C++进阶!
一些
- Vscode C/C++ Extension Pack 拓展
- (x++)++后置只能加一次
- 引用做模板参数必须是静态储存期
- 重载运算符(operator overloading)时,参数顺序是由运算符的语法规则决定的。对于二元运算符(如
+、-、*、/等),第一个参数是左操作数,第二个参数是右操作数。对于一元运算符(如-、!、++、--等),只有一个参数。 - 在模板类型推导中,引用类型参数将被视为非引用类型处理,也就是说其引用性被忽略。
- 在万能引用参数类型推导时,左值参数被特殊处理。
- 值传递形参的类型推导时,其 const 和 volatile 被忽略。
- 在模板类型推导时,数组或者函数类型被转换为指针类型,除非它们用来初始化引用。
- typeid, typeof, decltype,
- 右值引用&&+右值 move 配合使用
- C++的模板类声明和实现得在一个文件中,不然会
未定义的引用 - //function 不支持泛型函数打包,必须在赋值时显式实例化模板参数
- 函数声明是隐式 extern 的,变量如果不写就是定义
- offsetof 查看结构体/联合体成员的内存布局
- inline 最大的用处是:非 template 函数,成员或非成员,把定义放在头文件中,定义前不加 inline ,如果头文件被多个 translation unit(cpp 文件)引用,ODR 会报错 multiple definition。
- 判断是否是类成员函数可以 std:: is_function_v 或者 !std::is_member_function_pointer_v<decltype (&...)>
- C++ 的模板不是具体类型,实例化之后才是(即函数模板不是函数,类模板不是类),类模板的静态成员或静态成员函数也不属于模板,而是属于实例化后的具体类型
- ScopeGuard 原理介绍与实现(上) – Origought c++中的 defer
- 当你使用前向引用声明时,你只能使用被声明的符号,而不能涉及类的任何细节。
+[]是一个空捕获列表的 lambda 表达式,并且前面加上了一个加号+。这个加号的作用是将 lambda 表达式转换为一个函数指针。- 小于
16字节大小的结构体值传递效率比引用效率更高 - 从 mmap 的文件里拿出来如果原本结构有动态分配的,记得分配
- 要把移动构造函数写为 noexcept,这样编译器才会调用
- ((type *)0)->member
- 隐式转换操作符 operator type() const
uint8_t header_len : 4, ip_ver : 4;使用位域可以让代码直接按照协议规范的位数进行访问,而不需要手动进行位操作(如位移、掩码等)。这样既节省了存储空间,又使代码更易读和维护。- 建议在约束表达式中始终优先使用概念(如
same_as)而非类型特征(如is_same_v)requires (std::is_same_v<T, int> && T::value) // 危险! 当T=double时,虽然is_same_v为false,但编译器仍会实例化T::value导致编译错误(double 没有::value 成员) - 如果
num发生 扩容(reallocation),tmp仍然会失效,因为扩容会导致所有迭代器、指针和引用失效
new(q_)PTCPQ(conf_.TcpQueueSize);
typedef char TThostFtdcBrokerIDType[11]; 定义TThostFtdcBrokerIDType=char[11]
Quick C++ Benchmarks 性能测试
Fetching Title#or55 神器
C++ Insights
在 C 和 C++中,当赋值操作符的左侧和右侧是同一个对象,不能在赋值操作的两边使用自增或自减操作符,其他,*dst++ = *src++; 是可以的
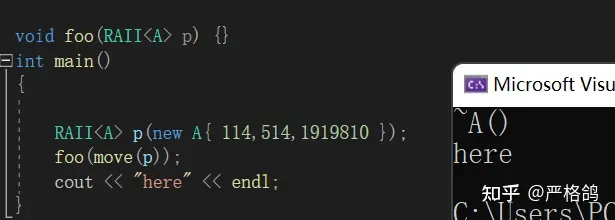
如何把 RAII 类作为函数的参数?

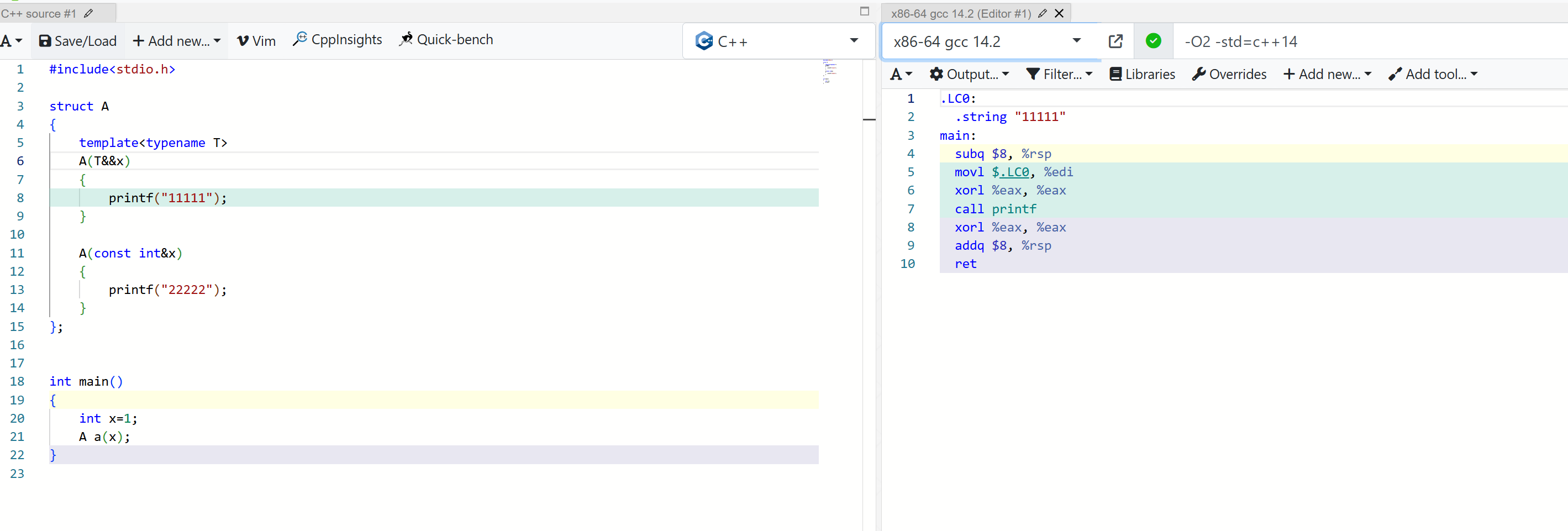
decay
作用
退化类型的修饰。
为类型 T 应用从左值到右值(lvalue-to-rvalue)、数组到指针(array-to-pointer)和函数到指针(function-to-pointer)的隐式转换。转换将移除类型 T 的 cv 限定符(const 和 volatile),并定义结果类型为 decay< T >:: type。这种转换很类似于函数参数按值传递时发生的转换。有以下几种情况:
若 T 为“ U 的数组”或“到 U 的数组的引用”类型,则 decay< T >:: type 为 U* 。
若 T 为函数类型 F 或到它的引用,则 decay< T >:: type 为 std::add_pointer< F >:: type 。
否则,decay< T >:: type 为 std::remove_cv<std::remove_reference< T >::type>:: type。
用数组指针或数组引用作为函数参数,有如下优点:
- 参数仍然保留着数组的信息,包括长度,所以我们可以使用基于范围的 for 循环。
- 防止参数误传。如果参数是长度为 8 的数组指针或引用,传递长度为 10 的数组作为参数,编译是无法通过的。
- 方便。
缺点是为了方便可能会使用模板元,减慢速度
declval
declval 就是专门治那些无法实例化具体对象的场合的。
std::declval<T>() 也被典型地用在编译期测试等用途
concept
template < template-parameter-list >
concept concept-name = constraint-expression;
其中,constraint-expression是一个可以被 eval 为 bool 的表达式或者编译期函数。 在使用定义好的 concept 时,constraint-expression会根据上面 template-parameter-list传入的类型,执行编译期计算,判断使用该 concept 的模板定义是否满足。 如果不满足,则编译期会给定一个具有明确语义的错误,即 这个 concept 没有匹配成功啦啦这种。 注意到,上述匹配的行为都是在编译期完成的,因此 concept 其实是 zero-cost 的。 举个例子来描述一下,最基本的 concept 的定义。
// 一个永远都能匹配成功的concept
template <typename T>
concept always_satisfied = true;
// 一个约束T只能是整数类型的concept,整数类型包括 char, unsigned char, short, ushort, int, unsinged int, long等。
template <typename T>
concept integral = std::is_integral_v<T>;
// 一个约束T只能是整数类型,并且是有符号的concept
template <typename T>
concept signed_integral = integral<T> && std::is_signed_v<T>;
看不懂
SFINAE
- sfinae 说白了就是一个机制, 当一个模板展开失败的时候, 会尝试用其他的重载进行展开, 而不是直接报错,
- 利用这个特性, 我们可以手工诱导发生 sfinae, 来实现编译器的一个类型判断.
