CentOS 7/8上部署Ceph
Ceph是一个分布式的存储系统,可以在统一的系统中提供唯一的对象、块和文件存储,Ceph的大致组件如下:
1. Ceph监视器(ceph-mon):用来维护集群状态的映射,包括监视器映射,管理器映射,OSD映射,MDS映射和CRUSH映射,这些映射是ceph守护程序相互协调所需的关键状态,另外还负责客户端到ceph存储的身份验证;通常要实现高可用,需要3个或以上的ceph-mon服务
2. Ceph管理器(ceph-mgr):ceph manager守护进程负责跟踪运行时指标和ceph集群当前的状态,包括存储利用率,当前性能指标和系统负载等,ceph-mgr还托管一些python模块,以实现基于web的ceph仪表盘和rest api,通常要实现高可用至少需要2个ceph-mgr进程,通常ceph-mon和ceph-mgr个数相同,1个ceph-mon同节点会伴随1个ceph-mgr守护进程
3. Ceph对象存储(ceph-osd):Ceph OSD是对象存储守护程序,是用来存储数据的核心组件,实现数据存储、数据复制和恢复、数据的重新平衡,并会检查其他Ceph OSD守护程序的心跳来向ceph-mon和ceph-mgr提供一些监控信息,通常至少需要3个ceph-osd才能实现冗余和高可用性,部署的时候ceph-osd会和ceph-mon分开节点部署.
4. Ceph元数据服务(ceph-mds):Ceph MDS为ceph文件系统存储元数据,注意Ceph块设备和对象存储不用mds存储元数据,Ceph MDS允许POSIX文件系统用户执行基本命令,而不会将压力都集中到Ceph OSD集群上,通常mds可以选择部署至少2个节点,可以和其他组件一起也可以分开
上面4个组件是构建ceph集群最基本的服务,下面就按照上面这4种顺序搭建完整的ceph集群,我们这里节点有以下3个:
node1 192.168.3.237
node2 192.168.3.238
node3 192.168.3.239
一个最小型的集群至少要有3个节点,其中:ceph-mon,ceph-mgr,ceph-mds都搭建在node1上,node2和node3上搭建ceph-osd,每个机器1个osd,这里每个机器提前留两个空白分区给osd使用,都是/dev/sdb1,只分区即可,不用格式化,其实官网提供了好多种部署方式,参考:https://ceph.readthedocs.io/en/latest/install/,其中cephadm方式只支持docker/podman方式启动,并且在生产环境的支持还不好,我们这里采用手动部署的方式,参考文档:https://ceph.readthedocs.io/en/latest/install/index_manual/
部署之前仍然要做好下面的准备工作:
1. 所有节点都配置好主机名以及hosts,严格对应
2. 所有节点的防火墙都要开放必要端口或者禁用防火墙,保证端口可以访问到;尽量关闭selinux
3. 保证所有节点的时间是同步的,可以使用ntp/chrony进行时间同步
另外ceph最新的版本工具完全使用python3实现,和python2的环境没有关系。对于centos7直接可以yum安装python3,和自带的2互不影响;对于centos8系统直接就是默认使用python3。不过不用担心,下面安装ceph会自动解决python3的依赖问题,这个安装文档同时适用于centos7和centos8有区别的地方下面都会注明,然后就让我们一步一步的搭建起ceph吧!
