超分辨率重建的基础知识
图像超分 (Image Super-Resolution) 是在计算机视觉图像处理中用于增强图片和视频的分辨率的技术。Super-Resolution (SR) 主要是指将低分辨率 (Low-Resolution LR) 图片复原到高分辨率 (High-Resolution HR) 图。其在现实生活中应用广泛,包括医疗图像、监控和帮助改善一些其他的计算机视觉任务。
一般来说,超分问题是具有挑战性和病态 (ill-posed) 的,因为一张 LR 的图片对应着多种 HR 图片。传统的方法主要包括基于预测的方法、基于边缘的方法、基于统计的方法和稀疏表达的方法等。然而随着近年深度学习的飞速发展,基于深度学习的 SR 方法已经在 SR 的各类 benchmark 达到了 the state of the art 水平。
问题的设定和一些术语
问题的定义
SR 问题常常被定义为一系列图像的退化问题,常常用下述表达式来进行 model SR 问题的图像退化过程。
其中 \(I_y \otimes k\) 表示一个模糊核 (blur kernel) \(k\) 和 HR 图 \(I_y\) 之间的卷积,\(\eta\) 则是图像中的噪声,一般为高斯白噪声。
而 SR 的目标则变成一个优化问题,由下式定义:
其中 \(\mathcal{L}(\hat{I}_y, I_y)\) 表示生成的 SR 图 \(\hat{I}_y\) 和真值图 \(I_y\) 之间的 loss 函数,\(\Phi(\theta)\) 是正则化项,\(\lambda\) 是超参数。
SR 的常用数据集
在常用的公开数据集中,一部分是有 LR-HR 图片对的,一部分是只提供 HR 图片,然后常常再使用 MATLAB 中的 imresize 来获得 LR 图。

图像的评价标准(Image Quality Assessment)
图像质量指的是图像的视觉属性和观看者的感受评价。一般来说,IQA 一般包括主观的方法(基于人类的感受)与客观计算的方法。前者是我们更需要的,但是耗时和成本都是昂贵的,因此后者是主流的。但是客观计算的方法往往不能达成一致,以致于在 IQA 评价结果上可能差别较大。
Peak Signal-to-Noise Ratio
峰值信噪比(PSNR) 是最普遍的重建质量的衡量标准。对于超分来说,通过最大像素值 \(L\) 和两张图片的均方误差 \(MSE\) 来定义 PSNR。考虑有 \(N\) 个像素的真值图片 \(I\) 与重建图片 \(\hat{I}\),PSNR 定义如下:
一般来说,\(L=255\)。因为 PSNR 是关注了像素级的 MSE,使用对应像素的差异来替代视觉感受,因此用 PSNR 来表示重建质量常常在更关注人类感受的实际场景表现不好。
Structural Similarity Index
由于人类视觉系统(Human Visual System HVS)更关注图像的结构,因此基于独立比较亮度(luminance)、对比度(contrast)和 structures 而提出结构相似性指数,其主要用于衡量图像间的结构相似性。考虑有 \(N\) 个像素亮度为 \(\mu_I\) 、对比度为 \(\sigma_I\) 的真值图片 \(I\) (其中亮度和对比度定义为图像强度的均值和标准差),于是真值图 \(I\) 和重建图片 \(\hat{I}\) 关于亮度和对比度的定义如下:
其中 \(C_1=(k_1L)^2,C_2=(k_2L)^2,k_1 \ll 1,k_2 \ll 1\) 用以防数值溢出。此外,图片的结构用标准化的像素值,其相关性可以用来衡量结构相似性,一般用 \(I\) 和 \(\hat{I}\) 的协方差来计算。结构对比函数定义如下:
最后定义 \(\mathrm{SSIM}\) 定义如下:
因为结构相似指数是从 HVS 的角度来评价重建质量,所以它更接近人类感受的评价。
监督学习的超分模型
超分常见的结构
因为图像的超分是一个病态问题,所以如何进行 upsampling 是一个关键的问题。现有的模型种类非常多,但根据所应用的 upsampling 运算和它们在模型中的位置主要分为 4 种。

Pre-upsampling SR
考虑到直接学习从低维空间到高维空间映射的难度,所以使用传统上采样算法获得高分辨图像,然后通过深度神经网络是一个直接的解法。SRCNN 是前置上采样 SR 框架的开山之作,其先通过传统的方法将 LR 图像通过传统的方法进行上采样到粗糙的 HR,再用神经网络进行填充细节。这类模型(如上图 (a))常常可以将输入进行任意倍数任意 size 的上采样从而输出任意尺寸的图像。