- 常见的做法有 enable_if 和 标签分发.
- if constexp 为我们的这种代码增加了更多的可读性
RAll
RAII(Resource Acquisition Is Initialization)是一种利用对象生命周期来控制程序资源(如内存、文件句柄、网络连接、互斥量等等)的简单技术。
在对象构造时获取资源,接着控制对资源的访问使之在对象的生命周期内始终保持有效,最后在对象析构的时候释放资源。借此,我们实际上把管理一份资源的责任托管给了一个对象。这种做法有两大好处:
- 不需要显式地释放资源。
- 采用这种方式,对象所需的资源在其生命期内始终保持有效。
RAII 机制其实就是在对象构造的时候初始化它所需要的资源,在析构的时候自动释放它持有的资源。
智能指针
- 内存泄漏:裸指针在分配内存后,如果忘记释放或者异常退出,会导致内存泄漏。智能指针可以利用其生命周期,在离开作用域时自动释放内存
- 悬空指针:裸指针在指向的对象被销毁后,仍然保持原来的值,这样就会造成悬空指针。智能指针可以避免这种情况,因为它会跟踪对象的引用计数,当引用计数为零时,就会销毁对象,并将指针置为空
- 多重释放:裸指针在多个地方被使用时,可能会导致同一块内存被多次释放,这样会引发未定义行为。智能指针可以通过独占或共享的方式管理资源的所有权,保证资源只被释放一次。## 使用 std::uniqueptr 管理具备专属所有权的资源
移动一个 std::unique_ptr 会将所有权从源指针移至目标指针(源指针被置空)。 std: :unique_ptr 不允许复制,因为如果复制了一个 std::unique ptr,就会得到两个指涉到同一资源的 std::uniqueptr,而这两者都认为且已拥有(因此应当析构)该资源。因而, std::unique_ptr 是个只移型别。在执行析构操作时,
由非空的 std:: unique_ptr 析构其资源。默认地,资源的析构是通过对 std:: unique ptr 内部的裸指针实施 delete 完成的。
unique_ptr 初始化
正常初始化
unique_ptr<string> p1(new string("Hello World"));
make_unique 初始化
make_unique()传入类型参数的构造方法
最低需要 C++14
匿名对象
unique_ptr<string> p3=unique_ptr<string>(new string("Hello World"));
移动语义初始化
std::unique_ptr<>=std:: move (xx)
释放方法 std::unique_ptr::release 指将智能指针转换为普通指针
注意!注意!注意!这里的释放并不会销毁其指向的对象,而且将其指向的对象释放出去。
MyString ms2 = std::move(ms1); // 调用移动构造函数
MyString ms3;
ms3 = std::move(ms2); // 调用移动赋值运算符
重写删除器
您不一定需要重写一个删除器,但是在一些情况下,您可能需要为 std:: unique_ptr 提供一个自定义的删除器。一些可能的情况是:
- 您想要使用 std:: unique_ptr 管理一个非堆内存的资源,例如一个文件指针、一个套接字或一个映射的内存区域。这些资源不能用 delete 操作符来释放,而需要用特定的函数来关闭或解除映射。例如,如果您想要使用 std:: unique_ptr 管理一个文件指针,您可以这样做 ³:
deleted_unique_ptr<FILE> file ( fopen ("file.txt", "r"), [] (FILE* f) { fclose (f); });
- 您想要在删除一个对象时执行一些额外的操作,例如记录、计数或通知。这些操作可以在删除器中实现,而不需要修改对象的析构函数。例如,如果您想要在删除一个投资对象时记录其信息,您可以这样做 ¹:
auto delInvmt = [] (Investment* pInvestment) { makeLogEntry (pInvestment); delete pInvestment; };
std::unique_ptr<Investment, decltype (delInvmt)> pInv (createInvestment (), delInvmt);
- 您想要使用 std:: unique_ptr 管理一个多态的对象,但是其基类没有虚析构函数。这种情况下,如果您直接使用 std::unique_ptr
<base>来管理一个派生类的对象,可能会导致内存泄漏或未定义行为。为了避免这个问题,您可以为 std:: unique_ptr 提供一个删除器,让它调用正确的析构函数。例如,如果您有一个基类 A 和一个派生类 B,但是 A 没有虚析构函数,您可以这样做 ²:
std::unique_ptr<A, void (*) (A*)> pA (new B (), [] (A* a) { delete static_cast<B*> (a); });
使用 std::shared_ptr 管理具备共享所有权的资源
shared_ptr 采用的是引用计数原理来实现多个 shared_ptr 对象之间共享资源:
shared_ptr 在内部会维护着一份引用计数,用来记录该份资源被几个对象共享。
当一个 shared_ptr 对象被销毁时(调用析构函数),析构函数内就会将该计数减 1。
如果引用计数减为 0 后,则表示自己是最后一个使用该资源的 shared_ptr 对象,必须释放资源。
如果引用计数不是 0,就说明自己还有其他对象在使用,则不能释放该资源,否则其他对象就成为野指针。
引用计数是用来记录资源对象中有多少个指针指向该资源对象。
void ThreadTest() {
auto sh_ptr = std::make_shared<int>(3);
std::thread td([&sh_ptr](){
for (int i = 0; i < 10; ++i) {
std::this_thread::sleep_for(std::chrono::milliseconds(100));
std::cout << *sh_ptr << std::endl;
}
});
td.detach();
std::cout << "main thread over" << std::endl;
}
错误!用引用捕获sptr不会增加引用计数
对于类似 std::shared_ptr 但有可能空悬的指针使用 std::weak_ptr
在定义双向链表或者在二叉树等有多个指针的时候,如果想要将该类型定义成智能指针,那么结构体内的指针需要定义成 weak_ptr 类型的指针,防止循环引用的出现。
tips
- 拷贝构造函数不能使用浅拷贝
- 共享了内存空间
- 析构函数重复释放
- 如果你想在模板内使用 typedef 来创建一个链表,它容纳的对象型别由模板形参指定的话,那你就要给 t ypedef 的名字加一个 typename 前缀
C ++中四种 cast 强制类型转换
c++强类型语言
const_cast:
1、去除 const 属性,将只读变为只读写
2、针对常量指针、常量引用和常量对象
const char *p;
char *p1 = const_cast<char*>(p);
static_cast:
- 内置数据类型之间的转换,int 转 double,char 转 int
- 基类指针与派生类之间的转换,只能转换有继承或派生关系的类。用于类层次结构之间基类和派生类指针和引用之间的转换,进行向上转型是安全的,但是进行向下转型是不安全的,但是是可以转换的; 向上转型:我们知道基类的引用和指针都可以指向派生类的对象,那么将派生类的指针或者引用强转为基类的指针或者引用,那么这就是向上转型,也就是向父类转; 向下转型:向下转型就和向上转型相反,它是将父类的指针或者引用,强制转换为子类的指针或者引用
- 把 void 类型指针转换为目标类型的指针
- 任何类型的表达式转化为 void 类型
// 整形转浮点型
int a = 10;
double b = static_cast<double>a;
//基类指针转派生类
class A{}; class B : public A{};
A *pA = new A;
B *pB = static_cast<B*>(pA);
dynamic_cast:
dynamic_cast 是运行时处理的,运行时进行类型检查,其他三种是编译时处理的
不能用于内置数据类型之间的转换
dynamic_cast 在进行上行转换时和 static_cast 效果是一样的,但是进行下行转换时会进行类型检查,比 static_cast 更加安全,下行转换是否成功取决于转换对象的实际类型与目标类型是否相同
要求基类必须具有虚函数,否则编译不通过
若转换成功,返回的是指向目标的指针或引用,不成功返回 NULL
dynamic_cast 还可以用于检查一个指针或引用是否指向或引用某个特定类型的对象。
Derived derived;
Base* base_ptr = &derived;
// 检查是否指向 Derived 类型的对象
if (dynamic_cast<Derived*>(base_ptr)) {
std::cout << "base_ptr points to a Derived object." << std::endl;
} else {
std::cout << "base_ptr does not point to a Derived object." << std::endl;
}
reinterpret_cast:
可以将一个类型的指针转换为其它任意类型的指针,也可以用在指针和整形数据之间的转换它是很危险的,如果我们没有使用它的充分理由,那么就不要使用它
