15445 数据库系统(笔记)
2025/4/21
- No free lunch
- Remove mmap!
- The human was stupid,right?
- It's a simple solution to a simple problem. Surprisingly, this was not invented until the 90s.
前九章:
【数据库系统导论 15-445 2023Fall】CMU—中英字幕_哔哩哔哩_bilibili
其余:
11-查询执行-I [中文讲解] CMU-15445 数据库内核_哔哩哔哩_bilibili
Database Storage p2
日志结构化存储
-
InnoDB:默认引擎,基于 B+树 的索引组织表,重做日志(redo log)和写入缓冲(change buffer)采用了日志结构化的设计。
-
MyISAM:非日志结构化,使用堆表(heap)和静态索引结构。
-
RocksDB(可通过 MyRocks 集成):基于 LSM-Tree(Log-Structured Merge-Tree),是典型的日志结构化存储。
表组织方式指导“应该把记录放到哪些页、以什么顺序放置”,Slotted Page 则在选定的页面内部做好“插入、删除、更新”的具体操作。
表组织方式
堆表(Heap Table)
定义:堆表是一种最基础的表存储结构,数据行以插入顺序无特定顺序地存储在数据页中。
特点:
- 数据行在物理存储上无特定顺序。
- 插入操作快速,但查询特定数据可能效率较低。
- 适用于频繁插入和更新的场景。
聚簇索引表(Clustered Index Table):
定义:数据行按照某个索引(通常是主键)的顺序存储。
特点:
- 提高基于索引的查询性能。
- 在 InnoDB 中,表默认使用聚簇索引。
索引组织表(Index-Organized Table, IOT):
定义:数据存储在索引结构中,数据行即为索引条目。
特点:
- 节省存储空间。
- 适用于主键查询频繁的场景。
哈希组织表(Hash Organized Table):
定义:数据行根据哈希函数的结果存储在不同的桶中。
特点:
- 适用于等值查询。
- 不适合范围查询。
槽式页面(Slotted Pages)
定义:Slotted Pages 是一种页面管理机制,用于在数据页中存储和管理可变长度的记录。
结构:
- 页面头部(Page Header):存储页面的元数据,如空闲空间的起始位置等。
- 槽目录(Slot Directory):存储指向实际数据记录的指针,通常位于页面的顶部。
- 数据记录(Data Records):实际的行数据,通常从页面底部向上增长。
优点: - 支持记录的插入、删除和更新操作。
- 通过槽目录,可以实现记录的移动而不影响指针的有效性。
eg. 表(Heap): 引擎在空闲页列表或空间位图(GAM/PFS)中找到一个有 ≥ 行大小 + 槽目录开销 的页面。对于 B+树则会导航到正确的叶子页。
页(Slotted Page):在该页的 Slot Directory 增加一个新条目,记录新行的偏移和长度。
将行数据写入 Data Area(从底部向上)。
更新 Page Header 中的空闲空间指针和行计数
存储结构
聚簇索引表
- B+ 树叶子节点:物理上按索引顺序组织,每个叶子节点存储多行完整记录。
- 辅助索引:二级索引页只存储索引键与聚簇索引键的映射(或指针),查询二级索引后需回聚簇索引树检索完整行。
- 页分裂:当叶子节点满时自动分裂,保持 B+ 树平衡。
索引组织表
- 主键 B*Tree:主键索引的叶子节点同时保存整行数据。
- Overflow 段:对于过大或稀有访问的列,可配置 IOT Overflow segment,将这些列的数据存放在单独的 overflow 表空间中,以优化主索引结构。
- 无堆段:IOT 不存在独立的堆存储段(heap segment),数据全靠索引结构管理。
性能特点对比
| 特性 | 聚簇索引表 | 索引组织表 (IOT) |
|---|---|---|
| 按主键查询 | 直接在聚簇索引树中定位,性能优异 | “索引即表”,也同样无需二次回表,性能同样高效 |
| 二级索引查询 | 必须先查二级索引,再回聚簇索引(回表开销) | 二级索引同样需回主索引,但通过主键查找表数据 |
| 更新/插入 | 可能触发页分裂;插入新键逐页定位 | 因所有数据在同一结构,更新大型列可能触发 overflow 存取 |
| 存储利用率 | 数据与索引分离,空间利用较灵活 | 整行存储在索引,空间利用高度依赖索引树结构 |
| 使用场景 | 适合查询模式多样、需要多种二级索引的 OLTP/OLAP | 适合主键访问为主、列数有限且以主键查询为核心的场景 |
Storage Models & Database Compression
