【吴恩达团队自然语言处理第四课】NLP中的注意力模型
【吴恩达团队自然语言处理第四课】NLP中的注意力模型
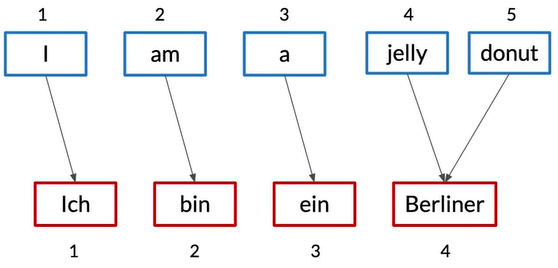
神经网络机器翻译
Outline
- Introduction to Neural Machine Translation
- Seq2Seq model and its shortcomings
- Solution for the information bottleneck
Seq2Seq model
- Introduced by Google in 2014
- Maps variable-length sequences to fixed-length memory
- LSTMs and GRUs are typically used to overcome the
vanishing gradient problem
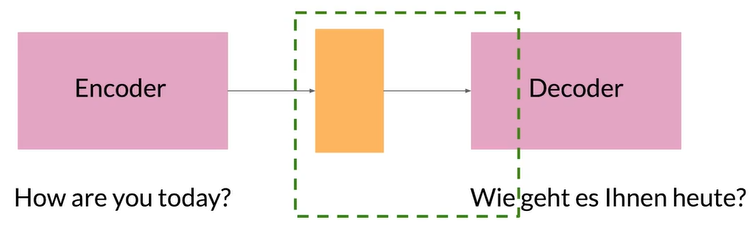
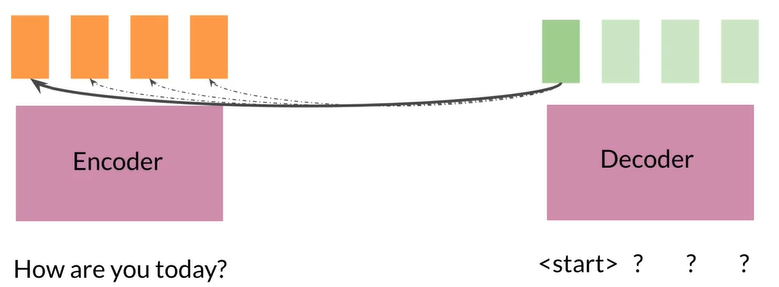
The information bottleneck
由于编码器的隐藏状态大小固定,较长的序列在进入解码器的过程中成为瓶颈,所以对较短的序列表现好,较长则不好
Seq2Seq shortcomings
-
Variable-length sentences +fixed-length memory=
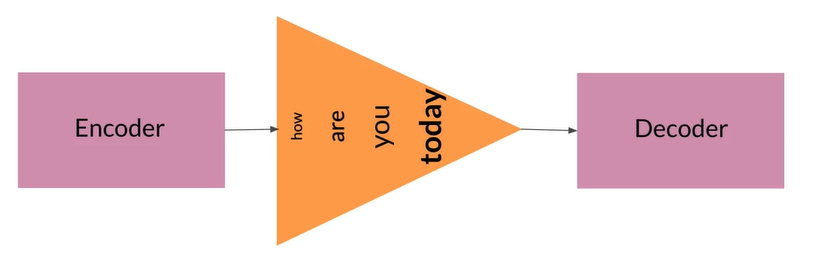
-
As sequence size increases,model performance decreases
One vector per word
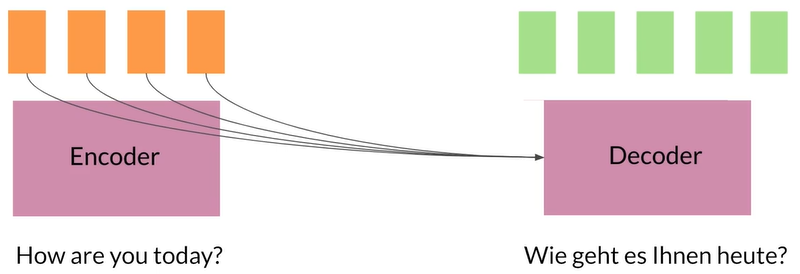
每个vector携带一个信息而不是将所有内容处理后组成一个大向量,
但是此模型在memory和context方面都有明显缺陷,如何建立可以从长序列中准确预测的a time and memory model
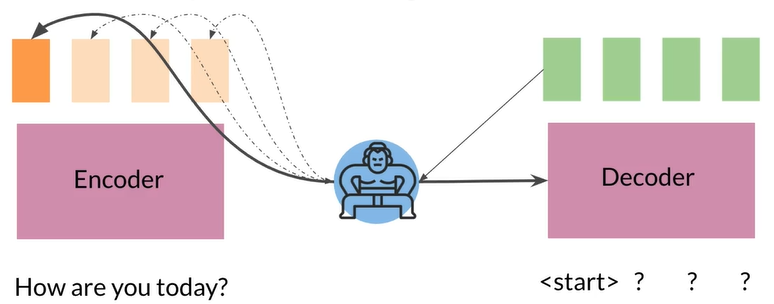
Solution: focus attention in the right place
- Prevent sequence overload by giving the model a way to focus on the likeliest words at each step 通过让模型在每个步骤中专注于最可能的词来防止序列过载
- Do this by providing the information specific to each input word 通过提供特定于每个输入单词的信息来做到这一点
Alignment
Motivation for alignment
希望输入的单词对其输出的单词
Correctly aligned words are the goal:
-
Translating from one language to another
-
Word sense discovery and disambiguation
bank可能是financial institution也可能是riverbank,将单词翻译成另一种语言,根据该词在其他语言中的解释,来分辨出含义 -
Achieve alignment with a system for retrieving information step by
step and scoring it
Word alignment
英语翻译的单词比德语多,在对齐时需要识别单词之间的关系
Which word to pay more attention to?
