CPU性能实战分析
1.从平均负载谈起
我们每次发现线上系统变慢时,第一件事往往都会使用top或者uptime命令查看cpu的负载以及占用率,比如top命令会有下面的结果:
top - 15:51:39 up 84 days, 1:24, 4 users, load average: 0.20, 0.22, 0.18
Tasks: 165 total, 1 running, 163 sleeping, 1 stopped, 0 zombie
%Cpu(s): 2.6 us, 0.8 sy, 0.0 ni, 95.8 id, 0.4 wa, 0.0 hi, 0.4 si, 0.0 st
MiB Mem : 31775.4 total, 404.9 free, 16313.4 used, 15057.1 buff/cache
MiB Swap: 8192.0 total, 8101.0 free, 91.0 used. 14823.6 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
411122 libvirt+ 20 0 10.5g 8.1g 5072 S 4.7 25.9 6232:25 qemu-system-x86
272695 libvirt+ 20 0 10.5g 8.0g 5148 S 4.3 25.8 3154:25 qemu-system-x86
712260 root 20 0 2162060 246380 184740 S 2.3 0.8 547:03.34 clickhouse-serv
42 root 25 5 0 0 0 S 1.7 0.0 1017:25 ksmd
272710 root 20 0 0 0 0 S 0.3 0.0 53:57.73 kvm-pit/272695
810400 root 20 0 9252 3840 3088 R 0.3 0.0 0:00.04 top
1 root 20 0 169092 13184 8460 S 0.0 0.0 2:19.67 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:01.44 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H-kblockd
9 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
10 root 20 0 0 0 0 S 0.0 0.0 1:09.54 ksoftirqd/0
11 root 20 0 0 0 0 I 0.0 0.0 63:12.44 rcu_sched但是,你真的知道这里每列输出的含义吗?
就拿第一行输出来说,前面几项我们都非常熟悉:
15:51:39 // 当前时间
up 84 days, 1:24, // 系统运行的时间
4 users // 当前登录的用户数而后面load average之后的3个数字,则依次是过去1分钟、5分钟、15分钟的平均负载。
平均负载这个词对我们来说可能既熟悉又陌生,熟悉是因为我们每天工作中都会提到这个词,但是陌生在于是否能够理解它背后的含义?有人可能会说平均负载是单位时间内cpu的使用率,其实这样的理解是错误的,我们可以通过命令man uptime来查看其中对于平均负载的解释。
简单来说,平均负载(Load Average)就是指单位时间内,系统处于可运行状态或不可中断状态的平均进程数量,可以理解为平均活跃过的进程数量,这玩意和cpu使用率并没有直接的关系,那么什么是进程的可运行状态和不可中断状态呢?
可运行状态是指进程正在使用CPU或者正在等待CPU的状态,也就是进程的运行态和就绪态,我们用ps命令看到进程的状态为R或者R+这样;而不可中断状态的进程则是正处于内核态执行流程中的进程,并且这些流程是不可被打断的,最常见的就是等待硬件设备的I/O响应,也就是用ps命令看到的D状态,这也是操作系统对硬件的一种保护机制避免不一致的状态出现;除了这两个关键状态外,还有S表示休眠状态,以及Z表示僵尸进程等。
总的来说,linux中常见的进程状态有下面这几种:
D uninterruptible sleep,不可中断状态,一般就是I/O状态,随着I/O状态的变化会导致CPU负载的变化
R running or runnable,运行或可运行,包括就绪队列上的进程
S interruptible sleep,可中断睡眠状态,一般是等待事件完成
T stopped by job control signal,由作业信号停止
Z 僵尸进程,属于终止状态但尚未被父进程回收
I 空闲状态,也就是不可中断睡眠的内核线程,和状态D相比,状态I则表示没有任何负载,因此不会计入CPU时间也不会导致负载升高
具体进程状态的含义可以通过ps的帮助手册查看,通过上面的描述直观上可以这么理解,平均负载就是单位时间内活跃过的进程数,实际上是活跃进程数指数衰减的平均值,因此最理想的情况下就是每个cpu上刚好运行1个进程,这样每个cpu都得到了充分的利用,假设我们看到平均负载是8,那么意味着什么?可以举例说明如下:
- 如果我们的cpu恰好是8核,意味着所有的cpu都刚好被完全占用。
- 如果我们的cpu是16核,说明cpu有一半的空闲。
- 但如果我们只有4核,则说明有一般的进程在竞争CPU。
讲完上面这些,那么我们该如何判断CPU负载是不是正常,首先我们要知道系统有几个CPU,可以在/proc/cpuinfo中读取到相关的信息:
grep 'model name' /proc/cpuinfo | wc -l有了CPU个数,我们就可以得知,当平均负载值比CPU个数还大时,系统就出现了过载。那么这3个值,应该看哪个?
