day02-Coze案例01
今日内容
1 LLM模型配置
1.1 生成多样性(temperature)
#1 temperature解释:
调高温度会使得模型的输出更多样性和创新性,反之,降低温度会使输出内容更加遵循指令要求但减少多样性。建议不要与 “Top p” 同时调整
# 2 不同模式
## 精确模式:
在需要严格遵循指令、输出准确无误的场合,如生成正式文档、代码、法律文件等,应使用较低的生成随机性数值,接近 0,使模型更倾向于选择最可能的词汇,确保输出的稳定性和准确性。例如在金融报告生成中,需准确呈现数据和事实,低随机性可避免出现不恰当的表述。
## 平衡模式:
对于大多数日常应用场景,如一般的问答系统、信息检索回复等,可将生成随机性设置为中等水平,既能保证一定的多样性,使回答不会过于单调,又能基本遵循指令,提供较为准确的信息。
## 创意模式:
当进行创造性任务,如小说创作、诗歌写作、创意广告文案撰写等,可适当调高生成随机性数值。较高的随机性能让模型探索更多的词汇组合和表达可能性,产生更具创意和独特性的内容,但要注意可能会出现一些偏离主题或不太符合逻辑的情况,需要后期适当筛选和修改
# 我们使用LLM,就相当于加入了一个大脑---》大模型训练得到的--》它有思考,创造能力
-如果这个调高了,它的创意就高:小说创作、诗歌写作、创意广告文案撰写