数据库工作负载
- on-line transaction processing (OLTP)
- 在线事务处理
- 只读/更新一小块数据
- on-line analytical processing (OLAP)
- 在线分析处理
- 读取大量数据聚合计算
- hybrid transaction + analytical processing
- 混合事务/分析处理
存储模型

Database Memory & Disk I/O Management
Buffer Pool Optimizations
- 多个缓冲池
- 预取
- Scan sharing(扫描共享)
- 允许多个查询共享同一个表扫描操作,减少 IO,提高缓存利用率,降低 CPU 开销,提高吞吐量
- Buffer Pool Bypass(缓冲池旁路)
- 允许某些操作直接访问磁盘数据,而不经过缓冲池的缓存机制,减少缓冲池污染,降低内存压力,提供特定查询的效率
顺序洪泛,当顺序访问时 LRU/Click 会丢失有效信息
解决: LRU - K
但也导致另一个问题,并未访问 K 次,导致被驱逐
解决: 维护一个内存中的哈希表,记录最近从磁盘中置换出去的几页以及它们访问的时间戳
- 允许某些操作直接访问磁盘数据,而不经过缓冲池的缓存机制,减少缓冲池污染,降低内存压力,提供特定查询的效率
Hash Tables
介绍了些常见的哈希算法
墓碑机制,避免线性探测到相同位置
布谷鸟算法,多个哈希
……
B+ Tree Indexes
Index Concurrentcy Control
MCS 锁
相较 TAS 自旋锁解决了缓存行弹跳的问题
MCS 锁采用了一种基于链表的策略来管理等待的线程,其核心思想是让每个等待的线程在一个本地变量上自旋,而不是一个共享变量。
实现
总结一下就是排队等待之前持有锁的线程释放,然后修改自己节点的自旋变量的值(
-
释放时的写 (Write by A): 当线程 A 修改
nodeB.locked时,这个写操作通常会伴随一个释放屏障 (Release Barrier) 或使用具有释放语义的原子写操作。这确保了在线程 A 进行这个写操作之前完成的所有内存修改(包括对受锁保护的数据的修改)对于线程 B 是可见的。 -
获取时的读 (Read by B): 线程 B 在循环中读取