实际上上面这3个值都要看,这3个值给我们提供了分析系统负载趋势的数据来源,让我们能更全面的了解目前的负载情况,就好像天气预报一样,我们可能更关心天气的变化情况,那么对于这3个值可以大致按照如下的思路分析:
- 如果这3个值基本相同,那么说明最近1分钟、5分钟、15分钟内的负载都比较平稳,说明系统最近一段时间整体运行波动不大。
- 但如果过去1分钟的值远远小于过去15分钟的值,则说明系统负载在减少,过去15分钟系统负载比较重,但是慢慢减少了。
- 反过来如果过去1分钟的值远远大于过去15分钟的值,就说明系统负载正在增大,增加可能是临时的,也可能是持续的,需要进一步观察。
不管是过去1分钟还是15分钟,只要是负载值超过了cpu个数,那么则意味着系统正在发生或者已经发生了过载问题,系统开始变得繁忙或者拥堵了,这时候就需要分析哪个进程导致的问题,并且想办法来优化。最理想的情况下的负载值 = CPU个数 * (0.7~0.8)左右,一旦过高,就可能导致进程响应变慢,对服务造成影响。
虽然CPU平均负载和CPU使用率并没有直接的关系,但是某些情况下会出现相似的表现,比如:
- 对于CPU密集型进程,进程越多会导致CPU利用率越高,同时会引起负载升高,这两者变化是一致的。
- 对于I/O密集型进程,等待I/O也会导致平均负载升高,但是CPU利用率却不高。
- 大量等待CPU时间片的进程调度也会导致平均负载升高,CPU利用率的体现也很高。
上面举例说明了CPU平均负载和利用率的关系,其他的不再多说,接下来我们进入实战环节来看一下常见的各类情况如何分析。
2.工具准备
模拟系统负载可以使用工具stress,同时还要安装必要的sysstat包从而可以使用iostat、pidstat等工具查看资源占用的情况,如果是Ubuntu系统可以使用下面的命令安装:
apt install stress如果是CentOS可以使用下面的命令安装:
yum install epel-release
yum install stress安装之后可以查看相应的帮助来学习使用:
stress --help
# 版本号
stress --version当然我们也可以不借助于工具,自己编写代码测试,同样可以实现工具的效果。
3.模拟用户空间高CPU消耗
我们当前的机器是4核,我们开2个进程来模拟200%的cpu占用:
# --cpu参数等同于-c
stress --cpu 2 --timeout 180然后我们打开top或者使用uptime看,负载不断升高,跑2分多钟后负载接近于2:
17:18:04 up 87 days, 23:49, 4 users, load average: 2.01, 1.00, 0.40同时看top中cpu占用率每个进程也是100%:
top - 17:19:09 up 87 days, 23:50, 4 users, load average: 2.00, 1.21, 0.52
Tasks: 148 total, 3 running, 145 sleeping, 0 stopped, 0 zombie
%Cpu(s): 49.3 us, 0.2 sy, 0.0 ni, 48.1 id, 0.7 wa, 0.0 hi, 1.6 si, 0.0 st
MiB Mem : 31775.6 total, 3655.0 free, 8232.9 used, 19887.7 buff/cache
MiB Swap: 8192.0 total, 8190.7 free, 1.3 used. 23081.2 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
347541 root 20 0 3856 104 0 R 100.0 0.0 2:40.72 stress
347542 root 20 0 3856 104 0 R 99.7 0.0 2:40.72 stress使用mpstat也可以方便查看到用户空间占用的变化:
05:21:03 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
05:21:08 PM all 5.67 0.00 0.25 0.40 0.00 0.50 0.00 0.45 0.00 92.73
05:21:08 PM 0 11.34 0.00 0.40 1.01 0.00 0.20 0.00 0.00 0.00 87.04
05:21:08 PM 1 11.38 0.00 0.00 0.61 0.00 0.00 0.00 0.61 0.00 87.40
05:21:08 PM 2 0.00 0.00 0.00 0.00 0.00 1.77 0.00 0.39 0.00 97.83
05:21:08 PM 3 0.20 0.00 0.60 0.00 0.00 0.00 0.00 0.80 0.00 98.40
05:21:08 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
05:21:13 PM all 48.01 0.00 0.19 0.34 0.00 3.46 0.00 0.72 0.00 47.24
05:21:13 PM 0 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
05:21:13 PM 1 99.80 0.00 0.00 0.00 0.00 0.20 0.00 0.00 0.00 0.00
05:21:13 PM 2 0.00 0.00 0.35 0.17 0.00 11.52 0.00 1.75 0.00 86.21
05:21:13 PM 3 0.00 0.00 0.39 1.18 0.00 0.99 0.00 0.99 0.00 96.45这个很好理解,因为是纯计算任务所以用几个cpu平均负载就会趋近于几。
4.模拟内存消耗
内存和CPU的关系也是难舍难分,同样我们可以使用stress模拟内存消耗来窥探内存和CPU使用之间的关系,先看一个最简单的开辟指定大小的内存并一直占用着:
# --vm指定开辟子进程数量 --vm-bytes每个进程分配内存的大小 --vm-keep表示内存一直占用
stress --vm 2 --vm-bytes 500M --vm-keep执行之后使用free或者top可以看到进程占用了1GB左右的内存,当然这个过于简单,可以指定内存申请的频率如:
# --vm-hang指定释放频率
stress --vm 2 --vm-bytes 500M --vm-hang 5这样表示每5s释放一次内存然后再申请,我们看CPU每5s会有一次小的波动:
Tasks: 147 total, 1 running, 146 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.2 us, 2.7 sy, 0.0 ni, 95.9 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st
MiB Mem : 31775.6 total, 2679.7 free, 9179.6 used, 19916.3 buff/cache
MiB Swap: 8192.0 total, 8190.7 free, 1.3 used. 22134.5 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
348349 root 20 0 515860 512204 208 S 6.6 1.6 0:00.56 stress --vm 2 --vm-bytes 500+
348350 root 20 0 515860 512204 208 S 6.6 1.6 0:00.56 stress --vm 2 --vm-bytes 500+原因是因为这2个进程申请内存时会发出系统调用,因此cpu占用其实是内核空间的占用率,另外我们还会注意到此时查看剩余内存并没有频繁变化,原因是程序重复申请的内存系统并不会真正的释放掉,而是仅仅标记为释放,方便下次重复利用。
稍微热身之后,来点重磅的,接下来就使用stress模拟连续写内存,看看具体的变化如何:
# --vm-stride写内存的步长
stress --vm 2 --vm-bytes 500M --vm-stride 16
stress --vm 2 --vm-bytes 500M --vm-stride 128
stress --vm 2 --vm-bytes 500M --vm-stride 1024
stress --vm 2 --vm-bytes 500M --vm-stride 4096
stress --vm 2 --vm-bytes 500M --vm-stride 1M我们主要关注CPU的变化:
1.步长16B
top - 19:05:30 up 88 days, 1:36, 4 users, load average: 0.39, 0.12, 0.03
Tasks: 147 total, 4 running, 143 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.6 us, 0.0 sy, 0.0 ni, 88.3 id, 0.0 wa, 0.0 hi, 11.1 si, 0.0 st
%Cpu1 : 45.0 us, 55.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 46.2 us, 53.8 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 1.0 us, 0.0 sy, 0.0 ni, 98.3 id, 0.0 wa, 0.0 hi, 0.7 si, 0.0 st
MiB Mem : 31775.6 total, 2680.0 free, 9176.7 used, 19918.9 buff/cache
MiB Swap: 8192.0 total, 8190.7 free, 1.3 used. 22137.4 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
348359 root 20 0 515860 512204 208 R 100.0 1.6 0:07.64 stress
348360 root 20 0 515860 512204 208 R 100.0 1.6 0:07.65 stress可以看到每个进程CPU占用100%,这100%由45%左右的用户空间占用以及55%左右的内核空间占用。
2.步长128B
top - 19:07:37 up 88 days, 1:38, 4 users, load average: 0.59, 0.24, 0.08
Tasks: 147 total, 3 running, 144 sleeping, 0 stopped, 0 zombie
%Cpu0 : 1.8 us, 0.4 sy, 0.0 ni, 87.1 id, 0.0 wa, 0.0 hi, 10.7 si, 0.0 st
%Cpu1 : 37.1 us, 62.9 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 2.0 us, 1.2 sy, 0.0 ni, 95.2 id, 0.0 wa, 0.0 hi, 1.6 si, 0.0 st
%Cpu3 : 38.8 us, 61.2 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 31775.6 total, 2779.7 free, 9076.5 used, 19919.5 buff/cache
MiB Swap: 8192.0 total, 8190.7 free, 1.3 used. 22237.6 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
348363 root 20 0 515860 395932 208 R 100.0 1.2 0:14.50 stress
348362 root 20 0 515860 395932 208 R 99.6 1.2 0:14.49 stress同样是总的CPU占用100%,用户空间利用率38%左右,内核空间为62%左右。
3.步长1024B即1K
top - 19:09:12 up 88 days, 1:40, 4 users, load average: 1.02, 0.54, 0.21