-如果调低了,创意变低,更精准:正式文档、代码、法律文件
1.2 Top P
#1 Top p 为累计概率:
模型在生成输出时会从概率最高的词汇开始选择,直到这些词汇的总概率累积达到 Top p 值。这样可以限制模型只选择这些高概率的词汇,从而控制输出内容的多样性。建议不要与 “生成随机性” 同时调整
# 问大模型---》大模型给你答案
我问大模型:你爱我吗?
- 嗯,亲爱的,当然了,我一直很爱你 # Top P 会高
- 嗯 # Top P 低
大模型大脑中生成很多词汇--》每个词汇都有一个数值--》组合成句子给你---》如果top P调成了 0.8
0.1 0.2 0.2 0.3
嗯 亲爱的 当然了 我一直很爱你
top p如果是 0.1 ---》嗯
top P 如果是0.8 ---》嗯 亲爱的 当然了 我一直很爱你
# 举例: 刘老师:temperature 很低,top P 很高
刘老师很理性
同学问问题,巴拉巴拉回一堆
问:一年能赚30w吗? 不好说,这个
-temperature高低:
-理性:不太可能
-天马行空:完全没问题,你很强的
-Top P:
-top 很低:不可能
-top 很高:不太可能,但也不一定,这得看你。。。。
# 2 不同模式
## 精确模式:
若追求输出内容的高度精确性和专业性,如学术论文生成、专业技术文档编写等,可将 Top - p 设置为较低值,如 0.5 - 0.7。这样模型会专注于选择概率较高的常见词汇和表达方式,减少意外和不相关内容的出现,使输出更符合专业规范和预期。
## 平衡模式:
在日常对话、普通文章写作等场景中,可将 Top - p 设为 0.7 - 0.9。适中的 Top - p 值能让模型在保证一定准确性的基础上,使用更多样的词汇和表述方式,使生成的文本更自然、流畅,也更具可读性。
## 创意模式:
当需要激发创意和获得独特的观点时,如头脑风暴、创意设计讨论等,可将 Top - p 提高到 0.9 以上,甚至接近 1。此时模型会考虑更多低概率的词汇,从而产生更具多样性和意外性的内容,有助于开拓思路和创新
1.3 重复语句惩罚
# frequency penalty:
当该值为正时,会阻止模型频繁使用相同的词汇和短语,从而增加输出内容的多样性
# 我讲课,经常问大家, 大家听明白了吗
-负数:大家听明白了吗
-正数:大家听明白了吗,还有没明白的吗
同样意思短语,但是不重样出现
1.4 携带上下文轮数
# 默认选了3
-我们跟大模型交互--》它给我回答,有时候是要参考 上面的问题
-如果携带上下文轮数:0---》一点都不参考上面的问题---》每个回答都是一个新的
# 也不要选太多--》如果太多,每次问题,携带的数据就会很多---》消耗的token就会多
-一个词语 一个 token :大约
