


3DM热门单机游戏排行榜的爬取和数据分析
(一)、选题的背景
3dm是一个综合游戏门户网站,拥有单机用户最多、最活跃的论坛,最初由一批日语高手和游戏爱好者组成的依靠网站广告生存的民间组织,成立于1999-2000年。几经波折后成为国内最大的集游戏资讯、游戏首发、游戏汉化、未加密补丁发布的游戏综合门户网站,网站以讨论游戏内容和提供首发游戏资源下载为主。3dm拥有国内最强的游戏汉化团队、游戏内容制作团队。网站常年致力于为游戏玩家提供最全、最新、最快的单机游戏及电玩游戏资讯、内容和服务,并以让玩家在游戏上市后最短时间内体验到国外大作的高质量中文版本为目标。
随着科技的发展,游戏在年轻人群体里得到越来越多的青睐,而热门的游戏排行榜可以体现各个游戏的指标,可以让玩家更好选择游戏
(二)、主题式网络爬虫设计方案(10 分)
1.主题式网络爬虫名称:
爬取3DM热门单机游戏排行榜数据并数据分析及可视化
2.主题式网络爬虫爬取的内容与数据特征分析:
对3DM热门单机游戏排行榜的“排名”,“游戏名”,“游戏类型”,“评分”四个数据进行爬取
3.主题式网络爬虫设计方案概述:
实现思路:进入3DM游戏官网,进入热门单机游戏排行榜,进入网页开发人员工具,得到网页源代码,查找所需标签的代码,进行数据采集,完成后对数据进行相应的分析整理并存入文档中。读取文件进行数据清洗和数据可视化,绘制图形进行数据分析。接下来分析排行和时长的数据拟合分析,最后进行数据持久化。
技术难点:爬取信息时对标签的筛选,做数据分析,即求回归系数,因为标题是文字,无法与数字作比较,需要把标题这一列删除,不然输出结果经常会显示超出列表范围。
(三)、主题页面的结构特征分析(10 分)
1.主题页面的结构与特征分析:
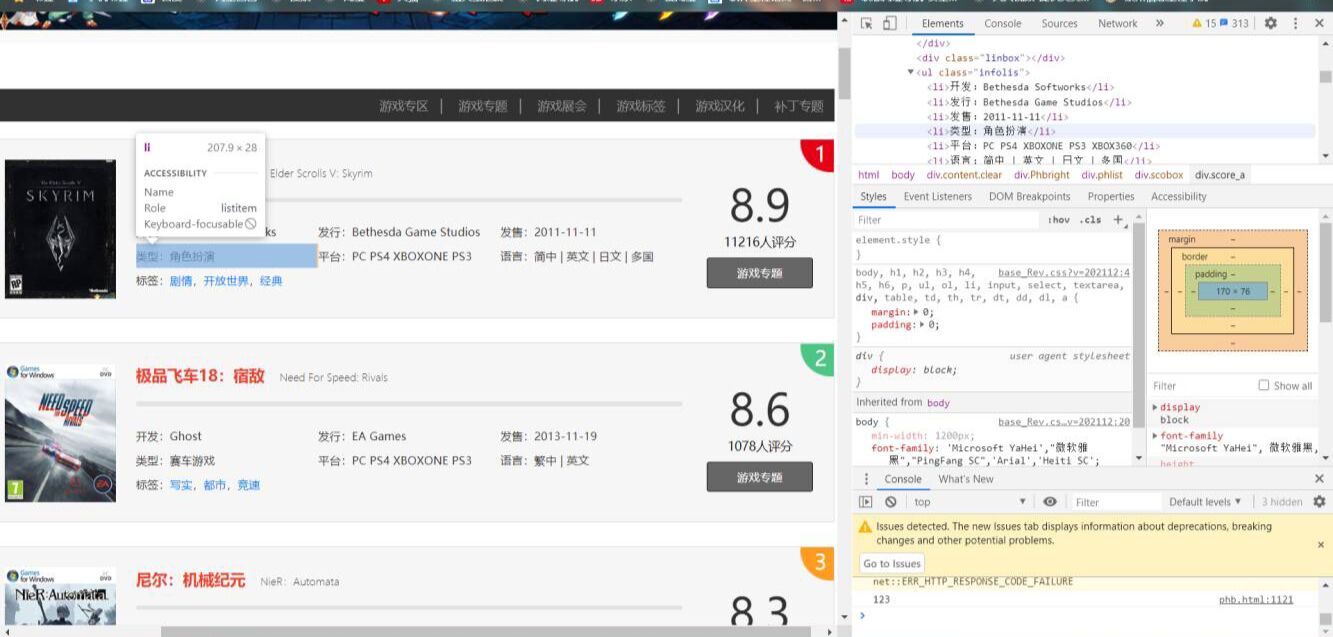
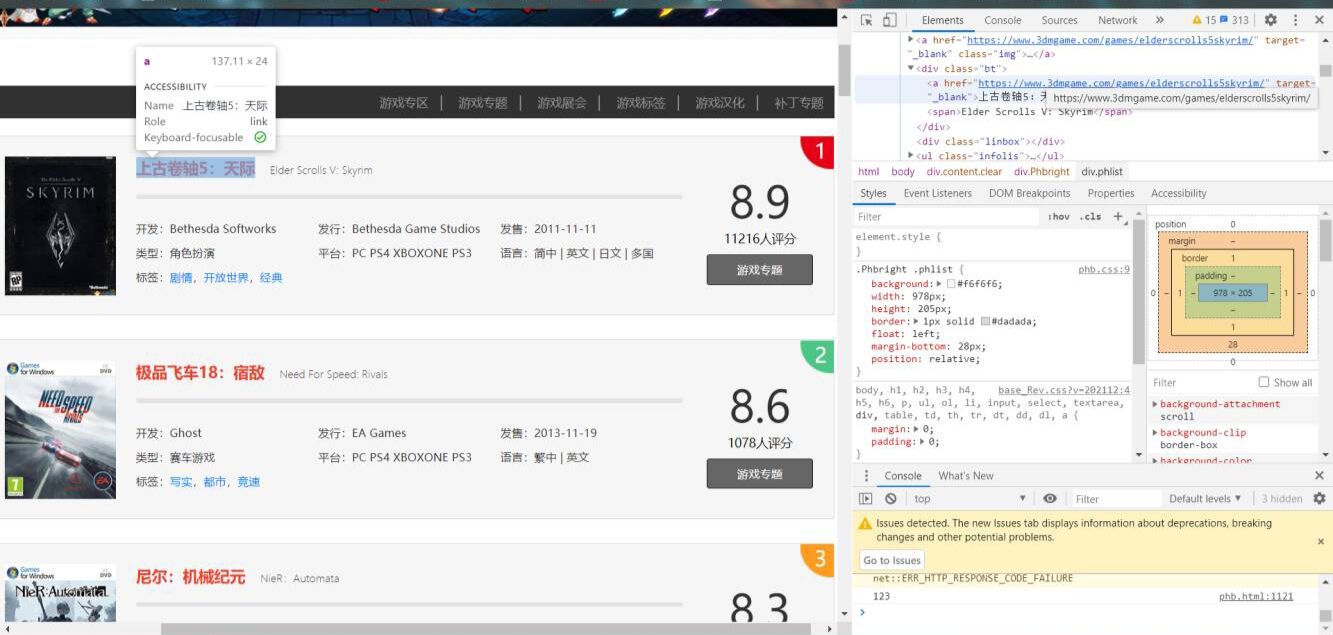
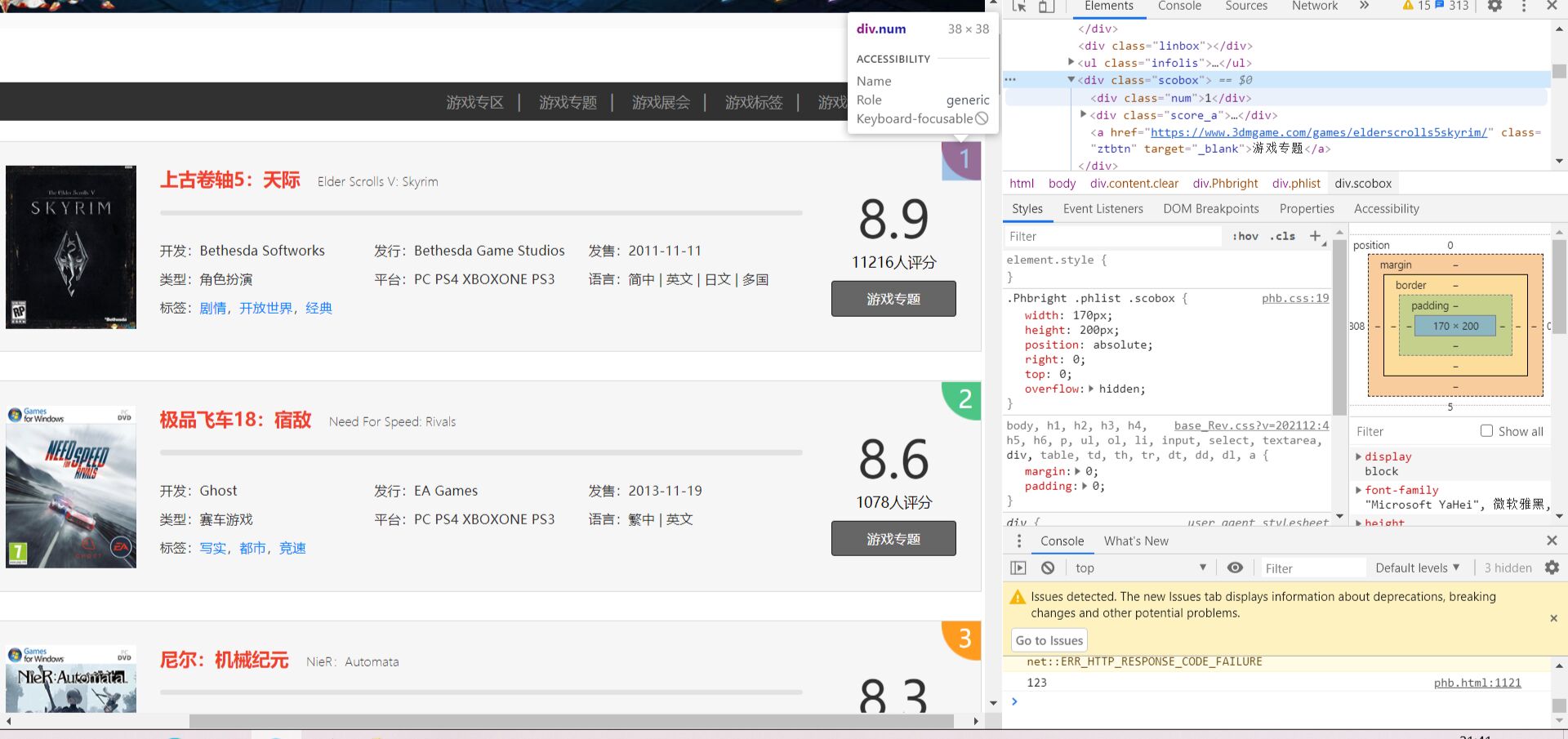
通过对页面结构的分析,发现<div class="phlist">元素中,发现所需要的数据。并进行查找,在标签<a>,<class="infolis">,<span>,<class="num">分别找到游戏名,游戏类型,评分,排名的数据
url为https://www.3dmgame.com/phb.html
网址首页
2.Htmls 页面解析
通过查找网页源代码,浏览其中元素,并对其中元素进行解析


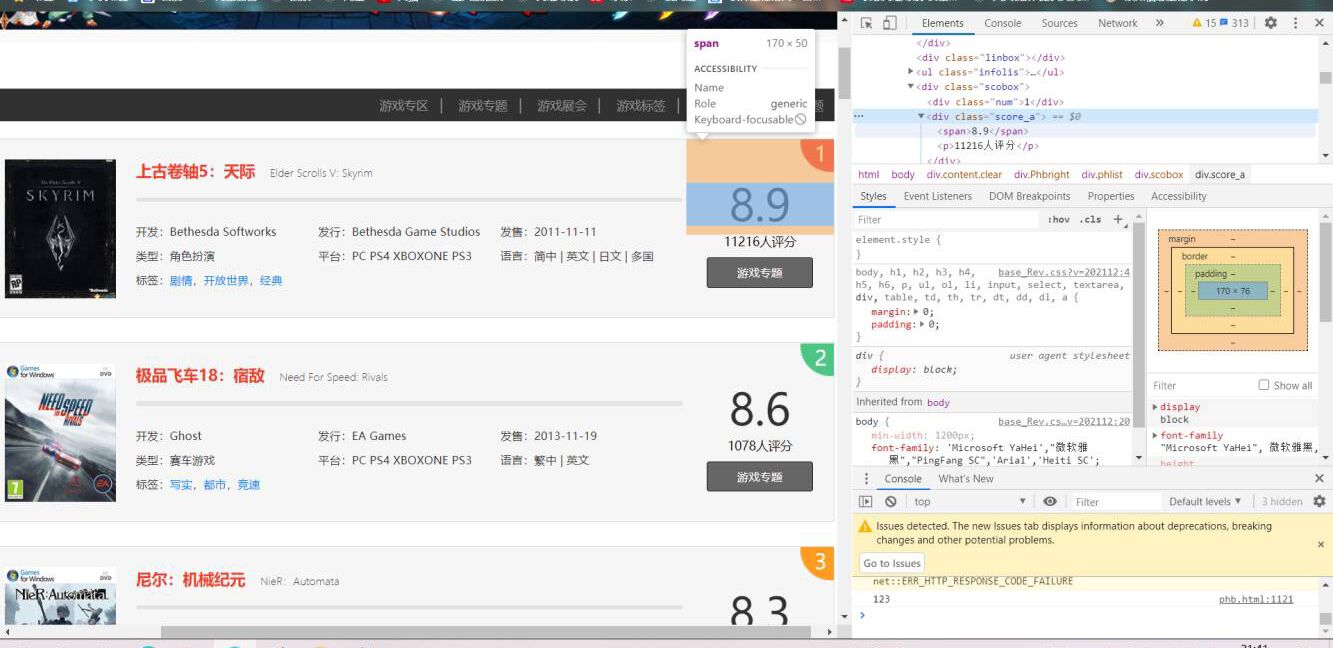
(四)、网络爬虫程序设计(60 分)
1.数据爬取与采集
1 #导入相关库 2 import requests 3 #引入pandas用于数据可视化 4 import pandas as pd 5 import numpy as np 6 import matplotlib.pyplot as plt 7 import matplotlib 8 import csv 9 import scipy as sp 10 import seaborn as sns 