为运算对象的位模式提供较低层次上的重新解释
用于底层的强制转换,依赖于机器,一般使用较少

函数类型和函数指针类型
void *(*)(void *) $\rightarrow$ 参数
$\downarrow$ $\downarrow$
返回值 函数指针
函数类型(Function Type):函数类型是用来描述函数的返回类型和参数列表的。它用于定义函数的原型或签名,但不代表函数的实际存储位置。函数类型是编译器用来检查函数调用是否正确匹配的一种方式。
例如,void() 表示一个没有参数并返回 void 的函数类型,int(int, int) 表示一个接受两个整数参数并返回整数的函数类型。
函数指针类型(Function Pointer Type):函数指针类型是用来指向函数的指针类型。它指示函数的存储位置,允许你在程序中通过指针来调用函数。
例如,void(*)() 是一个指向没有参数并返回 void 的函数的指针类型,int(*)(int, int) 是一个指向接受两个整数参数并返回整数的函数的指针类型。
在 C++ 中,函数名确实可以被视为函数指针,但有一些微妙的差别:
- 函数名作为函数指针:在大多数情况下,当你使用函数名时,它会自动转换为一个指向函数的指针,指向函数代码的起始位置。例如:
void (*funcPtr)() = myFunction;,其中myFunction是一个函数名,但在赋值给funcPtr时会自动转换为函数指针。 - 函数指针显式声明:你也可以显式地声明函数指针,这在涉及更复杂的指针用法时可能更有用。例如:
void (*funcPtr)() = &myFunction;,这里使用了&来显式获取函数的地址。
总结:函数类型用于描述函数的签名,而函数指针类型用于指向函数的指针,可以通过指针调用函数。函数名在大多数情况下会自动转换为函数指针,但在需要更多控制的情况下,你可以显式声明函数指针。
匿名函数
形式
[capture](parameters) ->return-type{body}
[捕获列表](参数列表) ->返回类型-
capture:捕获列表
- [] //捕获列表为空。在函数内无法使用外部变量。
- [a] //捕获列表为按值传递形式。在函数内仅能使用传递的变量值,无法改变变量。值在匿名函数生成时便已经确定,后续修改不会影响函数内的变量值。
- [&a] //按应用传递。可改变变量。
lambda 不是函数指针类型,可以通过 function 来封装
闭包捕获的变量默认是只读的,如果需要修改捕获的变量,可以给 lambda 加上 mutable 修饰,就加在 () 后面。
int x = 10;
auto lambda = [x] () mutable {
return x++; // 编译通过✅
};
注意:由于使用了值捕获,lambda 修改的是在他创建时对 x 的一份拷贝,外面的 x 不会改变!修改的只是拷贝的变量
std::function<bool(T)> f 参数类型
[](int t) -> bool 传入
反向迭代:vector
for (auto i=L.rebgin (); i!=L.rend (); i++)
继承(Derived)

继承的格式:
class 新类的名字:继承方式 继承类的名字{ };
基类和派生类
三种赋值
1:= 符号
父类=子类//切片原则
2:引用
&父类=子类
3:指针 *父类=&子类
子类默认的成员函数
构造函数
编译器会默认先调用父类的构造函数,再调用子类的构造函数
class human {
public:
human(string name = "小明")//先调用:父类默认构造调用一个print打印name,如果没有初始化,那么必须在子类给父类构造赋值
:_name(name)
{
cout << name << endl;
}
protected:
string _name;
};
class student :public human {//后调用:子类默认构造调用一个print打印name和age
public:
student(string name,int age)
:_age(age)
{
cout << name << endl<<age<<endl;
}
protected:
int _age;
改 $\downarrow$
student(string name,int age)
:_age(age)
, human(name)//新增,子类以自己的name给父类的析构中的name赋值,age和name的顺序随意变动
注意:C++没有base,所以直接调用
- 复制构造,复制赋值,这两种复制操作彼此独立,(已经被委员会声明为废弃特性)声明一个并不会阻止编译器声明另外一个。如你声明了一个复制构造函数,并撰写了需要用到复制赋值函数的地方,则编译器会默认生成之。
- 移动构造,移动赋值,这两种移动操作彼此不独立,声明了一个就会阻止编译器声明另外一个。
- 一旦声明了复制操作,则不会再生成移动操作(说明复制很可能与按成员复制不同,很可能移动也是如此)
- 一旦声明了移动操作,则不会再生成复制操作(只可移对象)
移动函数只有满足下面,才会被默认生成:
- 该类未声明任何复制操作
- 该类未声明任何移动操作
- 该类未声明任何析构函数
析构函数
析构函数和构造函数相反,编译器默认先调用子类的析构函数,再调用父类的析构函数。
千万不要在子类中调用父类的析构
如果是指针类型,那么同一块区域被析构两次就会造成野指针的问题。
也有可能析构不完
赋值运算符重载
子类的 operator=必须要显式调用父类的 operator=完成父类的赋值。
因为子类和父类的运算符,编译器默认给与了同一个名字,所以构成了隐藏,所以每次调用=这个赋值运算符都会一直调用子类,会造成循环,所以这里的赋值要直接修饰限定父类
菱形继承
错误代码
class A {
public:
string name;
};
class B :public A {
public:
int age;
};
class C :public A {
public:
string sex;
};
class D :public B, public C {
public:
int id;
};
int main()
{
D student;
student.name = "小明";
student.age = 18;
student.sex = "男";
student.id = 666;
return 0;
}
解决方法一:
加修饰限定
student.B::name = "小明";
解决方法二:
虚继承:在继承方式前加上 virtual。
class B :virtual public A {
public:
int age;
};
class C :virtual public A {
public:
string sex;
};
std:: function 基本用法
语法
std::function<return_type(parameter_types)> var_name;
其中,return_type 是函数返回值类型,parameter_types 是函数参数类型。
function 对象可以像普通函数一样调用,并且可以使用 bool 类型的运算符检查调用对象是否为空: if (var_name)
进阶用法
std:: function 可以存储智能指针,避免内存泄漏:
std::function<int (int, int)> add = std::make_shared<int (*)(int, int)>([](int a, int b) { return a + b; });
std::function<void()> fn1 = std::bind(test1);
std::function<int(int)> fn2 = std::bind(test2, std::placeholders::_1);
std::function<int(int, int)> fn3 = std::bind(test3,std::placeholders::_1, std::placeholders::_2);
右值引用、语义移动
移动必须不抛出异常,即使用 noexcept
Site Unreachable
- “使用右值引用”本身并不对原对象做任何操作,只是给使用者指明“这是个右值”,可以被移动。
- “可被移动”不是说内容可以在内存上移动到别的地方,而是“可以放在其他对象名下”。
- “万能引用”并不是特别的约定,而是模板实参+引用折叠的结果。
- “移动语义”的实现是逐级分解的过程,最终要落实到“移动构造函数”和“移动赋值操作符”上。(需要为类定义
- “复制消除”一开始是种优化,但 C++17 的值类别让它变得自然了,这也是我们目前的值类别系统。
- 右值引用使用&&声明(这样就可以重载了),只能绑定到一个即将被销毁的临时对象或者 std:: move(生成一个右值表达式,表明可被移动) 标记的对象上。
- 产生一个值的右值引用,或将它作为右值引用去使用,并不会对它本身产生任何影响。只是让开发者可以便捷的用以右值引用为参数的函数重载,去实现如我们上面所做的,一些更高效的重载
值类别
形式化定义(错的)
- 拥有自身“地址”的值被称为左值
- 不拥有“地址”的值被称为右值
开始 - 不可被移动的表达式称为左值
- 可以被移动的表达式称为右值
C++11 - 拥有身份且不可被移动的表达式被称作 左值 (lvalue) 表达式;
- 拥有身份且可被移动的表达式被称作 亡值 (xvalue) 表达式;
- 不拥有身份且可被移动的表达式被称作 纯右值 (prvalue) 表达式;
- 不拥有身份且不可被移动的表达式无法使用 。
- 左值和亡值统称为泛左值——可取地址;