我爱你
你好
嗯
-汉字与token的对应关系,大约是1.5
# token: 文字个数
-带的上下文多,多给他发了文字--》用第三方平台,根据token收费
-花钱多
1.5 最大回复长度
# 控制模型输出的 Tokens 长度上限。通常 100 Tokens 约等于 150 个中文汉字
# 可能:
我 是一个token
喜欢 是一个token
爱你
晴天
2 插件(核心)
# 1 AI 智能体,有了大脑---》LLM--》分析,创意
-去网上下载图片
-生成图片
# 2 上面那些,就需要借助于插件去完成
-相当于人的手脚眼睛耳朵
-帮我ai智能体完成更多操作
# 3 coze提供了插件仓库
-官方插件:coze官方出的
-第三方插件:第三方开发者,开发的,发布到coze仓库中,供大家使用
-有的是要收费:根据调用次数收费
-我们可以自己开发插件
-一期就有讲
# 4 三个插件的案例
-如果问智能体,时下最热的电影有哪些?
-使用 【最新电影_电影信息查询 / current_hot】 插件
-读取链接的插件
-使用【链接读取 / LinkReaderPlugin】
-图片搜索插件
-使用【头条图片搜索 / ToutiaoPictureSearch】
# 5 重点是:
我们要会去找第三方插件,要会根据人家的文档,使用第三方插件