11 from sklearn.linear_model import LinearRegression 12 from bs4 import BeautifulSoup 13 from pandas import DataFrame 14 from scipy.optimize import leastsq 15 import requests 16 from bs4 import BeautifulSoup 17 #3DM热门单机游戏排行榜 18 r = requests.get("https://www.3dmgame.com/phb.html") 19 r.encoding = "utf-8" #为了简化代码,没有考虑异常情况。 20 soup = BeautifulSoup(r.text,'html.parser') #soup就是一个BeautifulSoup对象。 21 #type(soup) 22 print(soup.prettify())#基于bs4库HTML的格式输出,让页面更友好的显示
1 #爬取数据 2 #爬取游戏名 3 h=[] 4 for n in soup.find_all("a",class_="")[33:63]: 5 h.append(n.get_text().strip()) 6 7 h 8 9 #爬取排名 10 c=[] 11 for n in soup.find_all(class_="num"): 12 c.append(n.get_text().strip()) 13 14 c 15 16 #爬取评分 17 b=[] 18 for i in soup.find_all('span', class_='')[8:-7:2]: 19 b.append(i.get_text().strip()) 20 21 b 22 23 #爬取游戏类型 24 d=[] 25 for i in soup.find_all('li', class_='')[12:-3:7]: 26 d.append(i.get_text().strip()) 27 28 e=d 29 e



1 #将数据整理成表格 2 print('{:^55}'.format('3DM热门单机游戏排行榜')) 3 print('{:^5}\t{:^40}\t{:^30}\t{:^10}'.format('排名', '游戏名', '游戏类型', '评分')) 4 num = 20 5 lst = [] 6 for i in range(num): 7 print('{:^5}\t{:^40}\t{:^30}\t{:^10}'.format(c[i], h[i], e[i],b[i])) 8 lst.append([c[i],h[i], d[i],b[i]]) 9 df = pd.DataFrame(lst,columns=['排名', '游戏名', '游戏类型', '评分']) 10 11 #将数据存入excel表 12 rank = r'3DM热门单机游戏排行榜.xlsx' 13 df.to_excel(rank)

2.对数据进行清洗和处理