- 纯右值和亡值统称为右值——可被移动。
移动
移动的实质并不是“将内容移动到另一个地方”,而是“转移了所有权”。
原
A tmp = factory.get();
con.push_back(tmp);
C 语言风格
A* tmp = factory.get();
con.push_back(tmp);
语义移动风格
A tmp = factory.get(); // 假设factory.get()返回一个右值引用
con.push_back(std::move(tmp)); // 使用std::move将tmp转换为右值引用,并调用容器的移动版本的push_back函数
----
get实现
1、// 假设A有一个带参数的构造函数
A factory.get(int x) {
A tmp(x); // 创建一个局部对象
return std::move(tmp); // 将它转换为右值引用返回
}
2、// 假设A有一个带参数的构造函数
A factory.get(int x) {
return A(x); // 直接返回一个匿名对象,产生一个右值引用
}
3、// 假设A有一个默认构造函数
A* factory.get() {
A* tmp = new A(); // 动态分配一个对象,并返回它的指针
return std::move(tmp); // 将指针转换为右值引用返回
}
好处
- 你不需要担心 tmp 指向的对象在添加到容器后是否有效,因为移动操作会将 tmp 中的资源转移给容器中的对象,而 tmp 本身会变成一个空对象。(防止内存泄漏,悬空指针)
- 你不需要担心 tmp 指向的对象是否被其他地方修改或者删除,因为移动操作会断开 tmp 与原来对象的关联,而且你也不再需要使用 tmp 了。(防止数据不一致或异常)
- 你不需要担心容器中存储的是什么类型,因为移动操作会保证容器中存储的是 A 类型的对象,而不是指针。
使用 C++的一个优点就是可以使用各种引用去代替指针,以规避繁琐且容易出错的手法。以上手法不仅繁琐,也不满足 C++的 RAII 原则。
PAII 全称为 Resource Acquisition Is Initialization,即资源获取即初始化。
RAII 是 C++语法体系中的一种合理管理资源避免出现内存泄漏的常用方法。以对象管理资源,利用的就是 C++构造的对象最终会被对象的析构函数销毁的原则。
完美转发
=引用折叠+万能引用+std::forword
意义在于能够根据参数类型调用到不同&,&&入参的函数
右值引用是 C++11 引入的一种新的引用类型,它可以绑定到临时对象或将要销毁的对象,从而实现资源的转移而非复制。右值引用的应用场景有以下几种:
- 移动语义:当一个对象被赋值或传递给另一个对象时,通常会调用拷贝构造函数或拷贝赋值运算符,这会导致资源的复制,如内存分配、文件打开等。如果原对象是一个临时对象或即将被销毁的对象,那么复制资源是没有必要的,可以直接将资源转移给新对象,从而提高效率。为了实现移动语义,C++11 引入了移动构造函数和移动赋值运算符,它们的参数都是右值引用类型。例如:
class String {
public:
// 普通构造函数
String(const char* str) {
if (str == nullptr) {
data_ = new char[1];
*data_ = '\0';
} else {
int len = strlen(str);
data_ = new char[len + 1];
strcpy(data_, str);
}
}
// 拷贝构造函数
String(const String& rhs) {
int len = strlen(rhs.data_);
data_ = new char[len + 1];
strcpy(data_, rhs.data_);
}
区别是参数是构造的类型还是类类型
// 移动构造函数
String(String&& rhs) noexcept : data_(rhs.data_) {
rhs.data_ = nullptr;
}
// 拷贝赋值运算符
String& operator=(const String& rhs) {
if (this != &rhs) {
delete[] data_;
int len = strlen(rhs.data_);
data_ = new char[len + 1];
strcpy(data_, rhs.data_);
}
return *this;
}
// 移动赋值运算符
String& operator=(String&& rhs) noexcept {
if (this != &rhs) {
delete[] data_;
data_ = rhs.data_;
rhs.data_ = nullptr;
}
return *this;
}
~String() {
delete[] data_;
}
private:
char* data_;
};
在上面的代码中,String类是一个简单的字符串类,它有一个 char*类型的成员变量 data_,用来存储字符串数据。当我们使用普通构造函数创建一个 String对象时,会在堆上分配一块内存,并将字符串拷贝到这块内存中。当我们使用拷贝构造函数或拷贝赋值运算符将一个 String对象赋值或传递给另一个 String对象时,也会在堆上分配一块新的内存,并将原对象的字符串拷贝到这块内存中。这样做会增加内存分配和释放的开销,以及字符串拷贝的开销。
为了避免这些开销,我们可以使用移动构造函数和移动赋值运算符,它们的参数都是右值引用类型。当我们将一个右值(如临时对象或即将被销毁的对象)赋值或传递给另一个 String对象时,就会调用移动构造函数或移动赋值运算符,它们不会在堆上分配新的内存,而是直接将原对象的 data_指针转移给新对象,并将原对象的 data_指针置为 nullptr。这样做就避免了资源的复制,只进行了资源的转移。
String s1("hello");
String s2 = std::move(s1); // 调用移动构造函数
s2 = std::move(s1); // 调用移动赋值运算符
这一段不能改成 String& operator=(String& rhs),因为这样会破坏右值引用的移动语义。如果参数是左值引用,那么当我们将一个右值赋值给一个 String对象时,就会调用拷贝赋值运算符,而不是移动赋值运算符,这样就会造成资源的复制,而不是转移。例如:
在上面的代码中,std::move可以将一个左值转换为一个右值引用,从而触发移动语义。如果我们将移动赋值运算符的参数改为左值引用,那么第三行的代码就会调用拷贝赋值运算符,而不是移动赋值运算符,这样就会在堆上分配新的内存,并将 s1的字符串拷贝到这块内存中,然后再将 s2的原来的内存释放。这样做就增加了内存分配和释放的开销,以及字符串拷贝的开销。而如果我们保持参数是右值引用,那么第三行的代码就会调用移动赋值运算符,它不会在堆上分配新的内存,而是直接将 s1的 data_指针转移给 s2,并将 s1的 data_指针置为 nullptr。这样做就避免了资源的复制,只进行了资源的转移
- 完美转发:完美转发是指在函数模板中,保持参数的类型和值类别不变地转发给另一个函数。为了实现完美转发,C++11 引入了两个新的关键字:
decltype和std::forward。decltype可以用来推断表达式的类型,而std::forward可以用来保持参数的值类别。例如:
void g(int& x) {
std::cout << "g(int&): " << x << std::endl;
}
void g(int&& x) {
std::cout << "g(int&&): " << x << std::endl;
}
template<typename T>
void f(T&& x) {
g(std::forward<T>(x)); // 完美转发
}
int main() {
int a = 10;
f(a); // 调用f(int&),输出g(int&): 10
f(20); // 调用f(int&&),输出g(int&&): 20
return 0;
}
- 在上面的代码中,
g函数有两个重载,一个参数是左值引用,一个参数是右值引用。f函数是一个函数模板,它的参数是一个万能引用(universal reference),也就是可以绑定到左值或右值的右值引用。当我们传递一个左值给f函数时,它的参数类型推断为左值引用,当我们传递一个右值给f函数时,它的参数类型推断为右值引用。在f函数中,我们使用std::forward<T>来保持参数的值类别不变地转发给g函数,这就是完美转发。这样做可以避免不必要的拷贝或移动,以及重载解析的错误。 - C++11 右值引用详解
对 auto&&型别的形参使用 decltype, 以 std: : forward 之。
构造函数
不能是虚函数
从存储空间角度,虚函数对应一个指向 vtable 虚函数表的指针,这大家都知道,可是这个指向 vtable 的指针其实是存储在对象的内存空间的。问题出来了,如果构造函数是虚的,就需要通过 vtable 来调用,可是对象还没有实例化,也就是内存空间还没有,怎么找 vtable 呢?所以构造函数不能是虚函数。 从使用角度,虚函数主要用于在信息不全的情况下,能使重载的函数得到对应的调用。构造函数本身就是要初始化实例,那使用虚函数也没有实际意义呀。所以构造函数没有必要是虚函数。虚函数的作用在于通过父类的指针或者引用来调用它的时候能够变成调用子类的那个成员函数。而构造函数是在创建对象时自动调用的,不可能通过父类的指针或者引用去调用,因此也就规定构造函数不能是虚函数。
析构函数
构造函数决不能是虚函数,析构函数最好用作虚函数.