为了正确对齐需要增加一层layer来使编码器了解哪些输入对预测更重要
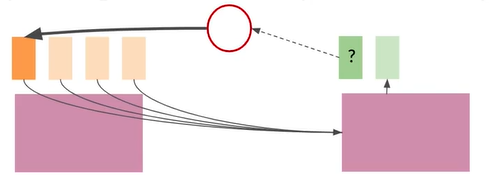
Give some inputs more weight!
更粗的线条意味着更大的影响
Calculating alignment
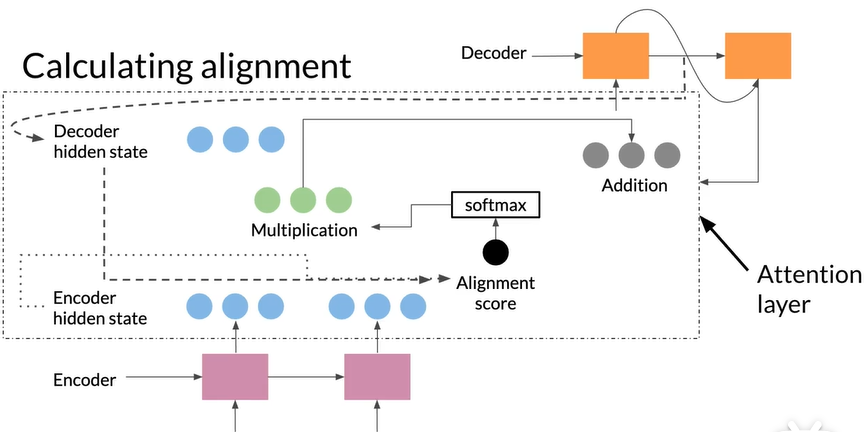
Attention
Outline
- Concept of attention for information retrieval
- Keys,Queries,and Values
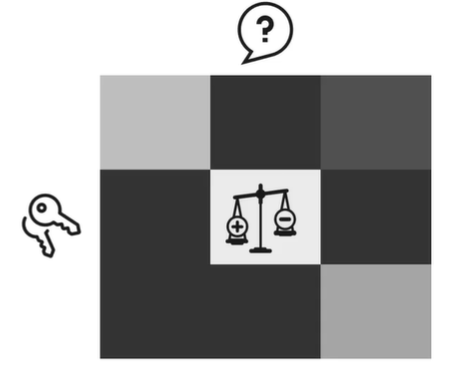
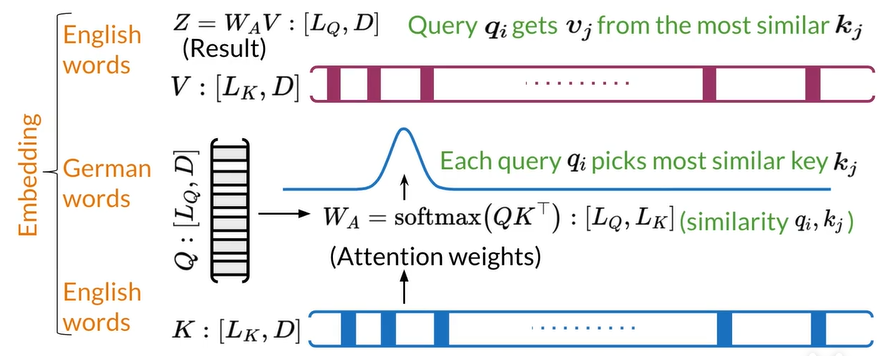
Information retrieval
信息检索 假设您正在寻找您的钥匙。
你请你妈妈帮你找到他们。
她根据钥匙通常的位置来权衡可能性,然后告诉你最有可能的位置。
这就是Attention 正在做的事情:使用您的查询查找正确的位置,并找到钥匙。
Inside the attention layer
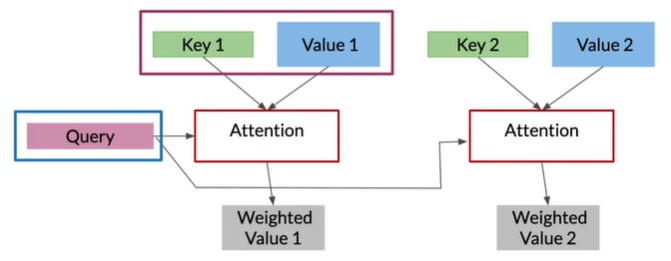
Attention
Keys and queries=1 matrix
with the words of one query(Q) as columns and the words of the keys(K) as the rows Value score(V) assigned based on the closeness of the match
Attention=Softmax(QK^T)V
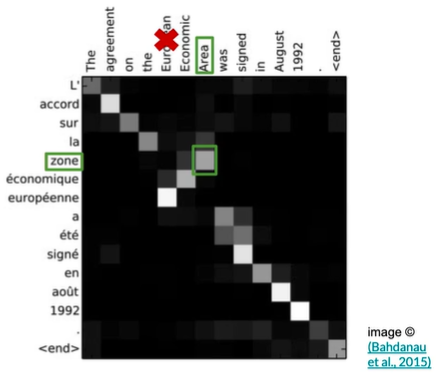
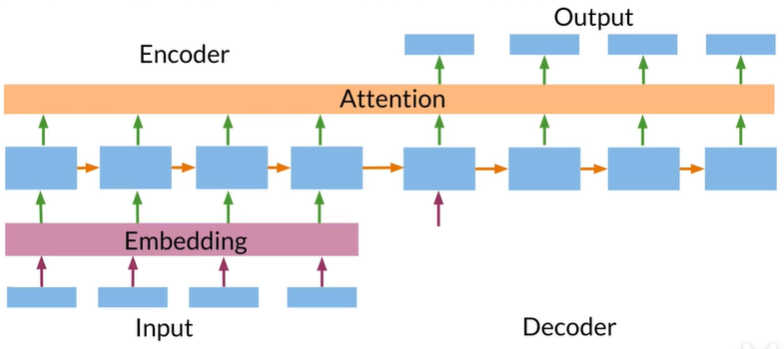
Neural machine translation with attention
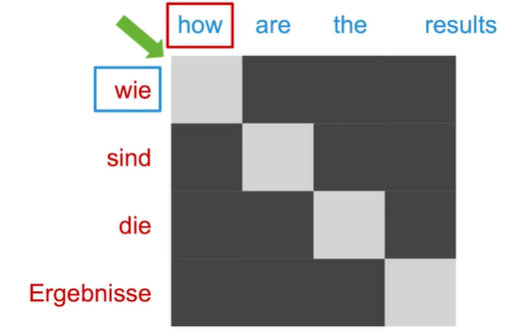
Flexible
attention For languages with differentgrammar structures,attention still looks at the correct token between them
Summary
- Attention is an added layer that lets a model focus on what's important
- Queries,Values,and Keys are used for information retrieval inside the Attention layer
- This flexible system finds matches even between languages with very different grammatical structures
Step up for machine tranlation
Data in machine translation

Machine translation setup
State-of-the-art uses pre-trained vectors
Otherwise,represent words with a one-hot vector to create the input
Keep track of index mappings with word2ind and ind2word dictionaries
Use start-of and end-of sequence tokens:

Preparing to translate to German
1结尾很多0,用0填充为配对的词


Training a NMT attention
- Teacher forcing
- Model for NMT with attention
How to know predictions are correct?
Teacher forcing allows the model to "check its work"at each step
Or,compare its prediction against the real output during training