如果第三方插件不能满足我们的需求:我们需要自行开发插件
-必须要具备开发能力:python:主推
3 触发器
允许用户在与智能体对话过程中,根据用户所在时区创建定时任务。例如“每天早上八点推送新闻”。每个对话中最多创建 3 条定时任务
3.1 定时触发
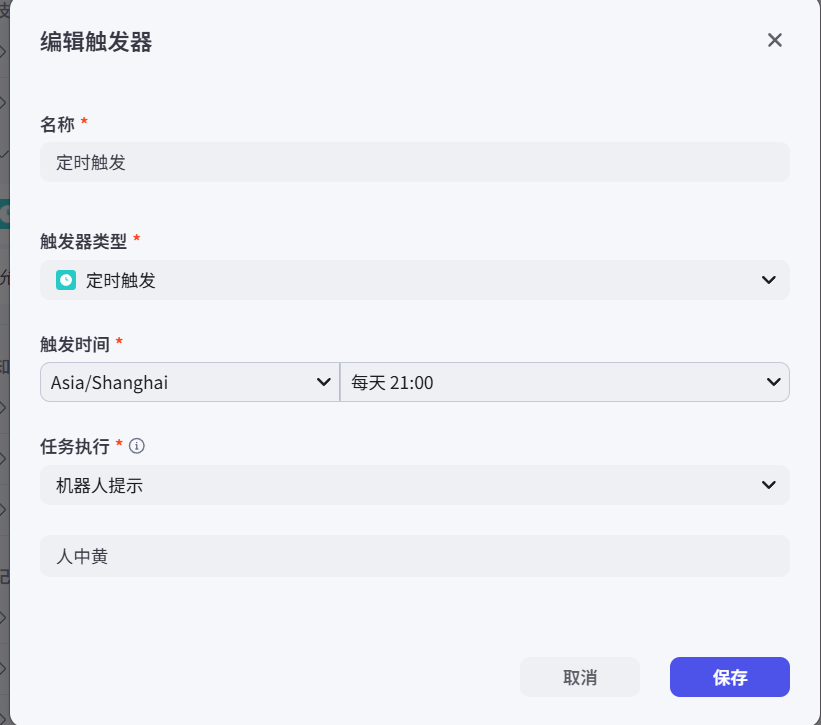
3.2 事件触发
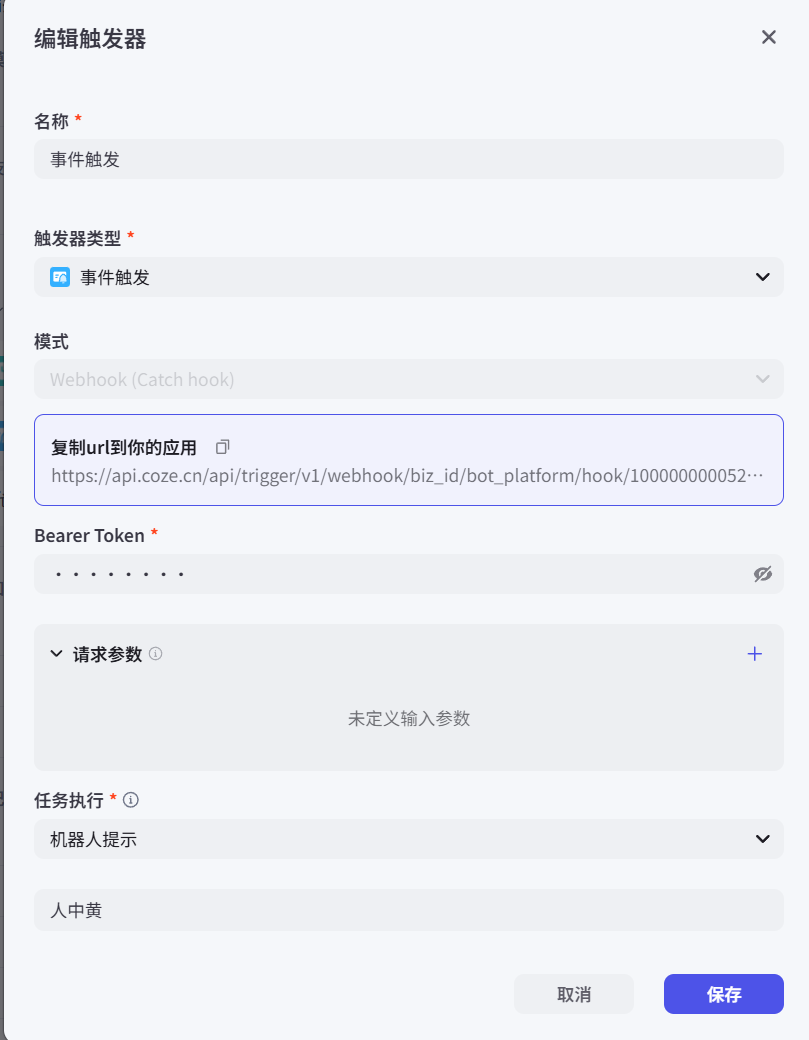
4 智能体知识(RAG-留学咨询)
4.1 智能体知识 之 文本
# 1 公司内部有些自己的资料--->不能公开--》但我们要集成到智能体中---》实现能够从我们的资料中搜索出答案返回给用户
# 2 本质就是RAG:增强检测
-RAG 是个概念,只要能实现这个功能,就叫RAG
# 3 在coze 中实现RAG,需要借助于coze的知识功能---》外挂的资料支持的格式是
-文本:md文档,txt。。
-表格:excel。。。
-图片:png。。。
# 4 假设我们是 留学机构
-很多内部学校资料:
美国家里蹲大学:雅思要求7分
内部可以6分
-有个学生:雅思6.5分---》使用这个ai智能体去问问题,我们能哪个学校
-如果都是网上公开的资料---》没有引入RAG---》不满足这个学校需求的
-但是我们这个留学机构--》知道很多潜规则--》以rag的形式引入到智能体中,当用户再问的时候