将可能会被继承的父类的析构函数设置为虚函数,可以保证当我们 new 一个子类,然后使用基类指针指向该子类对象,释放基类指针时可以释放掉子类的空间,防止内存泄漏。
C++默认的析构函数不是虚函数是因为虚函数需要额外的虚函数表和虚表指针,占用额外的内存。而对于不会被继承的类来说,其析构函数如果是虚函数,就会浪费内存。因此 C++默认的析构函数不是虚函数,而是只有当需要当作父类时,设置为虚函数。
作用
析构函数与构造函数对应,当对象结束其生命周期,如对象所在的函数已调用完毕时,系统会自动执行析构函数。
特点
析构函数名也应与类名相同,只是在函数名前面加一个位取反符~,以区别于构造函数。它不能带任何参数,也没有返回值(包括 void 类型)。只能有一个析构函数,不能重载。
如果用户没有编写析构函数,编译系统会自动生成一个缺省的析构函数(即使自定义了析构函数,编译器也总是会为我们合成一个析构函数,并且如果自定义了析构函数,编译器在执行时会先调用自定义的析构函数再调用合成的析构函数),它也不进行任何操作。所以许多简单的类中没有用显式的析构函数。
如果一个类中有指针,且在使用的过程中动态的申请了内存,那么最好显示构造析构函数在销毁类之前,释放掉申请的内存空间,避免内存泄漏。
类析构顺序:
1)派生类本身的析构函数;
2)对象成员析构函数;
3)基类析构函数。
静态函数和虚函数的区别
静态函数在编译的时候就已经确定运行时机,虚函数在运行的时候动态绑定。虚函数因为用了虚函数表机制,调用的时候会增加一次内存开销
虚函数和多态
多态的实现主要分为静态多态和动态多态,静态多态主要是重载,在编译的时候就已经确定;动态多态是用虚函数机制实现的,在运行期间动态绑定。举个例子:一个父类类型的指针指向一个子类对象时候,使用父类的指针去调用子类中重写了的父类中的虚函数的时候,会调用子类重写过后的函数,在父类中声明为加了 virtual 关键字的函数,在子类中重写时候不需要加 virtual 也是虚函数。
虚函数的实现:在有虚函数的类中,类的最开始部分是一个虚函数表的指针,这个指针指向一个虚函数表,表中放了虚函数的地址,实际的虚函数在代码段 (. text)中。当子类继承了父类的时候也会继承其虚函数表,当子类重写父类中虚函数时候,会将其继承到的虚函数表中的地址替换为重新写的函数地址。使用了虚函数,会增加访问内存开销,降低效率。
纯虚函数(Pure Virtual Function)和虚函数(Virtual Function)是 C++中用于实现多态性的重要概念。它们在语法和行为上有一些区别,同时也有一些共同点。
区别:
- 定义和实现:纯虚函数是在基类中声明但没有提供实现的函数,它以
= 0结尾。派生类必须提供对纯虚函数的实现。虚函数是在基类中声明并提供默认实现的函数,它可以被派生类重写。 - 抽象类:如果一个类中包含至少一个纯虚函数,该类就是抽象类,不能实例化对象。派生类必须实现所有纯虚函数才能被实例化。虚函数没有这个限制,可以在基类中提供默认实现。
- 函数调用机制:纯虚函数通过函数指针的形式实现动态绑定(运行时多态),派生类根据实际类型调用相应的函数。虚函数通过虚函数表(vtable)实现动态绑定,通过基类指针或引用调用函数时,根据指针或引用的静态类型确定调用哪个函数。
共同点:
- 多态性:纯虚函数和虚函数都用于实现多态性,在基类指针或引用上调用函数时,可以根据对象的实际类型调用相应的函数。
- 关键字:纯虚函数使用关键字
virtual和= 0声明。虚函数使用关键字virtual声明。
关于 override 关键字,它用于在派生类中指示对基类虚函数的重写。在 C++11 及以后的标准中,如果派生类中的函数与基类中的虚函数具有相同的名称和签名,并且希望将其作为重写,可以使用 override 关键字显式标记。这样做的好处是可以提供编译器级别的检查,确保正确地重写了基类的虚函数。
使用 override 关键字的语法如下:
class Derived : public Base {
public:
void function() override {
// 函数实现
}
};
在派生类中重写虚函数时,建议使用 override 关键字,以提高代码的可读性和可维护性。然而,对于纯虚函数,不需要使用 override 关键字,因为它们在派生类中必须进行重写,否则编译器会报错。
ifndef
ifndef 可以根据是否已经定义了一个变量来进行分支选择,其作用是:
1. 防止头文件的重复包含和编译;
#ifndef<标识>
#define<标识>
...
#endif<标识>
假如有一个 C 源文件(如 sourcefile. cpp),它包含两个头文件(如 headfile_1. h 和 headfile_2. h),而头文件 headfile_2. h 又包含了 headfile_1. h,则最终的效果是该源文件包含了两次 headfile_1. h。如果你在头文件里定义了结构体或者类类型,那么问题来了,编译时将会报重复定义的错误。
eg:
headfile_1. h
#include <iostream>
class CTest_1 {
CTest_1() {
//do something,eg:init;
}
~CTest_1() {
//do something ,eg:free;
}
void PrintScreen()
{
std::cout << "this is Class CTest_1!" << std::endl;
}
};
headfile_2. h
#include <iostream>
class CTest_2 {
CTest_2() {
//do something,eg:init;
}
~CTest_2() {
//do something ,eg:free;
}
void PrintScreen()
{
std::cout << "this is Class CTest_1!" << std::endl;
}
};
sourcefile. cpp
#include <iostream>
#include "headfile_1.h"
#include "headfile_2.h"
int main()
{
return 0;
}
改进:
#ifndef _HEADFILE_1_H
#define _HEADFILE_1_H
#include <iostream>
class CTest_1 {
CTest_1() {
//do something,eg:init;
}
~CTest_1() {
//do something ,eg:free;
}
void PrintScreen()
{
std::cout << "this is Class CTest_1!" << std::endl;
}
};
#endif //end of _HEADFILE_1_H
当第一次包含 headfile_1. h 时,由于没有定义_HEADFILE_1_H,条件为真,这样就会执行#ifndef _HEADFILE_1_H 和#endif 之间的代码;当第二次包含 headfile_1. h 时,前面一次已经定义了_HEADFILE_1_H,条件为假,#ifndef _HEADFILE_1_H 和#endif 之间的代码也就不会再次被包含,这样就避免了重定义。
2. 便于程序的调试和移植;
在调试程序时,常常需要对程序中的内容进行选择性地编译,即可以根据一定的条件选择是否编译。
- 当“标识符”没有由#define 定义过,则编译“程序段 1”,否则编译“程序段 2”。
#ifndef 标识符
程序段 1
#else
程序段 2
#endif
- 当“标识符”没有由#define 定义过,则编译“程序段 1”,否则编译“程序段 2”。
#ifndef 标识符
#define 标识符
程序段 1
#else
程序段 2
#endif
模板
template<typename T, int MAXSIZE>
class Stack
{
public:
Stack():idx(0){}
bool empty() const { return idx == 0;}
bool full() const { return idx == MAXSIZE;}
void push(const T&);
void pop();
T& top();
const T& top() const;
private:
int idx;
T elems[MAXSIZE];
}
变参数模板
template<typename... _Args>
void emplace_front(_Args&&... __args);
函数
auto func(agrs)->返回值{
}
构造函数析构函数可否抛出异常
C++只会析构已经完成的对象,对象只有在其构造函数执行完毕才算是完全构造妥当。在构造函数中发生异常,控制权转出构造函数之外。因此,在对象 b 的析构函数中发生异常,对象 b 的析构函数不会被调用。因此会造成内存泄漏。
用 auto_ptr 对象来取代指针类成员,便对构造函数做了强化,免除了抛出异常时发生资源泄漏的危机,不再选哟在析构函数中手动释放资源。
volatile
标准 C++ 的 volatile 几乎只在一种情况下有用:作为驱动开发者,需要操作映射到外设 I/O 的内存。对于绝大部分程序员而言,用不到、也不应该使用 volatile。
异常安全
异常安全是指程序在发生异常时仍能保持正确工作的状态。通常异常安全可以分为四个等级。
- 保证不抛出异常,此时自然不存在异常带来的错误。
- 强异常安全,指如果一个操作发生异常,则它不会产生任何副作用,系统保持这个操作前的一切状态。典型的,std:: vector 等容器提供强异常安全保证。
- 基本异常安全,指发生异常不会使对象处于不合法的状态(但原值可能改变)、也不会发生资源泄露。
- 无异常安全。例如,发生异常前动态申请了内存、异常处理后未释放,就产生了资源泄露;修改某个值,改了一半抛出了异常,就产生了值的错误等等。
程序中想要保证强异常安全是非常困难的,但如果使用异常,应尽可能做到基本异常安全。RAII 有助于保证这一点。
private,public,protected 区别
第一:private, public, protected 访问修饰符
- private:只能由 1.该类中的函数、2.友元函数访问。不能被任何其他访问,该类的对象也不能访问。
- protected:可以被 1.该类中的函数、2.子类的函数、3.其友元函数访问。但不能被该类的对象访问。