然而,前置上采样经常引入副作用,比如噪声和模糊效果也同步放大,又因为是在高维空间进行计算,所以时间和空间的代价都远远高于其他模型。
Post-upsampling SR
显然对比前置上采样,后置上采样的好处当然就是计算的高效与更充分使用深度学习了。这类模型(如上图 (b))常常在模型的尾部嵌入了一个预定义且可端到端学习的上采样层。因为占用的计算资源较少,所以成为了主流的结构。
Progressive-upsampling SR
后置上采样 SR 并非全无缺点,因为只在末端进行一次上采样,常常在面对较大倍数上采样时出现学习困难的情况,另外,每个上采样倍数都需要重新训练一个模型。Laplacian pyramid SR network (LapSRN) 即为一个逐步上采样的网络结构(如上图 (c)),它是一个级联的 CNN 结构,在每一个阶段都会被上采样到更高分辨率,然后被作为后面的 CNN 的输入进行细节的填充。
虽然这种模型很好解决了较大尺寸上采样和多尺度 SR的问题,但是其复杂的模型结构设计、训练的稳定性,以及需要更先进的训练策略给设计者和使用者造成了困扰。
Iterative Up-and-down Sampling Super-resolution
为了更好的获取 LR-HR 图像对的依赖性,一个有效的可迭代称之为 back-projection 的过程融合进入了 SR。这种结构被命名为可迭代上下采样 SR(如上图 (d)),其通过应用 back-projection refinement 计算重建的误差,然后将其融合来即时调整 HR,如:DBPN、SRFBN、RBPN 等。然而关于 back-projection 模块的设计准则依然不清晰,这种结构拥有巨大潜力还需要继续探索。
Learning-based Upsampling
Transposed Convolution Layer

转置卷积也就是反卷积 (deconvolution) ,其通过 size 如同普通卷积输出的特征图来预测跟普通卷积输入一样的 tensor。如上图,其通过插零和卷积的方式来提升图像的分辨率。以 3*3 的 kernel 进行 2 倍的超分为例,首先如图 (b) 进行插零使其成为原图尺寸的二倍,然后通过 padding 后进行卷积得到上采样后的图。转置卷积不好的地方在于容易在每一个轴导致 uneven overlapping 的问题,而且两个轴相乘的结果进一步创造棋盘式的 varying magnitudes ,从而影响 SR 效果。
Sub-pixel Layer
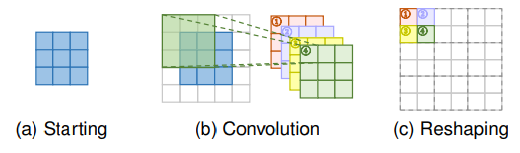
Sub-pixel Layer 通过卷积层生成大量的通道,然后再重新 reshape 以到达上采样的效果。如上图所示,图像首先通过卷积层生成通道为原通道的 s * s 倍的 tensor (其中 s 为 scaling factor)比如如果输入的 size 是 c * w * h,那么输出的 size 便为 (s * s * c) * w * h。然后通过 reshape 运算得到最后的输出 size 为 c * sw * sh。对比转置卷积 Sub-pixel Layer 通过语义更强的信息来生成更真实地细节(没有 padding 和 插零)。因为 blocky 区域共享同样地卷积核,因此可能再不同地 blocks 边界造成 artifacts。另一方面,独立预测一个 blocky 区域中的相邻像素可能会导致不平滑地输出。因此有人提出了 PixelTCL 来解决这个问题。
Meta Upscale Module
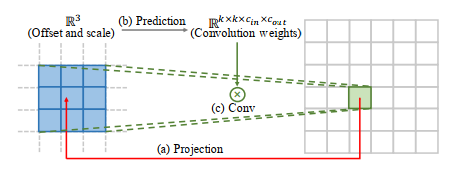
之前的方法都会预定义 scaling factors,训练不同得上采样 module 来进行不同 factor 的上采样。meta upscale module 第一次基于元学习解决了任意 scaling factors 的上采样。对于 HR 图像的每一个目标位置,这个 module 都将其 project 回 LR 图像中的一个小 patch。然后根据 projection 的 offsets 与 scaling factors 来用卷积进行预测卷积的权重。然后通过用预测的卷积权重来对 LR 的 patch 进行卷积得到 HR。虽然说这种方法需要在推理阶段预测权重,但所占时间并不多。可是,由于这种方法对 HR 每一个像素都会去预测权重,当面临较大 magnification 时,会显得效率低下。