1. 所有节点安装ceph软件包
上面说到的所有节点都需要安装完整的ceph安装包,才能进行各类组件的配置,下面先安装所有必需的包
对于centos7要执行下面的命令安装yum-plugin-priorities依赖,centos8不需要:
yum install yum-plugin-priorities
然后执行: cat /etc/yum/pluginconf.d/priorities.conf 确认里面的enabled为1,表示启用plugin
然后安装ceph的密钥,centos7和8都要执行,下面不特别说明都是centos7/8都执行命令:
rpm --import 'https://download.ceph.com/keys/release.asc'
然后安装elep-release仓库并安装一些必须的包:
yum install epel-release yum install snappy leveldb gdisk gperftools-libs
然后开始配置ceph的镜像源,新建镜像配置文件/etc/yum.repos.d/ceph.repo,官方给出的模板如下:
[ceph] name=Ceph packages for $basearch baseurl=https://download.ceph.com/rpm-{ceph-release}/{distro}/$basearch enabled=1 priority=2 gpgcheck=1 gpgkey=https://download.ceph.com/keys/release.asc [ceph-noarch] name=Ceph noarch packages baseurl=https://download.ceph.com/rpm-{ceph-release}/{distro}/noarch enabled=1 priority=2 gpgcheck=1 gpgkey=https://download.ceph.com/keys/release.asc [ceph-source] name=Ceph source packages baseurl=https://download.ceph.com/rpm-{ceph-release}/{distro}/SRPMS enabled=0 priority=2 gpgcheck=1 gpgkey=https://download.ceph.com/keys/release.asc
其中:{ceph-release}表示要安装的ceph的版本,{distro}代表系统的平台,对于具体的版本可以直接访问链接https://download.ceph.com查看

可以看到这里最新的是15.2.4,这里就安装最新的了,{distro}对于centos7替换成el7,centos8替换成el8,另外ceph官方源国内下载龟速,建议修改为中科大的源,地址为:https://mirrors.ustc.edu.cn/ceph/,这下面的结构通常和官方源都是一致的,除了刚发布还没同步的情况,因此安装的时候手动打开确认一下比较好,上面的替换有个小技巧,vim底行模式全部替换:
:%s/{ceph-release}/15.2.4/g
:%s/{distro}/el8/g
下面是我分别在centos7和8下面中科大源15.2.4的yum源配置:


[ceph] name=Ceph packages for $basearch baseurl=https://mirrors.ustc.edu.cn/ceph/rpm-15.2.4/el7/$basearch enabled=1 priority=2 gpgcheck=1 gpgkey=https://mirrors.ustc.edu.cn/ceph/keys/release.asc [ceph-noarch] name=Ceph noarch packages baseurl=https://mirrors.ustc.edu.cn/ceph/rpm-15.2.4/el7/noarch enabled=1 priority=2 gpgcheck=1 gpgkey=https://mirrors.ustc.edu.cn/ceph/keys/release.asc [ceph-source] name=Ceph source packages baseurl=https://mirrors.ustc.edu.cn/ceph/rpm-15.2.4/el7/SRPMS enabled=0 priority=2 gpgcheck=1 gpgkey=https://mirrors.ustc.edu.cn/ceph/keys/release.asc