Tasks: 147 total, 3 running, 144 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.3 us, 0.3 sy, 0.0 ni, 85.7 id, 2.4 wa, 0.0 hi, 11.3 si, 0.0 st
%Cpu1 : 29.3 us, 70.7 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 0.7 us, 0.0 sy, 0.0 ni, 98.3 id, 0.7 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu3 : 29.7 us, 70.3 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 31775.6 total, 3113.9 free, 8741.6 used, 19920.1 buff/cache
MiB Swap: 8192.0 total, 8190.7 free, 1.3 used. 22572.5 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
348366 root 20 0 515860 240828 272 R 100.0 0.7 0:05.58 stress
348367 root 20 0 515860 202036 272 R 100.0 0.6 0:05.58 stress4.步长4K
top - 19:13:18 up 88 days, 1:44, 4 users, load average: 1.75, 1.18, 0.55
Tasks: 147 total, 3 running, 144 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.9 us, 0.0 sy, 0.0 ni, 90.2 id, 0.0 wa, 0.0 hi, 8.9 si, 0.0 st
%Cpu1 : 25.2 us, 74.8 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 25.2 us, 74.8 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 0.0 us, 1.0 sy, 0.0 ni, 97.1 id, 0.0 wa, 0.0 hi, 1.9 si, 0.0 st
MiB Mem : 31775.6 total, 3647.7 free, 8206.5 used, 19921.4 buff/cache
MiB Swap: 8192.0 total, 8190.7 free, 1.3 used. 23107.4 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
348390 root 20 0 515860 20432 272 R 100.0 0.1 0:03.06 stress
348391 root 20 0 515860 24920 272 R 100.0 0.1 0:03.06 stress5.步长1M
top - 19:12:26 up 88 days, 1:43, 4 users, load average: 1.78, 1.07, 0.48
Tasks: 147 total, 3 running, 144 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.0 us, 0.0 sy, 0.0 ni, 95.7 id, 0.0 wa, 0.0 hi, 4.3 si, 0.0 st
%Cpu1 : 0.0 us, 0.0 sy, 0.0 ni, 80.0 id, 0.0 wa, 0.0 hi, 20.0 si, 0.0 st
%Cpu2 : 13.0 us, 87.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 13.3 us, 86.7 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 31775.6 total, 3669.1 free, 8185.3 used, 19921.2 buff/cache
MiB Swap: 8192.0 total, 8190.7 free, 1.3 used. 23128.8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
348383 root 20 0 1052436 4064 272 R 97.8 0.0 0:27.70 stress
348384 root 20 0 1052436 4064 272 R 97.8 0.0 0:27.70 stress通过上面的变化可以发现一个有趣的规律,就是随着写内存步长的增大,用户空间CPU占用率不断降低(us),内核空间占用率不断升高(sy),而且变化相当明显,事实上当步长为1Byte时,用户空间占用率接近100%,内核空间的占用率非常小,出现这个现象的原因究竟是为何?
要理解这个现象,首先要明白linux系统虚拟内存管理的机制,linux采用多级页表管理虚拟内存,内存分配的单元叫做页,每个页的物理地址空间和虚拟地址空间都是连续的,通常大小是4K,而页表(Page Table)是一个由虚拟地址到物理地址的映射表,严格来说是虚拟页号到物理页号的映射,每个进程单独维护1个页表,因此每个进程看起来虚拟地址空间是连续的无限大的,但是物理内存却是分散的,因此给定虚拟地址可以计算页号和偏移,然后通过查找页表可以找到物理页号然后加上偏移就得到物理地址,可以看下图:
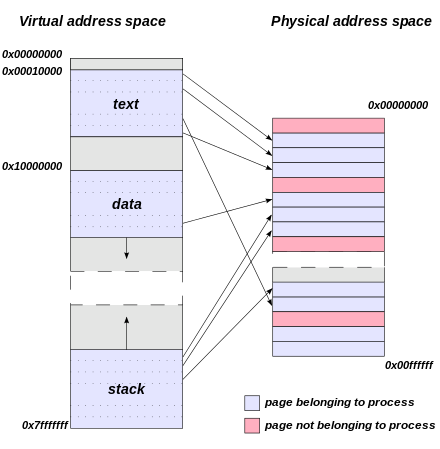
关于页表的细节先不多讲,我们只要知道页表用来做虚拟地址和物理地址的转换即可,而操作系统的作用就是屏蔽硬件的同时采用受限直接执行(limited direct execution)的方式,通过用户模式到内核模式的转换从而防止软件对硬件的破坏,所以我们每次查找页表的过程其实就是内核模式在做这次转换,因此此时是内核空间在占用CPU,体现就是sy的占用,但是由于单级页表占用空间过大的问题,现代linux普遍采用多级页表(Multilevel page tables)进行内存的映射,比如x86下面的3级页表:

至于多级页表如何节省空间有时间再另开1篇文章详细介绍,总之多级页表是一种时间换空间的思想,固然可以节省空间,只是会进行多次内存访问,性能有所下降,所以现代CPU中都有1个专用的芯片叫做TLB,全称是地址变换高速缓冲(Translation-Lookaside Buffer),这个芯片会缓存我们用过的虚拟内存页号,当我们在同一个内存页操作的时候,直接通过查询TLB,而无需通过从内存中查找页表就可以直接得到物理页号,不过TLB的大小和CPU高速缓存一样速度极快但是空间非常小,这就要求我们的程序具有良好的空间局部性,从而减少仿存的开销。
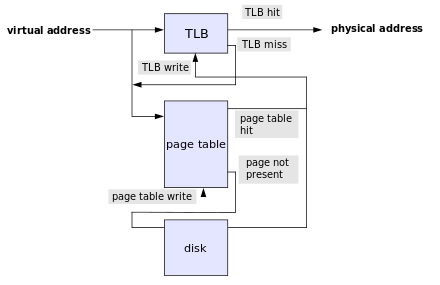
好了,有了TLB我们就可以不用查询页表通过虚拟地址直接找到物理地址,接下来我们就可以向物理地址写入数据了,同样向内存写入数据也属于操作系统的保护范围,由内核来完成,CPU也不是直接就向内存写入数据,而是直接操作CPU Cache,再由CPU Cache通过缓存一致性协议同步至物理内存,CPU同样也分为3级缓存,一级缓存速度最快但是空间也最小,通常只有32K,L1和L2 Cache通常是每个CPU核心单独一个,L3 Cache是多核共享的,下面这是一个物理分布图:

可以抽象出来如下:
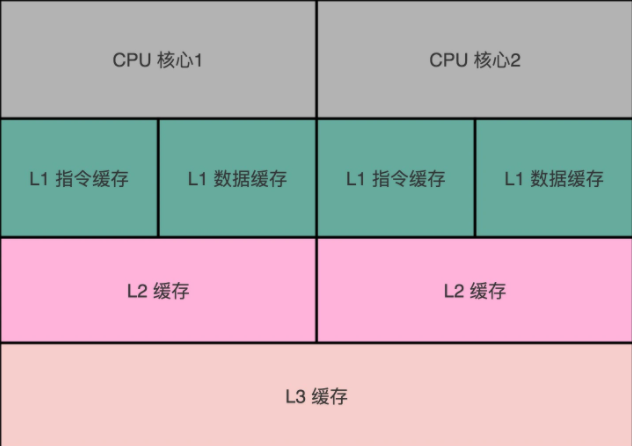
同样CPU缓存也有最小单元,这个最小单元叫做缓存块(Cache Line),通常这个大小是64B,也就是从内存中缓存数据的最小单元是64B,如果在这个范围内多次写,那么也不用每次都访问数据而只需要写缓存就好了,和TLB缓存地址相比,CPU缓存主要缓存的是数据本身,就是程序的指令和数据。
综上有了TLB和CPU Cache如果我们的操作具有局部性,那么CPU需要等待的时间就会非常短,这样用户空间利用率就能上来,而相反,如果程序不具备局部性而是跨度非常大,那么TLB和CPU Cache几乎起不到作用,相当于每次都得通过页表寻址并且每次都得同步cpu缓存,那么相当于多出好几次的内存访问,系统内核态工作时间变长,cpu会等待内核态仿存,所以内核利用率会增高,此时的表现就是程序性能变低。
根据这些分析,上面的测试出现的现象就不难理解了,开始步长非常小的时候,多次操作都集中在1个内存页内,因此地址转换和数据访问会多次被TLB以及CPU Cache命中,拿步长16来说,平均256次才需要从查找1次页表,cpu就有更多的周期进行实际的工作,所以用户空间利用率比较好,但是随着步长的增大,需要访问内存的次数同样情况下就会变多,最后的时候每次操作都需要访问页表,重新加载缓存等,完全不具备局部性的特征,cpu大部分时钟周期内都处于等待状态,所以内核空间的占用率迅速增长至将近90%,这样我们就通过现象和实际和原理分析,来揭示内存和CPU之间的关系。
5.模拟I/O wait
说到I/O wait,这和我们日常工作有着太多的关系,但凡做开发总是一个绕不过去的话题,同样我们也是通过模拟I/O阻塞来浅析这其中的联系,使用stress可以不断地执行刷盘:
stress -i 2查看cpu占用如下:
top - 20:15:17 up 88 days, 2:46, 4 users, load average: 0.59, 0.26, 0.19
Tasks: 147 total, 1 running, 146 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.3 us, 3.3 sy, 0.0 ni, 50.8 id, 39.8 wa, 0.0 hi, 5.7 si, 0.0 st
%Cpu1 : 1.0 us, 4.0 sy, 0.0 ni, 73.9 id, 20.7 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu2 : 1.3 us, 1.3 sy, 0.0 ni, 94.4 id, 2.3 wa, 0.0 hi, 0.7 si, 0.0 st
%Cpu3 : 0.7 us, 4.7 sy, 0.0 ni, 73.2 id, 21.4 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 31775.6 total, 3656.3 free, 8204.1 used, 19915.2 buff/cache
MiB Swap: 8192.0 total, 8190.7 free, 1.3 used. 23110.0 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
348459 root 20 0 3856 100 0 D 7.6 0.0 0:00.60 stress
348458 root 20 0 3856 100 0 D 7.0 0.0 0:00.62 stress可以发现I/O wait每个cpu核心占用了20~40%,同时看平均负载也已经上升至2左右:
20:17:29 up 88 days, 2:48, 4 users, load average: 1.95, 0.92, 0.45我们通过执行iotop命令也可以发现io占用高的进程:
Total DISK READ: 0.00 B/s | Total DISK WRITE: 0.00 B/s
Current DISK READ: 0.00 B/s | Current DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
348458 be/4 root 0.00 B/s 0.00 B/s 0.00 % 93.12 % stress -i 2
348459 be/4 root 0.00 B/s 0.00 B/s 0.00 % 92.03 % stress -i 2另外通过pidstat也可以查找对应的进程,通过iostat可以看到对应磁盘的tps非常高:

可以看到在这个模拟中,写入硬盘的数据量或者说带宽并不高,而是频繁的向磁盘sync导致io等待很长,那么我们怎么用程序来模拟这个情况呢?
