一期1. 深度学习基础
深度学习基础
1 深度学习¶
学习目标¶
知道深度学习概念
了解深度学习历史
1. 什么是深度学习¶
在介绍深度学习之前,我们先看下人工智能,机器学习和深度学习之间的关系:
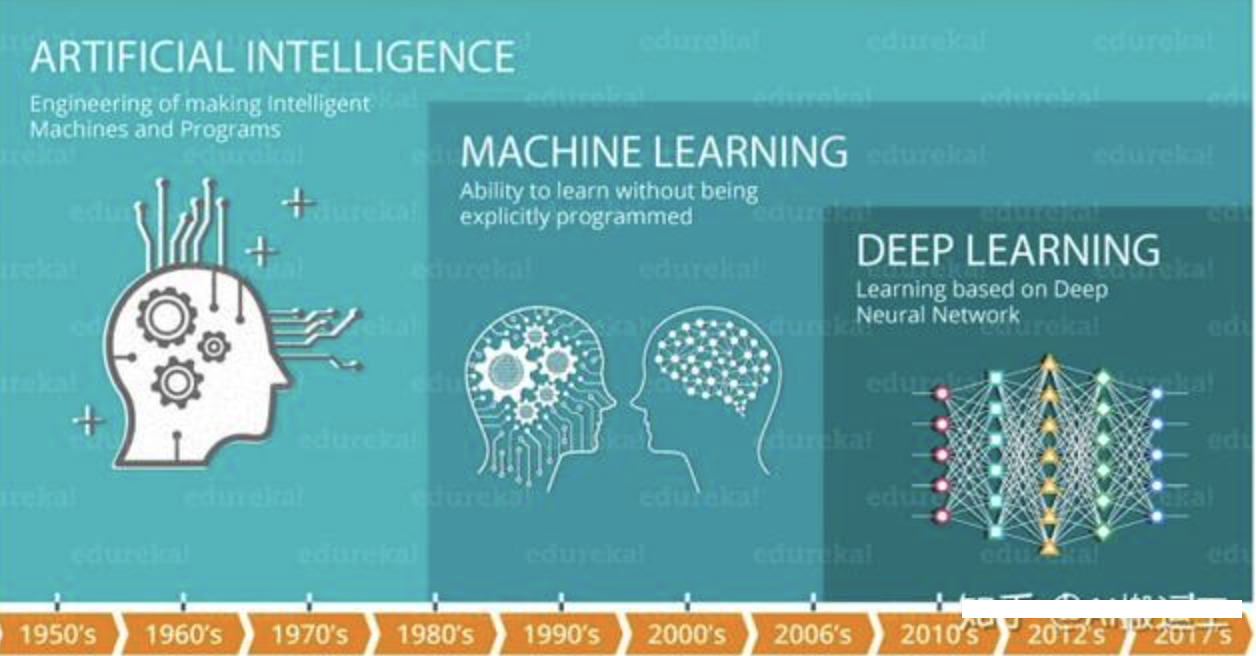
机器学习是实现人工智能的一种途径,深度学习是机器学习的一个子集,也就是说深度学习是实现机器学习的一种方法。与机器学习算法的主要区别如下图所示:

传统机器学习算术依赖人工设计特征,并进行特征提取,而深度学习方法不需要人工,而是依赖算法自动提取特征。深度学习模仿人类大脑的运行方式,从经验中学习获取知识。这也是深度学习被看做黑盒子,可解释性差的原因。
随着计算机软硬件的飞速发展,现阶段通过深度学习来模拟人脑来解释数据,包括图像,文本,音频等内容。目前深度学习的主要应用领域有:
语音识别
机器翻译
自动驾驶
当然在其他领域也能见到深度学习的身影,比如风控,安防,智能零售,医疗领域,推荐系统等。
2. 发展历史(了解)¶
深度学习其实并不是新的事物,深度学习所需要的神经网络技术起源于20世纪50年代,叫做感知机。当时也通常使用单层感知机,尽管结构简单,但是能够解决复杂的问题。后来感知机被证明存在严重的问题,因为只能学习线性可分函数,连简单的异或(XOR)等线性不可分问题都无能为力,1969年Marvin Minsky写了一本叫做《Perceptrons》的书,他提出了著名的两个观点:1.单层感知机没用,我们需要多层感知机来解决复杂问题 2.没有有效的训练算法。

20世纪80年代末期,用于人工神经网络的反向传播算法(也叫Back Propagation算法或者BP算法)的发明,给机器学习带来了希望,掀起了基于统计模型的机器学习热潮。这个热潮一直持续到今天。人们发现,利用BP算法可以让一个人工神经网络模型从大量训练样本中学习统计规律,从而对未知事件做预测。这种基于统计的机器学习方法比起过去基于人工规则的系统,在很多方面显出优越性。这个时候的人工神经网络,虽也被称作多层感知机(Multi-layer Perceptron),但实际是种只含有一层隐层节点的浅层模型。
2006年,杰弗里·辛顿以及他的学生鲁斯兰·萨拉赫丁诺夫正式提出了深度学习的概念。
2012年,在著名的ImageNet图像识别大赛中,杰弗里·辛顿领导的小组采用深度学习模型AlexNet一举夺冠。AlexNet采用ReLU激活函数,从根本上解决了梯度消失问题,并采用GPU极大的提高了模型的运算速度。
同年,由斯坦福大学著名的吴恩达教授和世界顶尖计算机专家Jeff Dean共同主导的深度神经网络——DNN技术在图像识别领域取得了惊人的成绩,在ImageNet评测中成功的把错误率从26%降低到了15%。深度学习算法在世界大赛的脱颖而出,也再一次吸引了学术界和工业界对于深度学习领域的关注。
2016年,随着谷歌公司基于深度学习开发的AlphaGo以4:1的比分战胜了国际顶尖围棋高手李世石,深度学习的热度一时无两。后来,AlphaGo又接连和众多世界级围棋高手过招,均取得了完胜。这也证明了在围棋界,基于深度学习技术的机器人已经超越了人类。

2017年,基于强化学习算法的AlphaGo升级版AlphaGo Zero横空出世。其采用“从零开始”、“无师自通”的学习模式,以100:0的比分轻而易举打败了之前的AlphaGo。除了围棋,它还精通国际象棋等其它棋类游戏,可以说是真正的棋类“天才”。此外在这一年,深度学习的相关算法在医疗、金融、艺术、无人驾驶等多个领域均取得了显著的成果。所以,也有专家把2017年看作是深度学习甚至是人工智能发展最为突飞猛进的一年。
2019年,基于Transformer 的自然语言模型的持续增长和扩散,这是一种语言建模神经网络模型,可以在几乎所有任务上提高NLP的质量。Google甚至将其用作相关性的主要信号之一,这是多年来最重要的更新。
2020年,深度学习扩展到更多的应用场景,比如积水识别,路面塌陷等,而且疫情期间,在智能外呼系统,人群测温系统,口罩人脸识别等都有深度学习的应用。
3. 小节¶
本小节简单带着大家了解了下深度学习应用场景、以及发展历史。从本小节中,同学们应该能够感受深度学习目前是实现人工智能的一种非常有力的方法。
2 神经网络¶
学习目标¶
知道人工神经网络
1. 什么是神经网络¶
人工神经网络( Artificial Neural Network, 简写为ANN)也简称为神经网络(NN),是一种模仿生物神经网络结构和功能的 计算模型。人脑可以看做是一个生物神经网络,由众多的神经元连接而成。各个神经元传递复杂的电信号,树突接收到输入信号,然后对信号进行处理,通过轴突输出信号。下图是生物神经元示意图:
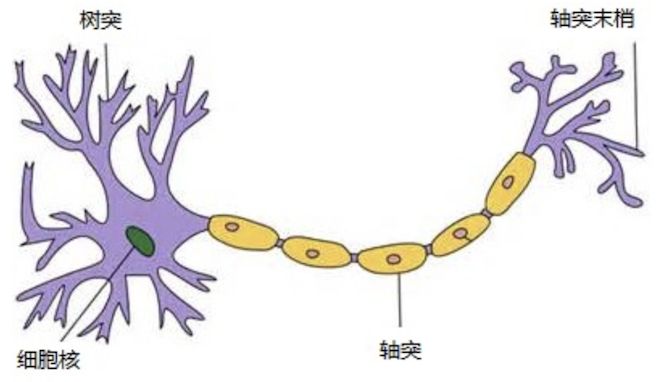
当电信号通过树突进入到细胞核时,会逐渐聚集电荷。达到一定的电位后,细胞就会被激活,通过轴突发出电信号。
2. 人工神经网络¶
那怎么构建人工神经网络中的神经元呢?