[ceph] name=Ceph packages for $basearch baseurl=https://mirrors.ustc.edu.cn/ceph/rpm-15.2.4/el8/$basearch enabled=1 priority=2 gpgcheck=1 gpgkey=https://mirrors.ustc.edu.cn/ceph/keys/release.asc [ceph-noarch] name=Ceph noarch packages baseurl=https://mirrors.ustc.edu.cn/ceph/rpm-15.2.4/el8/noarch enabled=1 priority=2 gpgcheck=1 gpgkey=https://mirrors.ustc.edu.cn/ceph/keys/release.asc [ceph-source] name=Ceph source packages baseurl=https://mirrors.ustc.edu.cn/ceph/rpm-15.2.4/el8/SRPMS enabled=0 priority=2 gpgcheck=1 gpgkey=https://mirrors.ustc.edu.cn/ceph/keys/release.asc
由于占空间先折叠了,需要可以展开查看,写好配置后保存/etc/yum.repos.d/ceph.repo文件,下面就可以开始安装ceph了,直接一行yum即可:
yum install ceph
安装过程中会自动安装python3.6以及相关的依赖等,安装完成之后最好再确认一下下面两个python模块是否存在,不存在就需要安装一下:
pip3 install pecan pip3 install werkzeug
否则待会查看ceph状态的时候会警告模块不存在的错误,比如Module 'restful' has failed dependency: No module named 'werkzeug',表示restful将无法使用
这样ceph的基本软件包都安装完成啦,注意所有节点都要安装一遍
2. ceph-mon服务部署(node1节点)
这部分部署ceph监视器服务,只在需要部署监视器的节点上执行操作即可,这里是在node1节点上执行操作,具体操作步骤如下:
生成fsid,这个表示ceph集群的唯一id,就是1个uuid格式的字符串,初始情况直接使用命令: uuidgen 生成1个就可以了,要保证整个集群始终一致,然后创建配置文件:/etc/ceph/ceph.conf,正常写入下面的配置:
[global] fsid = bdd23a75-12fc-4f25-abf5-7a739fa4e2d1 mon initial members = node1 mon host = 192.168.3.237:6789 public network = 192.168.0.0/20 auth cluster required = cephx auth service required = cephx auth client required = cephx osd journal size = 1024 osd pool default size = 2 osd pool default min size = 1 osd pool default pg num = 333 osd pool default pgp num = 333 osd crush chooseleaf type = 1 mon_allow_pool_delete = true
正常/etc/ceph目录被建好了,ceph的程序默认会自动读取配置文件ceph.conf,默认集群名称为ceph,集群名称是没有空格的简单字符串,比如ws-user,cluster1等,使用不同的集群只需要创建集群名命名的配置文件即可,比如:cluster1.conf,ws-user.conf,然后相关的ceph命令要指定集群名,比如ceph --cluster <cluster-name>,下面简单说一下这里面的配置项:
fsid:这个就是刚才生成的集群唯一uuid
mon initial members:这个配置监视器的主机名列表,多个用逗号分隔
mon host:这个配置监视器节点的ip:port列表,默认ceph-mon服务的端口号是6789,默认不修改可以不写,多个用逗号分隔
public network: 表示开放客户端访问的网络段,根据实际的情况配置
然后后面3项均表示启动认证,方式就是cephx
然后重点看:osd pool default size和osd pool default min size,第一个是osd的数据会复制多少份,osd节点或服务的个数至少要>=复制份数,正常生产环境副本至少要设置3个,保证数据安全,我们这里就两个osd,因此最多设置2;然后后面的配置是允许降级状态下写入几个副本,通常建议至少配置2,我们这里只有两个osd,因此配置了1