nodeB.locked时,这个读操作通常会伴随一个获取屏障 (Acquire Barrier) 或使用具有获取语义的原子读操作。这确保了当线程 B 看到了nodeB.locked的值变为非锁定状态时,它也能看到线程 A 在释放锁之前所做的所有内存修改。) -
队列节点 (QNode): 每个尝试获取 MCS 锁的线程都会关联一个本地的队列节点 (QNode) 对象。这个 QNode 通常包含两个字段:
next: 指向队列中的下一个 QNode。locked(或state): 一个布尔值或状态变量,表示当前线程是否获得了锁或是否还在等待。这个字段是当前线程本地的,存在于该线程所在处理器的缓存中。
-
全局尾指针 (Global Tail Pointer): MCS 锁本身维护一个全局的原子指针
tail,指向等待队列的最后一个 QNode。这是唯一的共享/全局变量,但它只在线程尝试加入队列时被修改。 -
获取锁 (Acquire):
- 线程 A 准备一个本地的 QNode
nodeA。 - 它原子地将全局的
tail指针指向nodeA。在更新tail指针的同时,它会获得更新前的tail指针(假设是prevNode)。 - 如果
prevNode为null,说明队列之前是空的,线程 A 直接获得了锁。 - 如果
prevNode不为null,说明队列中有其他线程在等待。线程 A 将prevNode的next指针指向nodeA,表示nodeA现在是队列的末尾。 - 然后,线程 A 在自己的本地 QNode (
nodeA) 的locked字段上自旋,等待前一个线程释放锁时通知它。
- 线程 A 准备一个本地的 QNode
-
释放锁 (Release):
- 持有锁的线程(假设是线程 A)需要释放锁。
- 它首先检查自己的 QNode (
nodeA) 的next指针是否为null。- 如果
next为null,说明它是队列中的最后一个线程。它会尝试原子地将全局的tail指针从nodeA改回null。如果成功,则表示队列清空,锁被完全释放。如果失败(说明在它检查next为null后,又有新的线程加入了队列),它会稍微等待一下,直到新的末尾节点的next指针指向它(即nodeA->next不再是null),然后继续下一步。 - 如果
next不为null,说明队列中还有下一个线程(假设是线程 B,对应 QNodenodeB)。线程 A 会修改nodeB的locked字段(例如,设置为false),以此点对点地通知线程 B 停止自旋并获取锁。