这个流程就像,来源不同树突(树突都会有不同的权重)的信息, 进行的加权计算, 输入到细胞中做加和,再通过激活函数输出细胞值。
接下来,我们使用多个神经元来构建神经网络,相邻层之间的神经元相互连接,并给每一个连接分配一个强度,如下图所示:
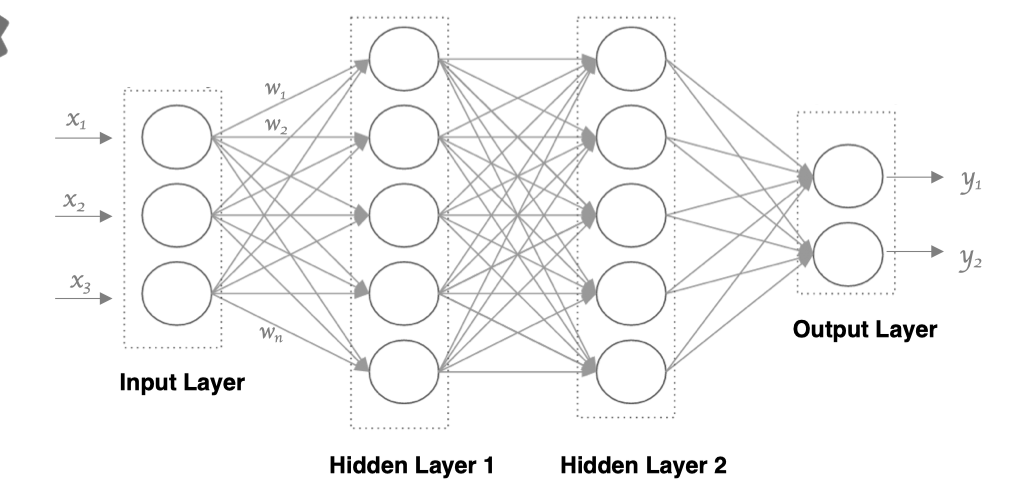
神经网络中信息只向一个方向移动,即从输入节点向前移动,通过隐藏节点,再向输出节点移动。其中的基本部分是:
输入层: 即输入 x 的那一层
输出层: 即输出 y 的那一层
隐藏层: 输入层和输出层之间都是隐藏层
特点是:
同一层的神经元之间没有连接。
第 N 层的每个神经元和第 N-1层 的所有神经元相连(这就是full connected的含义), 第N-1层神经元的输出就是第N层神经元的输入。每个连接都有一个权值。
3. 小节¶
本小节主要带着同学们了解下什么是神经网络。神经网络就是模拟人神经元的工作机理,并构造仿生的神经元来解决实际问题。一个简单的神经网络,包括输入层、隐藏层、输出层,其中隐藏层可以有很多层,每一层也可以包含数量众多的的神经元。
3 激活函数¶
学习目标¶
理解非线性因素
知道常见激活函数
1. 网络非线性因素的理解¶
激活函数用于对每层的输出数据进行变换, 进而为整个网络结构结构注入了非线性因素。此时, 神经网络就可以拟合各种曲线。如果不使用激活函数,整个网络虽然看起来复杂,其本质还相当于一种线性模型,如下公式所示:


1.没有引入非线性因素的网络等价于使用一个线性模型来拟合
2.通过给网络输出增加激活函数, 实现引入非线性因素, 使得网络模型可以逼近任意函数, 提升网络对复杂问题的拟合能力.
另外通过图像可视化的形式理解:
神经网络可视化
我们发现增加激活函数之后, 对于线性不可分的场景,神经网络的拟合能力更强。
2. 常见的激活函数¶
激活函数主要用来向神经网络中加入非线性因素,以解决线性模型表达能力不足的问题,它对神经网络有着极其重要的作用。我们的网络参数在更新时,使用的反向传播算法(BP),这就要求我们的激活函数必须可微。
2.1 sigmoid 激活函数¶

sigmoid 激活函数的函数图像如下:

从 sigmoid 函数图像可以得到,sigmoid 函数可以将任意的输入映射到 (0, 1) 之间,当输入的值大致在 <-6 或者 >6 时,意味着输入任何值得到的激活值都是差不多的,这样会丢失部分的信息。比如:输入 100 和输出 10000 经过 sigmoid 的激活值几乎都是等于 1 的,但是输入的数据之间相差 100 倍的信息就丢失了。
对于 sigmoid 函数而言,输入值在 [-6, 6] 之间输出值才会有明显差异,输入值在 [-3, 3] 之间才会有比较好的效果。
通过上述导数图像,我们发现导数数值范围是 (0, 0.25),当输入 <-6 或者 >6 时,sigmoid 激活函数图像的导数接近为 0,此时网络参数将更新极其缓慢,或者无法更新。
一般来说, sigmoid 网络在 5 层之内就会产生梯度消失现象。而且,该激活函数并不是以 0 为中心的,所以在实践中这种激活函数使用的很少。sigmoid函数一般只用于二分类的输出层。
在 PyTorch 中使用 sigmoid 函数的示例代码如下:
import torch
import matplotlib.pyplot as plt
import torch.nn.functional as F
def test():
_, axes = plt.subplots(1, 2)
# 函数图像
x = torch.linspace(-20, 20, 1000)
y = F.tanh(x)
axes[0].plot(x, y)
axes[0].grid()
axes[0].set_title('Sigmoid 函数图像')
# 导数图像
x = torch.linspace(-20, 20, 1000, requires_grad=True)
torch.sigmoid(x).sum().backward()
axes[1].plot(x.detach(), x.grad)
axes[1].grid()
axes[1].set_title('Sigmoid 导数图像')
plt.show()
if __name__ == '__main__':
test()
2.2 tanh 激活函数¶
Tanh 叫做双曲正切函数,其公式如下:
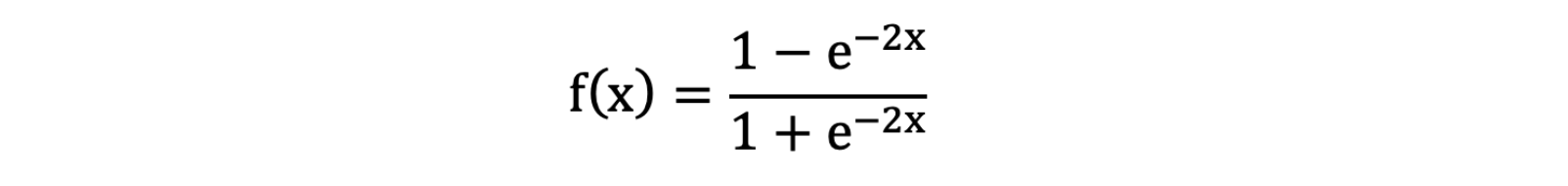
Tanh 的函数图像、导数图像如下:

由上面的函数图像可以看到,Tanh 函数将输入映射到 (-1, 1) 之间,图像以 0 为中心,在 0 点对称,当输入 大概<-3 或者 >3 时将被映射为 -1 或者 1。其导数值范围 (0, 1),当输入的值大概 <-3 或者 > 3 时,其导数近似 0。
与 Sigmoid 相比,它是以 0 为中心的,使得其收敛速度要比 Sigmoid 快,减少迭代次数。然而,从图中可以看出,Tanh 两侧的导数也为 0,同样会造成梯度消失。
若使用时可在隐藏层使用tanh函数,在输出层使用sigmoid函数。
import torch
import matplotlib.pyplot as plt
import torch.nn.functional as F
def test():
_, axes = plt.subplots(1, 2)
# 函数图像
x = torch.linspace(-20, 20, 1000)
y = F.tanh(x)
axes[0].plot(x, y)
axes[0].grid()
axes[0].set_title('Tanh 函数图像')
# 导数图像
x = torch.linspace(-20, 20, 1000, requires_grad=True)
F.tanh(x).sum().backward()
axes[1].plot(x.detach(), x.grad)
axes[1].grid()
axes[1].set_title('Tanh 导数图像')
plt.show()
if __name__ == '__main__':
test()
2.3 ReLU 激活函数¶
ReLU 激活函数公式如下:

函数图像如下:
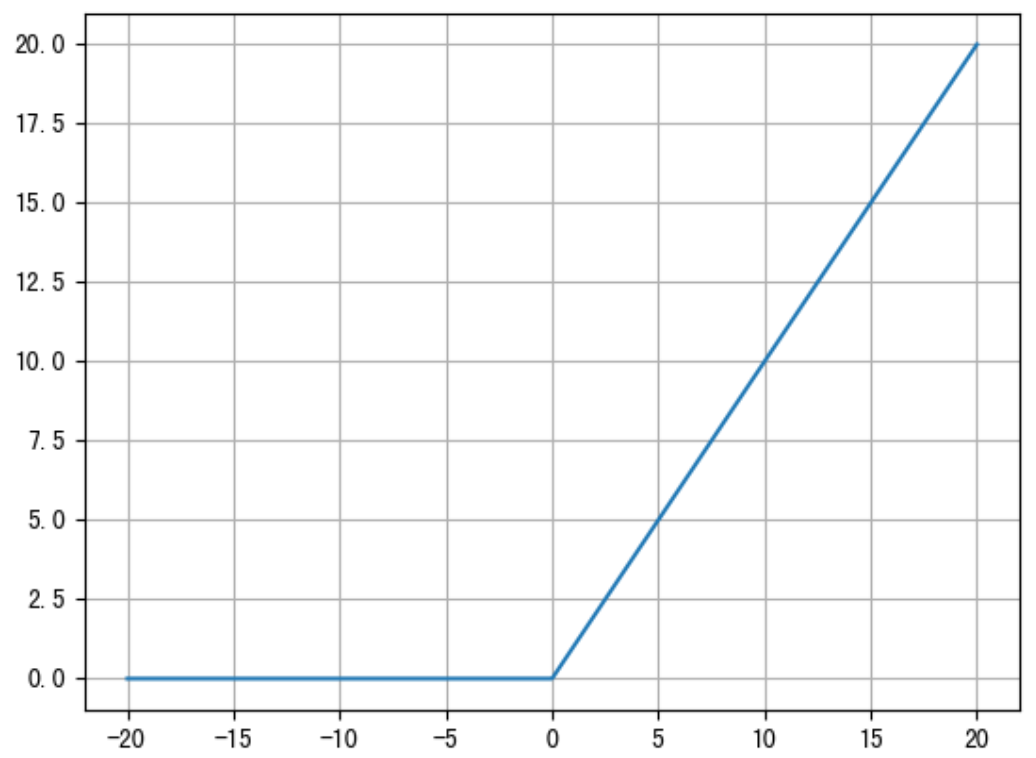
从上述函数图像可知,ReLU 激活函数将小于 0 的值映射为 0,而大于 0 的值则保持不变,它更加重视正信号,而忽略负信号,这种激活函数运算更为简单,能够提高模型的训练效率。
但是,如果我们网络的参数采用随机初始化时,很多参数可能为负数,这就使得输入的正值会被舍去,而输入的负值则会保留,这可能在大部分的情况下并不是我们想要的结果。
ReLU 的导数图像如下:

ReLU是目前最常用的激活函数。 从图中可以看到,当x<0时,ReLU导数为0,而当x>0时,则不存在饱和问题。所以,ReLU 能够在x>0时保持梯度不衰减,从而缓解梯度消失问题。然而,随着训练的推进,部分输入会落入小于0区域,导致对应权重无法更新。这种现象被称为“神经元死亡”。
与sigmoid相比,RELU的优势是:
采用sigmoid函数,计算量大(指数运算),反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
sigmoid函数反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
2.4 SoftMax¶
softmax用于多分类过程中,它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。
计算方法如下图所示:


Softmax 直白来说就是将网络输出的 logits 通过 softmax 函数,就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们将它理解成概率,选取概率最大(也就是值对应最大的)节点,作为我们的预测目标类别。
import torch
if __name__ == '__main__':
scores = torch.tensor([0.2, 0.02, 0.15, 0.15, 1.3, 0.5, 0.06, 1.1, 0.05, 3.75])
probabilities = torch.softmax(scores, dim=0)
print(probabilities)
程序输出结果:
tensor([0.0212, 0.0177, 0.0202, 0.0202, 0.0638, 0.0287, 0.0185, 0.0522, 0.0183,
0.7392])
3. 小节¶
本小节带着同学们了解下常见的激活函数,以及对应的 API 的使用。除了上述的激活函数,还存在很多其他的激活函数,如下图所示:
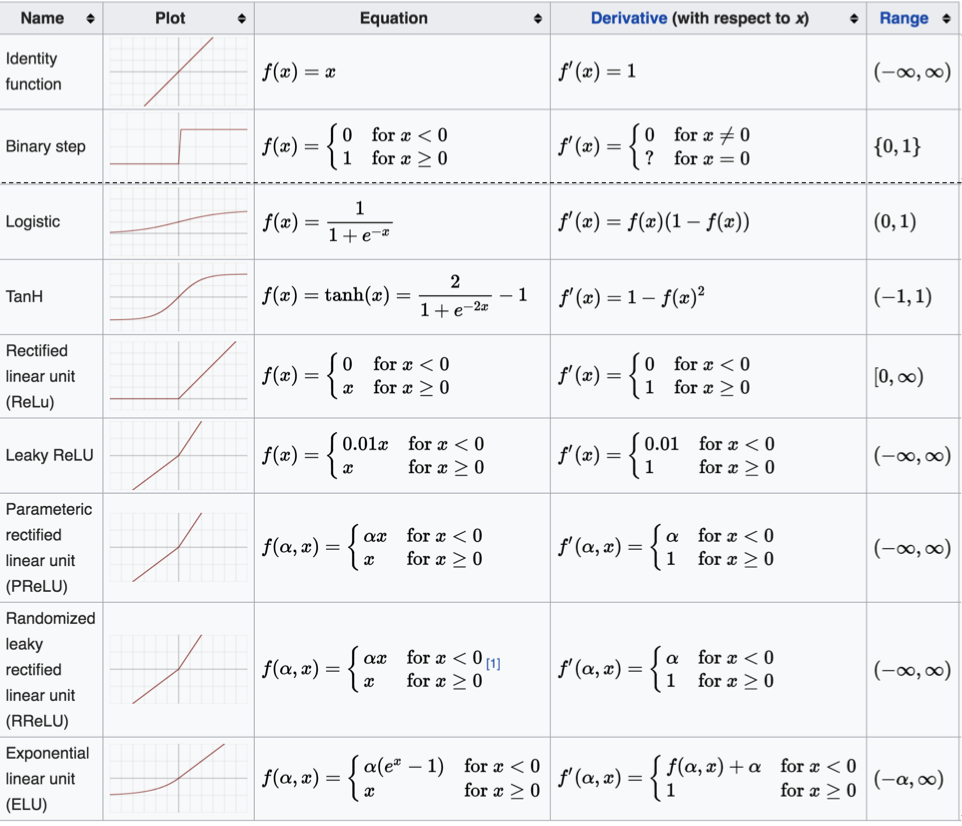
这么多激活函数, 我们应该如何选择呢?
对于隐藏层:
优先选择RELU激活函数
如果ReLu效果不好,那么尝试其他激活,如Leaky ReLu等。
如果你使用了Relu, 需要注意一下Dead Relu问题, 避免出现大的梯度从而导致过多的神经元死亡。
不要使用sigmoid激活函数,可以尝试使用tanh激活函数
对于输出层
二分类问题选择sigmoid激活函数
多分类问题选择softmax激活函数
回归问题选择identity激活函数
4 反向传播¶
学习目标¶
知道梯度下降算法
知道链式法则
掌握反向传播算法
多层神经网络的学习能力比单层网络强得多。想要训练多层网络,需要更强大的学习算法。误差反向传播算法(Back Propagation)是其中最杰出的代表,它是目前最成功的神经网络学习算法。现实任务使用神经网络时,大多是在使用 BP 算法进行训练,值得指出的是 BP 算法不仅可用于多层前馈神经网络,还可以用于其他类型的神经网络。通常说 BP 网络时,一般是指用 BP 算法训练的多层前馈神经网络。
这就需要了解两个概念:
- 正向传播
- 反向传播
1. 梯度下降算法回顾¶
梯度下降法简单来说就是一种寻找使损失函数最小化的方法。大家在机器学习阶段已经学过该算法,所以我们在这里就简单的回顾下,从数学上的角度来看,梯度的方向是函数增长速度最快的方向,那么梯度的反方向就是函数减少最快的方向,所以有:

其中,η是学习率,如果学习率太小,那么每次训练之后得到的效果都太小,增大训练的时间成本。如果,学习率太大,那就有可能直接跳过最优解,进入无限的训练中。解决的方法就是,学习率也需要随着训练的进行而变化。
在进行模型训练时,有三个基础的概念:
- Epoch: 使用全部数据对模型进行以此完整训练
- Batch: 使用训练集中的小部分样本对模型权重进行以此反向传播的参数更新
- Iteration: 使用一个 Batch 数据对模型进行一次参数更新的过程
实际上,梯度下降的几种方式的根本区别就在于 Batch Size不同,,如下表所示:

注:上表中 Mini-Batch 的 Batch 个数为 N / B + 1 是针对未整除的情况。整除则是 N / B。
假设数据集有 50000 个训练样本,现在选择 Batch Size = 256 对模型进行训练。
每个 Epoch 要训练的图片数量:50000
训练集具有的 Batch 个数:50000/256+1=196
每个 Epoch 具有的 Iteration 个数:196
10个 Epoch 具有的 Iteration 个数:1960
2. 前向和反向传播¶
利用反向传播算法对神经网络进行训练。该方法与梯度下降算法相结合,对网络中所有权重计算损失函数的梯度,并利用梯度值来更新权值以最小化损失函数。在介绍BP算法前,我们先看下前向传播与链式法则的内容。
前向传播指的是数据输入的神经网络中,逐层向前传输,一直到运算到输出层为止。

在网络的训练过程中经过前向传播后得到的最终结果跟训练样本的真实值总是存在一定误差,这个误差便是损失函数。想要减小这个误差,就用损失函数 ERROR,从后往前,依次求各个参数的偏导,这就是反向传播(Back Propagation)。
2.1 链式法则¶
反向传播算法是利用链式法则进行梯度求解及权重更新的。对于复杂的复合函数,我们将其拆分为一系列的加减乘除或指数,对数,三角函数等初等函数,通过链式法则完成复合函数的求导。为简单起见,这里以一个神经网络中常见的复合函数的例子来说明这个过程. 复合函数 𝑓(𝑥) 为:

其参数为权重 w、b。我们需要求关于 w 和 b 的偏导,然后应用梯度下降公式就可以更新参数。
我们将复合函数分解为一系列的初等函数导数相乘的形式:

整个复合函数 𝑓(𝑥; 𝑤, 𝑏) 关于参数 𝑤 和 𝑏 的导数可以通过 𝑓(𝑥; 𝑤, 𝑏) 与参数 𝑤 和 𝑏 之间路径上所有的导数连乘来得到,即:

以w为例,当 𝑥 = 1, 𝑤 = 0, 𝑏 = 0 时,可以得到:

常用函数的导数:

2.2 反向传播算法¶
BP (Back Propagation) 算法也叫做误差反向传播算法,它用于求解模型的参数梯度,从而使用梯度下降法来更新网络参数。它的基本工作流程如下:
1: 通过正向传播得到误差,所谓正向传播指的是数据从输入到输出层,经过层层计算得到预测值,并利用损失函数得到预测值和真实值之前的误差。
2: 通过反向传播把误差传递给模型的参数,从而对网络参数进行适当的调整,缩小预测值和真实值之间的误差。
3: 反向传播算法是利用链式法则进行梯度求解,然后进行参数更新。对于复杂的复合函数,我们将其拆分为一系列的加减乘除或指数,对数,三角函数等初等函数,通过链式法则完成复合函数的求导。
下面我们使用代码构建上面的网络, 并进行一次正向传播和反向传播.
import torch
import torch.nn as nn
import torch.optim as optim
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.linear1 = nn.Linear(2, 2)
self.linear2 = nn.Linear(2, 2)
# 网络参数初始化
self.linear1.weight.data = torch.tensor([[0.15, 0.20], [0.25, 0.30]])
self.linear2.weight.data = torch.tensor([[0.40, 0.45], [0.50, 0.55]])
self.linear1.bias.data = torch.tensor([0.35, 0.35])
self.linear2.bias.data = torch.tensor([0.60, 0.60])
def forward(self, x):
x = self.linear1(x)
x = torch.sigmoid(x)
x = self.linear2(x)
x = torch.sigmoid(x)
return x
if __name__ == '__main__':
inputs = torch.tensor([[0.05, 0.10]])
target = torch.tensor([[0.01, 0.99]])
# 获得网络输出值
net = Net()
output = net(inputs)
# print(output) # tensor([[0.7514, 0.7729]], grad_fn=<SigmoidBackward>)
# 计算误差
loss = torch.sum((output - target) ** 2) / 2
# print(loss) # tensor(0.2984, grad_fn=<DivBackward0>)
# 优化方法
optimizer = optim.SGD(net.parameters(), lr=0.5)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 打印 w5、w7、w1 的梯度值
print(net.linear1.weight.grad.data)
# tensor([[0.0004, 0.0009],
# [0.0005, 0.0010]])
print(net.linear2.weight.grad.data)
# tensor([[ 0.0822, 0.0827],
# [-0.0226, -0.0227]])
# 打印网络参数
optimizer.step()
print(net.state_dict())
# OrderedDict([('linear1.weight', tensor([[0.1498, 0.1996], [0.2498, 0.2995]])),
# ('linear1.bias', tensor([0.3456, 0.3450])),
# ('linear2.weight', tensor([[0.3589, 0.4087], [0.5113, 0.5614]])),
# ('linear2.bias', tensor([0.5308, 0.6190]))])
3. 小节¶
本小节主要学习了神经网络中最重要的反向传播(BP)算法,该算法通过链式求导的方法来计算神经网络中的各个权重参数的梯度,从而使用梯度下降算法来更新网络参数。
5 参数初始化¶
学习目标¶
知道常见初始化方法
我们在构建网络之后,网络中的参数是需要初始化的。我们需要初始化的参数主要有权重和偏置,偏置一般初始化为 0 即可,而对权重的初始化则会更加重要,我们介绍在 PyTorch 中为神经网络进行初始化的方法。
1. 常见初始化方法¶
均匀分布初始化,权重参数初始化从区间均匀随机取值。即在(-1/√d,1/√d)均匀分布中生成当前神经元的权重,其中d为每个神经元的输入数量。
正态分布初始化, 随机初始化从均值为0,标准差是1的高斯分布中取样,使用一些很小的值对参数W进行初始化.
全0初始化,将神经网络中的所有权重参数初始化为 0.
全1初始化,将神经网络中的所有权重参数初始化为 1.
固定值初始化,将神经网络中的所有权重参数初始化为某个固定值.
kaiming 初始化,也叫做 HE 初始化. HE 初始化分为正态分布的 HE 初始化、均匀分布的 HE 初始化.
xavier 初始化,也叫做Glorot初始化,该方法的基本思想是各层的激活值和梯度的方差在传播过程中保持一致。它有两种,一种是正态分布的 xavier 初始化、一种是均匀分布的 xavier 初始化.
接下来,我们使用 PyTorch 调用相关 API:
import torch
import torch.nn.functional as F
import torch.nn as nn
# 1. 均匀分布随机初始化
def test01():
linear = nn.Linear(5, 3)
# 从0-1均匀分布产生参数
nn.init.uniform_(linear.weight)
print(linear.weight.data)
# 2. 固定初始化
def test02():
linear = nn.Linear(5, 3)
nn.init.constant_(linear.weight, 5)
print(linear.weight.data)
# 3. 全0初始化
def test03():
linear = nn.Linear(5, 3)
nn.init.zeros_(linear.weight)
print(linear.weight.data)
# 4. 全1初始化
def test04():
linear = nn.Linear(5, 3)
nn.init.ones_(linear.weight)
print(linear.weight.data)
# 5. 正态分布随机初始化
def test05():
linear = nn.Linear(5, 3)
nn.init.normal_(linear.weight, mean=0, std=1)
print(linear.weight.data)
# 6. kaiming 初始化
def test06():
# kaiming 正态分布初始化
linear = nn.Linear(5, 3)
nn.init.kaiming_normal_(linear.weight)
print(linear.weight.data)
# kaiming 均匀分布初始化
linear = nn.Linear(5, 3)
nn.init.kaiming_uniform_(linear.weight)
print(linear.weight.data)
# 7. xavier 初始化
def test07():
# xavier 正态分布初始化
linear = nn.Linear(5, 3)
nn.init.xavier_normal_(linear.weight)
print(linear.weight.data)
# xavier 均匀分布初始化
linear = nn.Linear(5, 3)
nn.init.xavier_uniform_(linear.weight)
print(linear.weight.data)
if __name__ == '__main__':
test07()
2. 小节¶
网络构建完成之后,我们需要对网络参数进行初始化。常见的初始化方法有随机初始化、全0初始化、全1初始化、Kaiming 初始化、Xavier 初始化等,一般我们在使用 PyTorch 构建网络模型时,每个网络层的参数都有默认的初始化方法,当然同学们也可以通过交给大家的方法来使用指定的方式对网络参数进行初始化。
6 优化方法¶
学习目标¶
知道常见优化方法的问题及解决方案
传统的梯度下降优化算法中,可能会碰到以下情况:
碰到平缓区域,梯度值较小,参数优化变慢
碰到 “鞍点” ,梯度为 0,参数无法优化
碰到局部最小值
对于这些问题, 出现了一些对梯度下降算法的优化方法,例如:Momentum、AdaGrad、RMSprop、Adam 等.
1. 指数加权平均¶
我们最常见的算数平均指的是将所有数加起来除以数的个数,每个数的权重是相同的。加权平均指的是给每个数赋予不同的权重求得平均数。移动平均数,指的是计算最近邻的 N 个数来获得平均数。
指数移动加权平均则是参考各数值,并且各数值的权重都不同,距离越远的数字对平均数计算的贡献就越小(权重较小),距离越近则对平均数的计算贡献就越大(权重越大)。
比如:明天气温怎么样,和昨天气温有很大关系,而和一个月前的气温关系就小一些。
计算公式可以用下面的式子来表示:

St 表示指数加权平均值;
Yt 表示 t 时刻的值;
β 调节权重系数,该值越大平均数越平缓。
我们接下来通过一段代码来看下结果,我们随机产生进 30 天的气温数据:
import torch
import matplotlib.pyplot as plt
ELEMENT_NUMBER = 30
# 1. 实际平均温度
def test01():
# 固定随机数种子
torch.manual_seed(0)
# 产生30天的随机温度
temperature = torch.randn(size=[ELEMENT_NUMBER,]) * 10
print(temperature)
# 绘制平均温度
days = torch.arange(1, ELEMENT_NUMBER + 1, 1)
plt.plot(days, temperature, color='r')
plt.scatter(days, temperature)
plt.show()
# 2. 指数加权平均温度
def test02(beta=0.9):
# 固定随机数种子
torch.manual_seed(0)
# 产生30天的随机温度
temperature = torch.randn(size=[ELEMENT_NUMBER,]) * 10
print(temperature)
exp_weight_avg = []
for idx, temp in enumerate(temperature, 1):
# 第一个元素的的 EWA 值等于自身
if idx == 1:
exp_weight_avg.append(temp)
continue
# 第二个元素的 EWA 值等于上一个 EWA 乘以 β + 当前气氛乘以 (1-β)
new_temp = exp_weight_avg[idx - 2] * beta + (1 - beta) * temp
exp_weight_avg.append(new_temp)
days = torch.arange(1, ELEMENT_NUMBER + 1, 1)
plt.plot(days, exp_weight_avg, color='r')
plt.scatter(days, temperature)
plt.show()
if __name__ == '__main__':
test01()
test02(0.5)
test02(0.9)
程序结果如下:



从程序运行结果可以看到:
指数加权平均绘制出的气氛变化曲线更加平缓;
β 的值越大,则绘制出的折线越加平缓;
β 值一般默认都是 0.9.
2. Momentum¶
当梯度下降碰到 “峡谷” 、”平缓”、”鞍点” 区域时, 参数更新速度变慢. Momentum 通过指数加权平均法,累计历史梯度值,进行参数更新,越近的梯度值对当前参数更新的重要性越大。

梯度计算公式:Dt = β * St-1 + (1- β) * Dt
1: St-1 表示历史梯度移动加权平均值
2: wt 表示当前时刻的梯度值
3: β 为权重系数
咱们举个例子,假设:权重 β 为 0.9,例如:
第一次梯度值:s1 = d1 = w1
第二次梯度值:s2 = 0.9 * s1 + d2 * 0.1
第三次梯度值:s3 = 0.9 * s2 + d3 * 0.1
第四次梯度值:s4 = 0.9 * s3 + d4 * 0.1
1: w 表示初始梯度
2: d 表示当前轮数计算出的梯度值
3: s 表示历史梯度值
梯度下降公式中梯度的计算,就不再是当前时刻 t 的梯度值,而是历史梯度值的指数移动加权平均值。公式修改为:

那么,Monmentum 优化方法是如何一定程度上克服 “平缓”、”鞍点”、”峡谷” 的问题呢?
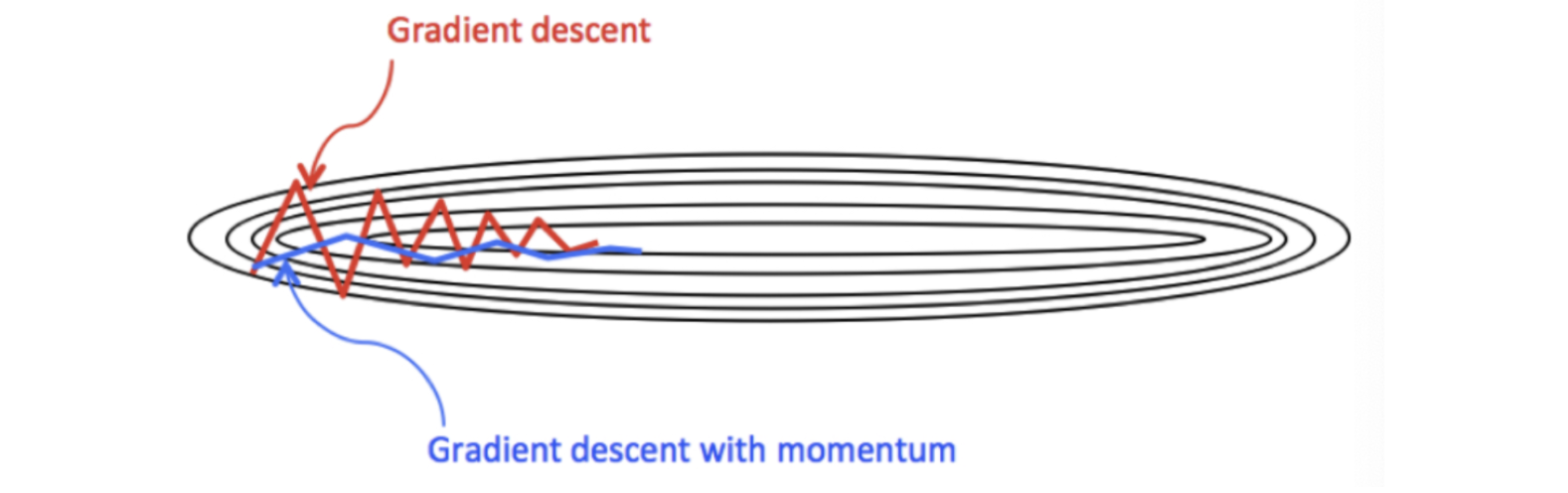
当处于鞍点位置时,由于当前的梯度为 0,参数无法更新。但是 Momentum 动量梯度下降算法已经在先前积累了一些梯度值,很有可能使得跨过鞍点。
由于 mini-batch 普通的梯度下降算法,每次选取少数的样本梯度确定前进方向,可能会出现震荡,使得训练时间变长。Momentum 使用移动加权平均,平滑了梯度的变化,使得前进方向更加平缓,有利于加快训练过程。一定程度上有利于降低 “峡谷” 问题的影响。
峡谷问题:就是会使得参数更新出现剧烈震荡.
Momentum 算法可以理解为是对梯度值的一种调整,我们知道梯度下降算法中还有一个很重要的学习率,Momentum 并没有学习率进行优化。
3. AdaGrad¶
AdaGrad 通过对不同的参数分量使用不同的学习率,AdaGrad 的学习率总体会逐渐减小,这是因为 AdaGrad 认为:在起初时,我们距离最优目标仍较远,可以使用较大的学习率,加快训练速度,随着迭代次数的增加,学习率逐渐下降。
其计算步骤如下:
1: 初始化学习率 α、初始化参数 θ、小常数 σ = 1e-6
2: 初始化梯度累积变量 s = 0
3: 从训练集中采样 m 个样本的小批量,计算梯度 g
4: 累积平方梯度 s = s + g ⊙ g,⊙ 表示各个分量相乘
5: 学习率 α 的计算公式如下:
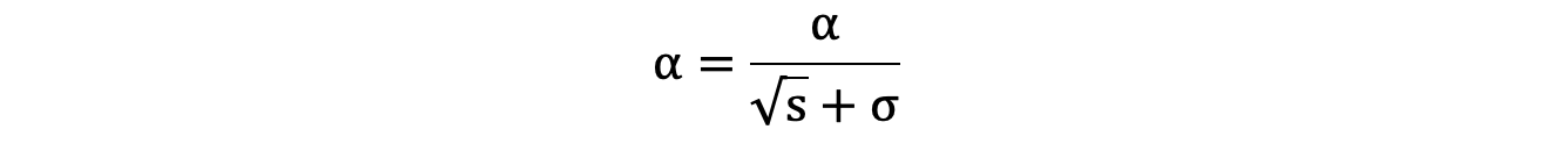
6: 参数更新公式如下:

7: 重复 2-7 步骤.
AdaGrad 缺点是可能会使得学习率过早、过量的降低,导致模型训练后期学习率太小,较难找到最优解。
4. RMSProp¶
RMSProp 优化算法是对 AdaGrad 的优化. 最主要的不同是,其使用指数移动加权平均梯度替换历史梯度的平方和。其计算过程如下:
1: 初始化学习率 α、初始化参数 θ、小常数 σ = 1e-6
2: 初始化参数 θ
3: 初始化梯度累计变量 s
4: 从训练集中采样 m 个样本的小批量,计算梯度 g
5: 使用指数移动平均累积历史梯度,公式如下:

6: 学习率 α 的计算公式如下:

7: 参数更新公式如下:

RMSProp 与 AdaGrad 最大的区别是对梯度的累积方式不同,对于每个梯度分量仍然使用不同的学习率。
RMSProp 通过引入衰减系数 β,控制历史梯度对历史梯度信息获取的多少. 被证明在神经网络非凸条件下的优化更好,学习率衰减更加合理一些。
需要注意的是:AdaGrad 和 RMSProp 都是对于不同的参数分量使用不同的学习率,如果某个参数分量的梯度值较大,则对应的学习率就会较小,如果某个参数分量的梯度较小,则对应的学习率就会较大一些
5. Adam¶
Momentum 使用指数加权平均计算当前的梯度值、AdaGrad、RMSProp 使用自适应的学习率,Adam 结合了 Momentum、RMSProp 的优点,使用: 移动加权平均的梯度和移动加权平均的学习率。使得能够自适应学习率的同时,也能够使用 Momentum 的优点。
6. 小节¶
本小节主要学习了常见的一些对普通梯度下降算法的优化方法,主要有 Momentum、AdaGrad、RMSProp、Adam 等优化方法,其中 Momentum 使用指数加权平均参考了历史梯度,使得梯度值的变化更加平缓。AdaGrad 则是针对学习率进行了自适应优化,由于其实现可能会导致学习率下降过快,RMSProp 对 AdaGrad 的学习率自适应计算方法进行了优化,Adam 则是综合了 Momentum 和 RMSProp 的优点,在很多场景下,Adam 的表示都很不错。
7 正则化¶
学习目标¶
知道正则化原因和方法
在训深层练神经网络时,由于模型参数较多,在数据量不足的情况下,很容易过拟合。Dropout 就是在神经网络中一种缓解过拟合的方法。
1. Dropout 层的原理和使用¶
我们知道,缓解过拟合的方式就是降低模型的复杂度,而 Dropout 就是通过减少神经元之间的连接,把稠密的神经网络神经元连接,变成稀疏的神经元连接,从而达到降低网络复杂度的目的。
我们先通过一段代码观察下丢弃层的效果:
import torch
import torch.nn as nn
def test():
# 初始化丢弃层
dropout = nn.Dropout(p=0.8)
# 初始化输入数据
inputs = torch.randint(0, 10, size=[5, 8]).float()
print(inputs)
print('-' * 50)
outputs = dropout(inputs)
print(outputs)
if __name__ == '__main__':
test()
程序输出结果:
tensor([[1., 0., 3., 6., 7., 7., 5., 7.],
[6., 8., 4., 6., 2., 0., 4., 1.],
[1., 4., 6., 9., 3., 1., 2., 1.],
[0., 6., 3., 7., 1., 7., 8., 9.],
[5., 6., 8., 4., 1., 7., 5., 5.]])
--------------------------------------------------
tensor([[ 0., 0., 15., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 10., 0., 0., 0.],
[ 0., 0., 0., 45., 0., 0., 0., 0.],
[ 0., 0., 15., 0., 0., 0., 0., 0.],
[25., 0., 0., 0., 0., 0., 0., 25.]])
我们将 Dropout 层的概率 p 设置为 0.8,此时经过 Dropout 层计算的张量中就出现了很多 0 , 概率 p 设置值越大,则张量中出现的 0 就越多。上面结果的计算过程如下:
先按照 p 设置的概率,随机将部分的张量元素设置为 0
为了校正张量元素被设置为 0 带来的影响,需要对非 0 的元素进行缩放,其缩放因子为: 1/(1-p),上面代码中 p 的值为 0.8, 根据公式缩放因子为:1/(1-0.8) = 5
比如:第 3 个元素,原来是 3,乘以缩放因子之后变成 15。
我们也发现了,丢弃概率 p 的值越大,则缩放因子的值就越大,相对其他未被设置的元素就要更多的变大。丢弃概率 P 的值越小,则缩放因子的值就越小,相对应其他未被置为 0 的元素就要有较小的变大。
当张量某些元素被设置为 0 时,对网络会带来什么影响?
比如上面这种情况,如果输入该样本,会使得某些参数无法更新,请看下面的代码:
import torch
import torch.nn as nn
# 设置随机数种子
torch.manual_seed(0)
def caculate_gradient(x, w):
y = x @ w
y = y.sum()
y.backward()
print('Gradient:', w.grad.reshape(1, -1).squeeze().numpy())
def test01():
# 初始化权重
w = torch.randn(15, 1, requires_grad=True)
# 初始化输入数据
x = torch.randint(0, 10, size=[5, 15]).float()
# 计算梯度
caculate_gradient(x, w)
def test02():
# 初始化权重
w = torch.randn(15, 1, requires_grad=True)
# 初始化输入数据
x = torch.randint(0, 10, size=[5, 15]).float()
# 初始化丢弃层
dropout = nn.Dropout(p=0.8)
x = dropout(x)
# 计算梯度
caculate_gradient(x, w)
if __name__ == '__main__':
test01()
print('-' * 70)
test02()
程序输出结果:
Gradient: [19. 15. 16. 13. 34. 23. 20. 22. 23. 26. 21. 29. 28. 22. 29.]
----------------------------------------------------------------------
Gradient: [ 5. 0. 35. 0. 0. 45. 40. 40. 0. 20. 25. 45. 55. 0. 10.]
从程序结果来看,是否经过 Dropout 层对梯度的计算产生了不小的影响,例如:经过 Dropout 层之后有一些梯度为 0,这使得参数无法得到更新,从而达到了降低网络复杂度的目的。
2. 小节¶
在本小节中,我们主要学习 dropout 层的使用,其作用用于控制网络复杂度,达到正则化的目的,类似于 L2 正则化对线性回归的作用。所以,同学们以后经常会看到该层在网络中出现。
8 批量归一化¶
学习目标¶
知道批量归一化公式
在神经网络的搭建过程中,Batch Normalization (批量归一化)是经常使用一个网络层,其主要的作用是控制数据的分布,加快网络的收敛。
我们知道,神经网络的学习其实在学习数据的分布,随着网络的深度增加、网络复杂度增加,一般流经网络的数据都是一个 mini batch,每个 mini batch 之间的数据分布变化非常剧烈,这就使得网络参数频繁的进行大的调整以适应流经网络的不同分布的数据,给模型训练带来非常大的不稳定性,使得模型难以收敛。
如果我们对每一个 mini batch 的数据进行标准化之后,数据分布就变得稳定,参数的梯度变化也变得稳定,有助于加快模型的收敛。
1. 批量归一化公式¶