- public:可以被 1.该类中的函数、2.子类的函数、3.其友元函数访问,也可以由 4.该类的对象访问。
注:友元函数包括 3 种:
设为友元的普通的非成员函数;
设为友元的其他类的成员函数;
设为友元类中的所有成员函数。
friend关键字的作用是在类定义内部声明一个非成员函数或者外部类作为友元函数或友元类,从而使得该函数或类能够访问类的私有成员。
在这个特定的情况下,我们希望将 operator>>函数声明为 Big类的友元函数,以便在函数内部直接访问 Big类的私有成员 number。如果没有使用 friend关键字修饰,那么 operator>>函数将无法访问 Big类的私有成员,从而无法将输入的字符串转换为 number数组。
通过使用 friend关键字修饰,我们将 operator>>函数声明为 Big类的友元函数,使得该函数能够在类的上下文中访问私有成员,实现字符串到 number数组的转换。
第二:类继承权限改变
有 public, protected, private 三种继承方式,它们相应地改变了基类成员的访问属性。
- 1.public 继承:基类 public 成员,protected 成员,private 成员的访问属性在派生类中分别变成:public, protected, private
- 2.protected 继承:基类 public 成员,protected 成员,private 成员的访问属性在派生类中分别变成:protected, protected, private
- 3.private 继承:基类 public 成员,protected 成员,private 成员的访问属性在派生类中分别变成:private, private, private
友元修饰函数或者类,可以访问私有变量
constexpr 函数
constexpr 还能定义一个常量表达式函数,即 constexpr 函数,常量表达式函数的返回值可以在编译
阶段就计算出来。不过在定义常量表示函数的时候,我们会遇到更多的约束规则[C++14]:
1.函数体允许声明变量,除了没有初始化、static 和 thread_local 变量。
2.函数允许出现 if 和 switch 语句,不能使用 goto 语句。
3.函数允许所有的循环语句,包括 for、while、do-while。
4.函数可以修改生命周期和常量表达式相同的对象。
5.函数的返回值可以声明为 void。
6.constexpr 声明的成员函数不再具有 const 属性。
另外还有些不允许的:
a. 它必须非虚; [c++20 前]
b. 它的函数体不能是函数 try 块; [c++20 前]
c. 它不能是协程; [c++20 起]
d. 对于构造函数与析构函数 [C++20 起],该类必须无虚基类
e. 它的返回类型(如果存在)和每个参数都必须是字面类型 (LiteralType)
f. 至少存在一组实参值,使得函数的一个调用为核心常量表达式的被求值的子表达式(对于构造函 数为足以用于常量初始化器) (C++14 起)。不要求诊断是否违反这点。
传入实参为非常量表达式时,退化为普通函数
constexpr 函数的理解:
(1).constexpr函数可以用在要求编译期常量的语境中。在这样的语境中,若你传给一个constexpr函数的实参值是在编译期已知的,则结果也会在编译期间计算出来。如果任何一个实参值在编译期未知,则你的代码将无法通过编译。
(2).在调用constexpr函数时,若传入的值有一个或多个在编译期未知,则它的运作方式和普通函数无异,亦即它也是在运行期执行结果的计算。这意味着,如果函数执行的是同样的操作,仅仅应用的语境一个是要求编译期常量的,一个是用于所有其它值的话,那就不必写两个函数。constexpr函数就可以同时满足所有需求。
constexpr函数仅限于传入和返回字面类型(literal type),意思就是这样的类型能够持有编译期可以决议的值。在C++11中,所有的内建类型,除了void,都符合这个条件。但是用户自定义类型同样可能也是字面类型,因为它的构造函数和其它成员函数可能也是constexpr函数。
C++中,if constexpr 是 C++17 引入的新特性,它可以在编译时进行条件判断,从而避免生成多余的运行时分支 。相比于普通的 if 语句,if constexpr 的优点是可以简化代码的编写,提高程序的效率和可读性 。if constexpr 的语法如下:
if constexpr (condition) {
// 编译时执行
} else {
// 编译时忽略
}
其中,condition 必须是一个编译时常量表达式,例如模板参数的值或类型。如果 condition 为 true,那么 if constexpr 语句块中的代码会被编译,否则会被忽略。同理,如果 condition 为 false,那么 else 语句块中的代码会被编译,否则会被忽略。
if constexpr 的一个常见用途是在泛型编程中根据模板参数的类型进行不同的处理。例如,下面的代码定义了一个将数值转换为字符串的函数:
template <typename T>
auto to_string(T t) {
if constexpr(std::is_integral<T>::value) {
return std::to_string(t);
} else {
return t;
}
}
这个函数可以接受任何类型的参数 t,如果 t 是整数类型,那么调用 std::to_string 函数将其转换为字符串;如果 t 不是整数类型,那么直接返回 t。这样就避免了使用 std::enable_if 或者重载函数来实现相同的功能
if constexpr 只能用在编译时可以确定条件的情况下,如果条件需要在运行时才能确定,那么就必须使用普通的 if 语句。例如,下面的代码定义了一个根据用户输入进行不同操作的函数:
void do_something() {
int n;
std::cin >> n;
if (n > 0) {
// do something positive
} else {
// do something negative
}
}
这个函数不能使用 if constexpr 来替换 if 语句,因为 n 的值只有在运行时才能获取。如果使用 if constexpr,那么编译器会报错,提示 n 不是一个常量表达式。
总之,if constexpr 是 C++17 中提供的一种按条件编译的语法糖,它可以让我们在编译时根据不同的情况执行不同的代码段,从而提高程序的效率和可读性。它只能用在条件是编译时常量表达式的情况下,否则就必须使用普通的 if 语句。
枚举类
降低命名空间污染
enum Color{black,white,red}; //black、white、red 作用域和 color 作用域相同
auto white = false; //错误,white 已经被声明过了
enum class Color{black,white,red};
Color c = Color::red;
if(c < 14.5) //错误,不能将枚举类和 double 进行比较
{
auto factors = primeFactors(c); //错误,Color 不能转化为 size_t 型别
}
避免隐式转换
限定作用域的枚举型别不允许发生任何隐式转换。如果非要转换,按就只能使用 static_cast 进行强制转换。
enum class Color{black,white,red};
Color c = Color::red;
if(c < 14.5) //错误,不能将枚举类和 double 进行比较
{
auto factors = primeFactors(c); //错误,Color 不能转化为 size_t 型别
}
可以前置声明
类中的 static
#include <iostream>
using namespace std;
class CMyClass {
public:
static int m_i;
};
int CMyClass::m_i = 0;
CMyClass myObject1;
CMyClass myObject2;
int main() {
cout << myObject1.m_i << endl;
cout << myObject2.m_i << endl;
myObject1.m_i = 1;
cout << myObject1.m_i << endl;
cout << myObject2.m_i << endl;
myObject2.m_i = 2;
cout << myObject1.m_i << endl;
cout << myObject2.m_i << endl;
CMyClass::m_i = 3;
cout << myObject1.m_i << endl;
cout << myObject2.m_i << endl;
}
template<typename T>
void print(T & t){
std::cout << "Lvalue ref" << std::endl;
}
template<typename T>
void print(T && t){
std::cout << "Rvalue ref" << std::endl;
}
template<typename T>
void testForward(T && v){
print(v);//v此时已经是个左值了,永远调用左值版本的print
print(std::forward<T>(v)); //本文的重点
print(std::move(v)); //永远调用右值版本的print
std::cout << "======================" << std::endl;
}
int main(int argc, char * argv[])
{
int x = 1;
testForward(x); //实参为左值
testForward(std::move(x)); //实参为右值
}
sentry 是一个 C++中的模式,它利用了对象的构造函数和析构函数在特定时机被调用的特性,来实现一些特定的功能。例如,可以用 sentry 对象来实现资源获取即初始化(RAII)的原则,也就是在对象的构造函数中获取资源,在对象的析构函数中释放资源。这样可以保证在正常或异常的情况下,资源都能被正确地管理 ¹。
sentry 对象也可以用来在一个函数的开始和结束时执行一些操作,类似于 Java 中的 finally 语句。例如,可以用 sentry 对象来实现锁的自动加锁和解锁,或者日志的自动记录和关闭 ¹。
