

Oracle数据恢复—Oracle报错system01.dbf需要更多的恢复来保持一致性的数据恢复案例
摘要: Oracle数据库故障:
机房异常断电后,Oracle数据库启库报错:“system01.dbf需要更多的恢复来保持一致性,数据库无法打开”。数据库没有备份,归档日志不连续。用户方提供了Oracle数据库的在线文件,需要恢复zxfg用户的数据。
Oracle数据库恢复方案:
检测数据库故障;尝试挂起并修复数据库;解析数据文件。
阅读全文
Oracle数据库故障:
机房异常断电后,Oracle数据库启库报错:“system01.dbf需要更多的恢复来保持一致性,数据库无法打开”。数据库没有备份,归档日志不连续。用户方提供了Oracle数据库的在线文件,需要恢复zxfg用户的数据。
Oracle数据库恢复方案:
检测数据库故障;尝试挂起并修复数据库;解析数据文件。
阅读全文
Oracle数据库故障:
机房异常断电后,Oracle数据库启库报错:“system01.dbf需要更多的恢复来保持一致性,数据库无法打开”。数据库没有备份,归档日志不连续。用户方提供了Oracle数据库的在线文件,需要恢复zxfg用户的数据。
Oracle数据库恢复方案:
检测数据库故障;尝试挂起并修复数据库;解析数据文件。
阅读全文
posted @ 2024-09-30 12:49
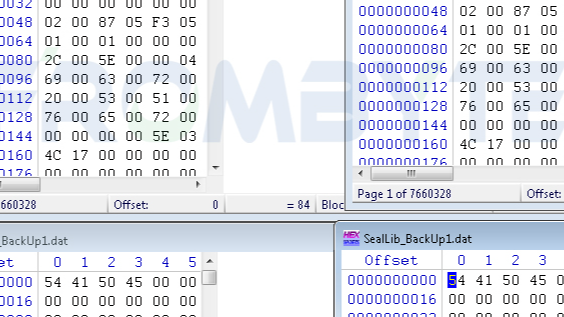 存储中有一组由3块SAS硬盘组建的raid。上层win server操作系统层面划分了3个分区,数据库存放在D分区,备份存放在E分区。
RAID中一块硬盘的指示灯亮红色,D分区无法识别;E分区可识别,但是拷贝文件报错。管理员重启服务器,导致离线的硬盘上线开始同步数据,同步还没有完成就直接强制关机了,之后就没有动过服务器。
存储中有一组由3块SAS硬盘组建的raid。上层win server操作系统层面划分了3个分区,数据库存放在D分区,备份存放在E分区。
RAID中一块硬盘的指示灯亮红色,D分区无法识别;E分区可识别,但是拷贝文件报错。管理员重启服务器,导致离线的硬盘上线开始同步数据,同步还没有完成就直接强制关机了,之后就没有动过服务器。
 一台存储上有一组由16块FC硬盘组建了一组raid。存储前面板上的对应10号和13号硬盘的故障灯亮起,存储映射到redhat linux操作系统服务器上的卷挂载不上,业务中断。
一台存储上有一组由16块FC硬盘组建了一组raid。存储前面板上的对应10号和13号硬盘的故障灯亮起,存储映射到redhat linux操作系统服务器上的卷挂载不上,业务中断。
 服务器数据恢复环境:
SAN环境下一台存储设备中有一组由6块硬盘组建的RAID6磁盘阵列,划分若干LUN,MAP到不同业务的SOLARIS操作系统服务器上。
服务器故障:
用户新增了一台服务器,将存储中的某个LUN映射到新增加的这台服务器上。这个映射的LUN其实之前已经MAP到其他SOLARIS操作系统的服务器上了。由于没有及时发现问题,新增加的这台服务器已经对此LUN做了初始化操作,磁盘报错,重启后发现卷无法挂载。
服务器数据恢复环境:
SAN环境下一台存储设备中有一组由6块硬盘组建的RAID6磁盘阵列,划分若干LUN,MAP到不同业务的SOLARIS操作系统服务器上。