λ 和 β 是可学习的参数,它相当于对标准化后的值做了一个线性变换,λ 为系数,β 为偏置;
eps 通常指为 1e-5,避免分母为 0;
E(x) 表示变量的均值;
Var(x) 表示变量的方差;
数据在经过 BN 层之后,无论数据以前的分布是什么,都会被归一化成均值为 β,标准差为 γ 的分布。
注意:BN 层不会改变输入数据的维度,只改变输入数据的的分布. 在实际使用过程中,BN 常常和卷积神经网络结合使用,卷积层的输出结果后接 BN 层。
2. BN 层的接口¶
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True)
由于每次使用的 mini batch 的数据集,所以 BN 使用移动加权平均来近似计算均值和方差,而 momentum 参数则调节移动加权平均值的计算;
affine = False 表示 γ=1,β=0,反之,则表示 γ 和 β 要进行学习;
BatchNorm2d 适用于输入的数据为 4D,输入数据的形状 [N,C,H,W]
其中:N 表示批次,C 代表通道数,H 代表高度,W 代表宽度
由于每次输入到网络中的是小批量的样本,我们使用指数加权平均来近似表示整体的样本的均值和方法,其更新公式如下:
running_mean = momentum * running_mean + (1.0 – momentum) * batch_mean
running_var = momentum * running_var + (1.0 – momentum) * batch_var
上面的式子中,batch_mean 和 batch_var 表示当前批次的均值和方差。而 running_mean 和 running_var 是近似的整体的均值和方差的表示。当我们进行评估时,可以使用该均值和方差对输入数据进行归一化。
3. 小节¶
本小节学习了批量归一化层,该层的作用主要是用来控制每层数据的流动时的均值和方差,防止训练过程出现剧烈的波动,模型难以收敛,或者收敛较慢。批量归一化层在计算机视觉领域使用较多。
9 案例-价格分类¶
学习目标¶
掌握构建分类模型流程
小明创办了一家手机公司,他不知道如何估算手机产品的价格。为了解决这个问题,他收集了多家公司的手机销售数据。
我们需要帮助小明找出手机的功能(例如:RAM等)与其售价之间的某种关系。我们可以使用机器学习的方法来解决这个问题,也可以构建一个全连接的网络。
需要注意的是: 在这个问题中,我们不需要预测实际价格,而是一个价格范围,它的范围使用 0、1、2、3 来表示,所以该问题也是一个分类问题。
1. 构建数据集¶
数据共有 2000 条, 其中 1600 条数据作为训练集, 400 条数据用作测试集。 我们使用 sklearn 的数据集划分工作来完成。并使用 PyTorch 的 TensorDataset 来将数据集构建为 Dataset 对象,方便构造数据集加载对象。
# 构建数据集
def create_dataset():
data = pd.read_csv('data/手机价格预测.csv')
# 特征值和目标值
x, y = data.iloc[:, :-1], data.iloc[:, -1]
x = x.astype(np.float32)
y = y.astype(np.int64)
# 数据集划分
x_train, x_valid, y_train, y_valid = \
train_test_split(x, y, train_size=0.8, random_state=88, stratify=y)
# 构建数据集
train_dataset = TensorDataset(torch.from_numpy(x_train.values), torch.tensor(y_train.values))
valid_dataset = TensorDataset(torch.from_numpy(x_valid.values), torch.tensor(y_valid.values))
return train_dataset, valid_dataset, x_train.shape[1], len(np.unique(y))
train_dataset, valid_dataset, input_dim, class_num = create_dataset()
train_test_split是 scikit-learn 库中用于将数据集分割为训练集和测试集的函数。下面我将详细解释你提到的每个参数的含义:- x: 这是输入特征的数组或矩阵。通常,
x包含你想要用于训练模型的所有特征数据。 - y: 这是目标变量的数组。
y包含与x中的每个样本相对应的标签或目标值。 - train_size: 这个参数指定训练集的比例。在这个例子中,
train_size=0.8意味着 80% 的数据将被用作训练集,剩下的 20% 将用作测试集。 - random_state: 这个参数用于设置随机数生成器的种子,确保每次运行代码时分割的结果都是一致的。在这个例子中,
random_state=88意味着使用种子 88 来初始化随机数生成器。 - stratify: 这个参数用于分层抽样。在这个例子中,
stratify=y意味着训练集和测试集中的目标变量y的类别分布将与原始数据集中的类别分布保持一致。这对于确保训练集和测试集具有相似的类别比例非常有用,特别是在处理不平衡数据集时。
2. 构建分类网络模型¶
我们构建的用于手机价格分类的模型叫做全连接神经网络。它主要由三个线性层来构建,在每个线性层后,我们使用的时 sigmoid 激活函数。
# 构建网络模型
class PhonePriceModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(PhonePriceModel, self).__init__()
self.linear1 = nn.Linear(input_dim, 128)
self.linear2 = nn.Linear(128, 256)
self.linear3 = nn.Linear(256, output_dim)
def _activation(self, x):
return torch.sigmoid(x)
def forward(self, x):
x = self._activation(self.linear1(x))
x = self._activation(self.linear2(x))
output = self.linear3(x)
return output
第一层: 输入为维度为 20, 输出维度为: 128
第二层: 输入为维度为 128, 输出维度为: 256
第三层: 输入为维度为 256, 输出维度为: 4
我们使用 sigmoid 激活函数.
3. 编写训练函数¶
网络编写完成之后,我们需要编写训练函数。所谓的训练函数,指的是输入数据读取、送入网络、计算损失、更新参数的流程,该流程较为固定。我们使用的是多分类交叉生损失函数、使用 SGD 优化方法。最终,将训练好的模型持久化到磁盘中。
def train():
# 固定随机数种子
torch.manual_seed(0)
# 初始化模型
model = PhonePriceModel(input_dim, class_num)
# 损失函数
criterion = nn.CrossEntropyLoss()
# 优化方法
optimizer = optim.SGD(model.parameters(), lr=1e-3)
# 训练轮数
num_epoch = 50
for epoch_idx in range(num_epoch):
# 初始化数据加载器
dataloader = DataLoader(train_dataset, shuffle=True, batch_size=8)
# 训练时间
start = time.time()
# 计算损失
total_loss = 0.0
total_num = 1
# 准确率
correct = 0
for x, y in dataloader:
output = model(x)
# 计算损失
loss = criterion(output, y)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
total_num += len(y)
total_loss += loss.item() * len(y)
print('epoch: %4s loss: %.2f, time: %.2fs' %
(epoch_idx + 1, total_loss / total_num, time.time() - start))
# 模型保存
torch.save(model.state_dict(), 'model/phone-price-model.bin')
4. 编写评估函数¶
评估函数、也叫预测函数、推理函数,主要使用训练好的模型,对未知的样本的进行预测的过程。我们这里使用前面单独划分出来的测试集来进行评估。
def test():
# 加载模型
model = PhonePriceModel(input_dim, class_num)
model.load_state_dict(torch.load('model/phone-price-model.bin'))
# 构建加载器
dataloader = DataLoader(valid_dataset, batch_size=8, shuffle=False)
# 评估测试集
correct = 0
for x, y in dataloader:
output = model(x)
y_pred = torch.argmax(output, dim=1)
correct += (y_pred == y).sum()
print('Acc: %.5f' % (correct.item() / len(valid_dataset)))
程序输出结果:
Acc: 0.54750
5. 网络性能调优¶
我们前面的网络模型在测试集的准确率为: 0.54750, 我们可以通过以下方面进行调优:
对输入数据进行标准化
调整优化方法
调整学习率
增加批量归一化层
增加网络层数、神经元个数
增加训练轮数
等等...
我进行下如下调整:
- 优化方法由 SGD 调整为 Adam
- 学习率由 1e-3 调整为 1e-4
- 对数据数据进行标准化
- 增加网络深度, 即: 增加网络参数量
网络模型在测试集的准确率由 0.5475 上升到 0.9625,调整后的完整代码为:
import torch
import torch.nn as nn
import torch.nn.functional as F
import pandas as pd
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
import torch.optim as optim
import numpy as np
import time
from sklearn.preprocessing import StandardScaler
# 构建数据集
def create_dataset():
data = pd.read_csv('data/手机价格预测.csv')
# 特征值和目标值
x, y = data.iloc[:, :-1], data.iloc[:, -1]
x = x.astype(np.float32)
y = y.astype(np.int64)
# 数据集划分
x_train, x_valid, y_train, y_valid = \
train_test_split(x, y, train_size=0.8, random_state=88, stratify=y)
# 数据标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_valid = transfer.transform(x_valid)
# 构建数据集
train_dataset = TensorDataset(torch.from_numpy(x_train), torch.tensor(y_train.values))
valid_dataset = TensorDataset(torch.from_numpy(x_valid), torch.tensor(y_valid.values))
return train_dataset, valid_dataset, x_train.shape[1], len(np.unique(y))
train_dataset, valid_dataset, input_dim, class_num = create_dataset()