然后是osd pool default pg num和osd pool default pgp num是配置单个pool默认的pg数量和pgp数量,pg全称是Placement Group,叫放置组,也就数据存储分组的单元,可以类比为hdfs的块类似的概念,pgp num要和pg num一致即可
osd crush chooseleaf type这个参数要注意,这个默认是1表示不允许把数据的不同副本放到1个节点上,这样是为了保证数据安全,集群肯定要配置成1,如果是单机环境搭多个osd做伪分布式测试,那么副本肯定是都在本机的,这个参数务必要改成0,否则最后pgs一直达不到active+clean的状态,就算1个机器上osd数量足够状态仍然为100% pgs not active以及undersized+peered的状态,同时会出现警告信息像下面这样,所以一定要注意这个参数
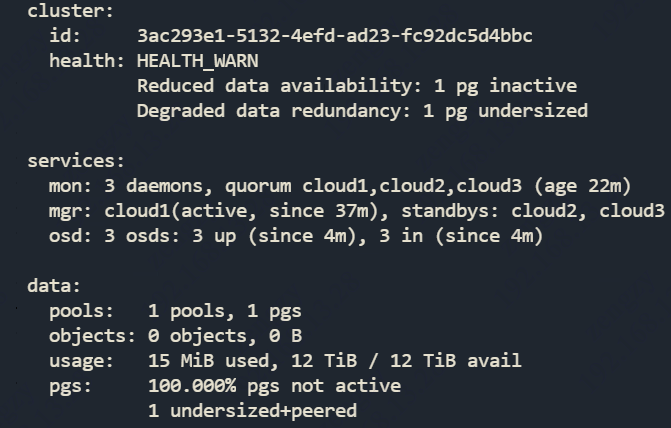
mon_allow_pool_delete 这个参数表示是否允许删除pool,就是存储池,默认是不允许的,改成这个则允许删除,生产环境建议关闭
上面就是基本的这些配置,然后需要把这个配置文件同步到所有的节点,注意之后ceph.conf只要有任何修改,都要同步到集群全部节点,不管是否用到这些配置项,目的是为了保证集群的配置统一,避免出现特殊的问题
接下来进行相关的配置:
# 为集群创建1个密钥环,作为监视器密钥 注意其中的点.不要丢 ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *' # 生成管理员密钥环 创建admin用户 也是第一个客户端用户 ceph-authtool --create-keyring /etc/ceph/ceph.client.admin.keyring --gen-key -n client.admin --cap mon 'allow *' --cap osd 'allow *' --cap mds 'allow *' --cap mgr 'allow *' # 生成bootstrap密钥环和用户 ceph-authtool --create-keyring /var/lib/ceph/bootstrap-osd/ceph.keyring --gen-key -n client.bootstrap-osd --cap mon 'profile bootstrap-osd' --cap mgr 'allow r' # 然后将刚才生成的密钥追加到ceph.mon.keyring ceph-authtool /tmp/ceph.mon.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring ceph-authtool /tmp/ceph.mon.keyring --import-keyring /var/lib/ceph/bootstrap-osd/ceph.keyring # 修改ceph.mon.keyring的权限为ceph ceph用户安装时已经自动创建 chown ceph:ceph /tmp/ceph.mon.keyring
上面这些命令全部复制执行即可,一行都不用改,然后生成ceph-mon 映射,存储到/tmp/monmap:
# 注意这里主机名, ip, fsid要换成实际的 monmaptool --create --add node1 192.168.3.237 --fsid bdd23a75-12fc-4f25-abf5-7a739fa4e2d1 /tmp/monmap
然后创建ceph-mon数据目录:
# 目录名为: 集群名-主机名 这里是: ceph-node1 mkdir /var/lib/ceph/mon/ceph-node1
使用刚才生成的密钥环和映射初始化数据目录:
# -i 指定主机名
ceph-mon --mkfs -i node1 --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring
调整数据目录权限为ceph:
chown -R ceph:ceph /var/lib/ceph/mon/ceph-node1/
然后启动ceph-mon服务:
# 服务名为:ceph-mon@主机名 systemctl start ceph-mon@node1 # 查看服务状态 systemctl status ceph-mon@node1
如果正常启动的话,这时候6789端口应该被监听了,这样ceph-mon服务就配置好了,如果配置多个节点的话,要将刚才的ceph.mon.keyring和monmap复制到其他的节点,然后初始化数据目录启动服务即可,密钥环不要多次生成,然后admin用户和bootstrap-osd用户的密钥环同时都要同步到其他的节点,配置好通过下面命令查看ceph状态:
ceph -s
正常显示HEALTH_OK即可,然后如果有WARN提示没有启用msgr2,需要通过下面的命令启用一下,然后稍等再次观察即可正常:
ceph mon enable-msgr2