服务器故障:
用户新增了一台服务器,将存储中的某个LUN映射到新增加的这台服务器上。这个映射的LUN其实之前已经MAP到其他SOLARIS操作系统的服务器上了。由于没有及时发现问题,新增加的这台服务器已经对此LUN做了初始化操作,磁盘报错,重启后发现卷无法挂载。
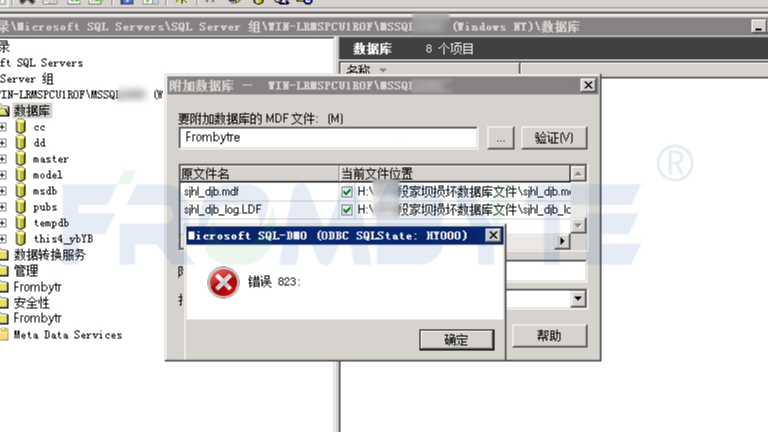 SQL Server附加数据库出现错误823,附加数据库失败。数据库没有备份,无法通过备份恢复数据库。
SQL Server数据库出现823错误的可能原因有:数据库物理页面损坏、数据库物理页面校验值损坏导致无法识别该页面、断电或者文件系统问题导致页面丢失。
SQL Server附加数据库出现错误823,附加数据库失败。数据库没有备份,无法通过备份恢复数据库。
SQL Server数据库出现823错误的可能原因有:数据库物理页面损坏、数据库物理页面校验值损坏导致无法识别该页面、断电或者文件系统问题导致页面丢失。
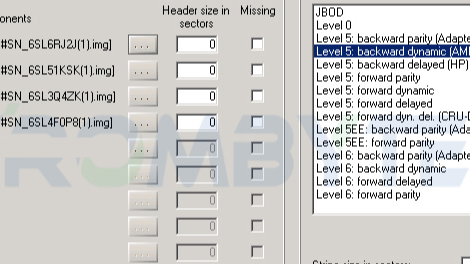 服务器磁盘阵列数据恢复环境:
服务器中有两组分别由4块SAS硬盘组建的raid5磁盘阵列,两组raid5阵列划分LUN,组成LVM结构,格式化为EXT3文件系统。
服务器磁盘阵列故障:
服务器中一组raid5阵列中有一块硬盘离线,热备盘自动上线替换离线硬盘。热备盘上线同步数据过程中又有一块硬盘离线,热备盘同步失败,该组raid5阵列崩溃,LVM结构变得不完整,文件系统无法使用。
硬件工程师对两块离线硬盘进行硬件故障检测,发现先离线硬盘无法识别,初步判断该硬盘存在硬件故障,需要进行开盘修复。后离线硬盘可以正常识别。
服务器磁盘阵列数据恢复环境:
服务器中有两组分别由4块SAS硬盘组建的raid5磁盘阵列,两组raid5阵列划分LUN,组成LVM结构,格式化为EXT3文件系统。
服务器磁盘阵列故障:
服务器中一组raid5阵列中有一块硬盘离线,热备盘自动上线替换离线硬盘。热备盘上线同步数据过程中又有一块硬盘离线,热备盘同步失败,该组raid5阵列崩溃,LVM结构变得不完整,文件系统无法使用。
硬件工程师对两块离线硬盘进行硬件故障检测,发现先离线硬盘无法识别,初步判断该硬盘存在硬件故障,需要进行开盘修复。后离线硬盘可以正常识别。
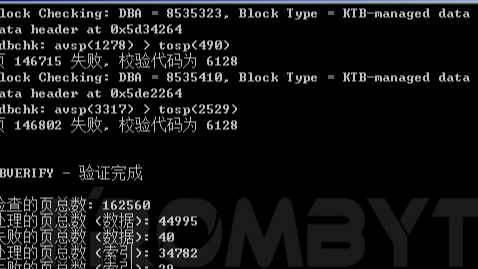 打开oracle数据库报错“system01.dbf需要更多的恢复来保持一致性,数据库无法打开”。
数据库没有备份,无法通过备份去恢复数据库。用户方联系北亚企安数据恢复中心并提供Oracle_Home目录中的所有文件,急需恢复zxfg用户下的数据。
打开oracle数据库报错“system01.dbf需要更多的恢复来保持一致性,数据库无法打开”。
数据库没有备份,无法通过备份去恢复数据库。用户方联系北亚企安数据恢复中心并提供Oracle_Home目录中的所有文件,急需恢复zxfg用户下的数据。
 NetAapp某型号存储,WAFL文件系统。工作人员误操作将NetApp存储中重要数据删除。
NetAapp某型号存储,WAFL文件系统。工作人员误操作将NetApp存储中重要数据删除。