1 #数据清洗 2 3 #重复值处理 4 print(df.duplicated()) 5 6 #统计空值 7 print(df.isnull().sum()) #返回0则没有空值 8 9 #缺失值处理 10 print(df[df.isnull().values==True]) #返回无缺失值 11 12 #用describe()命令显示描述性统计指标 13 print(df.describe())

4.数据分析与可视化
1 #选择排名和评分两个特征变量,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和拟合曲线 2 colnames=[" ","排名","名称","评分"] 3 df = pd.read_excel('C:/Users/方瑞行/3DM热门单机游戏排行榜.xlsx') 4 # 用来正常显示中文标签 5 plt.rcParams['font.sans-serif'] = ['SimHei'] 6 # 用来正常显示负号 7 plt.rcParams['axes.unicode_minus'] = False 8 X = df.排名 9 Y = df.评分 10 11 #评分与排名关系图 12 matplotlib.rcParams['font.sans-serif']=['SimHei'] 13 plt.plot(x,y) 14 plt.xlabel("排名") 15 plt.ylabel("评分") 16 plt.title('评分与排名关系图') 17 plt.show() 18 #评分与排名柱状关系图 19 plt.bar(df.排名,df.评分) 20 21 plt.xlabel("排名") 22 plt.ylabel("评分") 23 plt.title('评分与排名柱状关系图') 24 plt.show()
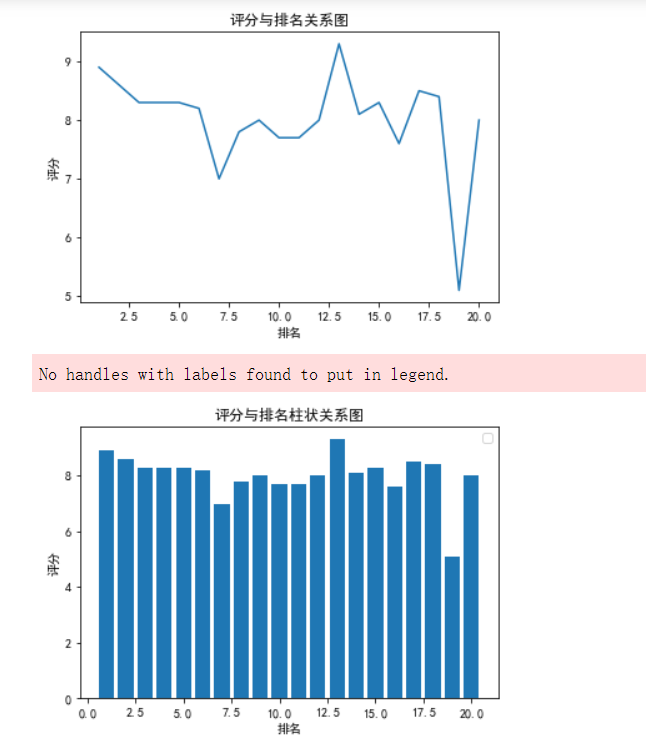
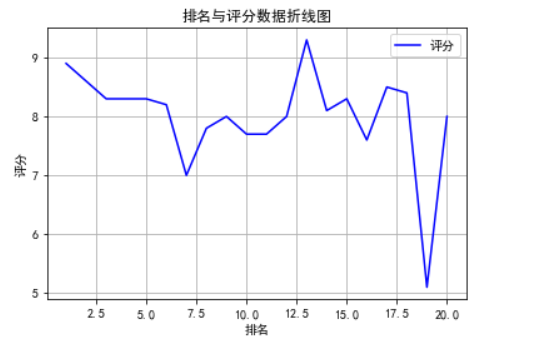
1 #绘制折线图 2 plt.rcParams['font.sans-serif']=['SimHei'] 3 a = df.排名 4 b = df.评分 5 plt.plot(a,b, color='b',label='评分') 6 plt.xlabel("排名") 7 plt.ylabel("评分") 8 plt.title('排名与评分数据折线图') 9 plt.legend(loc=1) 10 plt.grid() 11 plt.show()
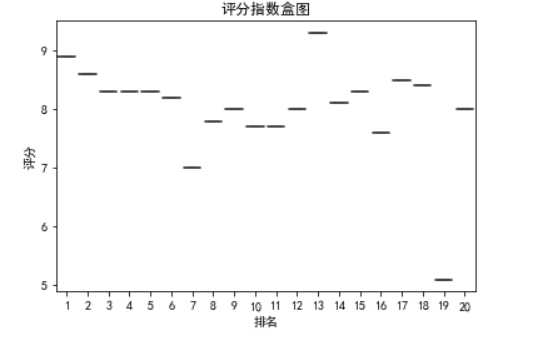
1 #绘制指数盒图 2 import seaborn as sns 3 def box(): 4 plt.title('评分指数盒图') 5 a = df.排名 6 b = df.评分 7 sns.boxplot(a,b) 8 plt.xlabel("排名") 9 plt.ylabel("评分") 10 11 box()
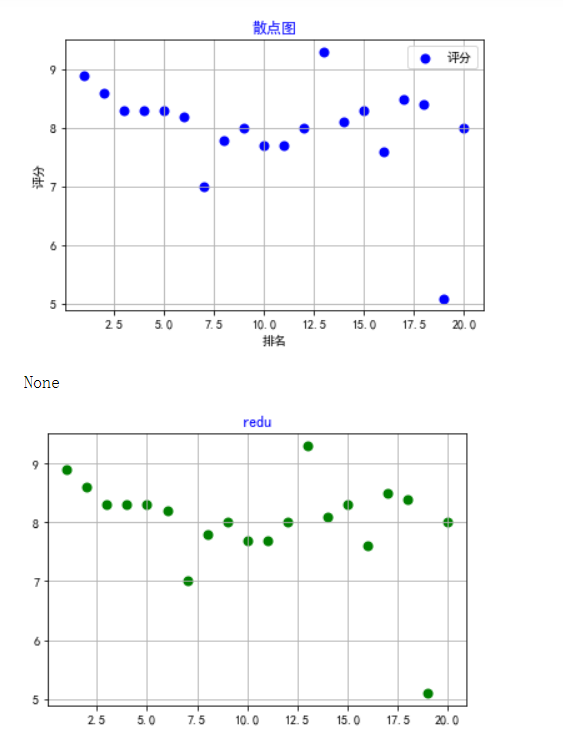
