize初始化方法里是创建的pthread_mutex_t对象,所以可以确定NSLock是对pthread_mutex的面向对象的封装
@implementation NSLock
+ (id) allocWithZone: (NSZone*)z
{
if (self == baseLockClass && YES == traceLocks)
{
return class_createInstance(tracedLockClass, 0);
}
return class_createInstance(self, 0);
}
+ (void) initialize
{
static BOOL beenHere = NO;
if (beenHere == NO)
{
beenHere = YES;
/* Initialise attributes for the different types of mutex.
* We do it once, since attributes can be shared between multiple
* mutexes.
* If we had a pthread_mutexattr_t instance for each mutex, we would
* either have to store it as an ivar of our NSLock (or similar), or
* we would potentially leak instances as we couldn't destroy them
* when destroying the NSLock. I don't know if any implementation
* of pthreads actually allocates memory when you call the
* pthread_mutexattr_init function, but they are allowed to do so
* (and deallocate the memory in pthread_mutexattr_destroy).
*/
pthread_mutexattr_init(&attr_normal);
pthread_mutexattr_settype(&attr_normal, PTHREAD_MUTEX_NORMAL);
pthread_mutexattr_init(&attr_reporting);
pthread_mutexattr_settype(&attr_reporting, PTHREAD_MUTEX_ERRORCHECK);
pthread_mutexattr_init(&attr_recursive);
pthread_mutexattr_settype(&attr_recursive, PTHREAD_MUTEX_RECURSIVE);
/* To emulate OSX behavior, we need to be able both to detect deadlocks
* (so we can log them), and also hang the thread when one occurs.
* the simple way to do that is to set up a locked mutex we can
* force a deadlock on.
*/
pthread_mutex_init(&deadlock, &attr_normal);
pthread_mutex_lock(&deadlock);
baseConditionClass = [NSCondition class];
baseConditionLockClass = [NSConditionLock class];
baseLockClass = [NSLock class];
baseRecursiveLockClass = [NSRecursiveLock class];
tracedConditionClass = [GSTracedCondition class];
tracedConditionLockClass = [GSTracedConditionLock class];
tracedLockClass = [GSTracedLock class];
tracedRecursiveLockClass = [GSTracedRecursiveLock class];
untracedConditionClass = [GSUntracedCondition class];
untracedConditionLockClass = [GSUntracedConditionLock class];
untracedLockClass = [GSUntracedLock class];
untracedRecursiveLockClass = [GSUntracedRecursiveLock class];
}
}
NSRecursiveLock
NSRecursiveLock也是对mutex递归锁的封装,API跟NSLock基本一致
NSCondition
NSCondition是对mutex和cond的封装
具体使用代码如下
@interface NSConditionDemo()
@property (strong, nonatomic) NSCondition *condition;
@property (strong, nonatomic) NSMutableArray *data;
@end
@implementation NSConditionDemo
- (instancetype)init
{
if (self = [super init]) {
self.condition = [[NSCondition alloc] init];
self.data = [NSMutableArray array];
}
return self;
}
- (void)otherTest
{
[[[NSThread alloc] initWithTarget:self selector:@selector(__remove) object:nil] start];
[[[NSThread alloc] initWithTarget:self selector:@selector(__add) object:nil] start];
}
// 线程1
// 删除数组中的元素
- (void)__remove
{
[self.condition lock];
NSLog(@"__remove - begin");
if (self.data.count == 0) {
// 等待
[self.condition wait];
}
[self.data removeLastObject];
NSLog(@"删除了元素");
[self.condition unlock];
}
// 线程2
// 往数组中添加元素
- (void)__add
{
[self.condition lock];
sleep(1);
[self.data addObject:@"Test"];
NSLog(@"添加了元素");
// 信号
[self.condition signal];
// 广播
// [self.condition broadcast];
[self.condition unlock];
}
@end
```##### 分析底层实现`NSCondition`也遵守了`NSLocking`协议,说明其内部已经封装了锁的相关代码
@interface NSCondition : NSObject
@private
void *_priv;
}
- (void)wait;
- (BOOL)waitUntilDate:(NSDate *)limit;
- (void)signal;
- (void)broadcast;
@property (nullable, copy) NSString *name API_AVAILABLE(macos(10.5), ios(2.0), watchos(2.0), tvos(9.0));
@end
我们通过`GNUstep Base`也可以看到其初始化方法里对`pthread_mutex_t`进行了封装
@implementation NSCondition
-
(id) allocWithZone: (NSZone*)z
{
if (self == baseConditionClass && YES == traceLocks)
{
return class_createInstance(tracedConditionClass, 0);
}
return class_createInstance(self, 0);
} -
(void) initialize
{
[NSLock class]; // Ensure mutex attributes are set up.