教师强制允许模型在每一步“检查其工作”,或者,在训练期间将其预测与实际输出进行比较结果:
Result:Faster,more accurate training
Teacher forcing: motivation
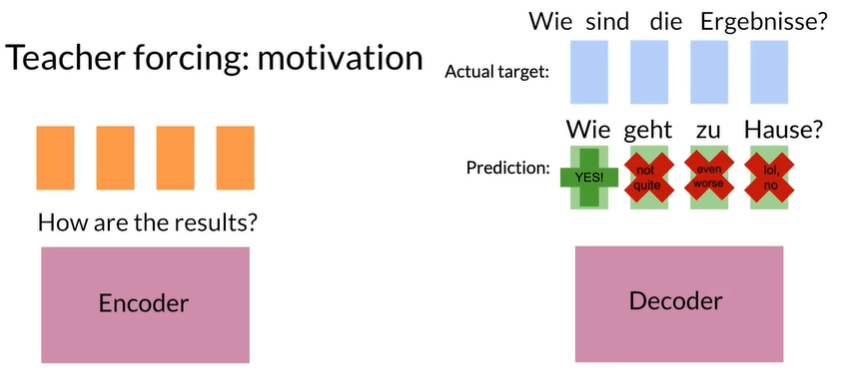
这一步的错误会导致下一步的预测更加错误,所以每一步的预测都要检查
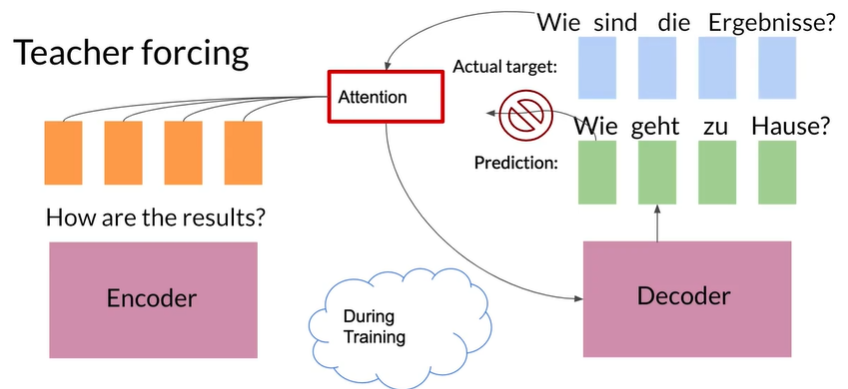
预测的绿色矩形不会用于预测下一个绿色矩形,
而实际的输出是解码器的输入
Training NMT
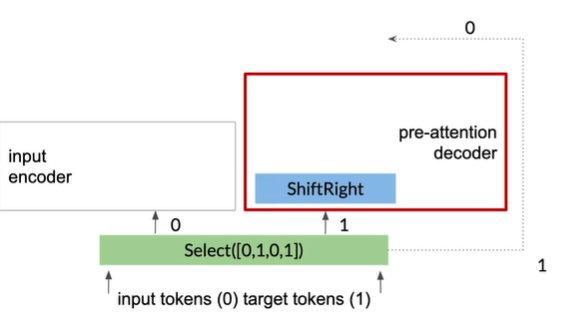
pre-attention decoder将预测目标转换为不同的向量空间,即query vector,
pre-attention decoder将target token右移一位,in start of sentence token是每个序列开头的符号
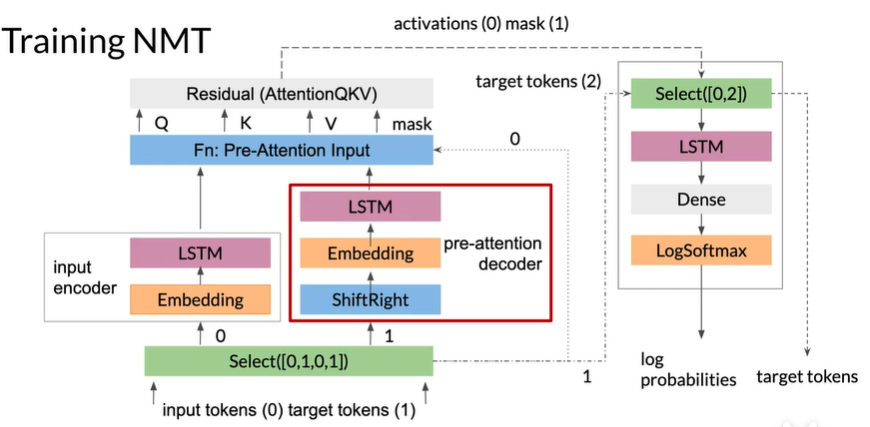
右边的四层为decoder
Evaluation for machine translation
BLEU Score
Stands for Bilingual Evaluation Understudy
Evaluates the quality of machine-translated text by comparing "candidate" text to one or more "reference"translations.
Scores: the closer to 1, the better, and vice versa:

e.g.

How many words in the candidate column appear in the reference translations?
"I"appears at most once in both,so clip to one:

BLEU score is great, but..
Consider the following:
- BLEU doesn't consider semantic meaning
- BLEU doesn't consider sentence structure:
"Ate I was hungry because!"
ROUGE
Recall-Oriented Understudy for Gisting Evaluation
Evaluates quality of machine text
Measures precision and recall between generated text and human-created text
与uni-gram结合使用的示例:
reference希望model预测出的理想结果

Recall =How much of the reference text is the system text capturing?
Precision=How much of the model text was relevant?


Problems in ROUGE
-
Doesn't take themes or concepts into consideration (i.e,a low ROUGE score doesn't necessarily mean the translation is bad)

Summary
- BLEU score compares"candidate" against "references"using an n-gram average
- BLEU doesn't consider meaning or structure
- ROUGE measures machine-generated text against an "ideal"reference
Sampling and decoding
Outline
- Random sampling
- Temperature in sampling
- Greedy decoding
- Beam search
- Minimum Bayes'risk(MBR)
Greedy decoding
