
软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践¦S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 阅读《构建之法》并提出问题、使用GitHub提交项目、完成WordCount程序并测试 |
| 作业正文 | 正文 |
| 其他参考文献 | 博客园、CSDN、简书、百度百科 |
part1:阅读《构建之法》并提问
问题1
在书中61页,作者用魔方的例子讲诉了“精通”二字的含义。
但我们真的有必要精通一门编程语言吗,以下摘自知乎平台的一份回答。
精通一门语言的最直接方法是研究和解析目标语言的编译原则。想精通太难,而且作为一个大学毕业的学生,执着于精通一门语言其实意义并不是很大。
在我过去三年的学习中,不要说精通,就连掌握一门语言的标准都没有达到。拿java来说,作为这次博客作业的编程语言,我花了不少时间去重新学习了map,hashmap,treemap三种数据结构对应的方法,以及他们之间的关系。而精通java不仅要了解底层实现,还要有广阔的技术视野,想必要花很多时间精力去学习。
我认为不必追求精通一门编程语言,但要不断扩展自己的“学习区”,强化基础知识,打牢基础。
问题2
在书中93页,作者主张在最外层,即行为和后果层给与他人反馈。作者的理由是前两层反馈难以改变,而最外层的行为和后果是可以被改正和弥补的。
此外,作者也提到三明治式的反馈是容易被人接受的。
但我认为这种方式有时不足以引起他人的重视。虽然三明治式的反馈确实让人容易接受,但也容易让别人不以为然,认为他犯的的错误只是小问题,拿过去的一次合作经历说,有些队员喜欢“划水”,队长不断地催促他们完成自己的任务,最后上交的成果并不好。如果给与他人的反馈,大多都在评论别人三种层次中的行为后果层,他或许只是这一次改正,但再次出现问题时,他还是会重蹈覆辙,所以我会考虑进一步在行为动机层上告诉他问题所在,这样会不会取得更好的效果呢?
问题3
在看第八章需求分析的时候,我突然萌生了一个问题,这里的需求与软件的发展有冲突怎么办?
例如手机上有一个夸克浏览器,过去我因为其简洁的界面一直把它当作手机浏览器的首选,但是在以后的更新中,夸克浏览器不但内置了语音助手,云存储,甚至有了它自己的ui。当然,浏览器多功能化是它的发展趋势,但与此同时也会与用户需求相矛盾。在视频网站bilibili上我也多次看到,许多up主吐槽夸克浏览器“忘记初心”,而且卸载了该浏览器。如果说软件的发展会影响对该软件的需求,那我们应该怎样平衡这种冲突呢?
问题4
26页讲述了单元测试的一些标准,好的单元测试在覆盖率,或是一些边缘,异常情况下,都要有好的表现。正如书中所说,代码覆盖率100%也不等同于100%正确。
但单元测试可否帮助提高程序的性能呢?还是说单元测试仅仅是用于验证正确性?
单元测试中有时间工具,可判断程序运行时间,有时我也会借此来估计程序的运行速度是否达到预期,而且在单元测试中,一些问题可能是由于数据结构不合理引发的,这时可以通过优化数据结构,在提高正确性的同时也提高了程序性能。
问题5
在49页,作者提到了软件工程师成长的第一点,是积累软件开发相关的知识,提升技术技能。其中包括一些编程语言,设备驱动程序,内核调试器的掌握以及对某一开发平台的掌握。
但是经过了大学三年,我发现自己好像学的太少了。对设备驱动程序和开发平台没有过多的了解,太久没用的编程语言也会忘记一些知识。所以我对于第一阶段的学习还远没有结束,我也不清楚自己要掌握了哪些具体技术之后,才算完成了初级软件工程师的第一阶段,以及我需要花费大概多少时间来学习这些技能。毕竟大四面临毕业,怎样在有限的时间内让自己在软件工程的领域内掌握足够的知识?