我们可能会想到用程序模拟写入字节流,用python先写一段代码如下:
f = open('test', 'w')
while True:
f.write('abc')
f.close()跑起来之后,我们看CPU占用如下:
top - 08:24:21 up 88 days, 14:55, 3 users, load average: 0.26, 0.22, 0.15
Tasks: 145 total, 2 running, 143 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.7 us, 0.0 sy, 0.0 ni, 99.0 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.0 us, 0.0 sy, 0.0 ni, 99.7 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 98.3 us, 1.7 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 0.3 us, 0.3 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 31775.6 total, 3136.4 free, 8213.5 used, 20425.7 buff/cache
MiB Swap: 8192.0 total, 8191.0 free, 1.0 used. 23100.7 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
350271 root 20 0 16432 10176 6552 R 100.0 0.0 0:10.84 python3查看磁盘占用:
iostat -d -t 1 -p /dev/sda308/04/2021 08:40:50 AM
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
sda3 0.00 0.00 0.00 0.00 0 0 0
08/04/2021 08:40:51 AM
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
sda3 0.00 0.00 0.00 0.00 0 0 0
08/04/2021 08:40:52 AM
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
sda3 17.00 0.00 116.00 0.00 0 116 0查看iotop的写入带宽:
Total DISK READ: 0.00 B/s | Total DISK WRITE: 32.41 M/s
Current DISK READ: 0.00 B/s | Current DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
350655 be/4 root 0.00 B/s 32.41 M/s 0.00 % 0.00 % python3我们会发现情况并不是我们想象的那样,相反的是用户模式几乎占用了100%的CPU,查看磁盘发现好大会才有一次较大的写盘,大部分情况下写入带宽都是接近于0,但是平均的写盘速度却达到30M/s以上,通过这样分析我们可能能猜出问题所在,我们的写入的数据好像是汇总之后批量写入的,而事实上确实是这样,想要彻底理解这个问题首先要了解linux文件系统的机制,文件系统、缓存、缓冲以及硬件存储之间的关系如下:
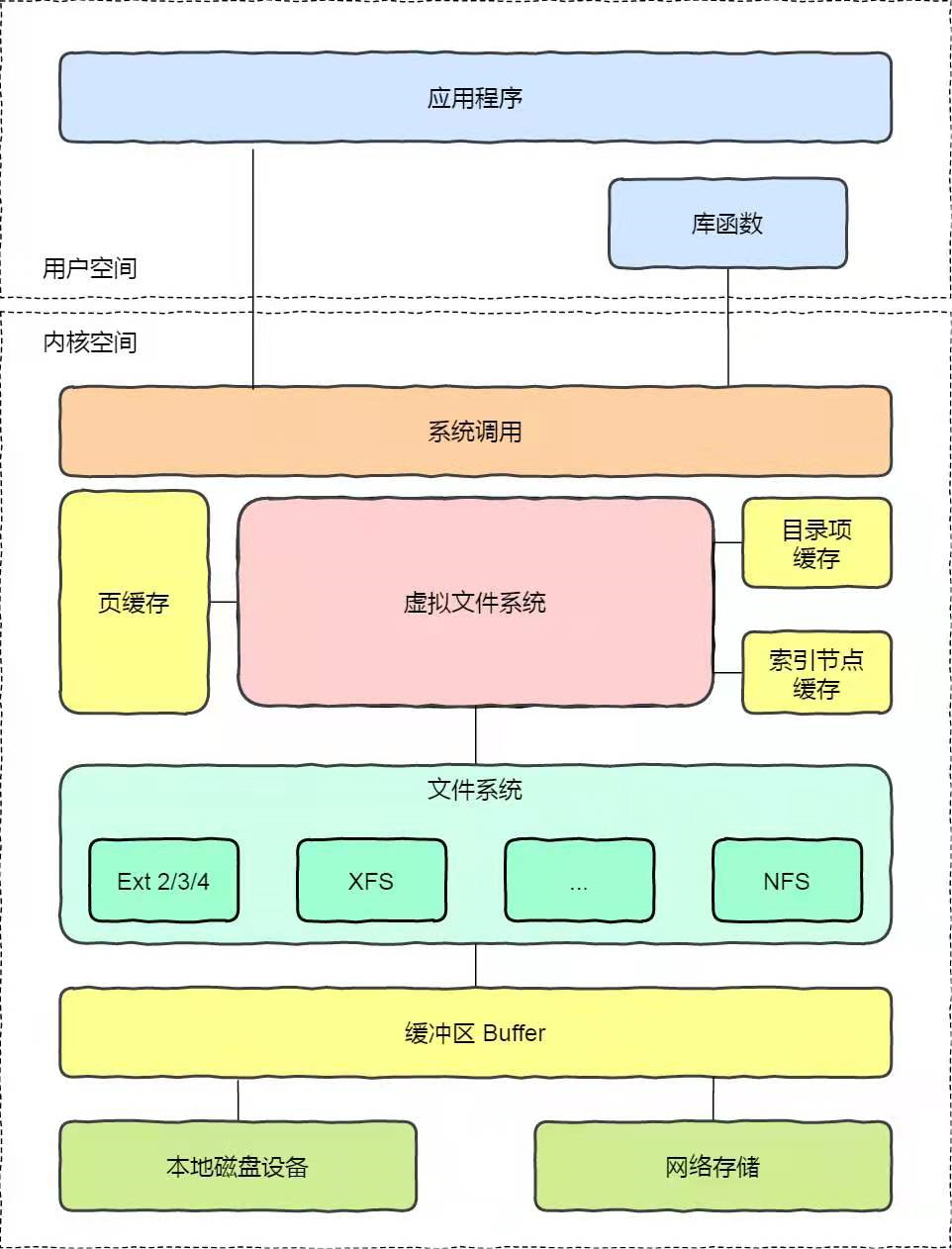
好吧,有了这张图我们就能知道使用f.write其实是发起系统调用,由内核执行文件系统的写入操作,数据是优先被写到系统的缓冲区Buffer中,也就是内存中的一块区域,等缓冲区满了之后再刷到硬盘上,所以写缓冲区基本上就是写内存,速度和硬盘差了不是1个量级,也就是说此时系统调用的时间极短,系统将数据交给文件系统后剩下的就由文件系统完成操作即可,所以此时大量的CPU用在用户代码上也就是那个while循环上,因此内核占用率和iowait几乎都没有,这个时候可能你会想,加个flush不就完事了?然后我们修改代码试一下每次都sync会怎么样:
f = open('test', 'w')
while True:
f.write('abc')
f.flush()查看CPU占用:
top - 09:02:32 up 88 days, 15:33, 3 users, load average: 0.28, 0.09, 0.10
Tasks: 143 total, 2 running, 141 sleeping, 0 stopped, 0 zombie
%Cpu0 : 2.2 us, 0.0 sy, 0.0 ni, 97.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.0 us, 0.0 sy, 0.0 ni, 89.4 id, 6.4 wa, 0.0 hi, 4.3 si, 0.0 st