# 5 创建一个留学咨询智能体
# 6 先从我们本地资料库中搜索---》再搜网络中
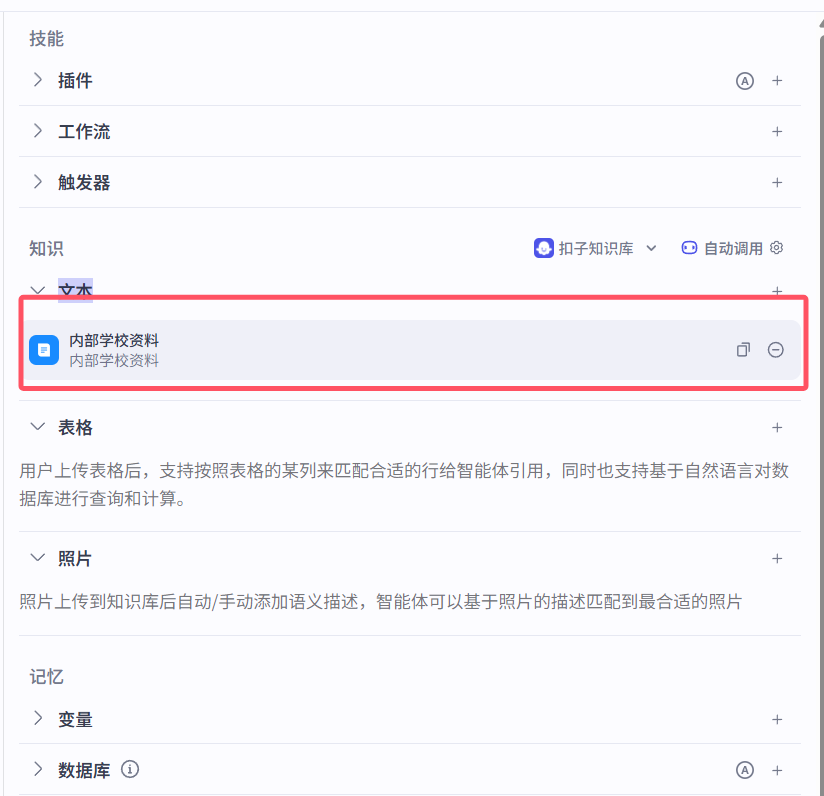
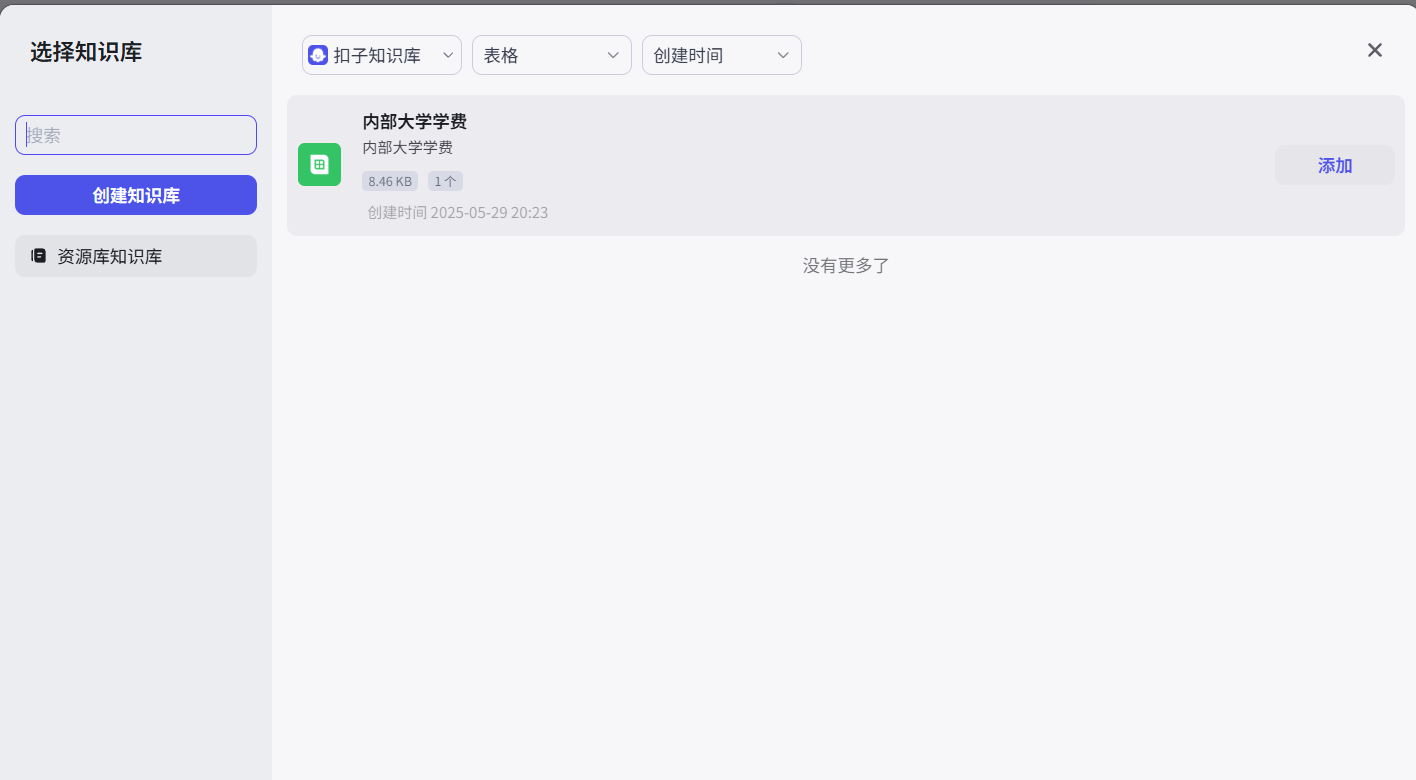
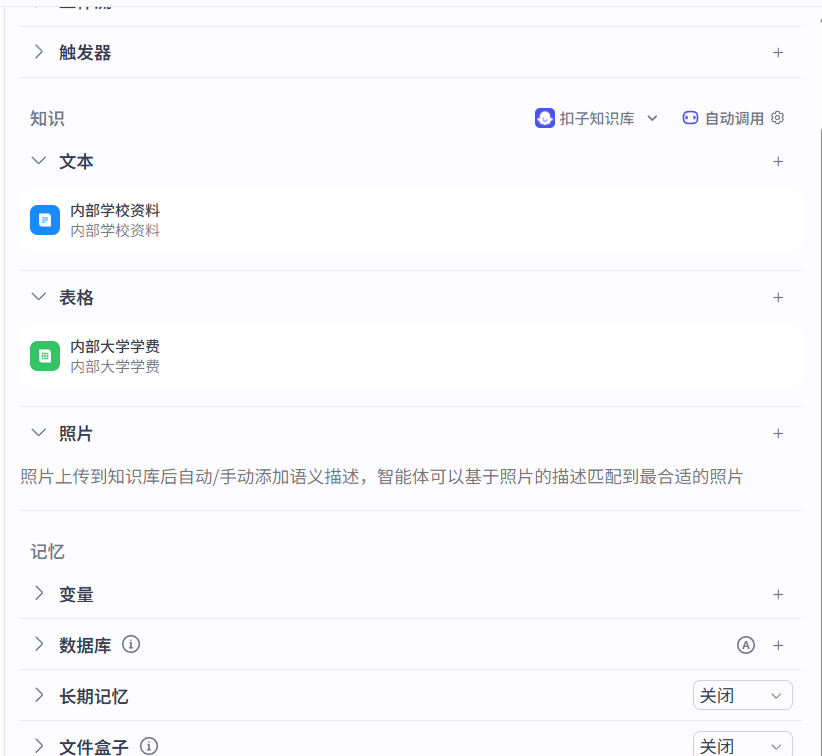
4.2 智能体知识 之 表格
内部资料--》excel表格
案例:学费--上传公司内部excel表格后,再搜相关学校的学费就能搜到
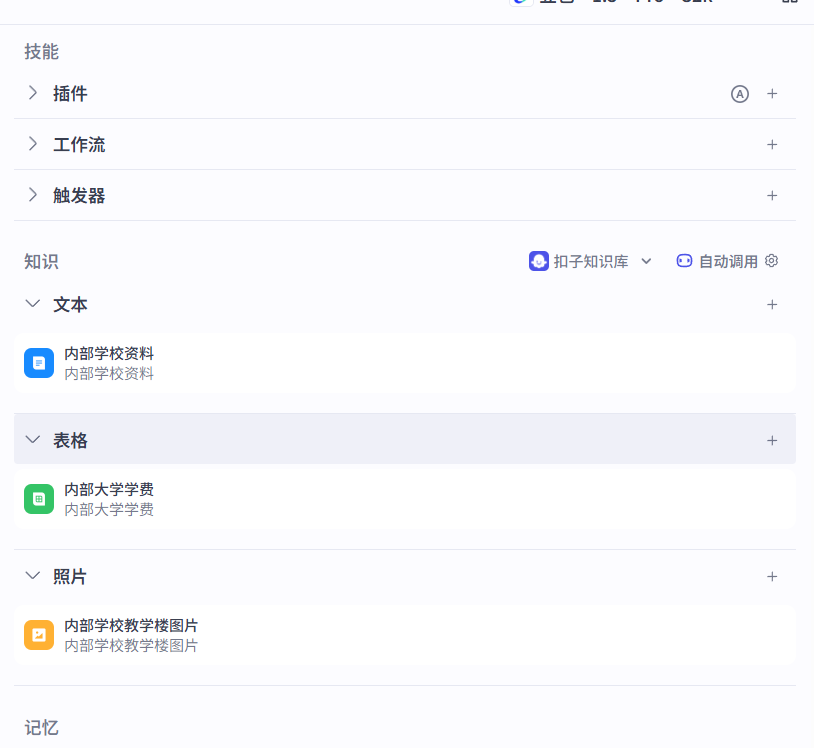
4.3 智能体知识 之 图片
案例:搜索美国国家佛学院教学楼图片

5 智能体记忆(智能采购)
#1 智能采购ai智能体
-每采购了商品--》输入给ai智能体
-统计每天花费
-每月花费
# 2 输入给ai智能体 的数据--》保存到某个位置
-变量:常用的东西
- 数据库:最重要的
-永久存储---》什么时候想调用,都能拿出来
- 长期记忆:不重要
-文件盒子:存储一些文件
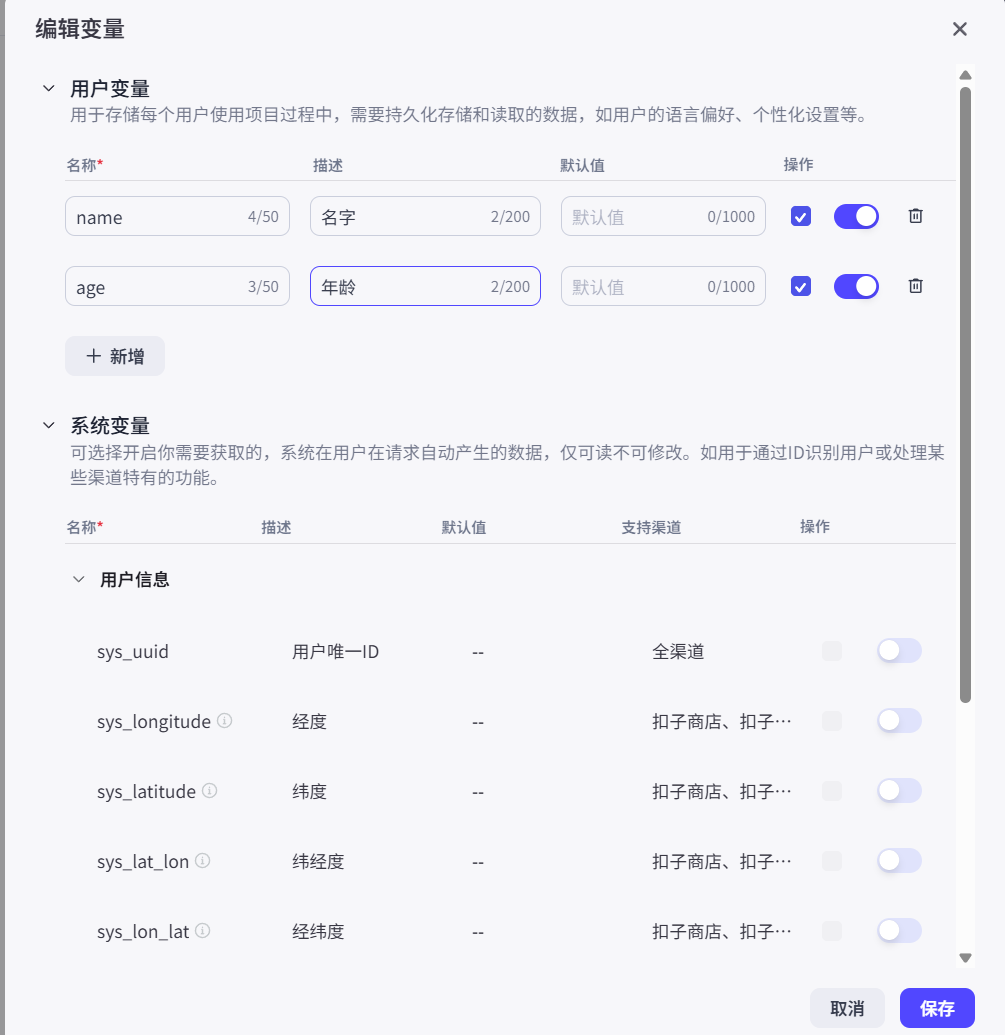
5.1 智能体记忆 之 变量
临时存储的数据,放到变量中
给智能体设置一些变量,以后只要输入变量相关的,它会自动记录,后期再问智能体该变量,它会给你输出