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变
量之间的回归方程(一元或多元)。
1 #构建数据分析模型 2 import numpy as np 3 import pandas as pd 4 import sklearn 5 from sklearn import datasets 6 from sklearn.linear_model import LinearRegression 7 X = df[["排名"]] 8 predict_model = LinearRegression() 9 predict_model.fit(X, df[['评分']]) 10 11 print("回归系数为{}".format(predict_model.coef_)) 12 print("回归方程截距:{}".format(predict_model.intercept_))

1 #选择排名和评分两个特征变量,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和拟合曲线 2 colnames=[" ","排名","名称","评分"] 3 df = pd.read_excel('C:/Users/方瑞行/3DM热门单机游戏排行榜.xlsx') 4 # 用来正常显示中文标签 5 plt.rcParams['font.sans-serif'] = ['SimHei'] 6 # 用来正常显示负号 7 plt.rcParams['axes.unicode_minus'] = False 8 X = df.排名 9 Y = df.评分 10 11 #绘制散点图 12 def A(): 13 plt.scatter(X,Y,color="blue",linewidth=2,label='评分') 14 plt.legend(loc=1) 15 plt.title("散点图",color="blue") 16 plt.grid() 17 plt.xlabel("排名") 18 plt.ylabel("评分") 19 plt.show() 20 21 22 def B(): 23 plt.scatter(X,Y,color="green",linewidth=2) 24 plt.title("redu",color="blue") 25 plt.grid() 26 plt.show() 27 28 29 def func(p,x): 30 a,b,c=p 31 return a*x*x+b*x+c 32 33 def error(p,x,y): 34 return func(p,x)-y 35 36 def main(): 37 plt.figure(figsize=(10,6)) 38 p0=[0,0,0] 39 Para = leastsq(error,p0,args=(X,Y)) 40 a,b,c=Para[0] 41 print("a=",a,"b=",b,"c=",c) 42 