sentry 对象还可以用来在一个类的构造函数和析构函数中执行一些操作,类似于 Python 中的enter和exit方法。例如,可以用 sentry 对象来实现流的状态检查和恢复,或者异常处理和传播 ²。
在 C++标准库中,有一个类叫做 basic_ostream:: sentry,它就是一个 sentry 对象的例子。它用于在每个输出操作之前和之后执行一些操作,比如检查流的状态,刷新绑定的流,跳过空白字符等 ³。你可以在查看更多关于这个类的信息。
仿函数
背景
对于一些函数参数不满足条件,比如 count_if 第三个参数只有一个参数的函数指针,返回值是 bool 类型。
//统计长度小于len的string的个数
bool LengthIsLessThanFive(const string& str, int len) {
return str.length()< len;
}
count_if(vec.begin(), vec.end(), LengthIsLessThanFive);//会报错
如果使用全局变量,1、容易出错2、没有可拓展性
struct ShorterThan {
public:
explicit ShorterThan(int maxLength) : length(maxLength) {}
bool operator() (const string& str) const {
return str.length() < length;
}
private:
const int length;
};
explicit :可以阻止不应该允许的经过转换构造函数进行的隐式转换的发生
eg:
ShorterThan t1(13) √
ShorterThan t2=13 ×
int main()
{
vector<string> vec = { "asdd","asddsa","dssa","asd" };
int res3 = count_if(vec.begin(), vec.end(), ShorterThan(5));
cout << res3 << endl;
system("pause");
return 0;
}
template<typename T> struct comp
{
bool operator()(T in1, T in2) const
{
return (in1 > in2);
}
};
int main()
{
comp<int> m_comp_objext;
cout << m_comp_objext(6, 3) << endl; //一、使用对象调用
cout << comp<int>()(6, 3) << endl; //二、使用临时对象
return 0;
}
仿函数(functor)又称为函数对象(function object)。是一个能行使函数功能的类。仿函数的语法几乎和我们普通的函数调用一样,不过作为仿函数的类,都必须重载 operator()运算符
重载和使用模板特化区别
(1)如果使用普通重载函数,那么不管是否发生实际的函数调用,都会在目标文件中生成该函数的二进制代码。而如果使用模板的特化版本,除非发生函数调用,否则不会在目标文件中包含特化模板函数的二进制代码。这符合函数模板的“惰性实例化”准则。
(2)如果使用普通重载函数,那么在分离编译模式下,需要在各个源文件中包含重载函数的申明,否则在某些源文件中就会使用模板函数,而不是重载函数。
偏特化
个数偏特化
template<> 括号中存留的参数是依然可以任意填的参数。
范围偏特化
这种情况的 template<>中还是要填上原有的大类型,且 const T*属于T*不属于const T
template<typename T>
struct A
{
void func()
{
cout << "泛化版本" << endl;
}
};
template<typename T>
struct A<const T>
{
void func()
{
cout << "const T版本" << endl;
}
};
template<typename T>
struct A<T*>
{
void func()
{
cout << "T*版本" << endl;
}
};
template<typename T>
struct A<T&>
{
void func()
{
cout << "T&版本" << endl;
}
};
template<typename T>
struct A<T&&>
{
void func()
{
cout << "T&&版本" << endl;
}
};
具体来说,`T`在函数模板`CountArgs`的定义中用于两个目的:
1. 在基本情况中,当没有参数时,我们使用`T`作为函数参数类型,表示没有参数需要处理。
2. 在递归情况中,我们使用`T`作为函数参数类型,表示第一个参数的类型,并通过递归调用`CountArgs(args...)`来处理剩余的参数。
// 基本情况:没有参数,返回0
template<typename T>
int CountArgs(T) {
return 0;
}
// 递归情况:至少有一个参数,返回1 + 剩余参数的个数
template<typename T, typename... Args>
int CountArgs(T, Args... args) {
return 1 + CountArgs(args...);
}
函数模板偏特化:
函数模板不能偏特化!!!!!!!!!!!!!
输入输出流及<<重载
person p;
cout<<p<<endl;
<==>cout<<p.operator (cout, p)
字符串"xx"的字面量是 const char*,不是 char []
test1
void operator << (ostream& os,const char *s) {
cout << string(s) <<string(" world") << endl;
}
int main() {
cout <<"hello";
}
ostream& operator << (ostream& os,const char *s) {
return os << string(s) << string(" world") << endl;
}
int main() {
cout <<"hello";
}
折叠表达式
template<typename ...Args>
void print(const Args & ... args){
using T = int[];
(void)T{(std::cout<<args<<' ',0)...};
}
当我们在 C++17 及更高版本中使用 ... 语法来表示参数包时,我们可以使用折叠表达式(fold expression)来对参数包进行操作。
在这个代码片段中,折叠表达式的形式是 (std::cout<<args<<' ',0)。
我们使用了逗号操作符来连接两个子表达式:(std::cout<<args<<' ')和 0。逗号操作符会先执行左侧的子表达式,然后忽略其结果,再执行右侧的子表达式,并将右侧子表达式的结果作为整个逗号表达式的结果。
(std::cout<<args<<' ',0):这是一个表达式,它将参数args的值与一个空格字符' '以及整数常量0连接在一起。...:这个...符号表示对参数包进行展开。(std::cout<<args<<' ',0)...:这个表达式中的...将会展开参数包args,并将每个参数依次放入表达式中进行处理。在这个例子中,每个参数都会通过std::cout进行输出打印,并在每个参数之后输出一个空格字符。(void)T{...}:这是一个使用了初始化列表的语法,它将展开后的表达式包装在类型为T的初始化列表中。这里的T是一个int类型的不完整数组,数组的大小没有指定。(void):将整个初始化列表强制转换为void类型,这样可以避免出现编译警告。
using 和 typedef
using 可以用于模板别名和别名声明,typedef 无法用于模板别名。
template<typename T>
using MyVector = std::vector<T>;
MyVector<int> myVec; // 等价于 std::vector<int> myVec;
类型萃取的一种常见实现
struct __TrueType//一个空类
{};
struct __FalseType//空类
{};
template <class T>
struct __TypeTraits
{
typedef __FalseType ISPODType; //默认为不是基本类型 POD(基本类型)
};
template <>
struct __TypeTraits<int>
{
typedef __TrueType ISPODType; //int是基本类型
};
template <class T>
T* TypeCopy(T* dst, const T* src, size_t n)
{
return __TypeCopy(dst, src, n, __TypeTraits<T>::ISPODType());
}
template <class T>
T* __TypeCopy(T* dst, const T* src, size_t n,__TrueType)
{
cout << "memcpy()" << endl;
return (T*)memcpy(dst, src, n*sizeof(T));
}
template <class T>
T* __TypeCopy(T* dst, const T* src, size_t n, __FalseType)
{
for (size_t i = 0; i < n; i++)
{
dst[i] = src[i];
}
cout << "operator=()" << endl;
return dst;
}
杂
- 避免使用 std:: string 定义常量
- 引发堆内存分配
- 析构函数非平凡,全局对象销毁顺序难以预测,存在生命周期结束后被访问的风险(例如被其他全局对象引用)
- 习惯使用 constexpr char[]
- 缺点:容易退化为 const char*需要带长度
类型断言#include <type_traits>
//-> decltype(std::forward<F>(f)(std::forward<Args>(args)...))