Selects the most probable word at each step But the best word at each step may not be the best for longer sequences..

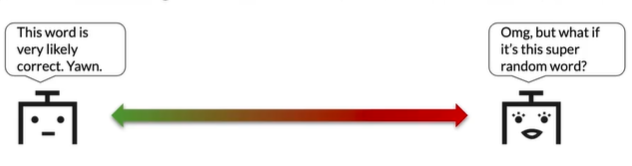
Random sampling

Often a little too random for accurate translation!
Solution: Assign more weight to more probable words, and less weight to less probable words.
Temperature
In sampling, temperature is a parameter allowing for more or less randomness in predictions
Lower temperature setting =More confident, conservative network
Higher temperature setting =More excited, random network(and more mistakes)
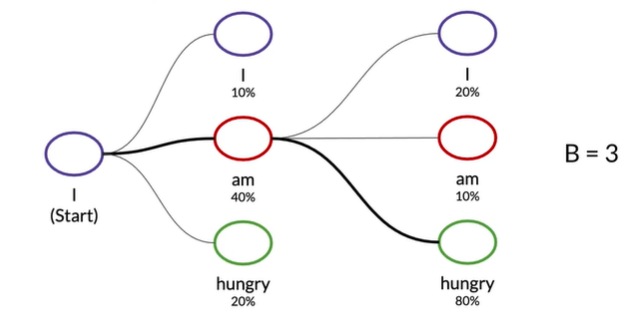
Beam search decoding
A broader,more exploratory decoding alternative
Selects multiple options for the best input based on conditional probability
Number of options depends on a predetermined beam width parameterB
Selects B number of best alternatives at each time step
e.g.
Problems with beam search
Since the model learns a distribution, that tends to carry more weight than single tokens
Can cause translation problems,i.e. in a speech corpus that hasn't been cleaned

Minimum Bayes Risk(MBR)
Compares many samples against one another. To implement MBR:
- Generate several random samples
- Compare each sample against all the others and assign a similarity score(such as ROUGE!)
- Select the sample with the highest similarity: the golden one
Example: MBR Sampling
To generate the scores for 4 samples:
- Calculate similarity score between sample 1 and sample2
- Calculate similarity score between sample 1 and sample3
- Calculate similarity score between sample 1 and sample 4
- average the score of the first 3 steps(Usually a weighted average)
- Repeat until all samples have overall scores
Summary
- Beam search uses conditional probabilities and the beam width parameter
- MBR(Minimum Bayes Risk)takes several samples and compares them against each other to find the golden one
- Go forth to the coding assignment!