}
- (id) init
{
if (nil != (self = [super init]))
{
if (0 != pthread_cond_init(&_condition, NULL))
{
DESTROY(self);
}
else if (0 != pthread_mutex_init(&_mutex, &attr_reporting))
{
pthread_cond_destroy(&_condition);
DESTROY(self);
}
}
return self;
}
#### NSConditionLock
`NSConditionLock`是对`NSCondition`的进一步封装,可以设置具体的条件值
通过设置条件值可以对线程做依赖控制执行顺序,具体使用见示例代码
@interface NSConditionLockDemo()
@property (strong, nonatomic) NSConditionLock *conditionLock;
@end
@implementation NSConditionLockDemo
-
(instancetype)init
{
// 创建的时候可以设置一个条件
// 如果不设置,默认就是0
if (self = [super init]) {
self.conditionLock = [[NSConditionLock alloc] initWithCondition:1];
}
return self;
} -
(void)otherTest
{
[[[NSThread alloc] initWithTarget:self selector:@selector(__one) object:nil] start];[[[NSThread alloc] initWithTarget:self selector:@selector(__two) object:nil] start];
[[[NSThread alloc] initWithTarget:self selector:@selector(__three) object:nil] start];
} -
(void)__one
{
// 不需要任何条件,只有没有锁就加锁
[self.conditionLock lock];NSLog(@"__one");
sleep(1);[self.conditionLock unlockWithCondition:2];
} -
(void)__two
{
// 根据对应条件来加锁
[self.conditionLock lockWhenCondition:2];NSLog(@"__two");
sleep(1);[self.conditionLock unlockWithCondition:3];
} -
(void)__three
{
[self.conditionLock lockWhenCondition:3];NSLog(@"__three");
[self.conditionLock unlock];
}
@end
// 打印的先后顺序为:1、2、3
#### dispatch\_queue\_t
我们可以直接使用`GCD`的串行队列,也是可以实现线程同步的,具体代码可以参考`GCD`部分的示例代码
#### dispatch_semaphore
`semaphore`叫做”信号量”
信号量的初始值,可以用来控制线程并发访问的最大数量
示例代码如下
@interface SemaphoreDemo()
@property (strong, nonatomic) dispatch_semaphore_t semaphore;
@property (strong, nonatomic) dispatch_semaphore_t ticketSemaphore;
@property (strong, nonatomic) dispatch_semaphore_t moneySemaphore;
@end
@implementation SemaphoreDemo
-
(instancetype)init
{
if (self = [super init]) {
// 初始化信号量
// 最多只开5条线程,也就是可以5条线程同时访问同一块空间,然后加锁,其他线程再进来就只能等待了
self.semaphore = dispatch_semaphore_create(5);
// 最多只开1条线程
self.ticketSemaphore = dispatch_semaphore_create(1);
self.moneySemaphore = dispatch_semaphore_create(1);
}
return self;
} -
(void)__drawMoney
{
dispatch_semaphore_wait(self.moneySemaphore, DISPATCH_TIME_FOREVER);[super __drawMoney];
dispatch_semaphore_signal(self.moneySemaphore);
} -
(void)__saveMoney
{
dispatch_semaphore_wait(self.moneySemaphore, DISPATCH_TIME_FOREVER);[super __saveMoney];