网络设计
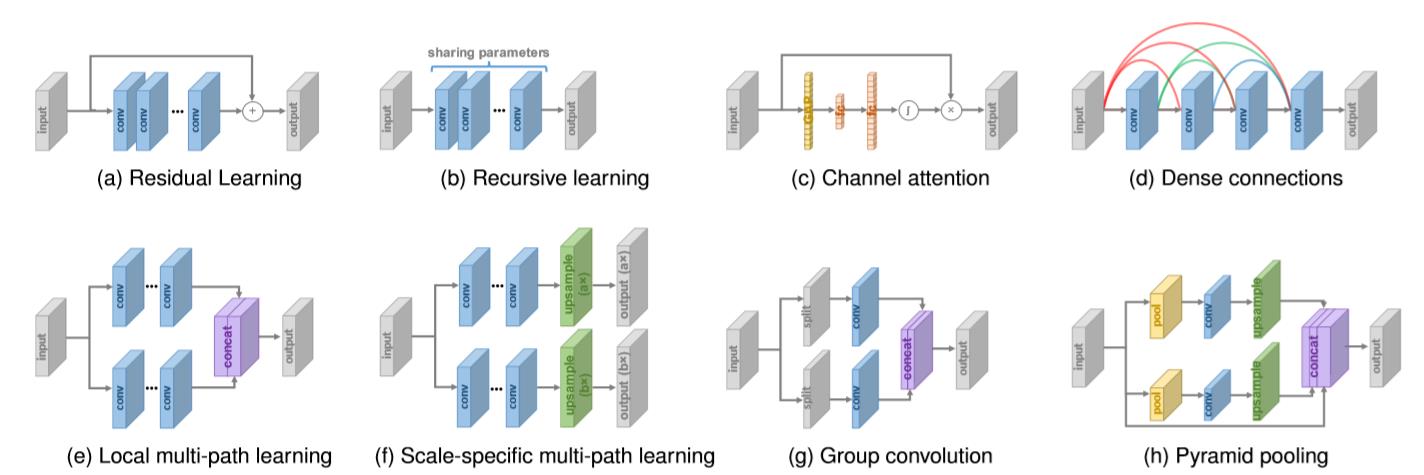
Residual Learning
在何凯明在 ResNet 大量使用残差学习之前,其早已在超分模型广泛应用了(如上图(a))。并且残差学习的策略可以别分为全局和局部的残差学习。
全局残差学习。因为图像 SR 是一个图像到图像转换的任务,其中输入图像是与输出图像高相关的,而只学习它们之间的残差被称之为全局残差学习。因为残差的大部分区域趋近于 0,模型的复杂性和学习的难度被大幅度降低,从而被广泛应用于超分模型。
局部残差学习。这与 ResNet 中的应用相似,而且也被用于缓解因网络层数加深而导致的梯度消失问题。跟全局残差学习一样,都是应用了 shortcut connection 然后再点加。
Recursive Learning
为了在不引入过多参数的情况下学习 higher-level features,循环学习就是循环的使用一个模块(如图(b))。例如 the 16-recursive DRCN 应用了单层卷积层作为循环单元最终获得 4141 的感受野,其比 SRCNN 的 1313 大得多,并且没有引入过多的参数。虽然这种方法不会引入过多的参数,但是也是无法避免高计算代价的。
Multi-path Learning
多路径学习指的是通过多条路径来传输 features,不同路径有不同的运算和不同的融合。
全局多路径学习。其主要利用多路径进行不同 aspects 图片的特征提取,这些路径在传播的过程互相交叉,因此极大的增强了学习能力。
局部多路径学习。如图(e),受到 Inception 使用一个模块来提取不同 scale 的特征影响,其用两种不同的卷积层一种卷积核是 33,另外一种卷积核是 55,来同时提取特征,最后将输出进行 concat。其是在网络结构内部进行了多路径学习,顾名思义为局部多路径学习。
特定尺寸多路径学习。其会共享模型的主要部分,在网络开始或者结束的地方会有特定 scale 的预处理(如图(f))。在训练阶段,只有所选 scale 分支会被更新。MDSR 通过这种方式大大降低了模型的容量,并且表现出与单
scale 模型相同的水平。
Dense Connections
自从 Huang 基于 dense blocks 提出了 DenseNet,dense connections 在视觉任务中是越来越普遍了。对于 dense block 中的每一层,之前所有层的特征图都是其输入,当然它自己的特征图也会被当作输入送入到之后的所有层。dense connections 不仅减轻了梯度消失的问题,增强了信号传播与特征的融合。
为了更好的融合 high-level 与 low-level 的特征,从而给重建高质量的细节提供丰富的信息,dense connection 被引入至 SR 领域(如图(d))。MemNet、CARN、RDN、DBPN 和 ESRGAN 都使用了 dense connections。
Attention Mechanism
Channel Attention。考虑到不同通道之间特征表达的内在联系(如图(c)),Hu 提出了以 squeeze-and-excitation 的方式来改善学习能力。这种方式,输入(B * C * W * H)的通道被使用全局平均池化 (GAP) squeeze 到称之为 channel descriptor 的状态(B * C * 1 * 1),然后再通过全连接后输出通道相关的权重(B * C * 1 * 1)并分别和输入(B * C * W * H)进行点乘。RCAN 使用了通道注意力使得 SR 模型表达能力和表现大大提升。
Non-local Attention。大多数的 SR 模型感受野都是局限的,可是往往相隔甚远的两个 patch 是有关联的。因此 Zhang 提出了局部和非局部注意力来获取像素之间的长程依赖。他们使用一个分支来提取特征,一个 mask 分支来自适应 rescaling 特征。在它们之中,local 分支使用 encoder-decoder 的结构来学习局部注意力,然而 non-local 分支 embed 高斯函数来评估特征图中每两个位置的关系,从而预测 scaling 权重。
Region-recursive Learning