如果想在其他osd节点也执行ceph -s查看状态的话,则需要同步/etc/ceph/ceph.client.admin.keyring文件到其他节点即可执行ceph状态相关的命令。
3. ceph-mgr服务部署(node1节点)
ceph-mgr和ceph-mon是成对出现的,在每个ceph-mon的节点上都应该有ceph-mgr进程,然后就是配置并启动ceph-mgr守护进程,下面是配置过程:
首先生成mgr身份验证密钥:
# 创建mgr密钥目录, 命名为: 集群名-主机名 mkdir /var/lib/ceph/mgr/ceph-node1 # 创建mgr身份验证密钥 注意里面的mgr.node1,node1为主机名 ceph auth get-or-create mgr.node1 mon 'allow profile mgr' osd 'allow *' mds 'allow *' > /var/lib/ceph/mgr/ceph-node1/keyring
# 修改权限
chown -R ceph:ceph /var/lib/ceph/mgr/ceph-node1/
注意官网这里用$name代替主机名,这里说的很含糊,建议使用主机名,无论如何和前面指定的那个host保持一致,这样后面就不会有一些奇怪的问题导致集群不能用,然后启动ceph-mgr守护进程:
ceph-mgr -i node1
同样这里-i参数指定主机名,启动后确认进程是否存在,启动没问题的话就可以先kill掉进程然后使用服务的方式启动即可:
systemctl start ceph-mgr@node1
# 查看服务状态
systemctl status ceph-mgr@node1
然后执行 ceph status 查看mgr的状态,正常显示active就表示可以了

4. ceph-OSD节点部署(node2,node3)
部署ceph-osd的步骤应该在所有的osd节点上运行,当然这里是node2和node3,每个节点都要执行同样的操作,首先要将node1上面的osd密钥发送到osd节点,否则创建osd会报错授权失败,如果刚才已经同步可以忽略,否则就在node1上执行:
scp /var/lib/ceph/bootstrap-osd/ceph.keyring node2:/var/lib/ceph/bootstrap-osd/ scp /var/lib/ceph/bootstrap-osd/ceph.keyring node3:/var/lib/ceph/bootstrap-osd/
然后才可以操作创建osd存储,这里创建的存储类型分为两种,分别是:BULE STORE和FILE STORE,即分别是默认的存储以及文件存储,这俩的区别是文件存储是每次写入都需要先写journal会产生写放大,最初是针对SATA这类机械盘设计的,没有对SSD做优化,而Bule store比较新一些主要对Flash介质做了优化所以在SSD上性能更好,通常默认采用bule store,对固态盘更友好,对于机械盘可以采用File store,但是每个File store的osd至少需要两块设备,因为每个文件存储都必须要指定配套的日志存储设备,我们这里创建的类型为bule store.
执行命令直接创建osd存储(lvm方式):
ceph-volume lvm create --data /dev/sdb1
--data指定块设备,我们这为/dev/sdb1,指定之后会有一些输出,如果没有报错正常就创建成功并且自动启动了osd服务,osd服务名为:ceph-osd@<osd编号>,这里第一个编号就是0了,因此服务名为:ceph-osd@0,使用命令查看osd服务是否正常: systemctl status ceph-osd@0 如果正常即可表示osd进程启动成功,现在用ceph -s也能看到osd的状态,然后再进入另外的osd节点,比如进入node3,同样执行这个命令创建块存储,查看服务ceph-osd@1是否正常,最后通过ceph查看状态如下:

除了上面的命令,使用下面的步骤也同样可以创建osd节点,步骤更细一些,分为准备和激活两个阶段:
# 准备设备 ceph-volume lvm prepare --data /dev/sdb1 # 查看osd卷列表 注意这个只能查看当前机器本地的osd卷 会得到刚创建的osd id和osd fsid这两个参数,下面要用到 ceph-volume lvm list # 激活设备 数字0为上面看到的的osd id,然后是osd fsid [这里特别注意下就是如果系统盘出现损坏无法进入系统重装系统后可以使用下面命令来恢复OSD元数据并启动服务,元数据其实都保存在lvm中] ceph-volume lvm activate 0 d57f965e-5be2-4778-8bbf-f6fd74afe451
上面这些步骤和开始的命令结果是完全一样的,可以任选一种方式创建osd,需要特别注意的是最后的fsid不是集群的fsid,而是osd fsid,这个官方的文档具有误导性,一定要注意;除了通过命令查看还可以注意到在第一步准备的时候会提示创建/var/lib/ceph/osd/ceph-{osd id}这样的目录,这个目录就能确定osd id,然后执行: cat /var/lib/ceph/osd/ceph-{osd id}/fsid 就可以得到osd fsid提供下一步输入。