%Cpu2 : 0.0 us, 0.0 sy, 0.0 ni, 97.8 id, 2.2 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 50.0 us, 50.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 31775.6 total, 4435.8 free, 8247.0 used, 19092.8 buff/cache
MiB Swap: 8192.0 total, 8191.0 free, 1.0 used. 23067.1 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
350655 root 20 0 16432 10140 6516 R 97.8 0.0 2:37.88 python3查看硬盘写入:
08/04/2021 09:03:58 AM
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
sda3 0.00 0.00 0.00 0.00 0 0 0
08/04/2021 09:03:59 AM
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
sda3 0.00 0.00 0.00 0.00 0 0 0
08/04/2021 09:04:00 AM
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
sda3 34.00 0.00 17524.00 0.00 0 17524 0
08/04/2021 09:04:01 AM
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
sda3 54.00 0.00 26848.00 0.00 0 26848 0
08/04/2021 09:04:02 AM
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
sda3 11.00 0.00 432.00 0.00 0 432 0
08/04/2021 09:04:03 AM
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
sda3 0.00 0.00 0.00 0.00 0 0 0查看写入平均带宽:
Total DISK READ: 0.00 B/s | Total DISK WRITE: 1447.25 K/s
Current DISK READ: 0.00 B/s | Current DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
350655 be/4 root 0.00 B/s 1447.25 K/s 0.00 % 0.00 % python3情况又发生了变化,此时iowait也没有上来,反而是用户态和内核态各占用50%?磁盘的写入确实比没加flush更频繁,写入平均带宽才1.5M/s左右比之前效率低了20倍,说明此时除了用户态的开销之外,大部分其实都花在系统调用上,由于每次调用flush都需要保存用户栈,恢复内核栈,等待调用代码执行完成后继续保存内核栈,然后恢复用户栈,同时要将数据从用户空间拷贝至内核空间,然后由内核写入到磁盘,这个操作主要就消耗在了内核空间上。那这个时候你可能会说怎么才能有I/O wait呢?原因是这里我们只写了3个字节,这个数据太小了,以至于内核开销得到放大,那我们写入更长的数据试试:
f = open('test', 'w')
while True:
f.write('abc'*1024)查看CPU:
top - 09:28:55 up 88 days, 15:59, 3 users, load average: 0.33, 0.11, 0.10
Tasks: 143 total, 2 running, 141 sleeping, 0 stopped, 0 zombie
%Cpu(s): 7.9 us, 18.0 sy, 0.0 ni, 30.5 id, 42.5 wa, 0.0 hi, 1.1 si, 0.0 st
MiB Mem : 31775.6 total, 1925.4 free, 8200.9 used, 21649.4 buff/cache
MiB Swap: 8192.0 total, 8191.0 free, 1.0 used. 23113.3 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
350655 root 20 0 44580 34292 15188 R 100.0 0.1 5:29.63 python3磁盘:
08/04/2021 09:29:26 AM
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
sda3 346.00 0.00 175696.00 0.00 0 175696 0
08/04/2021 09:29:27 AM
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