- 如果
缺点
- 实现更复杂: 相比简单的 Test-and-Set 或 TATAS 锁,MCS 锁的实现要复杂得多,涉及到链表管理和多个原子操作。
- 单次获取/释放开销略高: 在低竞争环境下,MCS 锁创建 QNode、修改指针等操作的开销可能略高于非常简单的自旋锁。
- 需要每个线程有自己的 QNode: 这通常意味着需要在线程本地存储或者动态分配 QNode。
TAS 和 CAS
- TAS 适用于最简单的互斥场景,例如实现一个基础的自旋锁。它的优点是简单快速。
- CAS 功能更强大、更通用,是实现各种原子更新操作和无锁数据结构的基础。它的优点是灵活性高,可以实现非阻塞算法。(ABA 问题)
避免锁根节点的优化: 乐观锁
乐观锁总是假设最好的情况,认为共享资源每次被访问的时候不会出现问题,线程可以不停地执行,无需加锁也无需等待,只是在提交修改的时候去验证对应的资源(也就是数据)是否被其它线程修改了(具体方法可以使用版本号机制或 CAS 算法)。
Sorting & Aggergation Algorithms
Timsort
-
识别和准备运行(Identify and Prepare Runs):
- Timsort 从输入数组的开始扫描,查找连续的升序或严格降序的子序列。
- 找到的这些子序列被称为“运行”(runs)。
- 如果找到的是严格降序运行,算法会将其反转,使其变为升序运行。
- 对于长度小于一个预设最小值(minrun)的运行,Timsort 会使用插入排序对其进行扩展和排序。插入排序在小规模数据上效率很高,这使得 Timsort 在处理接近有序的小块数据时表现出色。minrun 的值根据输入数组的大小动态计算,以优化性能。
-
合并运行(Merge Runs):
- 在识别并(如果需要)扩展运行后,Timsort 将这些运行放在一个栈上。
- 算法会按照一定的策略合并栈顶的相邻运行,直到只剩下一个运行,即整个数组有序。
- 合并过程是 Timsort 的关键部分。为了提高效率,Timsort 在合并时采用了称为“ galloping mode”(奔腾模式)的优化。当一个运行中的连续元素都小于或大于另一个运行的当前元素时,Timsort 会快速“跳过”这些元素,而不是逐个比较,从而减少比较次数。
- 为了确保稳定性(相等元素在排序后保持其原始相对顺序),Timsort 在合并时会优先从未被视为“gallop”的运行中取出元素。