Transformer
Outline
- Issues with RNNs
- Comparison with Transformers
transformer v.s. RNN
Neural Machine Translation
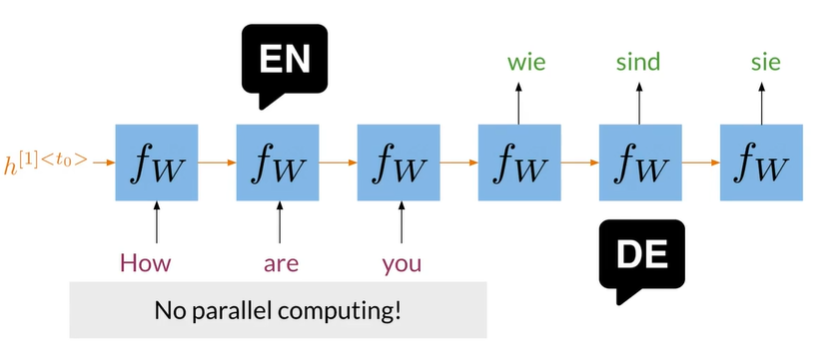
Seq2Seq Architectures
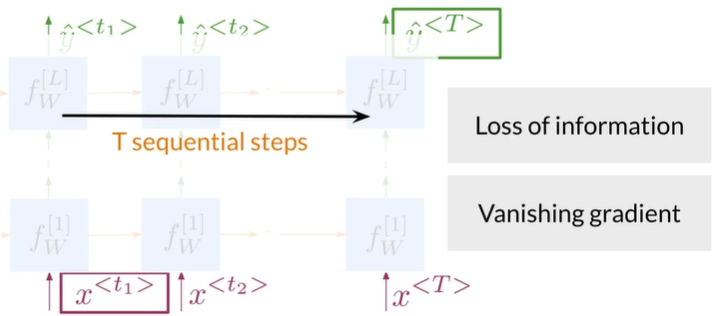
v.s
transformer基于attention,每层不需要任何顺序计算,需要传递的梯度也只有一步,没有梯度消失问题
Multi-headed attention
self-attention
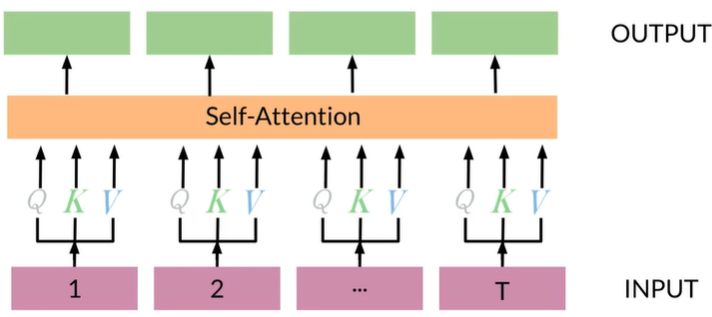
self-attention可以被理解为一个意图模型,每个输入的Q K V都包含一个dense layer
添加一组self-attention被称为heads
Multi-headed attention
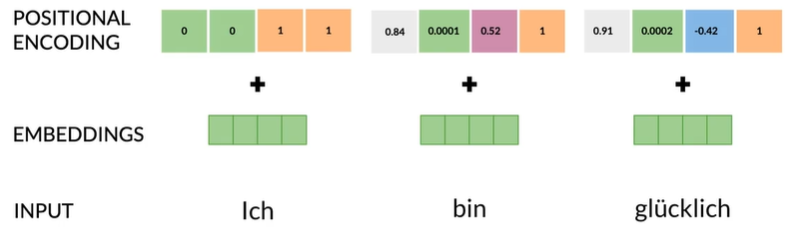
Positional Encoding
Transformers 还包含一个位置编码阶段,该阶段对序列中的每个输入位置进行编码,因为单词顺序和位置对于任何语言都非常重要。
Summary
- In RNNs parallel computing is difficult to implement
- For long sequences in RNNs there is loss of information
- In RNNs there is the problem of vanishing gradient
- Transformers help with all of the above
Application
Outline
- Transformers applications in NLP
- Some Transformers
- Introduction to T5
Transformers applications in NLP
Some Transformers
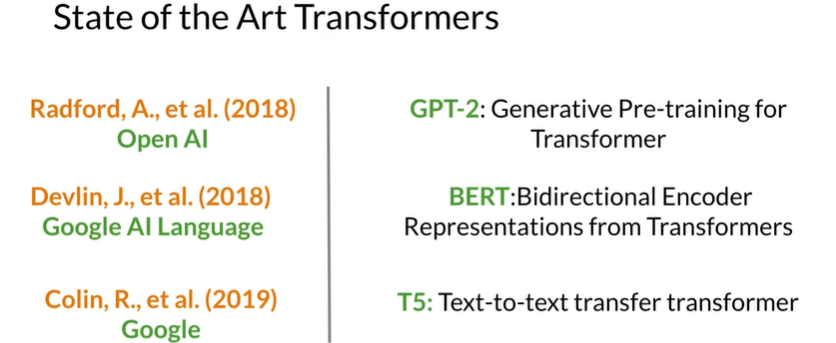
T5:Text-To-Text Transfer Transformer