dispatch_semaphore_signal(self.moneySemaphore);
} -
(void)__saleTicket
{
// 如果信号量的值>0就减1,然后往下执行代码
// 当信号量的值<=0时,当前线程就会进入休眠等待(直到信号量的值>0)
dispatch_semaphore_wait(self.ticketSemaphore, DISPATCH_TIME_FOREVER);[super __saleTicket];
// 让信号量的值加1
dispatch_semaphore_signal(self.ticketSemaphore);
}
@end
#### @synchronized
`@synchronized`是对`mutex`递归锁的封装
示例代码如下
@interface SynchronizedDemo: BaseDemo
@end
@implementation SynchronizedDemo
-
(void)__drawMoney
{
// @synchronized需要加锁的是同一个对象才行
@synchronized([self class]) {
[super __drawMoney];
}
} -
(void)__saveMoney
{
@synchronized([self class]) { // objc_sync_enter
[super __saveMoney];
} // objc_sync_exit
} -
(void)__saleTicket
{
static NSObject *lock;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
lock = [[NSObject alloc] init];
});@synchronized(lock) {
[super __saleTicket];
}
}
@end
##### 源码分析
我们可以通过程序运行中转汇编看到,最终都会调用`objc_sync_enter`
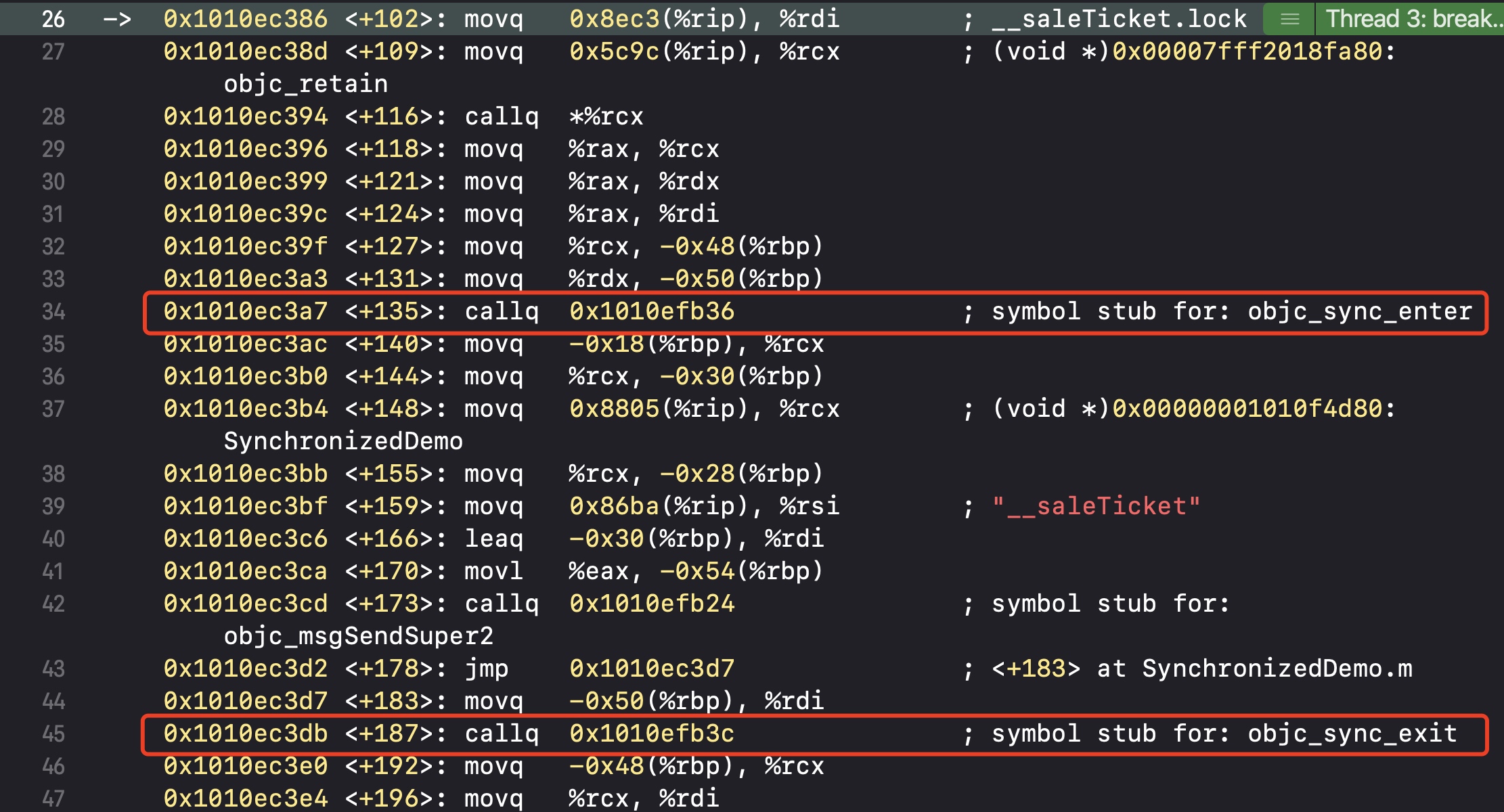
我们可以通过`objc4`中`objc-sync.mm`来分析对应的源码实现
int objc_sync_enter(id obj)
{
int result = OBJC_SYNC_SUCCESS;
if (obj) {
SyncData* data = id2data(obj, ACQUIRE);
ASSERT(data);
data->mutex.lock();
} else {
// @synchronized(nil) does nothing
if (DebugNilSync) {
_objc_inform("NIL SYNC DEBUG: @synchronized(nil); set a breakpoint on objc_sync_nil to debug");
}
objc_sync_nil();
}
return result;
}
可以看到会根据传进来的`obj`找到对应的`SyncData`
typedef struct alignas(CacheLineSize) SyncData {
struct SyncData* nextData;
DisguisedPtr<objc_object> object;
int32_t threadCount; // number of THREADS using this block
recursive_mutex_t mutex;
} SyncData;
在找到`SyncData`里面的成员变量`recursive_mutex_t`的真实类型,里面有一个递归锁
using recursive_mutex_t = recursive_mutex_tt
class recursive_mutex_tt : nocopy_t {
os_unfair_recursive_lock mLock; // 递归锁
public:
constexpr recursive_mutex_tt() : mLock(OS_UNFAIR_RECURSIVE_LOCK_INIT) {
lockdebug_remember_recursive_mutex(this);
}
constexpr recursive_mutex_tt(__unused const fork_unsafe_lock_t unsafe)
: mLock(OS_UNFAIR_RECURSIVE_LOCK_INIT)
{ }
void lock()
{
lockdebug_recursive_mutex_lock(this);
os_unfair_recursive_lock_lock(&mLock);
}
void unlock()
{
lockdebug_recursive_mutex_unlock(this);
os_unfair_recursive_lock_unlock(&mLock);
}
void forceReset()
{
lockdebug_recursive_mutex_unlock(this);
bzero(&mLock, sizeof(mLock));
mLock = os_unfair_recursive_lock OS_UNFAIR_RECURSIVE_LOCK_INIT;
}
bool tryLock()
{
if (os_unfair_recursive_lock_trylock(&mLock)) {