老印咖喱味太浓,听不进去(悲
Join Algorithms
Nested Loop Join
table 1: M page m tuples
table 2: N page n tuples
C
Stupid M+(m*N)

Block M+(M*N)

Lndex (M+m*C)
B+树
Sort-Merge Join
先排序,然后每次增加左右表游标所指记录相对小的游标。
Hash Join
Basic
先扫记录多的表建个哈希表,然后记录少的表从里面找
布隆过滤器加速,外表扫描的时候顺便建一个
Grace
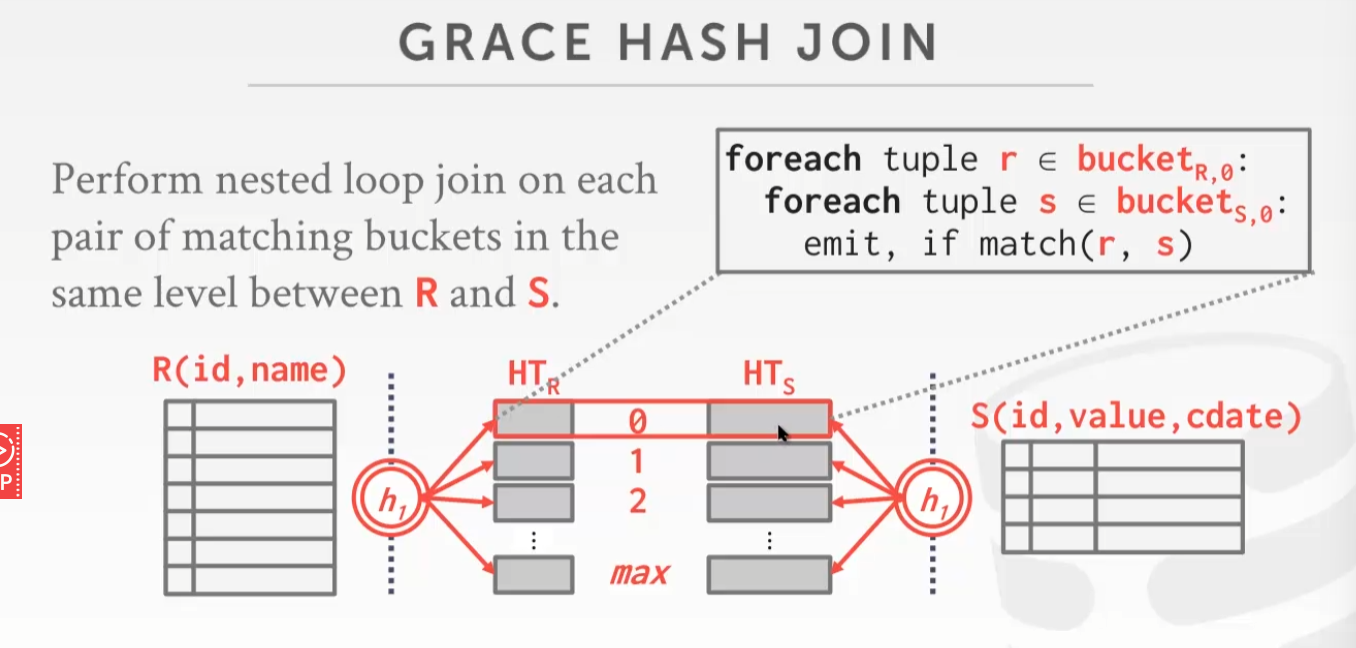

Query Execution
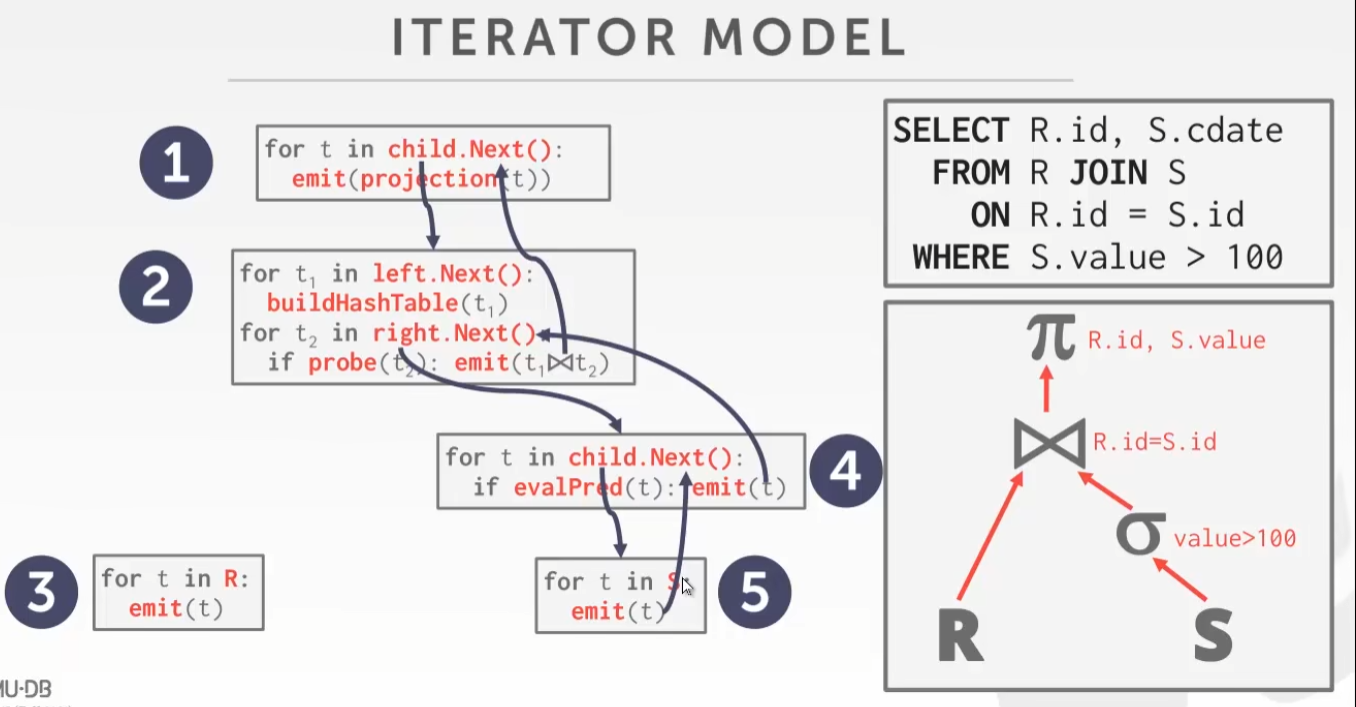
执行模型
迭代模型(火山模型/流式)
一条一条返回
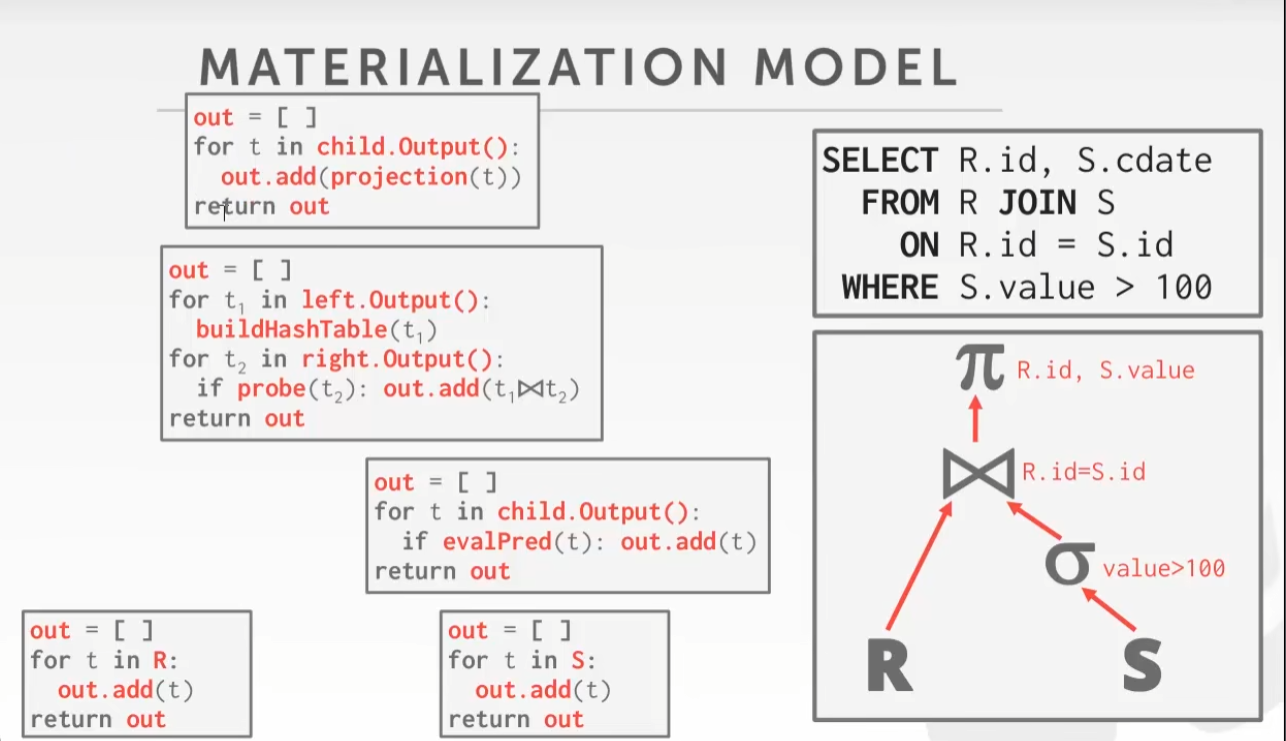
物化模型
全部返回
向量化模型(分批模型)
一批一批,缝合怪
计划执行方向
自顶向下,自底向上
存取方法
顺序扫描
优化:
- 预取
- 缓存池旁路
- 并行
- Heap Clustering
- Zone Maps
- 对每个页做统计信息,最大值,平均,总和,Count
- 延迟物化
- 只返 ID/指针即可,回表查

Inter Query
Intera Query
Exchange Type
- Gather
- Distribute
- Repartition
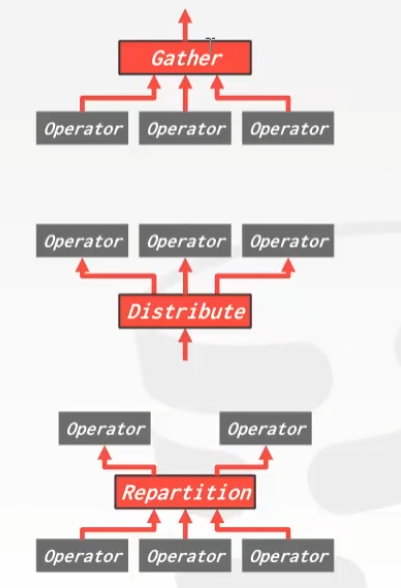
- 水平,按照数据范围切分,多个线程执行,最后聚合(Exchange)
- 垂直,多个线程负责不同层级的操作,不断给上一层数据
- Bushy,水平 + 垂直
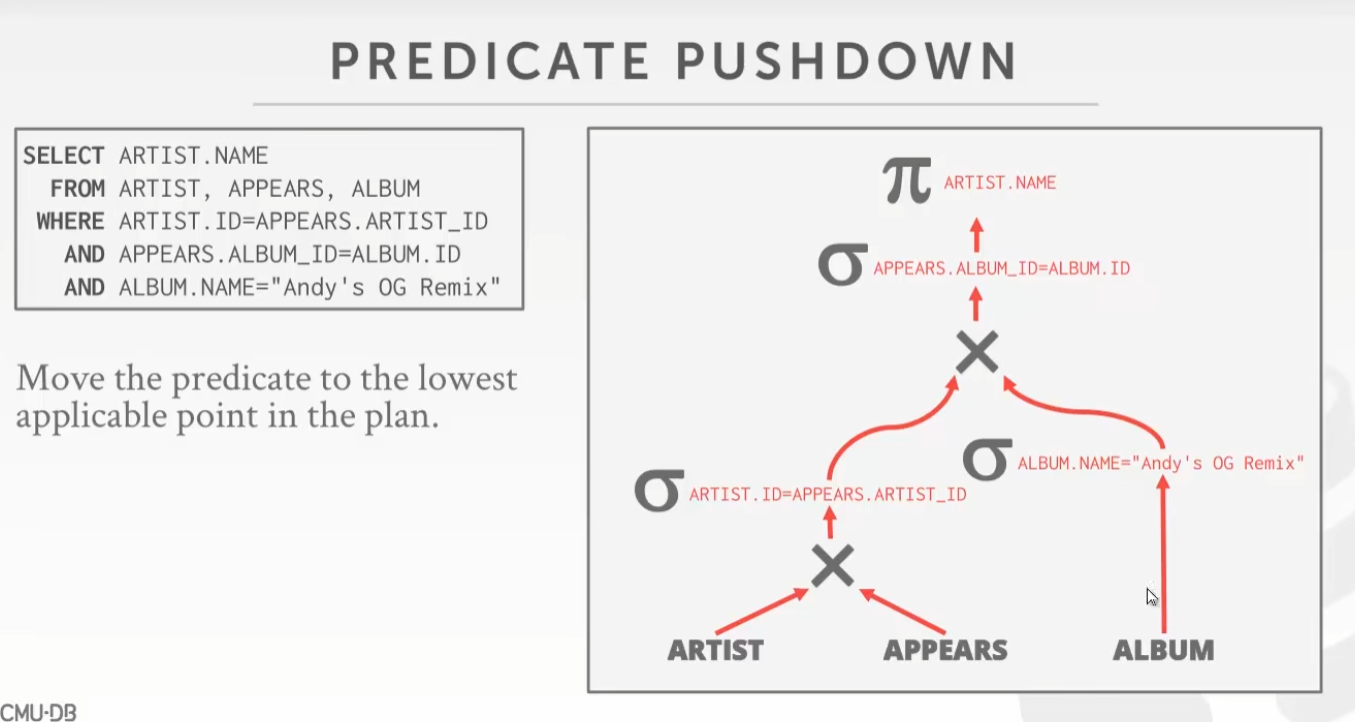
Query Planning 查询优化
谓词下推(Predicatite Pushdown)
投影下推(Projection Pushdown)
尽早过滤掉查询中不需要的列
-- 原始查询
SELECT a.name, a.age FROM (
SELECT * FROM users WHERE gender = 'M'
) a WHERE a.age > 30;