plt.scatter(X,Y,color="blue",linewidth=2,label='评分分布') 43 plt.legend(loc=1) 44 x=np.linspace(0,20,20) 45 y=a*x*x+b*x+c 46 plt.plot(x,y,color="red",linewidth=2,label="拟合曲线") 47 plt.legend(loc=1) 48 plt.title("一元二次方程关系图") 49 plt.xlabel("排名") 50 plt.ylabel("评分") 51 plt.grid() 52 plt.show() 53 54 print(A()) 55 56 print(B()) 57 58 print(main())
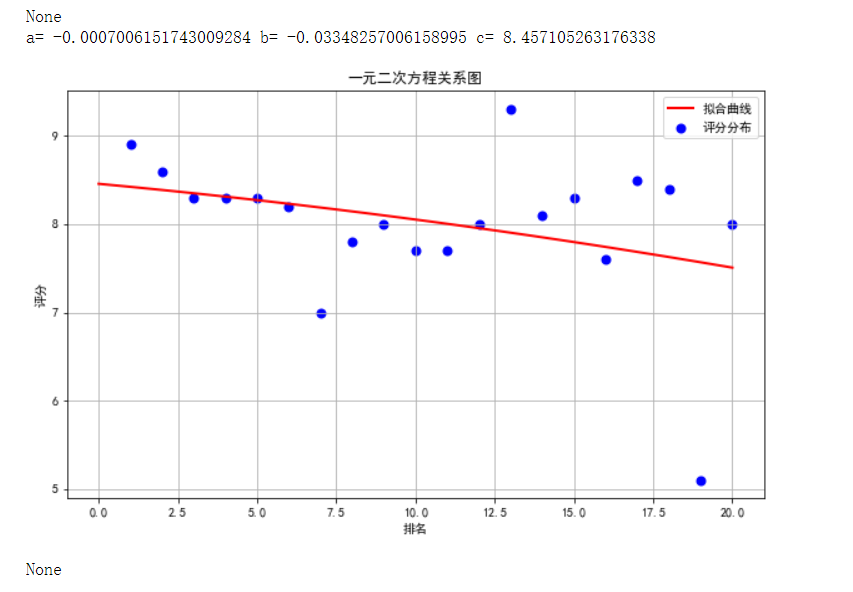
6.数据持久化
1 #数据持久化 2 #将数据存入excel表 3 rank = r'3DM热门单机游戏排行榜.xlsx' 4 df.to_excel(rank)
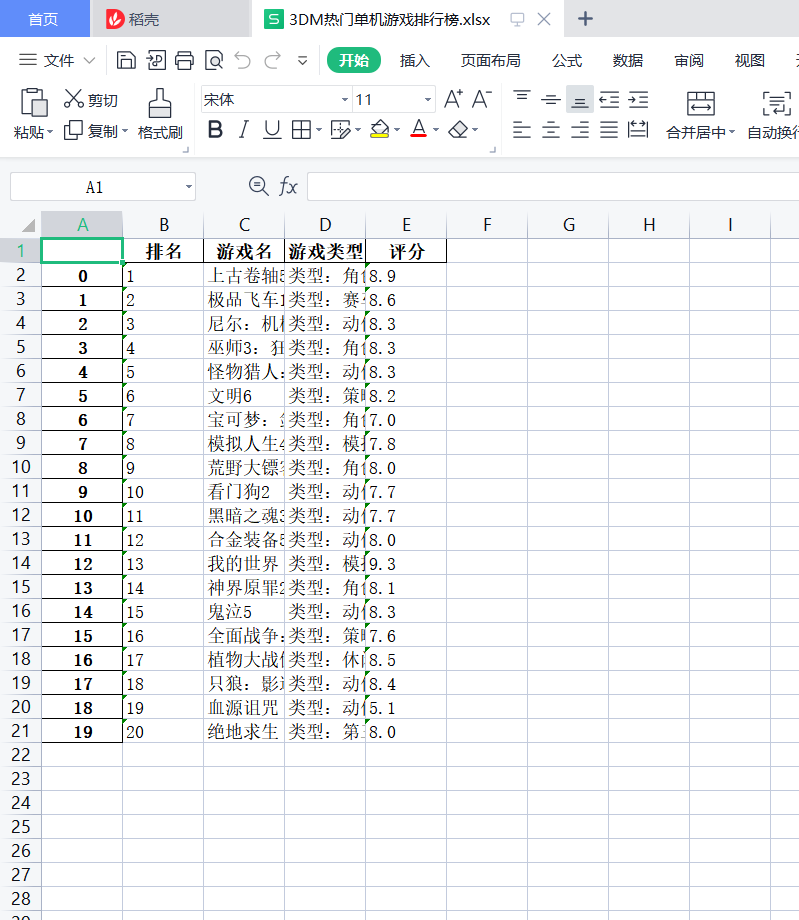
7.将以上各部分的代码汇总,附上完整程序代码
1 #导入相关库 2 import requests 3 #引入pandas用于数据可视化 4 import pandas as pd 5 import numpy as np 6 import matplotlib.pyplot as plt 7 import matplotlib 8 import csv 9 import scipy as sp 10 import seaborn as sns 11 from sklearn.linear_model import LinearRegression 12 from bs4 import BeautifulSoup 13 from pandas import DataFrame 14 from scipy.optimize import leastsq 15 import requests 16 from bs4 import BeautifulSoup 17 #3DM热门单机游戏排行榜 18 r = requests.get("https://www.3dmgame.com/phb.html") 19 r.encoding = "utf-8" #为了简化代码,没有考虑异常情况。 20 soup = BeautifulSoup(r.text,'html.parser') #soup就是一个BeautifulSoup对象。 21 #type(soup) 22 print(soup.prettify())#基于bs4库HTML的格式输出,让页面更友好的显示 23 #爬取数据 24 #爬取游戏名 25 h=[] 26 for n in soup.find_all("a",class_="")[33:63]: 27 h.append(n.get_text().strip()) 28 29 h 30 31 #爬取排名 32 c=[] 33 for n in soup.find_all(class_="num"): 