 虚拟化数据恢复环境:
某品牌服务器(部署VMware EXSI虚拟机)+同品牌存储(存放虚拟机文件)。
虚拟化故障:
意外断电导致服务器上某台虚拟机无法正常启动。查看虚拟机配置文件发现这台故障虚拟机除了磁盘文件以外其他配置文件全部丢失,xxx-flat.vmdk磁盘文件和xxx-000001-delta.vmdk快照文件还在。管理员联系VMware工程师寻求帮助。VMware工程师尝试新建一个虚拟机来解决故障,但发现ESXi存储空间不足。于是将故障虚拟机下的xxx-flat.vmdk磁盘文件删除,然后重建一个虚拟机并且分配固定大小的虚拟磁盘。新建虚拟机安装Windows Server操作系统,部署SQL Server数据库环境(管理宏桥和索菲两套应用数据库)。
虚拟化数据恢复环境:
某品牌服务器(部署VMware EXSI虚拟机)+同品牌存储(存放虚拟机文件)。
虚拟化故障:
意外断电导致服务器上某台虚拟机无法正常启动。查看虚拟机配置文件发现这台故障虚拟机除了磁盘文件以外其他配置文件全部丢失,xxx-flat.vmdk磁盘文件和xxx-000001-delta.vmdk快照文件还在。管理员联系VMware工程师寻求帮助。VMware工程师尝试新建一个虚拟机来解决故障,但发现ESXi存储空间不足。于是将故障虚拟机下的xxx-flat.vmdk磁盘文件删除,然后重建一个虚拟机并且分配固定大小的虚拟磁盘。新建虚拟机安装Windows Server操作系统,部署SQL Server数据库环境(管理宏桥和索菲两套应用数据库)。
 服务器数据恢复环境:
一台linux操作系统服务器上跑了几十个网站,服务器上只有一块SATA硬盘。
服务器故障:
服务器突然宕机,尝试再次启动失败。将硬盘拆下检测,发现存在坏扇区。
服务器数据恢复环境:
一台linux操作系统服务器上跑了几十个网站,服务器上只有一块SATA硬盘。
服务器故障:
服务器突然宕机,尝试再次启动失败。将硬盘拆下检测,发现存在坏扇区。
 删除Oracle数据库数据一般有以下2种方式:delete、drop或truncate。下面针对这2种删除oracle数据库数据的方式探讨一下oracle数据库数据恢复方法(不考虑全库备份和利用归档日志)。
删除Oracle数据库数据一般有以下2种方式:delete、drop或truncate。下面针对这2种删除oracle数据库数据的方式探讨一下oracle数据库数据恢复方法(不考虑全库备份和利用归档日志)。
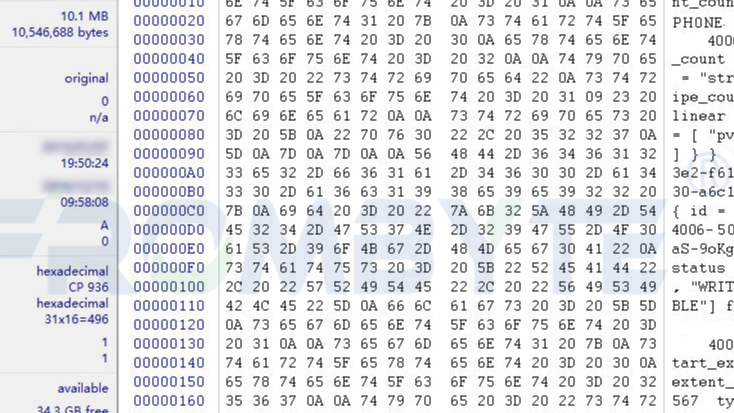 服务器数据恢复环境:
一台服务器中有一组由4块STAT硬盘通过RAID卡组建的RAID10阵列,上层是XenServer虚拟化平台,虚拟机安装Windows Server操作系统,作为Web服务器使用。
服务器故障:
因机房异常断电导致服务器中一台VPS(Xen Server虚拟机)不可用,虚拟磁盘文件丢失。
服务器数据恢复环境:
一台服务器中有一组由4块STAT硬盘通过RAID卡组建的RAID10阵列,上层是XenServer虚拟化平台,虚拟机安装Windows Server操作系统,作为Web服务器使用。
服务器故障:
因机房异常断电导致服务器中一台VPS(Xen Server虚拟机)不可用,虚拟磁盘文件丢失。