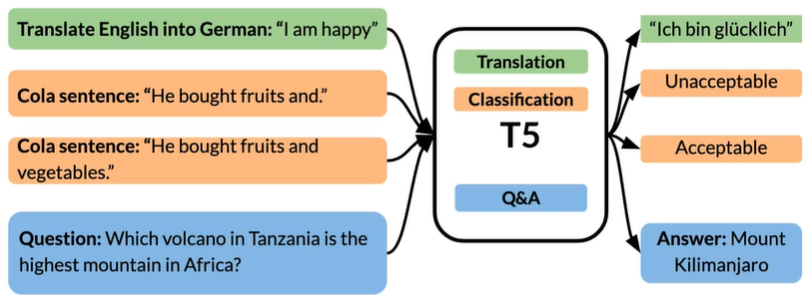
不需要为每一个任务单独训练模型,一个模型就可以完成这些任务
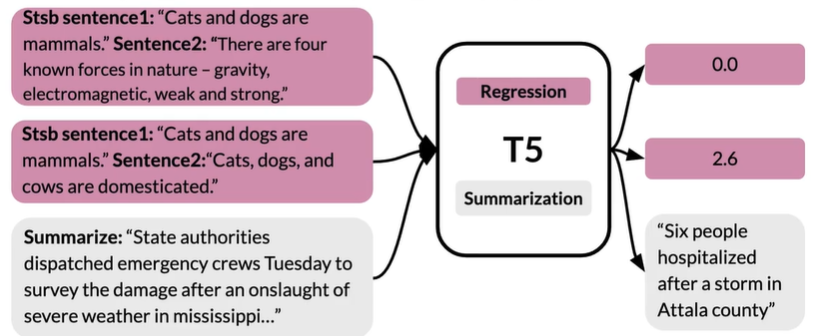
Summary
- Transformers are suitable for a wide range of NLP applications
- GPT-2,BERT and T5 are the cutting-edge Transformers
- T5 is a powerful multi-task transformer
dot production attention
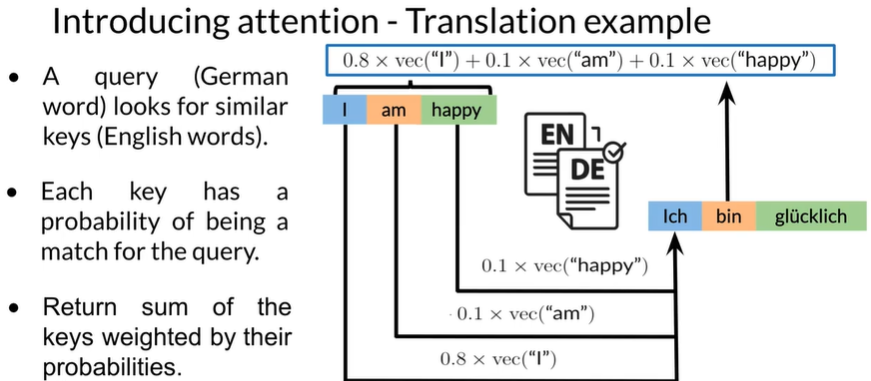
Queries, Keys and Values
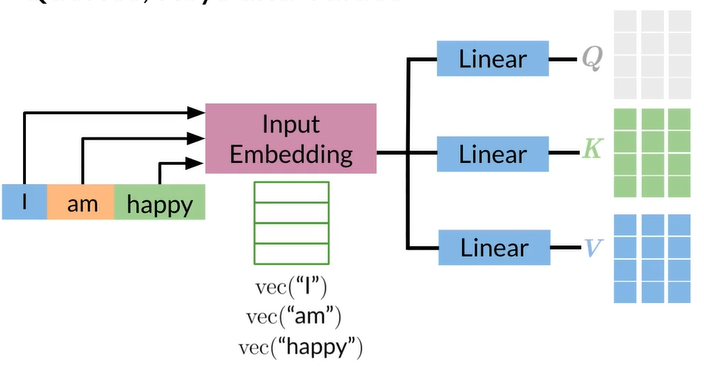
Concept of attention
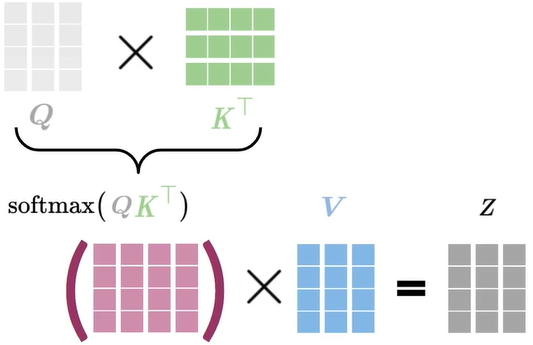
Attention math
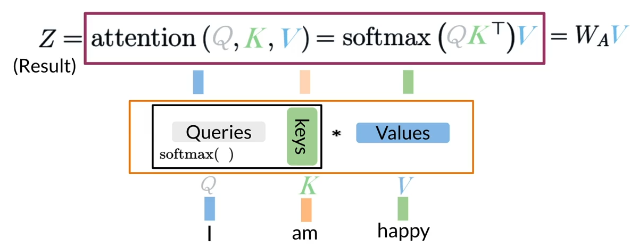 `
`
Summary
- Dot-product Attention is essential for Transformer·The input to Attention are queries,keys,and values
- A softmax function makes attention more focused on best keys
- GPUs and TPUs is advisable for matrix multiplications
Causal Attention
Outline
- Ways of Attention
- Overview of Causal Attention
- Math behind causal attention
Three ways of attention
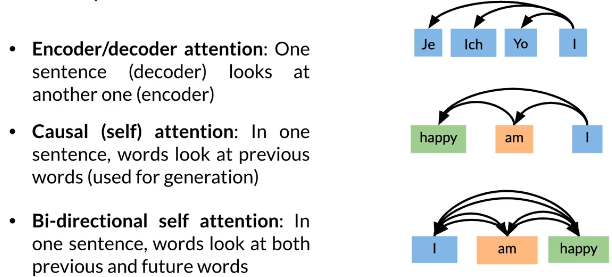
Causal attention
- Queries and keys are words from the same sentence