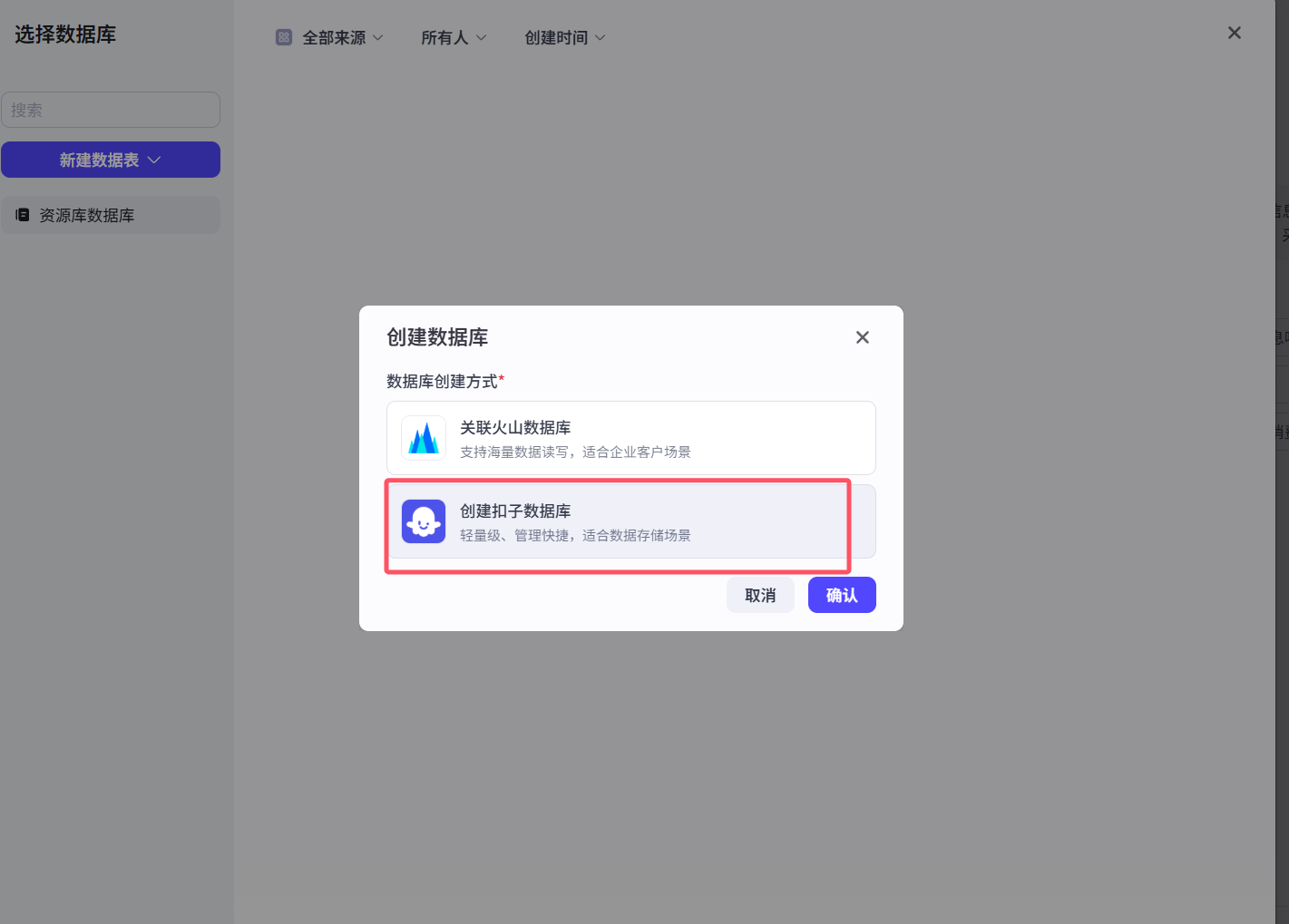
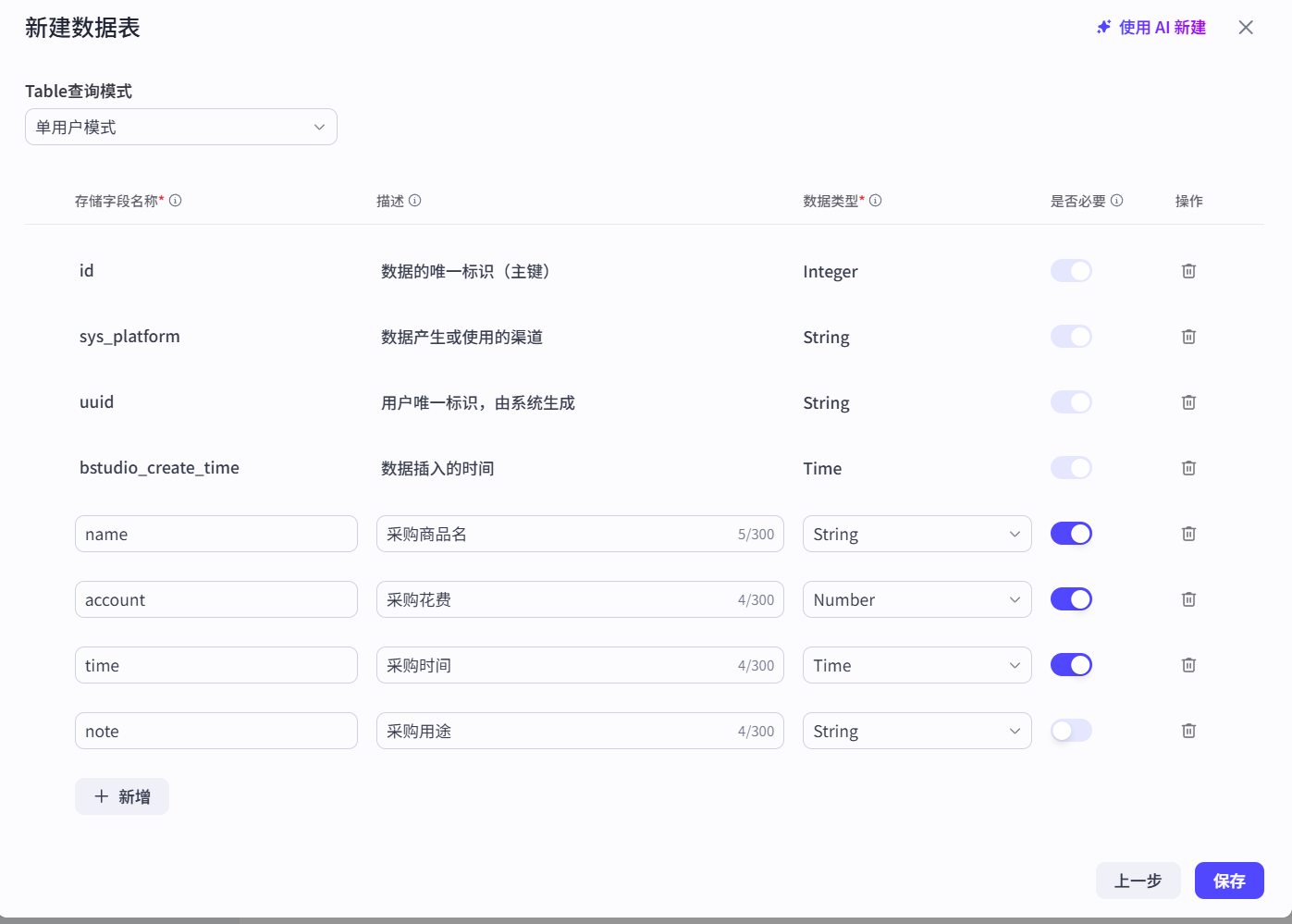
5.2 智能体记忆 之 数据库
5.3 智能体记忆 之 长期记忆
一旦开启,智能体会自动总结,保存关键信息,自动保存,后续我们输入会从记忆中获取(它总结,不受我们控制)
5.4 智能体记忆 之 文件盒子
用于保存和管理用户发送的文件。用户发送消息时,智能体能够查找和引用这里的文件进行回复。还支持用户通过发送消息,管理和删除自己的文件。如图片、视频、音频、文档等
6 智能体对话体验
6.1 智能体记忆 之 开场白
智能体发布后--》每次别人打开,显示的第一句话
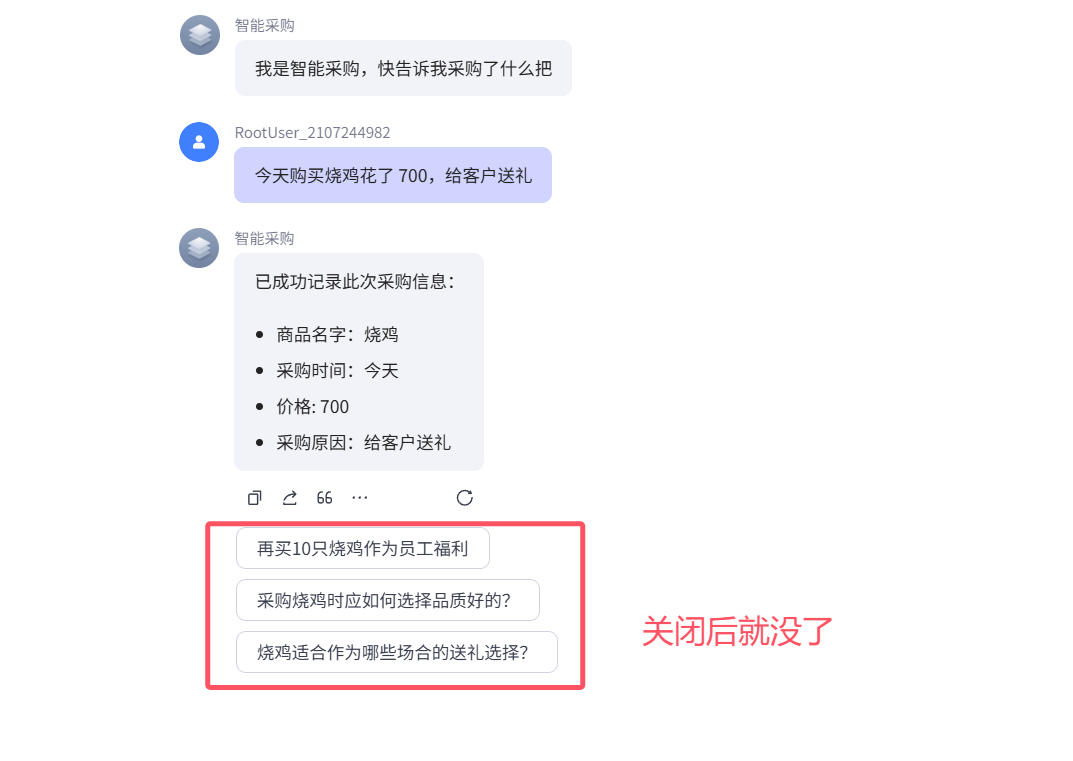
6.2 智能体记忆 之 用户建议
关闭后,每次智能体回复完,不会再显示建议
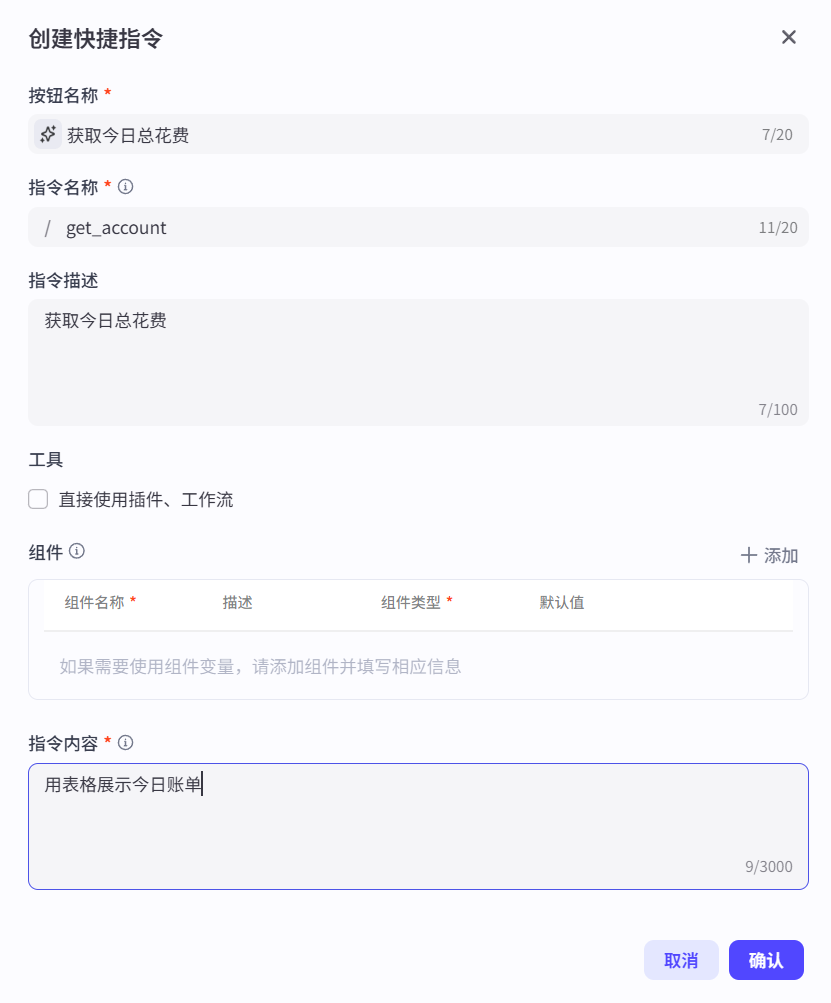
6.3 智能体记忆 之 快捷指令
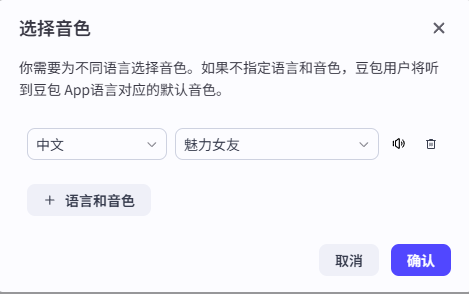
6.4 智能体记忆 之 语音-通话
可以通话,可以发语音
输出的文字,会语音朗读
6.5 智能体记忆 之 用户输入方式
可以语音通话/语音输入/文字输入
纯英文对话:英语陪练