34 c.append(n.get_text().strip()) 35 36 c 37 38 #爬取评分 39 b=[] 40 for i in soup.find_all('span', class_='')[8:-7:2]: 41 b.append(i.get_text().strip()) 42 43 b 44 45 #爬取游戏类型 46 d=[] 47 for i in soup.find_all('li', class_='')[12:-3:7]: 48 d.append(i.get_text().strip()) 49 50 e=d 51 e 52 #将数据整理成表格 53 print('{:^55}'.format('3DM热门单机游戏排行榜')) 54 print('{:^5}\t{:^40}\t{:^30}\t{:^10}'.format('排名', '游戏名', '游戏类型', '评分')) 55 num = 20 56 lst = [] 57 for i in range(num): 58 print('{:^5}\t{:^40}\t{:^30}\t{:^10}'.format(c[i], h[i], e[i],b[i])) 59 lst.append([c[i],h[i], d[i],b[i]]) 60 df = pd.DataFrame(lst,columns=['排名', '游戏名', '游戏类型', '评分']) 61 62 #将数据存入excel表 63 rank = r'3DM热门单机游戏排行榜.xlsx' 64 df.to_excel(rank) 65 #数据清洗 66 67 #重复值处理 68 print(df.duplicated()) 69 70 #统计空值 71 print(df.isnull().sum()) #返回0则没有空值 72 73 #缺失值处理 74 print(df[df.isnull().values==True]) #返回无缺失值 75 76 #用describe()命令显示描述性统计指标 77 print(df.describe()) 78 #选择排名和评分两个特征变量,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和拟合曲线 79 colnames=[" ","排名","名称","评分"] 80 df = pd.read_excel('C:/Users/方瑞行/3DM热门单机游戏排行榜.xlsx') 81 # 用来正常显示中文标签 82 plt.rcParams['font.sans-serif'] = ['SimHei'] 83 # 用来正常显示负号 84 plt.rcParams['axes.unicode_minus'] = False 85 X = df.排名 86 Y = df.评分 87 88 #评分与排名关系图 89 matplotlib.rcParams['font.sans-serif']=['SimHei'] 90 plt.plot(x,y) 91 plt.xlabel("排名") 92 plt.ylabel("评分") 93 plt.title('评分与排名关系图') 94 plt.show() 95 #评分与排名柱状关系图 96 plt.bar(df.