sda3 249.00 0.00 147188.00 0.00 0 147188 0
08/04/2021 09:29:28 AM
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
sda3 288.00 0.00 176144.00 0.00 0 176144 0
08/04/2021 09:29:29 AM
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
sda3 310.00 0.00 180580.00 0.00 0 180580 0平均带宽:
Total DISK READ: 0.00 B/s | Total DISK WRITE: 170.25 M/s
Current DISK READ: 0.00 B/s | Current DISK WRITE: 184.99 M/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
350756 be/4 root 0.00 B/s 0.00 B/s 0.00 % 97.78 % [kworker/u8:2+flush-253:0]
350655 be/4 root 0.00 B/s 170.25 M/s 0.00 % 68.76 % python3现在终于模拟出了我们想要的结果,此时I/O wait也就是cpu的wa那一项占用了40%以上,查看磁盘的TPS和写入都比较高并且很平稳,带宽达到180M/s,因为我这里用的是机械盘,所以基本上到了极限,由于写入的数据比较长因此内核缓冲区将会被频繁刷新因此内核利用率也能达到18%,所谓某个瓶颈就是在这个方便的占比明显超过其他方面,是一个相对的关系,这样就可以根据这个主要方面来优化,你可以搜索一下Amdahl定律,是由计算机科学领域的先锋Gene Amdahl提出,这个定律的精髓就是渐进加速比例的变化,通过解决所占比例最大的部分就可以获得最高的性能提升比,你值得拥有!
那么除了写入更长的字节还有没有别的办法来模拟?因为默认情况下文件系统的IO都是缓存I/O,还有一种IO叫做Direct I/O也就是直接I/O,这种情况程序可以直接访问磁盘数据而不需要经过内核缓冲区,可以减少内核缓存和用户程序之间的数据复制,举例如下:
import os
import mmap
f = os.open('test', os.O_DIRECT|os.O_CREAT|os.O_RDWR|os.O_SYNC)
m = mmap.mmap(-1, 1024)
m.write(b'abc')
while True:
os.write(f, m)这种情况到底能不能模拟出来I/O wait呢?你自己可以试一下就能得到答案。
其实用stress也可以模拟非直接io的情况,比如:
stress -d 1 --hdd-bytes 10M这个命令就是通过文件系统写入,使得内核利用率接近100%,你也可以自己试一下。
现在我们对I/O wait状态就有一个相对清晰的认识了,但是有的时候I/O wait却会被其他进程“屏蔽”掉,你知道这是什么原因吗?其实这是操作系统为了充分利用cpu资源而采取的进程调度策略,比如早期我们的CPU可能只有1个核心,如果1个程序I/O wait特别高,另外1个程序计算更多一些,反正I/O等待的时候CPU也是等着,何不让出资源给另外需要CPU的程序执行呢?所以另外的进程就获得了CPU时间片,提高了用户空间或者内核空间的利用率,因此I/O wait会下降,此时的现象就好像wa那一项被“屏蔽”掉了,给排查问题带来一些困难,不过现在的CPU大都是多核,由于进程的上下文切换可能会调度到不同的核心,有些进程出现wa高的时候还是很容易能体现出来的,不过需要多观察一会来确定,并不需要停掉其他进程。
6.用stress模拟线上的复杂
stress --cpu 1 --io 2 --vm 1top - 10:09:39 up 88 days, 16:40, 3 users, load average: 3.21, 1.01, 0.44
Tasks: 147 total, 3 running, 144 sleeping, 0 stopped, 0 zombie
%Cpu0 : 1.3 us, 2.6 sy, 0.0 ni, 43.5 id, 47.7 wa, 0.0 hi, 4.9 si, 0.0 st
%Cpu1 : 1.9 us, 4.2 sy, 0.0 ni, 45.7 id, 44.7 wa, 0.0 hi, 3.5 si, 0.0 st
%Cpu2 : 23.7 us, 76.3 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 31775.6 total, 12647.1 free, 8255.4 used, 10873.1 buff/cache
MiB Swap: 8192.0 total, 8191.0 free, 1.0 used. 23058.8 avail Mem是不是真相了?
最后感谢您的耐心阅读,这篇对于CPU性能分析的分享就到这里,希望能对你的工作带来一点帮助!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号