lockdebug_recursive_mutex_lock(this);
return true;
}
return false;
}
bool tryUnlock()
{
if (os_unfair_recursive_lock_tryunlock4objc(&mLock)) {
lockdebug_recursive_mutex_unlock(this);
return true;
}
return false;
}
void assertLocked() {
lockdebug_recursive_mutex_assert_locked(this);
}
void assertUnlocked() {
lockdebug_recursive_mutex_assert_unlocked(this);
}
};
然后我们分析获取`SyncData`的实现方法`id2data`,通过`obj`从`LIST_FOR_OBJ`真正取出数据
static SyncData* id2data(id object, enum usage why)
{
spinlock_t *lockp = &LOCK_FOR_OBJ(object);
SyncData *listp = &LIST_FOR_OBJ(object);
SyncData result = NULL;
if SUPPORT_DIRECT_THREAD_KEYS
// Check per-thread single-entry fast cache for matching object
bool fastCacheOccupied = NO;
SyncData *data = (SyncData *)tls_get_direct(SYNC_DATA_DIRECT_KEY);
if (data) {
fastCacheOccupied = YES;
if (data->object == object) {
// Found a match in fast cache.
uintptr_t lockCount;
result = data;
lockCount = (uintptr_t)tls_get_direct(SYNC_COUNT_DIRECT_KEY);
if (result->threadCount <= 0 || lockCount <= 0) {
_objc_fatal("id2data fastcache is buggy");
}
switch(why) {
case ACQUIRE: {
lockCount++;
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);
break;
}
case RELEASE:
lockCount--;
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);
if (lockCount == 0) {
// remove from fast cache
tls_set_direct(SYNC_DATA_DIRECT_KEY, NULL);
// atomic because may collide with concurrent ACQUIRE
OSAtomicDecrement32Barrier(&result->threadCount);
}
break;
case CHECK:
// do nothing
break;
}
return result;
}
}
endif
// Check per-thread cache of already-owned locks for matching object
SyncCache *cache = fetch_cache(NO);
if (cache) {
unsigned int i;
for (i = 0; i < cache->used; i++) {
SyncCacheItem *item = &cache->list[i];
if (item->data->object != object) continue;
// Found a match.
result = item->data;
if (result->threadCount <= 0 || item->lockCount <= 0) {
_objc_fatal("id2data cache is buggy");
}
switch(why) {
case ACQUIRE:
item->lockCount++;
break;
case RELEASE:
item->lockCount--;
if (item->lockCount == 0) {
// remove from per-thread cache
cache->list[i] = cache->list[--cache->used];
// atomic because may collide with concurrent ACQUIRE
OSAtomicDecrement32Barrier(&result->threadCount);
}
break;
case CHECK:
// do nothing
break;
}
return result;
}
}
// Thread cache didn't find anything.