排名,df.评分) 97 98 plt.xlabel("排名") 99 plt.ylabel("评分") 100 plt.title('评分与排名柱状关系图') 101 plt.show() 102 #绘制折线图 103 plt.rcParams['font.sans-serif']=['SimHei'] 104 a = df.排名 105 b = df.评分 106 plt.plot(a,b, color='b',label='评分') 107 plt.xlabel("排名") 108 plt.ylabel("评分") 109 plt.title('排名与评分数据折线图') 110 plt.legend(loc=1) 111 plt.grid() 112 plt.show() 113 #绘制指数盒图 114 import seaborn as sns 115 def box(): 116 plt.title('评分指数盒图') 117 a = df.排名 118 b = df.评分 119 sns.boxplot(a,b) 120 plt.xlabel("排名") 121 plt.ylabel("评分") 122 123 box() 124 #构建数据分析模型 125 import numpy as np 126 import pandas as pd 127 import sklearn 128 from sklearn import datasets 129 from sklearn.linear_model import LinearRegression 130 X = df[["排名"]] 131 predict_model = LinearRegression() 132 predict_model.fit(X, df[['评分']]) 133 134 print("回归系数为{}".format(predict_model.coef_)) 135 print("回归方程截距:{}".format(predict_model.intercept_)) 136 #选择排名和评分两个特征变量,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和拟合曲线 137 colnames=[" ","排名","名称","评分"] 138 df = pd.read_excel('C:/Users/方瑞行/3DM热门单机游戏排行榜.xlsx') 139 # 用来正常显示中文标签 140 plt.rcParams['font.sans-serif'] = ['SimHei'] 141 # 用来正常显示负号 142 plt.rcParams['axes.unicode_minus'] = False 143 X = df.排名 144 Y = df.