最后官网还提供一种完全手动的方式创建,这种方式不用创建lvm卷而是直接通过原始分区创建,步骤更为繁琐一些,具体操作如下:
# 生成osd fsid变量 接下来创建osd使用 UUID=$(uuidgen) # 生成osd cephx认证密钥 OSD_SECRET=$(ceph-authtool --gen-print-key) # 创建osd id,正常id会自增排列 这里同样会重用之前销毁的id ID=$(echo "{\"cephx_secret\": \"$OSD_SECRET\"}" | \ ceph osd new $UUID -i - \ -n client.bootstrap-osd -k /var/lib/ceph/bootstrap-osd/ceph.keyring) # 创建新的osd目录 mkdir /var/lib/ceph/osd/ceph-$ID # 格式化将要用作osd存储的分区设备 这里为/dev/sdb1 mkfs.xfs /dev/sdb1 # 挂载设备到ceph osd目录 mount /dev/sdb1 /var/lib/ceph/osd/ceph-$ID # 创建ceph osd密钥环 ceph-authtool --create-keyring /var/lib/ceph/osd/ceph-$ID/keyring \ --name osd.$ID --add-key $OSD_SECRET # 初始化osd数据目录 ceph-osd -i $ID --mkfs --osd-uuid $UUID # 设置osd目录访问权限 chown -R ceph:ceph /var/lib/ceph/osd/ceph-$ID # 最后启动服务并设置开机自启动 systemctl start ceph-osd@$ID systemctl enable ceph-osd@$ID # 查看服务状态 systemctl status ceph-osd@$ID # 通过ceph查看osd状态 ceph -s ceph osd ls
上面这种完全手动的方式,在遇到问题时操作比较好使,容易定位到具体的问题,正常使用前两种lvm分区方式创建osd其实就可以了
5. ceph-mds部署(node1)
最后部署ceph-mds守护进程,这个需要在单独的mds节点执行,这里选node1为mds节点,下面是配置的过程:
创建mds数据目录:
# 目录名同样是: 集群名-主机名 mkdir /var/lib/ceph/mds/ceph-node1 # 然后创建mds 密钥环到刚建的目录中, 注意mds.node1同样写主机名 ceph-authtool --create-keyring /var/lib/ceph/mds/ceph-node1/keyring --gen-key -n mds.node1 # 最后导入密钥环 设置访问权限 同样注意主机名 ceph auth add mds.node1 osd "allow rwx" mds "allow" mon "allow profile mds" -i /var/lib/ceph/mds/ceph-node1/keyring
然后编译配置文件:/etc/ceph/ceph.conf,添加如下的配置块:
[mds.node1]
host = node1
这里node1就是主机名,注意根据实际的mds节点替换,保存后将配置文件同步到集群所有节点,最后启动ceph-mds守护进程:
# -i指定mds节点主机名, -m指定ceph-mon的主机名:端口 ceph-mds --cluster ceph -i node1 -m node1:6789
这里ceph-mds和ceph-mon是同一个节点,因此都是指定node1,启动之后查看进程是否存在,然后通过ceph -s可以看到mds的状态:
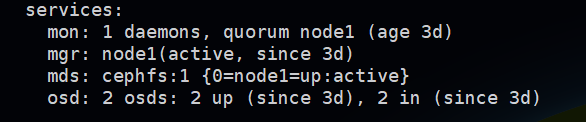
现在所有的组件状态都是正常的了
6. 创建存储池以及ceph文件系统
ceph所有的存储都是基于存储池才能分配,因此要先创建存储池,初始情况至少创建两个存储池(RADOS):1个用于存储数据,1个用于存储元数据信息,创建命令如下:
# 创建名字为cephfs_data的数据池 pg大小为128 ceph osd pool create cephfs_data 128 # 创建名字为cephfs_metadata的存储池 pg大小为64 ceph osd pool create cephfs_metadata 64
存储池可以创建多个,并且所有的存储池共享底层的存储空间,比如A存储池占用了一部分,那个B存储池就只能用剩下的部分了,而且之后挂载后剩余大小的显示也会变小,这个后面可以验证