-- 优化后(投影下推)
SELECT a.name, a.age FROM (
SELECT id, name, age FROM users WHERE gender = 'M'
) a WHERE a.age > 30;
并发控制
二阶段锁
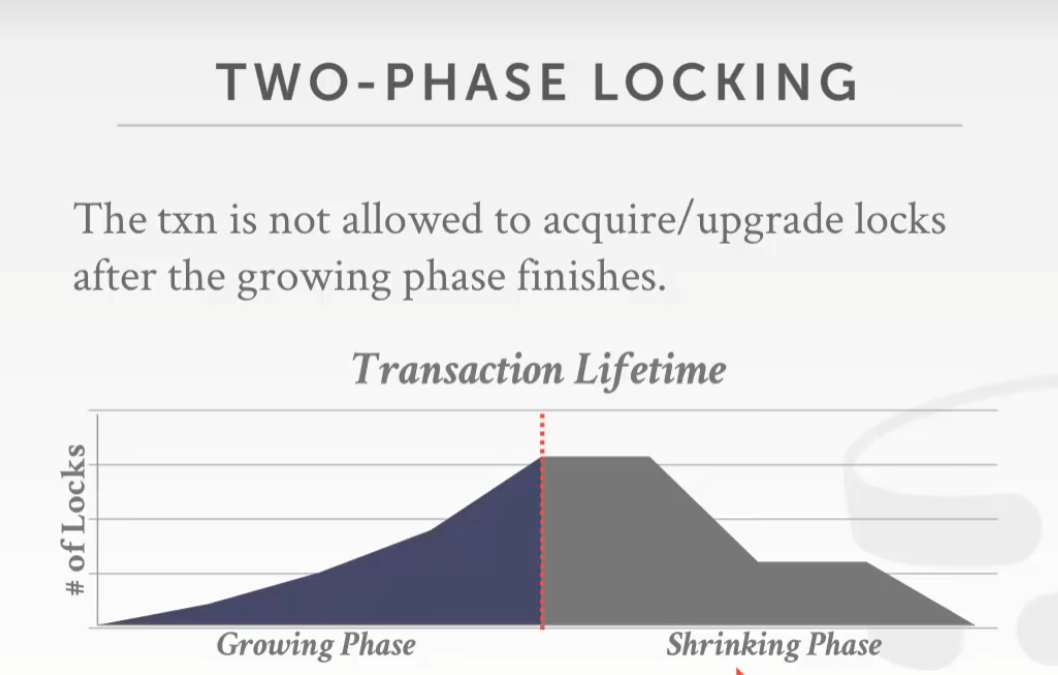
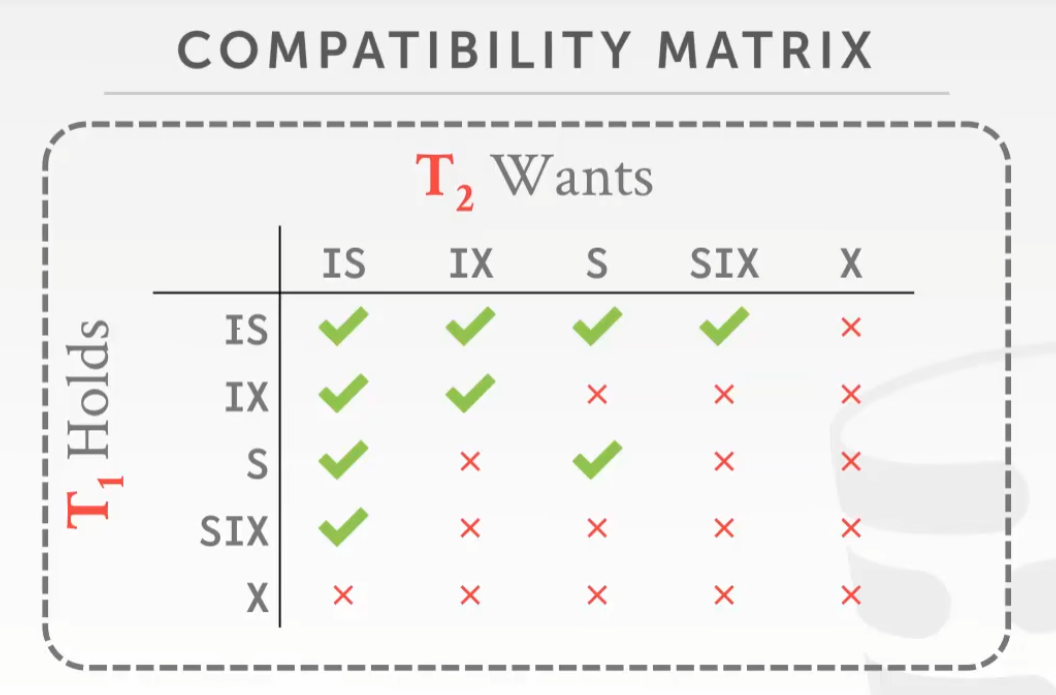
时间戳顺序并发控制
| 机制 | 策略 | 适用场景 |
|---|---|---|
| 悲观锁(如2PL) | 默认加锁,防止冲突 | 高冲突、短事务 |
| OCC | 提交时检测冲突 | 低冲突、长事务或高并发读 |
| MVCC | 多版本快照隔离 | 读多写少,要求一致性快照(如PostgreSQL) |
垃圾回收(版本)
- 没有事务可以看见这个版本
- 版本由一个回滚的事务创建
行记录级别
- 为了避免全表扫描,使用一个 dirty block,只清理脏页
- 工作线程遍历版本的时候顺便清理
事务级别

辅助索引
- 逻辑指针 (主键/tuple id)
- 物理指针
- 带来的问题:多个辅助索引指向的同一块物理地址可能会发生改变(插入新的版本)

数据库恢复
checkpoints
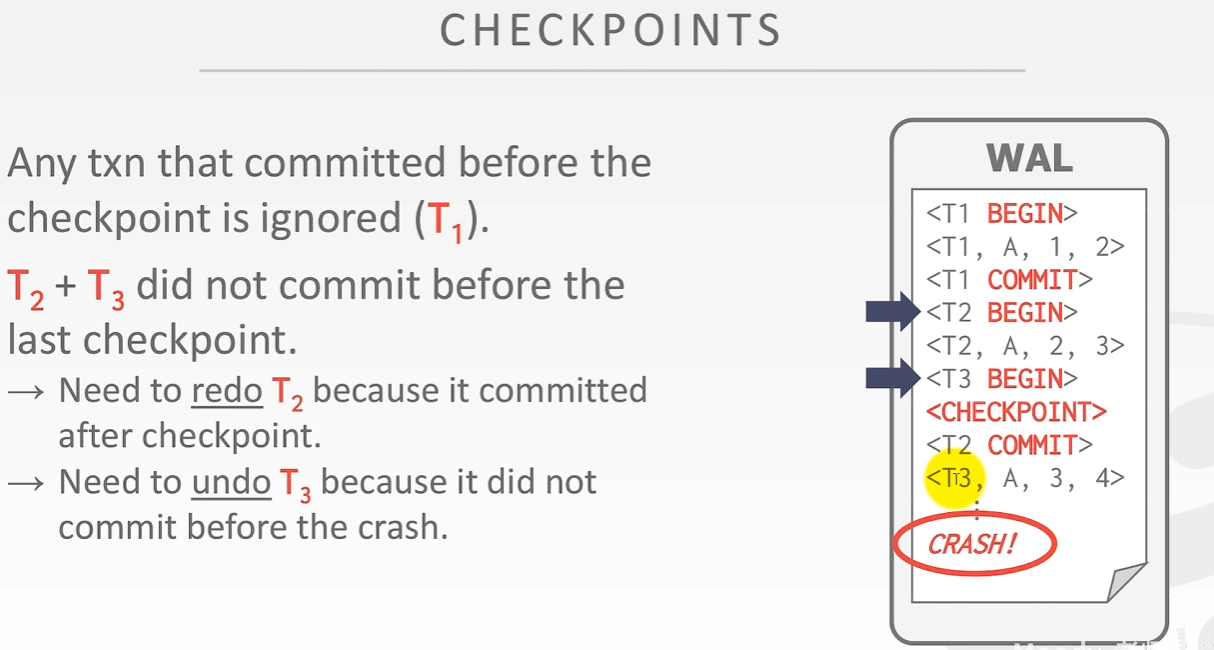
commit 就已经刷盘了(至少redolog 和 binlog)
补充:
redo log已落盘但未commit。binlog需要判断是否完整写入
binlog 完整性的判断依据
(1) 事务标识符(XID)
- 全局唯一标识:每个事务在
redo log和binlog中记录一个唯一的XID(事务标识符)。 - 关键作用:在崩溃恢复时,通过 XID 关联
redo log和binlog,确保两者的对应关系。
(2) binlog 事务事件的完整性
- 事务边界标记:每个事务在
binlog中表现为一个完整的事件序列,包括:- BEGIN 事件(隐式或显式)。
- DML 操作事件(如 INSERT/UPDATE/DELETE)。
- COMMIT/XID 事件(显式提交标记)。
- 完整性检查:若
binlog中存在对应 XID 的完整事件序列(包含 BEGIN 和 COMMIT/XID),则认为该事务的binlog是完整的。
(3) 校验机制