# 构建网络模型
class PhonePriceModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(PhonePriceModel, self).__init__()
self.linear1 = nn.Linear(input_dim, 128)
self.linear2 = nn.Linear(128, 256)
self.linear3 = nn.Linear(256, 512)
self.linear4 = nn.Linear(512, 128)
self.linear5 = nn.Linear(128, output_dim)
def _activation(self, x):
return torch.sigmoid(x)
def forward(self, x):
x = self._activation(self.linear1(x))
x = self._activation(self.linear2(x))
x = self._activation(self.linear3(x))
x = self._activation(self.linear4(x))
output = self.linear5(x)
return output
# 编写训练函数
def train():
# 固定随机数种子
torch.manual_seed(0)
# 初始化模型
model = PhonePriceModel(input_dim, class_num)
# 损失函数
criterion = nn.CrossEntropyLoss()
# 优化方法
optimizer = optim.Adam(model.parameters(), lr=1e-4)
# 训练轮数
num_epoch = 50
for epoch_idx in range(num_epoch):
# 初始化数据加载器
dataloader = DataLoader(train_dataset, shuffle=True, batch_size=8)
# 训练时间
start = time.time()
# 计算损失
total_loss = 0.0
total_num = 1
# 准确率
correct = 0
for x, y in dataloader:
output = model(x)
# 计算损失
loss = criterion(output, y)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
total_num += len(y)
total_loss += loss.item() * len(y)
print('epoch: %4s loss: %.2f, time: %.2fs' %
(epoch_idx + 1, total_loss / total_num, time.time() - start))
# 模型保存
torch.save(model.state_dict(), 'model/phone-price-model.bin')
def test():
# 加载模型
model = PhonePriceModel(input_dim, class_num)
model.load_state_dict(torch.load('model/phone-price-model.bin'))
# 构建加载器
dataloader = DataLoader(valid_dataset, batch_size=8, shuffle=False)
# 评估测试集
correct = 0
for x, y in dataloader:
output = model(x)
y_pred = torch.argmax(output, dim=1)
correct += (y_pred == y).sum()
print('Acc: %.5f' % (correct.item() / len(valid_dataset)))
if __name__ == '__main__':
train()
test()
学员问题
-
1: 安装pip 包, 指定阿里云的镜像
- pip install -i https://mirrors.aliyun.com/pypi/simple torch
-
2: 计算机中的随机数都是伪随机数
- 需要设定随机种子.
-
3: 张量运算
- data.add()
- dada.sub()
- data.mul()
- data.div()
- data.neg()
- 都是矩阵中的每一个元素都要做对应的计算.
-
4: 阿达母积 & 点积 (矩阵乘法)
-
data1 = [[1, 2] [3, 4]] data2 = [[5, 6] [7, 8]] data = torch.mul(data1, data2) 等效于 data = data1 * data2 print(data) [[5, 12] [21, 32]] ---------------------------- [[19, 22] [43, 50]] -
矩阵的广播机制
-
torch.matmul(torch.randn(3, 4, 5), torch.randn(5, 4)).shape 广播之前: [3,4,5] --- [5,4] 广播之后: [3,4,5] --- [3,5,4] 矩阵乘法: [3,4,4] [5,4] --- [3,4,5] [3,5,4] --- [3,4,5] [3,5,5] -
torch.cuda.is_available() 判断服务器, 电脑是否支持cuda (GPU)
-
问题1: numpy的数据类型 + Pytorch的数据类型?
- Numpy: ndarray
- Pytorch: Tensor
-
问题2: 关于计算机领域的copy分成两种的问题?
- 深拷贝: copy(), deepcopy()
- 不指向同一块内存
- 浅拷贝: 内存共享
- x = y
- 本质上指向同一块内存
- 真名, 小名, 外号 = 指向同一个人
- 深拷贝: copy(), deepcopy()
-
问题3: 关于item()函数的用法?
- Data.item()只有1个元素的时候可以把标量提取出来
- 如果data里面有>=2个元素, 不能使用item()函数
- RuntimeError: a Tensor with 2 elements cannot be converted to Scalar
-
问题4: 两个关键命令?
- Numpy --->>> torch: data = torch.from_numpy(data)
- Torch --->>> numpy: data = data.numpy()
- 两个都是浅拷贝
-
问题5: 关于张量拼接的两个函数的区别?
-
Torch.cat() --- 拼接的时候, 不改变原始张量的维度. 3 -> 3
-
Torch.stack() --- 拼接的时候, 改变原始张量的维度. 2 -> 3 (相当于新创建一个维度出来)
-
这样叠加是为了啥? (姜同学👏🏻)
- ✅ 未来我们构建神经网络的时候, 经常会对网络进行拼接, 垒积木一样. 才需要这种命令.
-
如果张量的维度不一样怎么办? 能吗? (仙人掌🌵)
- RuntimeError: stack expects each tensor to be equal size, but got [2, 3] at entry 0 and [2, 3, 4]
- 强烈鼓励小伙们自己实验就全懂了.
-
刚才说的torch.cat张量维度不变不太明白,像new_data = torch.cat([data1, data2], dim = 0)new_data的维度不是从原来的3维变成了6维了吗?不太理解这里 (北冥有鱼🐟)
- [3, 5, 4] --->>> [6, 5, 4] 这种不叫维度发生变化, 只是里面具体数值变了
- [3, 5, 4] = 定义成维度等于3的张量
- [3, 5] = 定义成维度等于2的张量
- 维度变化, 是指3维变2维, 或者2维变4维
-
有点晕 标量能stack吗? (韭菜王🍊)
-
# 下面是可以的, 理解成1行1列的数据 x = torch.Tensor([1]) y = torch.Tensor([2]) z = torch.stack([x, y],dim=0) # 下面是错误❌的 x = torch.Tensor(1) y = torch.Tensor(2) z = torch.stack([x, y],dim=0)
-
-
-
问题6: 关于transpose()函数和permute()函数?
- Transpose()函数: 一次交换两个维度 torch.transpose(data, x, y) --- x, y 就是要交换的两个维度的下标
- 李辉 (👏🏻)
- Transpose()函数每次只能接收两个维度的变化
- TypeError: transpose() received an invalid combination of arguments - got (Tensor, int, int, int), but expected one of:
- (Tensor input, int dim0, int dim1)
- 推理出: 类似于[0, 1, 2] --->>> [2, 0, 1] 的变换, 需要执行2次transpose()操作
- Permutte()函数: 一次交换多个维度 torch.permute(data, [2, 0, 1])
- [3, 4, 5] --->>> [5, 3, 4]
- 3: 交换前维度 = 0, 交换后3变到第1个维度上, 只需要把下标0放在第1个维度上
- 5: 交换前维度 = 2, 交换后5变到第0个维度上, 只需要把下标2放在第0个维度上
- 4: 交换前维度 = 1, 交换后4变到第2个维度上, 只需要把下标1放在第2个维度上
- 老师有时候reshape和transpose可以实现相同的功能吗? (仙人掌🌵)
- 很深刻!!!!!!!
- 本质上reshape()函数不破坏内存的连续性, transpose()函数破坏了内存的连续性
- 怎么让内存连续呢?
- ⭕️new_data = data.contiguous().view()就可以了!!!
- Transpose()函数: 一次交换两个维度 torch.transpose(data, x, y) --- x, y 就是要交换的两个维度的下标
-
问题7: 那view比reshape速度快吗? (豪 --- 👏🏻)
- 鼓励全班小伙伴课下实验 + 查资料, 交作业 🍊🍊🍊🍌🍌🍌
-
问题1: 当前深度学习的三大框架?
- Google: Tensorflow --- 2014
- Facebook: Pytorch --- 2016
- Baidu: PaddlePaddle --- 2020
-
问题2: 关于函数的求导?
- y = x^2 + 20
- y' = 2x
- y = x^2 + 20 (因为有4个值)
- y.mean() 等效于 y/4
- y' = ((x^2 + 20) / 4)' = ((1/4) x^2 + 20)' = 1/2 * x
- 重点⭕️: 使用Pytorch框架进行反向传播求导的时候, 求导对象一定是一个标量!!!
- y = 3.888 ✅
- Vector = [1.2, 3.5, 4.4, 8.1] ❌
-
问题3: 我这个可以啊f1.backward(torch.ones_like(f1)) 直接求导??? (韭菜王📚)
-
torch.ones_like(f1)不是张量么??? (.同学)
-
相当于标量之上, 继续求标量的导数.
-
和我前面说的标量求导不是一回事.
-
tensor([1., 1., 1., 1.], dtype=torch.float64) tensor([ 120., 420., 920., 1620.], dtype=torch.float64, grad_fn=<AddBackward0>) 秘密就是 120 --- 1 420 --- 1 920 --- 1 1620 --- 1
-
-
问题4: 关于梯度求导x.grad的累加性质?
- 如果在代码中不对梯度清零: x.grad.data.zero_()
- 每一轮梯度会累加在x.grad这个属性上.
- ✅如果我连续运行了100轮代码, 相当于x.grad属性累加了100次梯度值!!!
-
问题5: 关于模型的保存方法?
- 方法一: 保存模型的状态字典
- torch.save(model.state_dict(), 'model_weights.pth')