 虚拟化技术原理是将硬件虚拟化供不同的虚拟机使用,一台物理机上可以有多台虚拟机。人为误操作或者物理机故障会导致上层虚拟机不可用,甚至虚拟机里的重要数据丢失。下面给大家分享一个vmware虚拟化误操作还原快照的数据恢复案例。
虚拟化数据恢复环境:
一台由物理机迁移到EXSI上面的虚拟机,迁移完成后做了一个快照。该虚拟机上运行SQL Server数据库,记录了几年的数据。
EXSI虚拟化平台上一共有数十台虚拟机,EXSI连接了一台EVA存储,所有的虚拟机(包括故障虚拟机)都放在EVA存储上。
虚拟化技术原理是将硬件虚拟化供不同的虚拟机使用,一台物理机上可以有多台虚拟机。人为误操作或者物理机故障会导致上层虚拟机不可用,甚至虚拟机里的重要数据丢失。下面给大家分享一个vmware虚拟化误操作还原快照的数据恢复案例。
虚拟化数据恢复环境:
一台由物理机迁移到EXSI上面的虚拟机,迁移完成后做了一个快照。该虚拟机上运行SQL Server数据库,记录了几年的数据。
EXSI虚拟化平台上一共有数十台虚拟机,EXSI连接了一台EVA存储,所有的虚拟机(包括故障虚拟机)都放在EVA存储上。
 出于尽可能避免数据灾难的设计初衷,RAID解决了3个问题:容量问题、IO性能问题、存储安全(冗余)问题。从数据恢复的角度讨论RAID的存储安全问题。
常见的起到存储安全作用的RAID方案有RAID1、RAID5及其变形。基本设计思路是相似的:当部分数据异常时,可通过特定算法将数据还原出来。以RAID5为例:如果要记录两个数字,可以通过再多记录这两个数字的和来达到记录冗余性的目的。例如记录3和5,同时再记录这2个数字的和8。在不记得到底是几和5的情况下,只需要用8-5就可以算出这个丢失的数字了,其余情况依此类推。
出于尽可能避免数据灾难的设计初衷,RAID解决了3个问题:容量问题、IO性能问题、存储安全(冗余)问题。从数据恢复的角度讨论RAID的存储安全问题。
常见的起到存储安全作用的RAID方案有RAID1、RAID5及其变形。基本设计思路是相似的:当部分数据异常时,可通过特定算法将数据还原出来。以RAID5为例:如果要记录两个数字,可以通过再多记录这两个数字的和来达到记录冗余性的目的。例如记录3和5,同时再记录这2个数字的和8。在不记得到底是几和5的情况下,只需要用8-5就可以算出这个丢失的数字了,其余情况依此类推。
 EMC NAS(Isilon S200),共3个节点,每个节点配置12块STAT硬盘。数据分两部分:一部分数据为vmware虚拟机(WEB服务器),通过NFS协议共享到ESX主机;另一部分数据为视频教学文件,通过CIFS协议共享给虚拟机(WEB服务器)。
外部入侵导致视重要数据被删除,其中包括MSSQL数据库,MP4、ASF和TS类型的视频教学文件。主要是删除了NFS共享的所有数据(虚拟机),而CIFS共享的数据则没有影响。
EMC NAS(Isilon S200),共3个节点,每个节点配置12块STAT硬盘。数据分两部分:一部分数据为vmware虚拟机(WEB服务器),通过NFS协议共享到ESX主机;另一部分数据为视频教学文件,通过CIFS协议共享给虚拟机(WEB服务器)。
