个人项目:论文查重
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Networkengineering1834/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Networkengineering1834/homework/11146 |
| 这个作业的目标 | 个人完成论文查重项目 |
一、GitHub链接:
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 25 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 25 |
| Development | 开发 | 515 | 620 |
| · Analysis | · 需求分析 (包括学习新技术) | 35 | 45 |
| · Design Spec | · 生成设计文档 | 25 | 25 |
| · Design Review | · 设计复审 | 35 | 40 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 25 | 25 |
| · Coding | · 具体编码 | 180 | 200 |
| · Code Review | · 代码复审 | 65 | 65 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 130 | 200 |
| Reporting | 报告 | 65 | 65 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 25 | 25 |
| · 合计 | 600 | 710 |
三、计算模块接口的设计与实现过程
1.算法原理
参考文章:https://www.cnblogs.com/qdhxhz/p/9484274.html
(1)可通过向量来计算相识度公式。
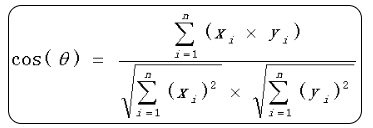
(2)余弦值越接近1,也就是两个向量越相似,这就叫"余弦相似性",
余弦值越接近0,也就是两个向量越不相似,也就是这两个字符串越不相似。
2、案例理论知识
举一个例子来说明,用上述理论计算文本的相似性。为了简单起见,先从句子着手。
句子A:这只皮靴号码大了。那只号码合适。
句子B:这只皮靴号码不小,那只更合适。
怎样计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
句子A:这只/皮靴/号码/大了。那只/号码/合适。
句子B:这只/皮靴/号码/不/小,那只/更/合适。
第二步,计算词频。(也就是每个词语出现的频率)
句子A:这只1,皮靴1,号码2,大了1。那只1,合适1,不0,小0,更0
句子B:这只1,皮靴1,号码1,大了0。那只1,合适1,不1,小1,更1
第三步,写出词频向量。
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)
第四步:运用上面的公式:计算如下:

计算结果中夹角的余弦值为0.81非常接近于1,所以,上面的句子A和句子B是基本相似的
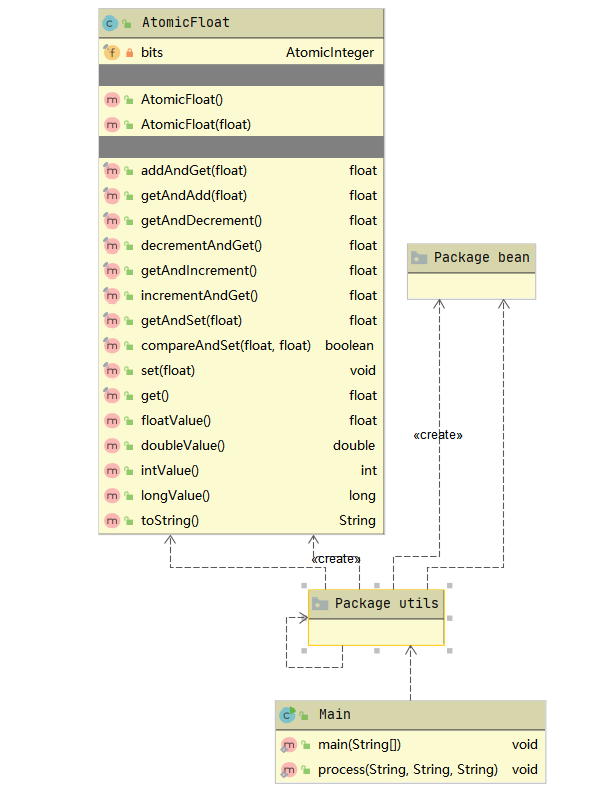
3.类图
4.独到之处:
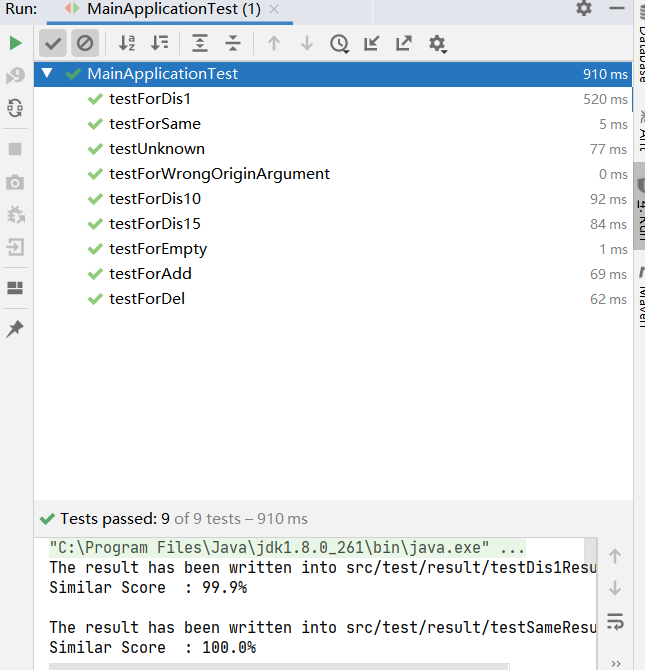
运行速度还是比较快的,基本可以在3s以内完成
四、计算模块接口部分的性能改进
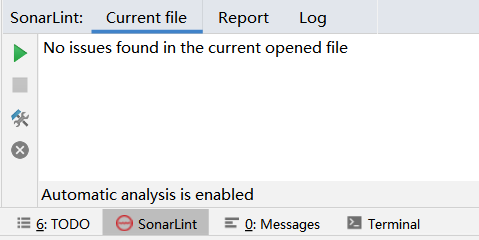
1.使用SonarLint发现警告并消除
消除后:
2.性能分析:
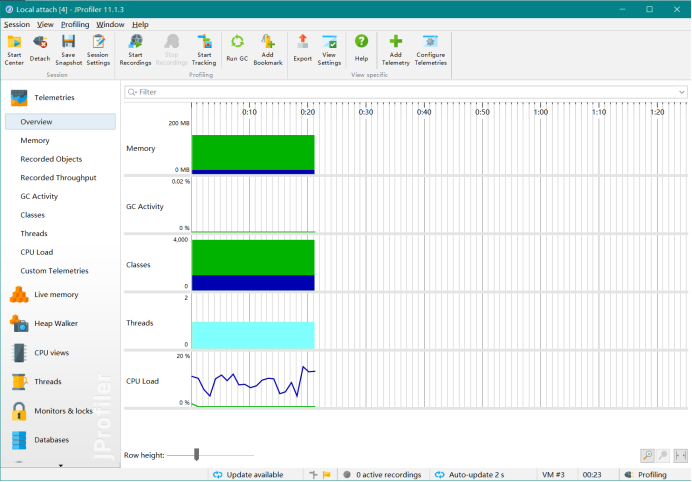
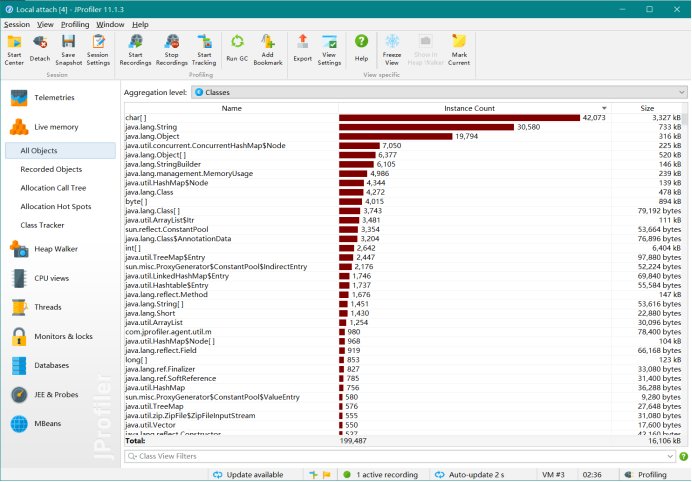
五、计算模块部分单元测试展示
1.部分代码:
String[] paths = {
"src/test/testcase/orig.txt",
"src/test/testcase/empty.txt",
"src/test/testcase/orig_0.8_add.txt",
"src/test/testcase/orig_0.8_del.txt",
"src/test/testcase/orig_0.8_dis_1.txt",
"src/test/testcase/orig_0.8_dis_10.txt",
"src/test/testcase/orig_0.8_dis_15.txt",
"src/test/testcase/unknown.txt",
"src/test/testcase/orig_0.8_dis_16.txt"
};
/**
* 测试 文本为空文本的情况
*/
@Test
public void testForEmpty(){
try {
Main.process(paths[0],paths[1],"src/test/result/testEmptyResult.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试 输入的对比文本路径参数为错误参数的情况
*/
@Test
public void testForWrongOriginArgument(){
try {
Main.process("src/test/testcase/123.txt",paths[0],"src/test/result/testAddResult.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试20%文本添加情况:orig_0.8_add.txt
*/
@Test
public void testForAdd(){
try {
Main.process(paths[0],paths[2],"src/test/result/testAddResult.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试20%文本删除情况:orig_0.8_del.txt
*/
@Test
public void testForDel(){
try {
Main.process(paths[0],paths[3],"src/test/result/testDelResult.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试20%文本乱序情况:orig_0.8_dis_1.txt
*/
@Test
public void testForDis1(){
try {
Main.process(paths[0],paths[4],"src/test/result/testDis1Result.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试20%文本乱序情况:orig_0.8_dis_10.txt
*/
@Test
public void testForDis10(){
try {
Main.process(paths[0],paths[5],"src/test/result/testDis10Result.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试20%文本乱序情况:orig_0.8_dis_15.txt
*/
@Test
public void testForDis15(){
try {
Main.process(paths[0],paths[6],"src/test/result/testDis15Result.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试相同文本:orig.txt
*/
@Test
public void testForSame(){
try {
Main.process(paths[0],paths[0],"src/test/result/testSameResult.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试未知文本:unknown.txt
*/
@Test
public void testUnknown(){
try {
Main.process(paths[0],paths[7],"src/test/result/testUnknown.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
2.测试思路:
思路来源于命令行测试代码:Java: java -jar main.jar [原文文件] [抄袭版论文的文件] [答案文件]
设定三份文件路径,以文本之间不同的比对,来达到测试代码的目的
3.测试覆盖率
-
首次测试:

显然,测试代码覆盖率并不高,还有很多改进的空间 -
尝试改进utils,结果:

六、计算模块部分异常处理说明
1.IOException
采用空文本与原文对比测试

2.FileNotFoundException
采用路径错误的文本与原文对比测试


 浙公网安备 33010602011771号
浙公网安备 33010602011771号