__func__打印函数名
template<typename F, typename... Args>
void retry(bool flag, const std::string& errMsg, F&& f, Args&&... args)
{
using RetType = decltype(std::forward<F>(f)(std::forward<Args>(args)...));
static_assert(std::is_same_v<RetType, bool>, "Return type of f must be bool");
bool ret = flag;
while (ret) {
ret = f(args...);
if (!ret) {
std::cout << "Error: " << errMsg << std::endl;
std::cout << "Retrying..." << std::endl;
}
}
}
template<typename F, typename... Args>
void retry(const std::string& errMsg, F&& f, Args&&... args)
{
retry(true, errMsg, std::forward<F>(f), std::forward<Args>(args)...);
}
std::mem_fn(&Producer::sendMessage),&pro
非静态成员转换为静态
f(args...)和 invoke(f,args...)有什么区别?
f(args...) 和 std::invoke(f, args...) 都是用于调用可调用对象(函数、函数指针、成员函数指针、函数对象等)的语法。它们之间的区别在于以下几个方面:
- 调用语法:
f(args...)是直接的函数调用语法,将可调用对象f与参数args...一起使用。而std::invoke(f, args...)是使用std::invoke函数模板进行调用,将可调用对象f和参数args...作为函数模板的参数。 - 支持的可调用对象类型:
f(args...)的调用语法可以适用于任何可调用对象,包括普通函数、函数指针、成员函数指针、函数对象等。而std::invoke(f, args...)是通过std::invoke函数模板进行调用,它支持更广泛的可调用对象类型,包括普通函数、函数指针、成员函数指针、函数对象、成员函数对象等,并且可以处理重载函数的调用。 - 访问限制:
f(args...)的调用语法受到可调用对象的访问属性限制,例如私有成员函数只能在类内部调用。而std::invoke(f, args...)通过使用std::invoke函数模板,可以在适当的上下文中调用私有成员函数。 - 错误处理:
f(args...)的调用语法对于无效的可调用对象或参数可能会引发编译时或运行时错误。而std::invoke(f, args...)通过使用std::invoke函数模板,提供了更灵活的错误处理机制,可以在编译时或运行时捕获和处理错误。
错误!
需要多个 public
explicit

模板的各个实例间并不天然就有 friend 关系,因而不能互访私有成员 ptr* 和 shared_count*。


nodiscard
nodiscard 是 c++17 引入的一种标记符,其语法一般为 [[nodiscard]] 或 [[nodiscard("string")]] (c++20 引入),含义可以理解为“不应舍弃”。nodiscard 一般用于标记函数的返回值或者某个类,当使用某个弃值表达式而不是 cast to void (static_cast<void>)来调用相关函数时,编译器会发出相关 warning。
宏
#define TRACE_BLOCK \
std::cout << 1 << std::endl; \
do { \
/* code */ \
} while (0); \
std::cout << 1 << std::endl;
拷贝构造函数如果用值传递会有什么影响?
如果把拷贝构造函数的参数设置为值传递,那么参数肯定就是本类的一个 object,采用值传递,在形参和实参相结合的时候,是要调用本类的拷贝构造函数,是不是就是一个死循环了?为了避免拷贝构造函数无限制的递归下去。
如何限制一个类对象只能在堆(栈)上分配空间
- 将构造函数设为私有
- 使用删除函数
variant
visit 两种用法
std::visit([](auto &&arg){
using T = std::decay_t<decltype<arg>;
if constexpr(std::is_same_v<T,type>){
} ...
})
std::visit(voerloaded{
[](type1 arg){},
[](type2 arg){},
...
v
})
运行效率
避免使用以下语法
- 动态类型转换:避免在模板中使用
dynamic_cast,因为它在运行时进行类型检查,会导致性能下降。如果可能,使用static_cast或reinterpret_cast。 - 虚函数:虽然虚函数本身并不一定是动态的,但在模板中使用虚函数可能会导致运行时多态,这通常比编译时多态(如模板特化)更慢。
- 异常处理:在模板中使用异常处理(
try、catch)会增加运行时开销,因为异常处理机制需要在运行时检查和处理异常。 - 动态内存分配:尽量避免在模板中频繁使用
new和delete,因为动态内存分配和释放操作通常比栈上的内存分配更慢。 - 复杂的运行时逻辑:避免在模板中嵌入复杂的运行时逻辑,如大量的条件判断和循环,这些都会增加运行时开销。
- 不必要的模板实例化:避免不必要的模板实例化,因为每个实例化都会生成新的代码,可能会导致代码膨胀。
结构体初始化
C
(*(T->Htree)) ={1, -1, -1, 1}; // 错误
(*(T->Htree)) =Node{1, -1, -1, 1}; //正确 复合字面量
HTNode t = {1, 1, 1, 1}; //正确 聚合初始化
Cpp
(*(T->Htree)) = {1, -1, -1, 1}; //正确 统一初始化,自动类型推导
(*(T->Htree)) =Node{1, -1, -1, 1}; //正确
HTNode t = {1, 1, 1, 1}; //正确 聚合初始化 注意此处不是initializer_list,
// 只有moderm cpp容器支持initializer_list ,不存在隐式转换
类型转换操作符 #magic
ps: 不知道上次做的笔记跑哪去了,重写一下
class MyClass {
public:
operator int() const {
return m_value;
}
private:
int m_value;
};
int main() {
MyClass obj;
int value = obj;
return 0;
}
- 类型转换操作符:允许将当前类类型隐式转换为其他类型。
类型双关
没什么卵用,可以用 variant / bit_cast 来替代
Union 类型双关的作用与解决的问题
Union 类型双关(Type Punning with Unions)是一种利用 C/C++ 中 union 类型的特性来实现数据解释的技术。它的核心思想是通过 union 类型,允许同一块内存以不同的数据类型进行访问,从而实现对数据的灵活解释。
1. Union 类型双关的作用
union 是一种特殊的数据结构,它允许多个成员共享同一块内存空间。通过 union,可以在不进行显式类型转换的情况下,以不同的数据类型访问同一块内存。这种特性被称为“类型双关”。
例如:
union Data {
int i;
float f;
char c;
};
union Data data;
data.i = 42; // 以 int 类型存储数据
printf("%f\n", data.f); // 以 float 类型解释同一块内存
在上面的例子中,data.i 和 data.f 共享同一块内存,但分别以 int 和 float 类型进行解释。这就是类型双关的典型应用。
2. 解决的问题
Union 类型双关主要用于以下场景:
(1)节省内存
union 允许多个成员共享同一块内存,这在需要存储多种类型数据但不需要同时使用它们的场景下非常有用。例如,在网络协议解析中,一个数据包可能包含不同类型的数据(如整数、浮点数、字符串等),但每次只需要访问其中一种类型。
(2)灵活的数据解释
在某些情况下,需要对同一块内存以不同的数据类型进行解释。例如:
- 在硬件编程中,寄存器可能以不同的位段(bit-field)或数据类型进行访问。
- 在数据序列化/反序列化中,可能需要将二进制数据解释为不同的类型。
(3)避免显式类型转换
通过 union,可以直接以不同的类型访问数据,而不需要使用显式的类型转换(如 reinterpret_cast 或指针强制转换)。这种方式在某些场景下更直观和安全。
3. Union 类型双关的潜在问题
尽管 Union 类型双关在某些场景下非常有用,但它也存在一些潜在问题:
- 未定义行为:在 C++ 中,通过
union进行类型双关可能会导致未定义行为(Undefined Behavior),尤其是在访问与当前存储类型不匹配的成员时。 - 可移植性问题:不同的编译器对
union类型双关的支持可能不同,尤其是在涉及严格别名规则(Strict Aliasing Rule)时。 - 代码可读性差:滥用
union类型双关可能导致代码难以理解和维护。
严格别名原则
严格别名规则就是编译器当看到多个别名(alias)时,会在一定规则下默认它们指向不同的内存区域(即使实际上可能指向相同的区域),并以此进行优化,可能会生成与我们期望不同的代码。
根据 C 和 C++标准,除非存在以下特殊情况,否则程序不能通过一种类型的指针或引用访问另一种类型的对象:
- 字符类型:可以通过
char、unsigned char或signed char类型的指针访问任何其他类型的对象。 - 兼容类型:可以通过兼容类型的指针或引用访问对象。
void*:void*可以指向任何类型的对象,但不能直接用于访问对象的内容,需要先强制转换为正确的类型。
虚析构函数允许在运行时根据对象的实际类型调用正确的析构函数,从而实现多态性。
如果基类的析构函数不是虚的,当通过基类指针删除指向派生类对象的对象时,只会调用基类的析构函数,而
不会调用派生类的析构函数。这可能导致派生类的资源未被正确释放,造成内存泄漏。
浅拷贝仅复制对象的值,而不涉及对象内部动态分配的资源。在浅拷贝中,新对象和原对象共享相同的资源,而不
是复制一份新的资源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号