- Queries should only be allowed to look at words before
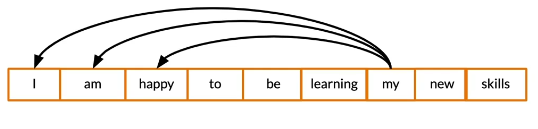
Math
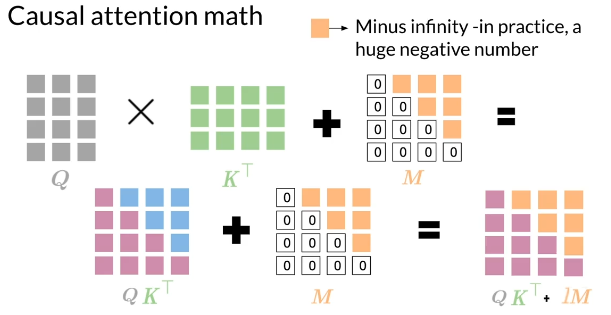
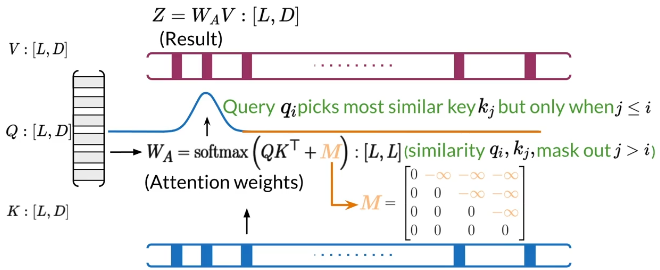
Summary
- There are three main ways of Attention:Encoder/Decoder,Causal and Bi-directional type
- In causal attention,queries and keys come from the same sentence and queries search among words before only
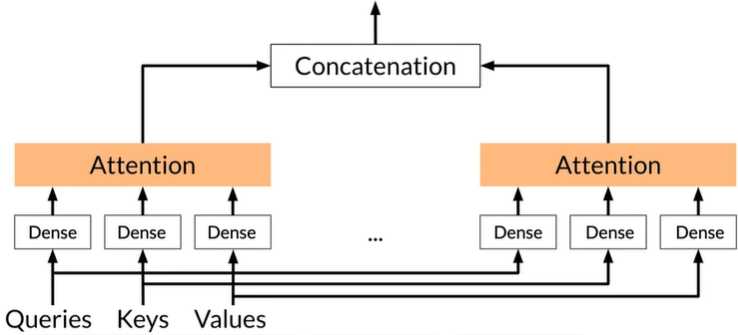
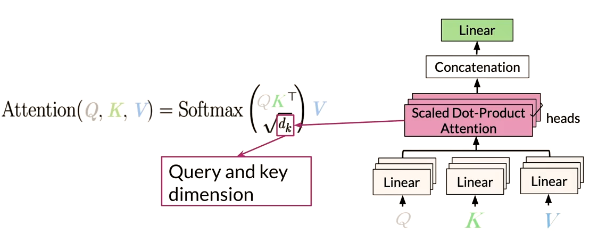
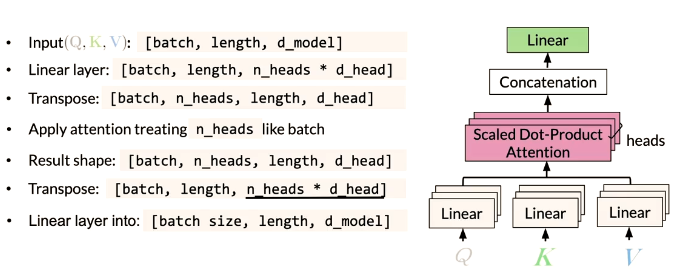
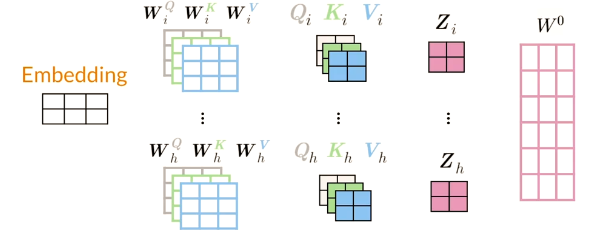
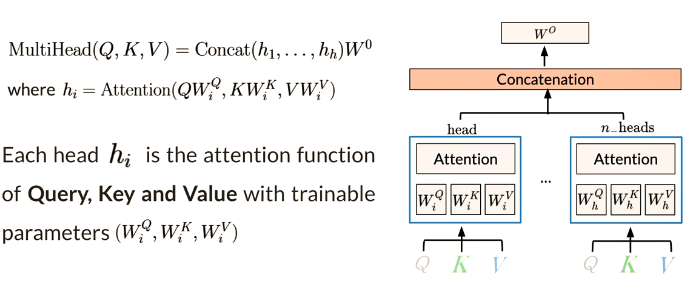
Multi-head attention
-
Each head uses different linear
transformations to represent
words -
Different heads can learn different
relationships between words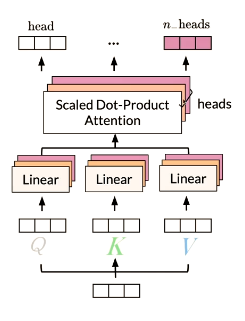
Concatenation
math
Summary
- Different heads can learn different relationship between words
- Scaled dot-product is adequate for Multi-Head Attention
- Multi-Headed models attend to information from different