附加题
蓝牙的名字来源于10世纪丹麦国王Harald Blatand——英译为Harold Bluetooth(因为他十分喜欢吃蓝梅,所以牙齿每天都带着蓝色)。在行业协会筹备阶段,需要一个极具有表现力的名字来命名这项高新技术。行业组织人员,在经过一夜关于欧洲历史和未来无限技术发展的讨论后,有些人认为用Blatand国王的名字命名再合适不过了。Blatand国王将现在的挪威,瑞典和丹麦统一起来;他的口齿伶俐,善于交际,就如同这项即将面世的技术,技术将被定义为允许不同工业领域之间的协调工作,保持着个各系统领域之间的良好交流,例如计算,手机和汽车行业之间的工作。名字于是就这么定下来了。
part2:WordCount编程
Github项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时 | 实际耗时 |
|---|---|---|---|
| Planning | 计划 | 1h | 0.5h |
| • Estimate | • 估计这个任务需要多少时间 | 1h | 0.5h |
| Development | 开发 | 8h | 8h |
| • Analysis | • 需求分析 (包括学习新技术) | 3h | 2h |
| • Design Spec | • 生成设计文档 | 15min | 15min |
| • Design Review | • 设计复审 | 30min | 1h |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30min | 30min |
| • Design | • 具体设计 | 1h | 2h |
| • Coding | • 具体编码 | 4h | 4.5h |
| • Code Review | • 代码复审 | 30min | 15min |
| • Test | • 测试(自我测试,修改代码,提交修改) | 1h | 1.5h |
| Reporting | 报告 | 3h | 4h |
| • Test Repor | • 测试报告 | 15min | 15min |
| • Size Measurement | • 计算工作量 | 0.5h | 15min |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 0.5h | 0.5h |
| 合计 | 25h | 26h |
解题思路
- 输入方式:命令行
- 输入内容:两个文本的路径(相对路径或绝对路径),其中,前一个文本为待读取文本,后一个文本为待输出文本
- 输出内容:待输出文本中的内容,包括:
- 统计字符数
- 统计单词数
- 统计有效行数
- 统计最多的10个单词及其词频
首先我先不考虑用命令行的输入方式,而是手动输入两个文件的路径。输入文件路径后,下一步要读取文本并对文本进行分析统计,读取文本不难,可创建一个用于打开文件并分析文件的类,在该类中写一些静态的方法(实践中发现创建静态方法并不是最优选择)。下面对4种统计要求进行分析:
- 统计字符数:可在打开文件读取内容时顺带执行
- 统计单词数:使用正则表达式匹配(实践中发现效率不高。已舍弃)
- 统计有效行数:使用正则表达式匹配(实践中发现效率不高。已舍弃)
- 统计最多的10个单词及其词频:利用统计单词数时的数据进行排序
最后将统计结果按照规定格式写进输出文本即可。
代码规范制定链接
设计与实现过程
类
- Wordcount
用于获取命令行的文本路径,主函数的运行以及调用Lib类。 - Lib
用于读写文本并对文本内容进行分析统计。
Lib类中的函数
- readFileByChars() —— 打开文件并统计字符数,单词数,有效行数,并保存单词及其频率
利用FileReader逐个读入字符并统计字符数
fr = new FileReader(inputFilePath);
int ch;
while ((ch = fr.read()) != -1) {