多数的超分模型将 SR 看作一个像素独立的任务,不能将生成的像素之间的内在联系合理的利用。受到 PixelCNN 启发,Dahl 第一次提出了像素循环来进行像素间的生成,其通过使用两个网络来获取全局语义信息和连续生成的联系。这种方法可以用非常低像素的图片来生成真实的头发和皮肤细节。但是这种方法的缺陷在于更长的传播增加了计算的成本和训练的难度。
Learning Strategies
Loss Functions
在超分早期,研究者常常使用像素之间的 L2 loss 来衡量重建的误差与引导模型优化。但后来发现这不能很准确的衡量重建的质量(而且容易使图像变得平滑),因此许多 loss 函数应运而生。
Pixel Loss 常常用于衡量两张图像之间像素与像素的差异。主要包括 L1 loss 和 L2 loss。
另有一种 L1 loss 的变种称之为 Charbonnier loss:
Pixel loss 旨在使得 SR 和真值在像素值上足够的接近。相比于 L1 loss,L2 loss 对小误差的容忍性更强(小于 1 的小数的平方更小),因此会产生更平滑的结果。Pixel loss 实际上是没有考虑图像质量的,其结果缺乏高频细节,而且常常会带有过度平滑的效果。
Content Loss 是用于评估图片的感知质量 (perceptual quality)。主要的做法是使用一个预训练的分类网络,这个网络一般用 \(\phi\) 表示,那么网络第 \(l\) 层提取的高层特征图用 \(\phi^{(l)}\) 表示,定义 loss 如下:
比起 Pixel loss,Content Loss 使 SR 在人类感知上与真值图更加接近,而不是一味追求对应的像素值相近。常常使用 VGG 或者 ResNet 作为 \(\phi\)。
Texture Loss 是在考虑重建图像应该有与目标图像相同的风格,同时受到 Gatys 提出的风格表达的启发,texture loss 被引入 SR。图像的 texture 被看作是不同特征通道之间的联系,并定义为 Gram 矩阵 \(G^{(l)} \in \mathbb{R}^{c_l \times c_l}\)。其中:
上述下标均代表的不同通道。最后 loss 定义如下:
Adversarial Loss 是 GAN 领域的东西。在超分领域,SR 模型被看作生成器,然后另外再定义一个判别器。基于交叉熵 SRGAN 使用了对抗 loss:
以上分别代表生成器和判别器的对抗 loss,\(D(I)\) 代表图像经过判别器后的结果,结果越接近 1,表示判别器觉得它越是真的。\(I_s\) 代表从真值上随机采样的结果。MOS 实验表示尽管使用 Adversarial Loss 和 Content Loss 的 SR 模型在 PSNR 的指标上评价相对低一些,但在感知质量上是很不错的。
Cycle Consistency Loss 是受到 CycleGAN 启发,将其引入至超分领域。总体而言,其不仅考虑如何将 LR \(I\) 变换到 HR \(\hat{I}\),同时使用另外一个 CNN 将 \(\hat{I}\) 变换回另外一张 LR \(I^{\prime}\)。这两张 LR 需要保持一致,因而有:
关于BN
Lim 指出 BN 层会使得每张图像的 scale 信息缺失并且使网络变化失去灵活性,而且当去除 BN 时,会节约 40% 的内存。
Other Improvements
Context-wise Network Fusion
其主要思想为 使用多个 SR 网络进行预测,得到预测结果后将其全部送入独立的卷积层,最后将输出进行求和得到最后的预测结果。
Multi-task Learning
多任务学习主要通过使用类似目标检测、语义分割等任务来获得特定领域的信息来改善泛化能力。在超分领域,Wang 使用语义分割网络来提供语义先验知识,然后生成生成特定的语义细节(SFT-GAN)。此外,考虑到直接超分含有噪声的图片可能会导致噪声的放大,DNSR 分别训练了噪声网络和超分网络,然后将其 concat 到一起,最后进行 fine-tune。
Self-Ensemble
首先将 LR 图片进行不同角度 \((0^{\circ},90^{\circ},180^{\circ},270^{\circ})\) 和水平翻转的 8 种变换。然后将这些图片喂入 SR 模型中得到最后的输出后取它们的均值或者中位数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号