外部入侵导致视重要数据被删除,其中包括MSSQL数据库,MP4、ASF和TS类型的视频教学文件。主要是删除了NFS共享的所有数据(虚拟机),而CIFS共享的数据则没有影响。
 一台NetApp存储配置24块磁盘。管理员几个月之前删除一个文件夹,后期发现这个文件夹中的数据很重要,需要恢复。
根据NetApp文件系统WAFL的特性,新写入数据覆盖之前的数据的可能性不大,可以尝试恢复这个很久之前删除的文件夹。
一台NetApp存储配置24块磁盘。管理员几个月之前删除一个文件夹,后期发现这个文件夹中的数据很重要,需要恢复。
根据NetApp文件系统WAFL的特性,新写入数据覆盖之前的数据的可能性不大,可以尝试恢复这个很久之前删除的文件夹。
 服务器存储数据恢复环境:
一台infortrend存储中有一组由12块硬盘组建的RAID6阵列。RAID6阵列空间划分了一个LUN,映射到WINDOWS SERVER系统上。WINDOWS SERVER系统上划分了一个GPT分区。
服务器存储故障:
存储在运行过程中突然无法访问。管理员查看后发现raid6阵列中有3块盘离线。管理员通过非常规手段上线存储并开始rebuild,但通过主机访问时发现分区打不开,存储中所有数据均无法访问。咨询一些专业人士后基本上确认存储中的数据已经破坏。为避免情况进一步恶化,管理员中止rebuild,将存储关机后寻求当地一家数据恢复公司的帮助。经过该公司的全力恢复后,发现还是有大量数据丢失以及大量的文件无法打开。
服务器存储数据恢复环境:
一台infortrend存储中有一组由12块硬盘组建的RAID6阵列。RAID6阵列空间划分了一个LUN,映射到WINDOWS SERVER系统上。WINDOWS SERVER系统上划分了一个GPT分区。
服务器存储故障:
存储在运行过程中突然无法访问。管理员查看后发现raid6阵列中有3块盘离线。管理员通过非常规手段上线存储并开始rebuild,但通过主机访问时发现分区打不开,存储中所有数据均无法访问。咨询一些专业人士后基本上确认存储中的数据已经破坏。为避免情况进一步恶化,管理员中止rebuild,将存储关机后寻求当地一家数据恢复公司的帮助。经过该公司的全力恢复后,发现还是有大量数据丢失以及大量的文件无法打开。
 服务器存储数据恢复环境:
一台存储中有一组由7块硬盘组建的RAID5阵列,存储中还有另外3块盘是raid中掉线的硬盘(硬盘掉线了,管理员只是添加一块的新的硬盘做rebuild,并没有将掉线的硬盘拔掉)。整个RAID5阵列的存储空间划分了一个LUN。
服务器存储故障:
硬盘出现故障导致存储中阵列瘫痪。
和管理员沟通,据管理员说是磁盘阵列中某些硬盘出现故障导致存储不可用,初步判断RAID中有硬盘掉线了。
服务器存储数据恢复环境:
一台存储中有一组由7块硬盘组建的RAID5阵列,存储中还有另外3块盘是raid中掉线的硬盘(硬盘掉线了,管理员只是添加一块的新的硬盘做rebuild,并没有将掉线的硬盘拔掉)。整个RAID5阵列的存储空间划分了一个LUN。
服务器存储故障:
硬盘出现故障导致存储中阵列瘫痪。
和管理员沟通,据管理员说是磁盘阵列中某些硬盘出现故障导致存储不可用,初步判断RAID中有硬盘掉线了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号