- Checksum 校验:MySQL 5.6 之后支持
binlog的checksum功能(通过参数binlog_checksum启用),对每个binlog事件计算校验和,确保日志内容未被篡改或损坏。 - 文件完整性:崩溃恢复时还会检查
binlog文件的完整性(如文件末尾是否截断)。
恢复流程的具体步骤
- 扫描
redo log:找到所有处于prepare状态的事务(即未标记为commit)。 - 提取 XID:从这些
redo log中提取对应的 XID。 - 检查
binlog:- 若
binlog中存在对应 XID 的COMMIT/XID 事件,则认为事务已成功提交,将redo log标记为commit并重放数据修改。 - 若
binlog中无对应 XID 或事件不完整(如缺少 COMMIT),则认为事务未提交,回滚redo log的修改。
- 若
ARIES (Algorithms for Recovery and Isolation Exploiting Semantics)
LSN (Log Sequence Numbers)

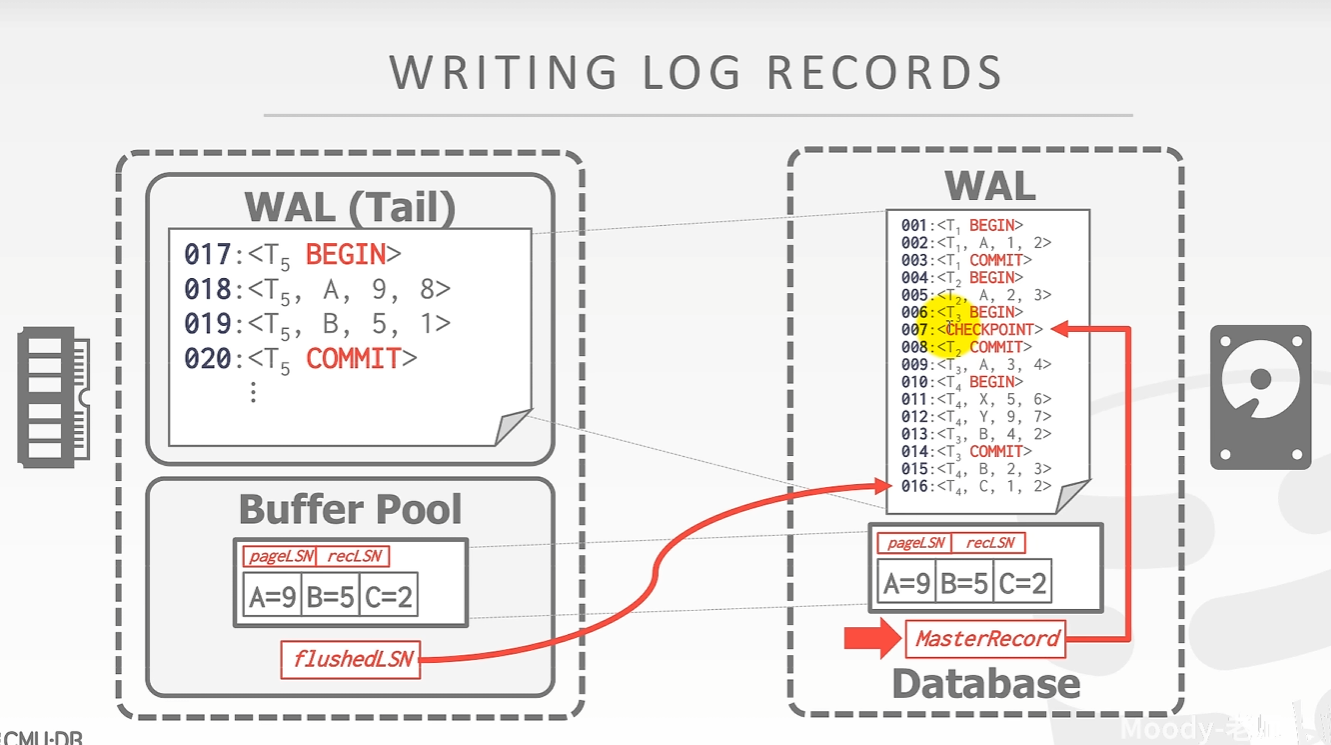
保证 pageLSN 大于 flushedLSN 的不能提前刷,即所有关于该页的日志必须均已完成刷盘。
Transaction Abort
prevLSN 尽量保证连续性,避免同时执行其他事务的 LSN 干扰
Compensation Log Records (CLR) 补偿日志记录,记录 UndoNext
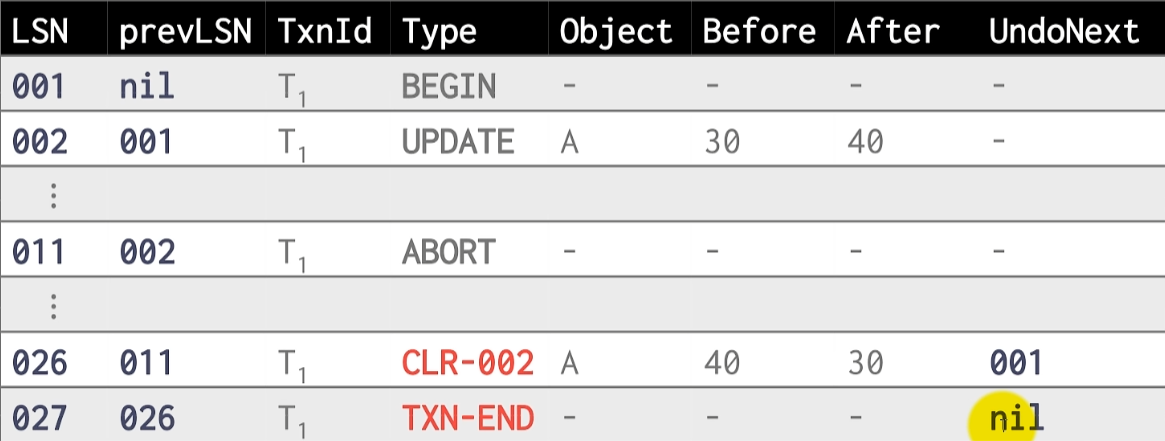
- 写 Abort record
- 对于每个更新记录
- 写一条新的 CLR
- 重新恢复旧值
- 写一条 Txn-End 日志记录
确保事务回滚/恢复过程中断,也能够通过最新 CLR 记录的 UndoNext 断点继续

如果 DBMS 在重做阶段的恢复过程中崩溃,它会怎么做?
一切都重做一遍。(因为重做的操作都在操作内存中的页,还没有持久化)
分布式
等 Lab 做完补充
总结
至此,15445 的课程基本看完了,接下来是更重要的代码环节。
应用层那块记的比较简单,因为算是比较熟悉。带上 6.824,6. s081 …开的第三个坑了,希望能在毕业之前做完吧…

 浙公网安备 33010602011771号
浙公网安备 33010602011771号