另外就是注意这里pg大小正常指定128或64就够了,正常默认1个pool最多支持250个pg,可以通过参数调整限制大小,这里两个池都是一样的数据池,后续创建文件系统会指定哪个用于数据,哪个用于元数据存储,这里名字只是个代号,然后基于存储池创建文件系统,命令如下:
# ceph fs new <fs名称> <元数据池> <数据池>
ceph fs new cephfs cephfs_metadata cephfs_data
执行成功之后通过命令: ceph fs ls 查看存在的文件系统,正常显示如下:

然后还可以执行 ceph mds stat 查看mds当前的活动状态
7. 挂载文件系统
挂载文件系统有两种方式,一种是基于操作系统内核直接挂载,另一种是使用ceph fuse挂载,通常推荐第一种方式挂载,这样性能和效率都是最高的,如果第一种方式挂载不成功的话,可以尝试使用fuse方式挂载,看看能否定位到什么问题,下面我们直接使用内核方式挂载:
使用内核方式挂载要确认mount是否支持ceph: stat /sbin/mount.ceph ,正常安装好ceph包都会有/sbin/mount.ceph这个文件,说明支持ceph的文件系统,然后创建挂载点使用admin用户挂载:
mkdir /mnt/mycephfs mount -t ceph :/ /mnt/mycephfs/ -o name=admin
正常没有任何错误信息就挂载上了,通过 df -h 可以查看挂载的情况以及容量,这个时候容量应该为两块盘总容量的一半,因为我们有2个副本;另外注意这里挂载的用户是admin,还记得之前为admin用户创建了密钥环吗,这里就是读取的/etc/ceph/ceph.client.admin.keyring这个密钥文件,如果没有的话会报错提示读取密钥环文件的顺序,需要将文件发送至客户端挂载,另外如果有专门的客户端节点,也可以再单独创建用户挂载,操作方法如下:
首先按照第一部分的步骤配置源完整的安装基础组件和ceph包,安装完成自动生成/etc/ceph目录,然后继续操作创建用户授权并挂载:
# 获取最小配置 这里ssh的是ceph-mon节点机器 注意配置hosts 执行按照提示输入密码 ssh root@node1 "ceph config generate-minimal-conf" | tee /etc/ceph/ceph.conf # 设置默认权限 chmod 644 /etc/ceph/ceph.conf # 创建用户密钥环 cephfs是文件系统名称 这里用户名是zzy 对根目录/有rw权限 ssh root@node1 "ceph fs authorize cephfs client.zzy / rw" | tee /etc/ceph/ceph.client.zzy.keyring # 设置密钥文件的权限 chmod 600 /etc/ceph/ceph.client.zzy.keyring # 创建挂载点 mkdir /cephfs
按照上面的方法操作完成之后,就可以挂载cephfs了
mount -t ceph :/ /cephfs/ -o name=zzy
其实也可以手动指定ceph-mon的ip:port以及密钥字符串来挂载也是可以的,密钥通过keyring文件查看:
mount -t ceph 192.168.3.237:6789:/ /cephfs/ -o name=zzy,secret=AQA5s0RfvaGWBBAA0deE9bB+5Qfogxt823ubRg== # 或者指定secretfile 这个文件内容就是密钥base64本身 不能包含任何别的东西 mount -t ceph 192.168.3.237:6789:/ /cephfs/ -o name=zzy,secretfile=/etc/ceph/zzy.secret
通常推荐用第一种方法更省事,具体ceph的地址会自动读取ceph.conf配置文件,密钥环会自动读取生成的,而且ceph支持单个文件系统多个客户端同时挂载,并且任何一个用户的修改其他用户都是立即可见的,ceph提供一块大的包含冗余副本的空间,而多个客户端会共享这块空间,如果想独立挂载可以授权时多个用户使用不同的目录,再或者创建多个存储池,挂载不同的存储池来实现
经过上面这些步骤,ceph集群就基本上搭建好了,参考官方文档:https://ceph.readthedocs.io/en/latest/install/manual-deployment/,整个安装过程都是自己多次验证通过的,正常走下来应该是没问题的,如果文中有错误或者有任何疑问,欢迎留言哈~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号