charsNumber++;
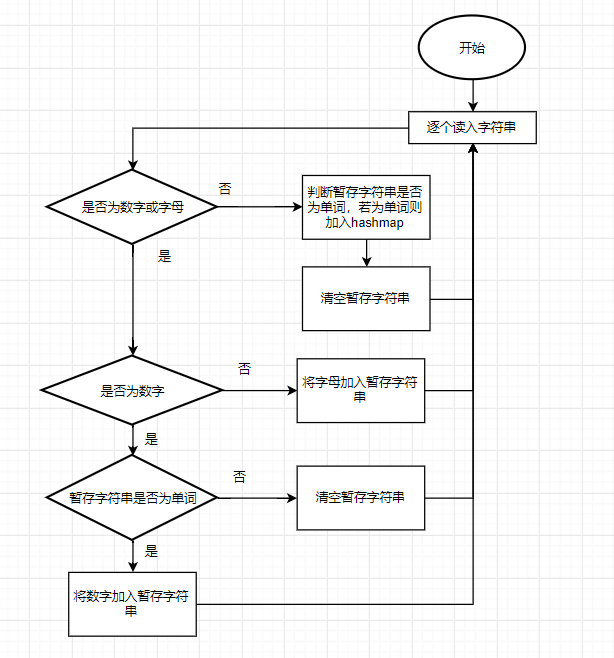
由于单词至少有4个字母开头,且之后可跟数字,所以可理解为单词的开头是4个字母,单词是由于非字母数字结束的(单词不会因为数字而结束,因为小于4个字母开头构不成单词),基于此设计算法。
单词的判断算法:
- 设定一个暂存字符串,规定暂存字符串只有三种类型:为空,由1~3个字母组成,为一个单词。(判断暂存字符串是否为单词的方法:长度是否大于三)
- 不断读入字符,判断该字符的类型。
- 字符类型为字母,加入暂存字符串。
- 字符类型为非字母非数字,清空暂存字符串,判断暂存字符串是否为单词,若是则记录。
- 字符类型为数字,判断暂存字符串是否为单词,若不是则清空暂存字符串,若是则加入暂存字符串。
- 读入字符结束,判断暂存字符串是否为单词,若是则记录。
添加单词进hashmap(需判断其是否存在)
if (tempWord.length() > 3) {
//若没有则添加,若有则加一
word = tempWord.toString().toLowerCase();
wordsCount.merge(word, 1, Integer::sum);
由于换行一定有一个回车键,只需判断在两个回车键之间是否出现过非空字符,基于此设计算法。
有效行的判断算法:
- 设定一个布尔数a为假,代表该行没有非空字符。
- 不断读入字符,判断该字符的类型。
- 若字符不为回车,也不为空白字符,且该行没有非空字符,则将a置为真。
- 若字符为回车,判断该行有无非空字符,若有则有效行加一,不管结果如何a都置为假。
- 读入字符结束,判断该行有无非空字符,若有则有效行加一。
if (ch == 10) {
if (isValued) {
lineNumber++;
}
isValued = false;
} else {
if (!isValued && !isBlankCharFuc(ch)) {
isValued = true;
}
}
- countWords() —— 对单词按照频率进行排序
利用stream可以同时实现:
- 按频率排序
- 再按key值大小排序
- 截取前十个元素
wordsCount = getWordsCount()
.entrySet()
.stream()
.sorted(Map.Entry
.<String, Integer>comparingByValue()
.reversed()
.thenComparing(Map.Entry.comparingByKey()))
.limit(10)
.collect(Collectors
.toMap(Map.Entry::getKey
, Map.Entry::getValue
, (e1, e2) -> e2
, LinkedHashMap::new));
- writeFile() —— 写入文件
遍历hashmap
for (Map.Entry<String, Integer> entry : wordsCount.entrySet()) {
outputString.append(entry.getKey())
.append(": ")
.append(entry.getValue())
.append('\n');
}
利用BufferedOutputStream写入文件
fos = new FileOutputStream(outputFilePath);
bos = new BufferedOutputStream(fos);
//设置编码为utf-8
byte[] bytes = outputString.toString().getBytes(StandardCharsets.UTF_8);
bos.write(bytes, 0, bytes.length);
- getCharsNumber() —— 获取字符数
- getWordNumber() —— 获取单词数
- getLineNumber() —— 获取有效行数