representations at different positions
Transformer decoder
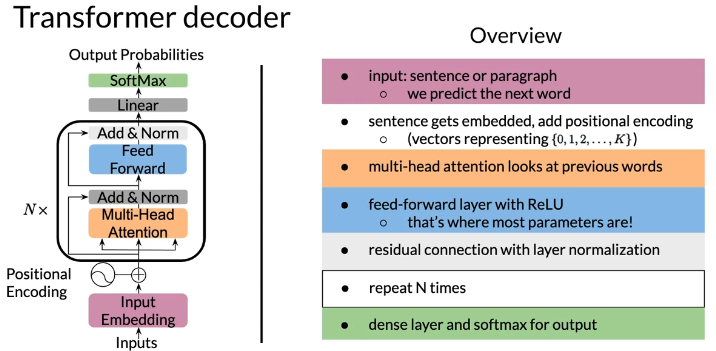
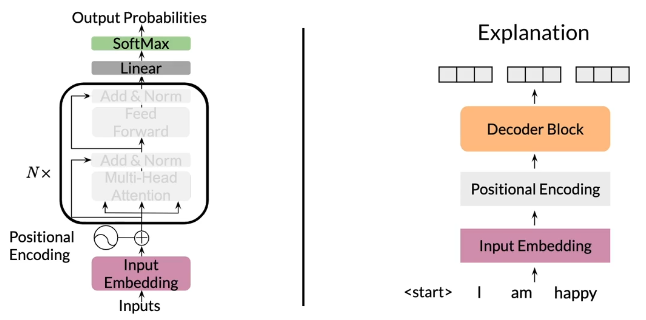
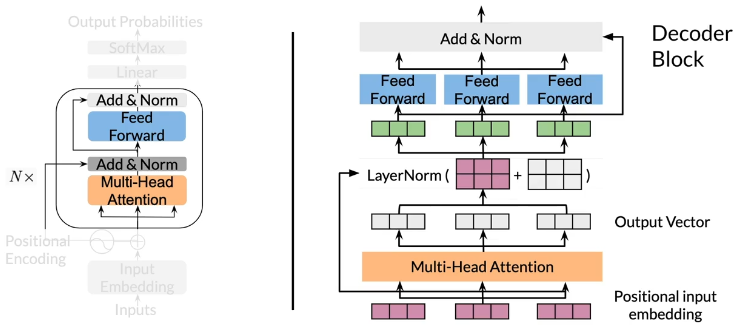
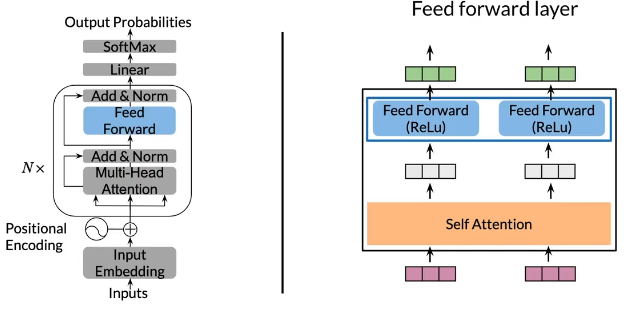
Summary
- Transformer decoder mainly consists of three layers
- Decoder and feed-forward blocks are the core of this model code
- It also includes a module to calculate the cross-entropy loss
Transformer summarizer
Outline
- Overview of Transformer summarizer
- Technical details for data processing
- Inference with a Language Model
overview
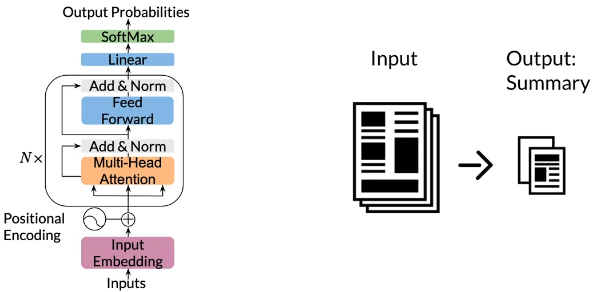
data processing
1是<EOS>
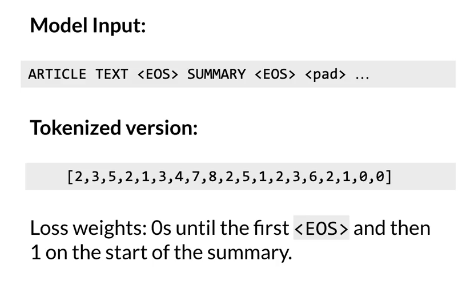
通过Loss weights focus on summary
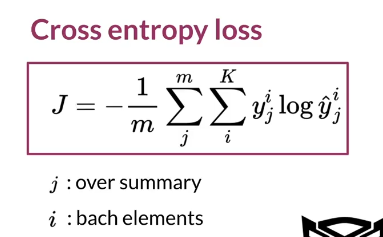
cost function
Inference with a Language Model

Summary
- For summarization,a weighted loss function is optimized
- Transformer Decoder summarizes predicting the next word using
- The transformer uses tokenized versions of the input

 浙公网安备 33010602011771号
浙公网安备 33010602011771号