评分 145 146 #绘制散点图 147 def A(): 148 plt.scatter(X,Y,color="blue",linewidth=2,label='评分') 149 plt.legend(loc=1) 150 plt.title("散点图",color="blue") 151 plt.grid() 152 plt.xlabel("排名") 153 plt.ylabel("评分") 154 plt.show() 155 156 157 def B(): 158 plt.scatter(X,Y,color="green",linewidth=2) 159 plt.title("redu",color="blue") 160 plt.grid() 161 plt.show() 162 163 164 def func(p,x): 165 a,b,c=p 166 return a*x*x+b*x+c 167 168 def error(p,x,y): 169 return func(p,x)-y 170 171 def main(): 172 plt.figure(figsize=(10,6)) 173 p0=[0,0,0] 174 Para = leastsq(error,p0,args=(X,Y)) 175 a,b,c=Para[0] 176 print("a=",a,"b=",b,"c=",c) 177 plt.scatter(X,Y,color="blue",linewidth=2,label='评分分布') 178 plt.legend(loc=1) 179 x=np.linspace(0,20,20) 180 y=a*x*x+b*x+c 181 plt.plot(x,y,color="red",linewidth=2,label="拟合曲线") 182 plt.legend(loc=1) 183 plt.title("一元二次方程关系图") 184 plt.xlabel("排名") 185 plt.ylabel("评分") 186 plt.grid() 187 plt.show() 188 189 print(A()) 190 191 print(B()) 192 193 print(main()) 194 195 #数据持久化 196 #将数据存入excel表 197 rank = r'3DM热门单机游戏排行榜.xlsx' 198 df.to_excel(rank)
(五)、总结(10 分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
根据数据分析可以发现,排名会随着评分的降低而降低,消费者可以按排名来选择游戏
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
在设计过程中,我收获到了如何编写爬虫程序,如何把网页想要爬取的内容提取出来,怎么画出自己想要的图像。改进的地方可能是编写代码经验不足吧,写代码的时候比较吃力。希望我自己在以后的就业或者提升中花费多些时间、精力来提升这一短板

 浙公网安备 33010602011771号
浙公网安备 33010602011771号