性能改进
- 一开始我想用静态方法实现这些函数,但是每个方法都要传递参数,有的甚至要四五个参数,例如写文件时要给函数文件路径,单词数,有效行数等等,而且静态函数有时需要返回多个值,综上考虑后舍弃静态方法,而是在类中添加了若干成员变量。
- 将打开读取文件与统计字符,统计单词,统计有效行一起执行,做到只读取一次文件内容。之前我是把文件内容存进String中,后来想到,万一这个String很大很大,在统计单词与有效行的时候需要一遍又一遍地遍历,十分花时间,干脆只读取一次。
- 舍弃正则匹配有效行数与单词数。利用算法可以在读取字符时顺带统计。
- hashmap排序的stream用法。
单元测试
测试统计字符数函数
由于不考虑中文,仅用0~127号ascii码测试,结果为128,符合预期
StringBuilder text= new StringBuilder();
for(int i=0; i<128; i++) {
text.append((char) i);
}
测试统计单词与提取频率最高的10个单词函数
测试统计单词:设计了一个字符串,其中包含5个合法单词,并让字符串重复添加五遍,总单词数为25,符合预期
StringBuilder text= new StringBuilder();
String words="123a;a15;A81qqs;axSx1651;1888asadw;QDWQ156;1535;awwwwc;ACWa;acwa\n";
for(int i =0; i < 5; i++) {
text.append(words);
}
测试提取频率最高的10个单词
测试了单词全小写,相同频率单词的排序,结果符合预期
String[] answerKey={"acwa", "awwwwc", "axsx1651", "qdwq156"};
Integer[] answerValue = {10, 5, 5, 5};
int i=0;
for (Map.Entry<String, Integer> entry : testLib.wordsCount.entrySet()){
Assert.assertEquals(entry.getKey(), answerKey[i]);
Assert.assertEquals(entry.getValue(), answerValue[i]);
i++;
}
测试有效行函数
测试包括多行空行,单行空行,单行中仅包含空白字符,结果为4,符合预期
String text="\ncs\n61561\n\n\n156\n\t\n615\n\n";
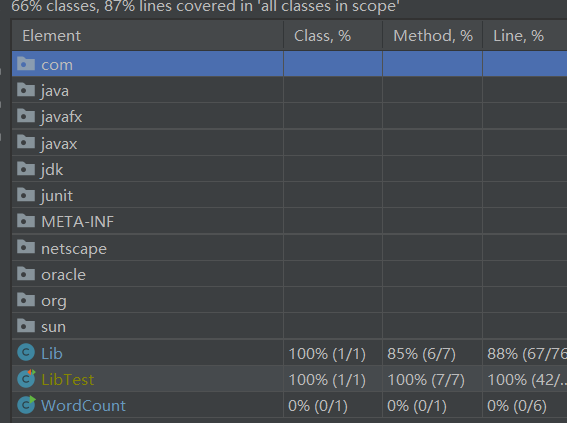
覆盖率截图
提高覆盖率方法:可通过对各个函数都进行测试,有分支的情况如if需要将每种情况测试一遍。
异常处理说明
包含两个部分:命令行传递参数不为2,文件读写错误
- 若参数不为2则退出程序:
if (args.length != 2) {
System.out.print("该程序只接受两个参数,待读取文件与待写入文件,程序关闭。。。");
System.exit(0);
}
- 待读写文件不存在则显示错误信息
catch (IOException e) {
e.printStackTrace();
System.exit(0);
}
心路历程与收获
- 这次作业相较于上次作业来说,工作量明显增加了,作业的要求写得十分详细,但即便如此我做起来仍然有些费劲,感觉把java重新学了一遍。
- 之前我没有这么系统的用github提交一个项目,这次作业加深了我对项目管理的认识。
- 重新读了一遍《构建之法》,对软件工程的理解更加深刻了,但还没有用于实践,希望能够尽快学以致用。
- 我之前用的ide是eclipse,现在换成了idea,对很多功能不是很了解,例如JUnit4的使用,通过这次作业让我学习很多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号