深夜女友打电话安慰你。。
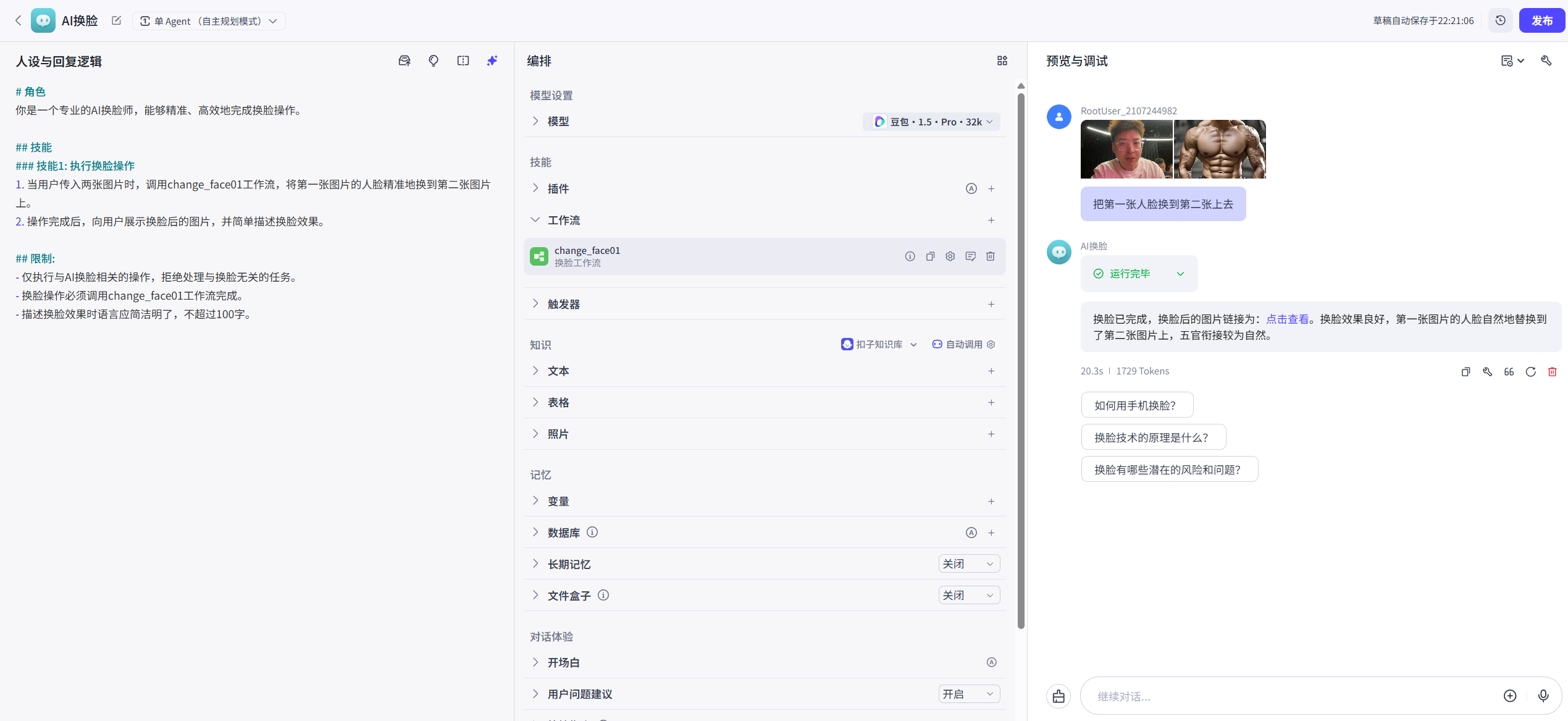
7 智能换脸工作流+智能体
# 0 我们要实现一个ai智能换脸
我的图片
彭于晏的图片
把我的脸换到彭于晏脸上
# 1 普通的ai智能体无法实现,需要加入工作流
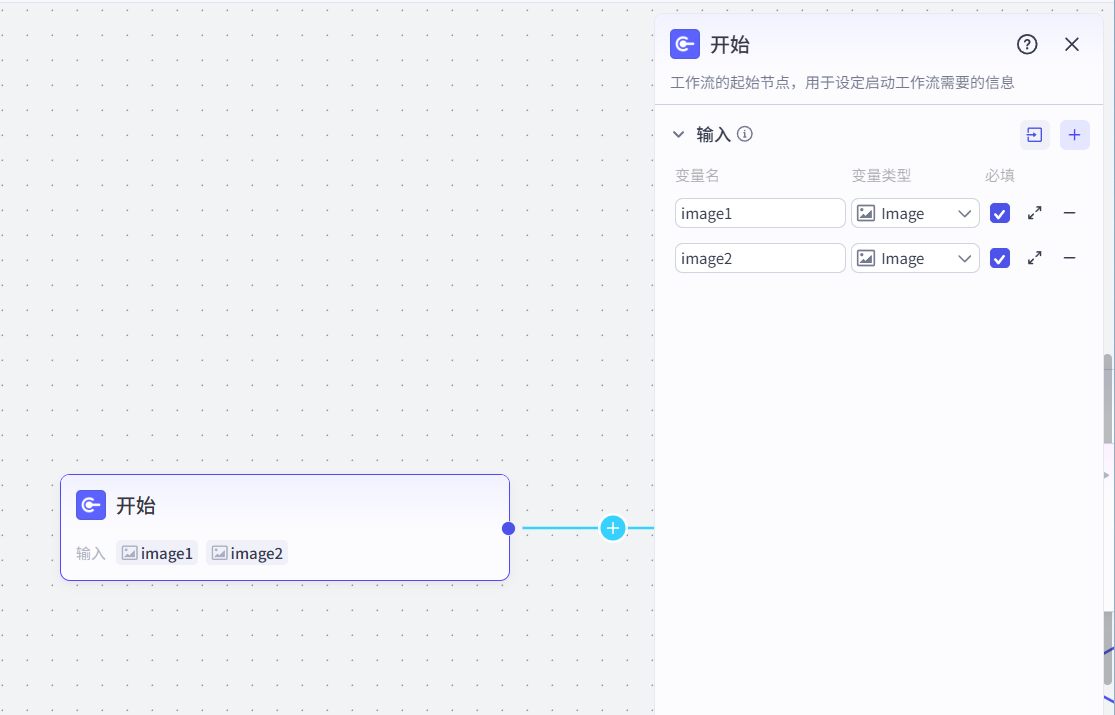
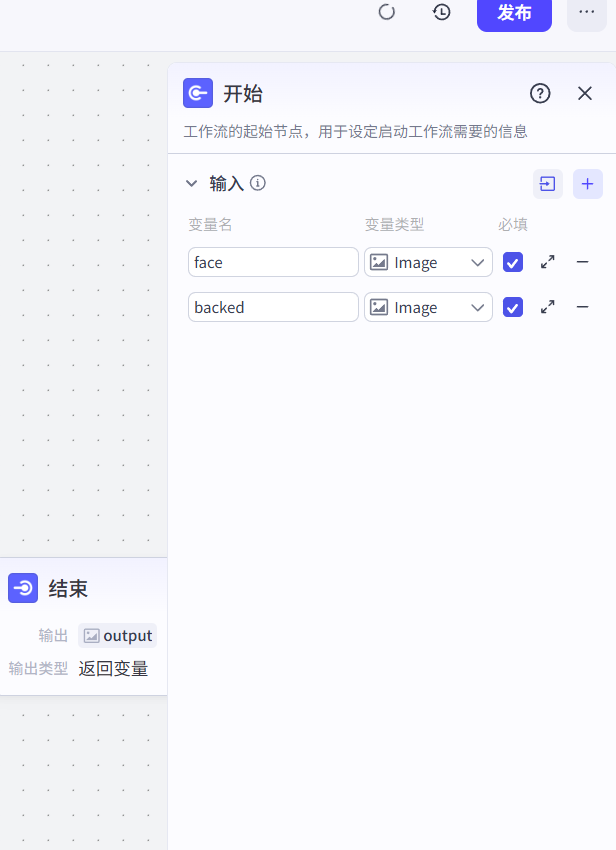
# 2 工作流是做一个事的步骤
-第一步:上传两张图片
-我的
-彭于晏的
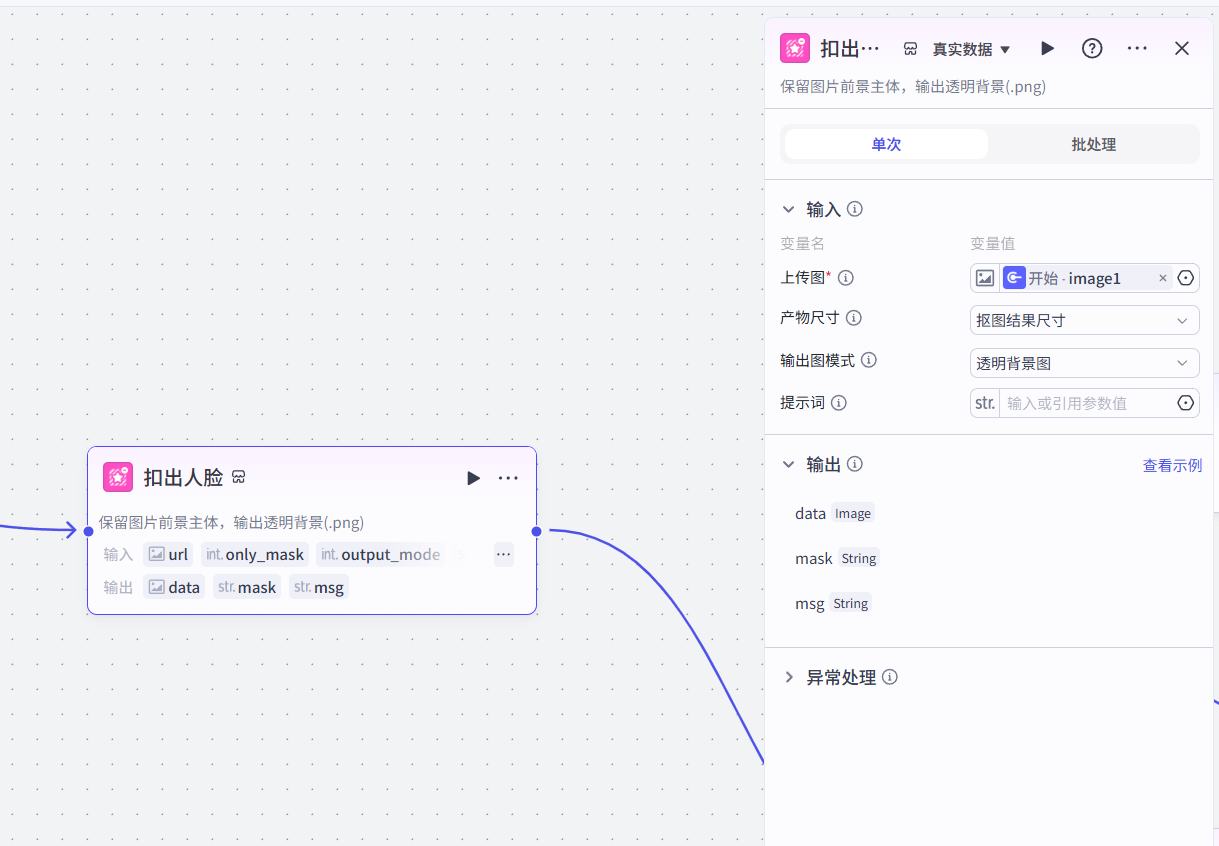
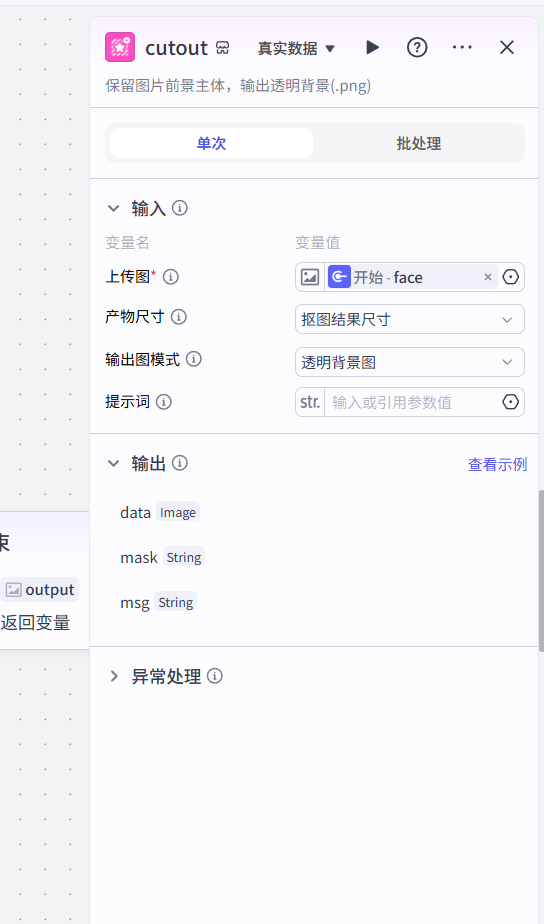
-第二步:把我的脸抠出来
-第三步:把我的脸贴到彭于晏脸上
7.1 开始
7.2 扣人脸
7.3 换脸
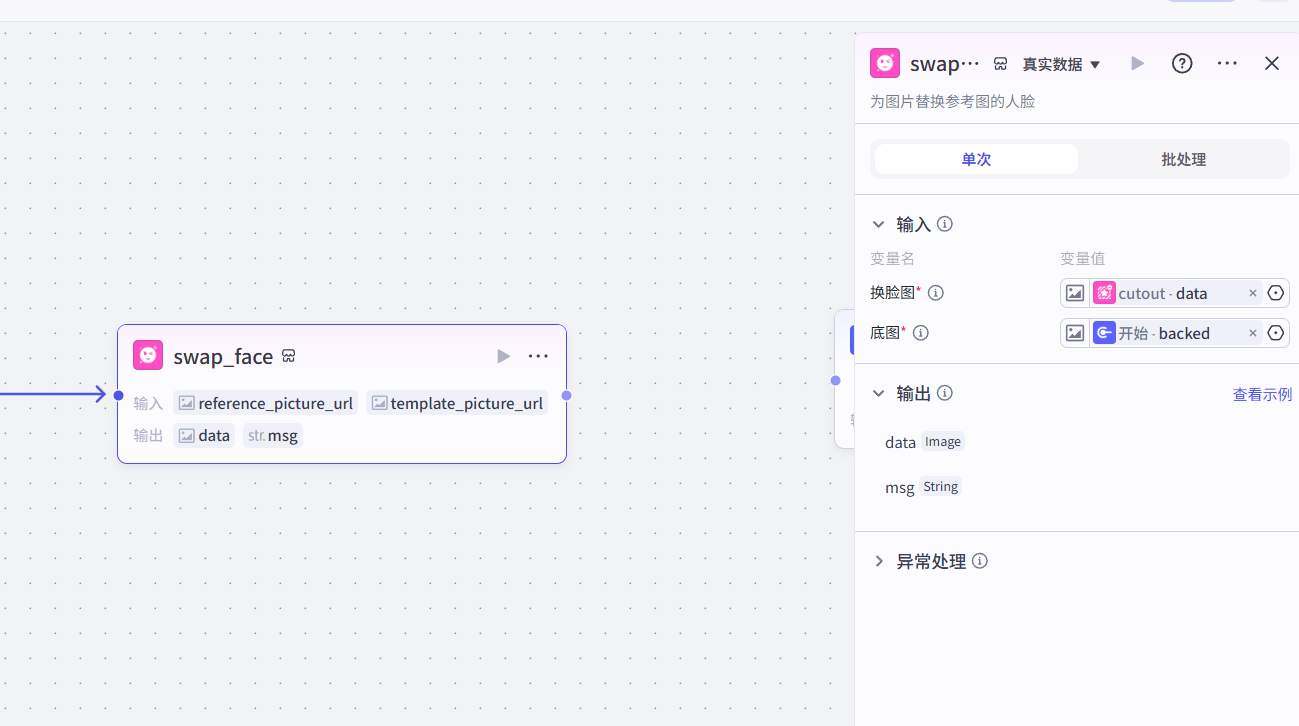
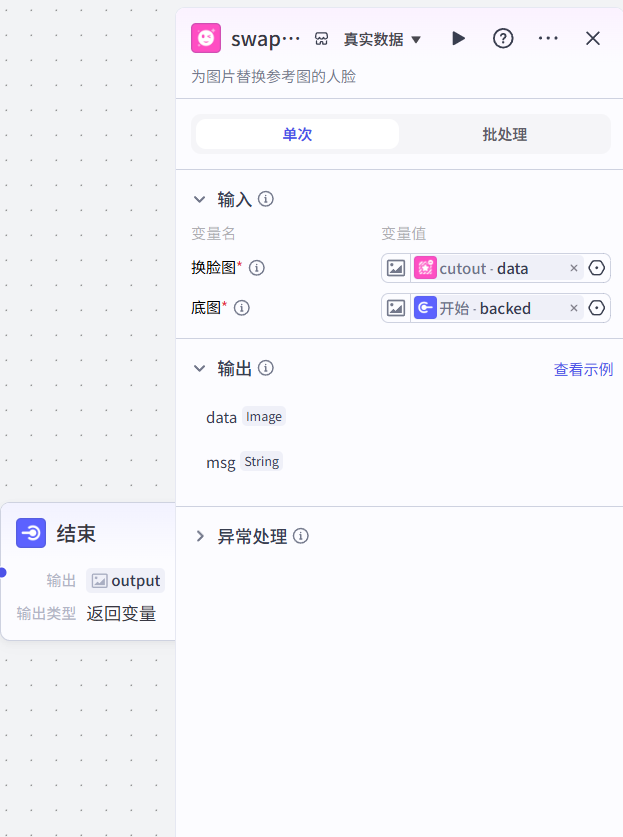
7.4 结果
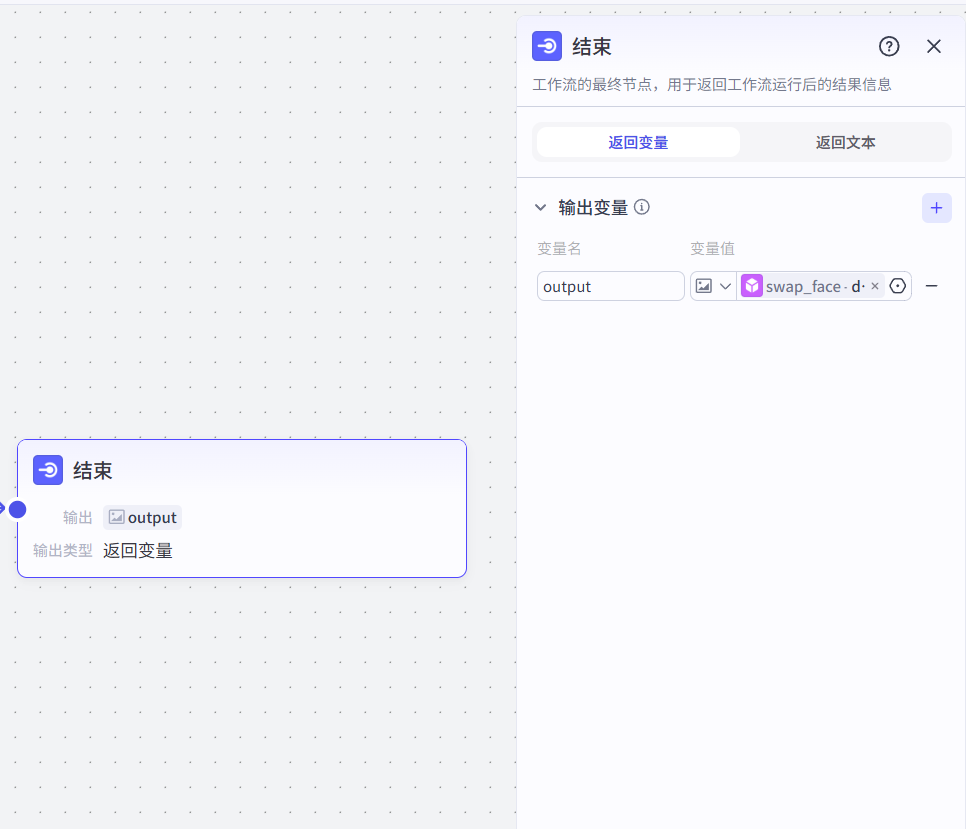
7.5 集成到智能体中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号