- 方法二: 保存完整的模型
- torch.save(model, 'model_full.pth')
- 方法一: 保存模型的状态字典
-
问题6: 老师训练和加载时GPU型号不一样 device那里不存在什么兼容问题吧? (一片花飞🌺, AI老司机的问题)
- 1: 一般来说, 只要你的cuda版本不变, 不同的GPU训练后的模型, 换一组GPU推理没有问题!!!
- 4块3090训练 --- 2块4090推理, cuda版本不变, 没问题. ✅
- 2: 虽然你的cuda版本不变, 大模型有很多训练技巧, 混合精度训练, 有问题!!!
- 8块H100混合精度训练 --- 2块A100推理, cuda一样, 照样有问题!!! ❌
- H100: 支持int8加速
- A100: 不支持int8加速
- 8块H100混合精度训练 --- 2块A100推理, cuda一样, 照样有问题!!! ❌
- 3: 有的情况, 即使你的cuda版本不同, GPU也不一样, 推理照样没问题!!! ✅
- 4: GPU训练模型, 不管用的什么型号, 放在CPU推理, 绝大多数情况都OK!!! ✅
- CPU推理很友好!!! 在2023年之前深受AI小伙伴和公司的欢迎......
- 2023年大模型时代后, 大家放弃了......
- 1: 一般来说, 只要你的cuda版本不变, 不同的GPU训练后的模型, 换一组GPU推理没有问题!!!
-
问题7: 关于理解AI, ML, DL的关系?
- AI是最大的一个概念
- ML: 是AI的一个子集
- 1990 - 2012: 大学里, 读研, 做AI门槛是很高的!!!
- 本科生很难触达!!!
- 硕士为辅, 博士为主!!!
- 1990 - 2012: 大学里, 读研, 做AI门槛是很高的!!!
- Deep Learning: 使用了神经网络技术的ML就是深度学习!!!
- 2012 - 2022: 门槛大大降低了
- 本科生可以触达了!!!
- 硕士成了主力.
- 博士一般都是研究员!!!
- 没有特征向量了??? (贤之)
- 不是没有特征向量, 而是不需要人类算了!!!
- 神经网络模型自动搞定了
- 即使在2024年, 推荐系统领域, 依然需要工程师来做特征工程!!!
- 只是在CV, NLP, MM领域, 越来越不愿意做特征工程了!!!
-
问题8: 关于人工神经网络的几个原则规定?
- 1: 同一层的神经元不能互相连接!!!
- 2: 下一层的神经元, 决不能向它之前的层进行连接!!!
- 3: 未来看各种各样的神经网络图, 每一个圆圈⭕️是一个神经元, 可以理解成一个浮点数; 所以带箭头的连边上都有权重值w1
- 老师 那这里面一定要全部链接上吗? 能不能只连一部分? (一片花飞🌺)
- 不需要!!!
- 刻意只连一部分, 但是需要特殊操作!!!
- nn.Linear(N, M) 定义的隐藏层, 就是全连接层, 全部连接上了!!!
- 不能跳着连吧? (渡 同学)
- 能!!!
- 未来你会看到一种技术叫"残差连接", 或者"跳跃连接"
-
问题9: 2012是深度学习发展的一个转折点?
- AlexNet: 本质上加州伯克利一个博士生Alex.
- Key: 激活函数换成了ReLU()函数......直接效果爆表!!!
- 实在毕不了也了, 病急乱投医, 一轮操作猛如虎, 最后一战成名!!!
- Alex就是当初Hinton大神的博士生!!!
- Hinton大神刚刚因为对人工智能的卓越贡献获得图灵奖!!!
- 1989年, Hinton大神发表反向传播算法!!! ⭕️✅
- 从1989 - 2012年, 一直很沉寂, 没人认识到BP算法的重要性......一直到2012重出江湖, 大家才看清楚BP的划时代的意义!!!
- 美国科学院院士: 一件事只有大家都知道了它的重要性, 他的重要性才体现出来!!!
- ⭕️整个AI时代最重要的算法---反向传播算法!!!⭕️
- 1: 没有英伟达的GPU
- 2: 没想起来激活函数的事
- AlexNet: 本质上加州伯克利一个博士生Alex.
-
问题10: 关于ReLU()激活函数?
- 不是完美的
- Leaky-ReLU()函数
- 各种ReLU()函数的变体.
- PReLU、 RReLU、ELU、SELU、GELU 这些变体都可以去看看 (顾曼桢 - 金同学)
-
问题11: 为什么要用这一套复杂的梯度下降来求解? 为什么不直接解方程?
- (王晨欢) 微分方程很难解吧
- 1: 原因大型的, 复杂的神经网络, 本质上是一个"非凸优化问题"!!!
- 2: 数学上, 非凸优化是没有解析解的!!!
- y = x ^2 + 5
- 解析解: 直接按照公式算!!!
- 高次方程是没有办法得到解析解 --- 梯度下降求解.
- ⭕️反向传播 + 梯度下降, 能不能得到最优解???
- 不能!!!
- ChatGPT, 百度文心一言 --- 别看着很厉害, 背后都不是最优解, 得到次优解!!!
- w_new = w_old - learning_rate * grad
- 0.9999 = 1.0 - 0.01 * 0.01
- 0.9997 = 0.9999 - 0.01 * 0.02
-
问题12: 关于反向传播算法的理解程度?
- 2015 ~ 2020期间: 面试必考题!!!
- 2021 ~ 2024期间: 根本没人问了!!!
- 默认你已经会了
- loss.backward()
- 工作中根本用不上!!!
- ⭕️建议: 数学基础好的同学, 回去深刻的看看, 用MSE, softmax推到一轮.
- 数学底子一般的, 理解思想就好......
- 面试手撕transformer的相关代码!!!
- 25K以上的offer, 考的频率很高.
-
Homework_01 + homework_02统一提交邮箱📮.......
- Homework_02: Pytoch模块剩余部分 + 深度学习模块前4章
- 鼓励你手推一下反向传播算法: MSE, softmax, 拍照提交
- 348811083@qq.com
- 邮件名: 名字 (网名)
- Homework_02: Pytoch模块剩余部分 + 深度学习模块前4章
-
问题1: 关于作业提交的格式问题?
- 打包, .zip格式✅, .rar打不开❌
- md文件, txt, jupyter都是OK的✅
-
问题2: 关于课程全过程的考核?
- 开卷考试 + 1对1模拟面试 (腾讯会议) ......
- 2次开卷考试 + 2次模拟面试 ......
- 参加考核前提: 正常提交合格的80%以上的作业. (作业得合格, 不能凑数)
-
问题3: 1e-6等于多少? (赶紧复习)
- 10的-6次方
- 1e-10 = 0.0000000001
-
问题4: 老师 也就是学习率 也是能自我学习迭代吗?
- 当然啦!!!
- AdaGrad
- Adam
-
问题5: 那这种不是一辈子都找不到梯度等于0吗? (韭菜王 📚 👏🏻)
- 如果一直找不到grad = 0, 不就永远找不到局部最优解??? 找不到最小值???
- ⭕️深度学习中的最优解: 从来不是靠梯度=0得到的!!!
- 比如loss达到一定标准
- 比如准确率达到一定标准
- 都是其他指标OK了, 训练结束了!!!
- ROC, precision, recall, accuracy, F1
-
问题6: 关于优化方法的学习?
- 重点理解一下Momentum的理论
- 理解一下AdaGrad, RMSProp的计算学习率的方法
- ⭕️主要都在用Adam优化器!!!
- Adam = Adaptive + momentum
- 动量方法 + 自适应学习率
- 相当于梯度在变化 + 学习率在变化
-
问题7: 正则化方法有哪些?
- L1
- L2
- Dropout
- 为什么要降低网络的复杂度呢???
- 神经网络功能太强大了!!!
- 需要用dropout让神经网络不那么厉害, 稍微笨一点好!!! ✅
- (李辉, 艾瑾行 --- 什么是拟合呢???)
- 所有没学导学课机器学习模块的, 一定抽时间补上!!!
- 不是里面的算法重要, 而是建立思想重要!!!
- 拟合, 过拟合
- 训练集, 测试集, 验证集
- 训练集: 中学课堂上老师的例题 + 课后作业, 必须有
- 测试集: 期末考试, 中考, 高考, 必须有
- 验证集: 可以有, 也可以没有
- 泛化能力才是模型训练的一个重要指标!!! ✅
- 而不是在训练集上表现多么完美!!! ❌
- 意思是能举一反三才是牛逼, 而不是照本宣科? (仙人掌🌵)
-
问题8: torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True)
- 不用过于纠结, 未来写代码跑模型多了, 自然就熟悉了
- Affine: 数学上的仿射变换......affine=True, 表示有参数需要学习!!!
- BatchNorm2d: 核心作用就是归一化, 防止不同批次的数据分布剧烈变化, 对模型参数的更新也剧烈变化, 不利于模型的训练和收敛!!!
- 不用过于纠结, 未来写代码跑模型多了, 自然就熟悉了
-
问题9: 称为Ai算法工程师, AI研发, AI应用开发工程师后, 你的工作时间如何划分?
- 算法+模型: 30(🥰) --- 10(😖)
- 数据处理+清洗: 30 --- 50 提高重视
- 字节, 百度 --- 40%左右!!! (小朱)
- 2017年以前 --- 大厂会有专门数据组 (中型公司也有, 小公司)
- 2018年以后, 数据部门收缩, 砍了
- 产品狗PK: 20 --- 30
- 产品狗是什么?
- 产品经理
- 领导做PPT: 20 --- 40
- 不是还有个项目经理的角色吗???
- 项目狗 --- 程序员👨🏻💻的敌人
-
问题10: 关于神经网络的构建?
- self.linear1 = nn.Linear(10, 128) --- 左侧10个神经元, 右侧128个神经元
- 总共1280条连边
- 总共1280个权重值
- 总共1280个参数
- 总共1280个浮点数float32, float64
- self.linear2 = nn.Linear(128, 256)
- 注意📢: 下一层神经元的个数, 一定要和上一层的神经元个数匹配!!!
- 关于函数def forward(self, x):
- 前向传播的逻辑一定要程序员自己实现!!!
- self.linear1 = nn.Linear(10, 128) --- 左侧10个神经元, 右侧128个神经元
-
问题11: 关于模型训练?
- 1: 固定的3个步骤
- 1.1: 实例化模型model = nn.Module()类对象
- 1.2: 选定损失函数 nn.CrossEntropyLoss()
- 1.3: 选定优化器 nn.optim.SGD(), nn.optim.Adam()
- 2: 训练阶段
- 2.1: 经典的双重循环
- For epoch in range(num_epochs):
- 2.2: 内层for循环中的"老三样"
-
- 梯度清零: optimizer.zero_grad()
-
- 反向传播: loss.backward()
- 参数更新: optimizer.step()
-
- 2.1: 经典的双重循环
- 1: 固定的3个步骤
-
问题12: 为什么深度学习中,在第一层比如设置10个神经元,第二层的网络的神经元个数可以随便设置来着了?刚才是不是讲过?(北冥有鱼🐟)
- 每一层神经元的个数, 都是程序员自主确定!!!
- 未来主要靠经验值 + 调参侠!!!
- 所有层的激活函数都要一样吗? (根)
- 不需要!!!
-
问题13: 损失函数该怎么选择 包括优化器 激活函数之类的 只能纯靠经验吗 能不能挨个排列组合一遍 试试哪个效果好?(一片花飞🌺)
- ⭕️经验 + 套路!!!
- 绝不是挨个试一遍!!!
- 相信同学们10月份的时候, 你面对不同问题选择上面这一套 --- 轻车熟路的!!!
- 成为炼丹大师!!!
- 就是来和小朱老师学经验的 (王晨欢)
- 为什么不挨个实验?
- 有经验的时候, 实验前就知道不靠谱!!!
- 谷歌训练大模型时候经常暴力解法, 但是暴力不是随便暴力
- 该实验的参数去实验
- 不该实验的参数直接选定!!!
- 同学们真的成为了炼丹大师 + 调参大师 --- 40w ~ 50w随便挑!!!
- 大模型时代, 很多东西真的是经验!!!
-
作业: 回去对案例进行调优, 点评效果TOP3小伙伴......
-
回去之后, 各种实验 + 各种调参侠.....
- Acc: 0.96250. 课件上的表现, 同学们必须>= 0.9625
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号