// Walk in-use list looking for matching object
// Spinlock prevents multiple threads from creating multiple
// locks for the same new object.
// We could keep the nodes in some hash table if we find that there are
// more than 20 or so distinct locks active, but we don't do that now.
lockp->lock();
{
SyncData* p;
SyncData* firstUnused = NULL;
for (p = *listp; p != NULL; p = p->nextData) {
if ( p->object == object ) {
result = p;
// atomic because may collide with concurrent RELEASE
OSAtomicIncrement32Barrier(&result->threadCount);
goto done;
}
if ( (firstUnused == NULL) && (p->threadCount == 0) )
firstUnused = p;
}
// no SyncData currently associated with object
if ( (why == RELEASE) || (why == CHECK) )
goto done;
// an unused one was found, use it
if ( firstUnused != NULL ) {
result = firstUnused;
result->object = (objc_object *)object;
result->threadCount = 1;
goto done;
}
}
// Allocate a new SyncData and add to list.
// XXX allocating memory with a global lock held is bad practice,
// might be worth releasing the lock, allocating, and searching again.
// But since we never free these guys we won't be stuck in allocation very often.
posix_memalign((void **)&result, alignof(SyncData), sizeof(SyncData));
result->object = (objc_object *)object;
result->threadCount = 1;
new (&result->mutex) recursive_mutex_t(fork_unsafe_lock);
result->nextData = *listp;
*listp = result;
done:
lockp->unlock();
if (result) {
// Only new ACQUIRE should get here.
// All RELEASE and CHECK and recursive ACQUIRE are
// handled by the per-thread caches above.
if (why == RELEASE) {
// Probably some thread is incorrectly exiting
// while the object is held by another thread.
return nil;
}
if (why != ACQUIRE) _objc_fatal("id2data is buggy");
if (result->object != object) _objc_fatal("id2data is buggy");
if SUPPORT_DIRECT_THREAD_KEYS
if (!fastCacheOccupied) {
// Save in fast thread cache
tls_set_direct(SYNC_DATA_DIRECT_KEY, result);
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)1);
} else
endif
{
// Save in thread cache
if (!cache) cache = fetch_cache(YES);
cache->list[cache->used].data = result;
cache->list[cache->used].lockCount = 1;
cache->used++;
}
}
return result;
}
`LIST_FOR_OBJ`是一个哈希表,哈希表的实现就是将传进来的`obj`作为`key`,然后对应的锁为`value`
define LIST_FOR_OBJ(obj) sDataLists[obj].data // 哈希表
static StripedMap
// 哈希表的实现就是将传进来的对象作为key,然后对应的锁为value
通过源码分析我们也可以看出,`@synchronized`内部的锁是递归锁
### 锁的比较
#### 性能比较排序
下面是每个锁按性能从高到低排序
- os\_unfair\_lock- OSSpinLock- dispatch\_semaphore- pthread\_mutex- dispatch\_queue(DISPATCH\_QUEUE\_SERIAL)- NSLock- NSCondition- pthread_mutex(recursive)- NSRecursiveLock- NSConditionLock- @synchronized
选择性最高的锁
- dispatch\_semaphore- pthread\_mutex
#### 互斥锁、自旋锁的比较
##### 什么情况使用自旋锁
- 预计线程等待锁的时间很短- 加锁的代码(临界区)经常被调用,但竞争情况很少发生- CPU资源不紧张- 多核处理器
##### 什么情况使用互斥锁
- 预计线程等待锁的时间较长- 单核处理器(尽量减少CPU的消耗)- 临界区有IO操作(IO操作比较占用CPU资源)- 临界区代码复杂或者循环量大- 临界区竞争非常激烈
 浙公网安备 33010602011771号
浙公网安备 33010602011771号