Flink Standalone集群jobmanagers高可用配置
上篇文章简单叙述了Flink standalone集群的基础部署,在生产环境中假如只有1个jobmanager的话,那么这个节点一旦挂掉,所有运行的task都会中断,带来的影响比较大,因此在生产环境至少要保证jobmanager的高可用,至少2个节点,也可以将jobmanager和taskmanager两个实例运行到1个物理节点上,多个taskmanager和多个jobmanager并存实现高可用,高可用需要依赖zookeeper的故障恢复,因此要先准备好zookeeper集群,建议独立搭建zookeeper集群,不要用flink内置的单节点zookeeper,之前原有的环境如下:
bigdata1 - jobmanager
bigdata2,bigdata3,bigdata4 - taskmanager
目前zookeeper集群为:bigdata1,bigdata2,bigdata3,端口号为2181
接下来要进行jobmanager扩展,在bigdata4上面运行jobmanager,和bigdata1的jobmanager共同实现高可用.
首先在一个节点开始配置,这里现在bigdata1开始配置:
配置:conf/flink-conf.yaml 找到High Availability配置部分,这部分默认都是注释的也就是不使用高可用,需要手动去掉注释并且添加一些配置项,具体配置如下:
high-availability: zookeeper high-availability.storageDir: file:///data/flink/ha high-availability.zookeeper.quorum: bigdata1:2181,bigdata2:2181,bigdata3:2181 high-availability.zookeeper.path.root: /flink high-availability.cluster-id: /flink_cluster
high-availability默认是NONE,表示不使用高可用,这里改成zookeeper
high-availability.storageDir 这个是高可用中用于存储一些较大的对象用于恢复,文档中建议配置所有节点都可以访问到的资源,推荐使用hdfs,这里配置的是本地文件系统,具体有效性需要验证,建议生产环境使用hdfs
high-availability.zookeeper.quorum 配置zookeeper集群
high-availability.zookeeper.path.root 配置flink在zookeeper中的path,整个集群要统一,这里是/flink;如果是多个flink集群使用同一个zookeeper集群,那么这里要区分开.
high-availability.cluster-id 集群的标识,整个集群要一致,在zookeeper下以及storageDir下都有这个cluster-id指定的目录,用于存放必须的协调数据
上面这些配置无误后,保存文件
配置masters,文件:conf/masters,添加bigdata4的节点
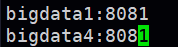
同时conf/slaves保持不变,仍然为bigdata2,bigdata3,bigdata4
然后将flink-conf.yaml和masters配置同步到集群其他所有节点,同时保证zookeeper服务已经正常运行
执行: bin/start-cluster.sh 启动集群,启动后会发现bigdata4多出了StandaloneSessionClusterEntrypoint进程,这个时候通过zookeeper客户端执行 get /flink/flink_cluster/leader/rest_server_lock 查看当前的jobmanager master可以一般会看到是bigdata1
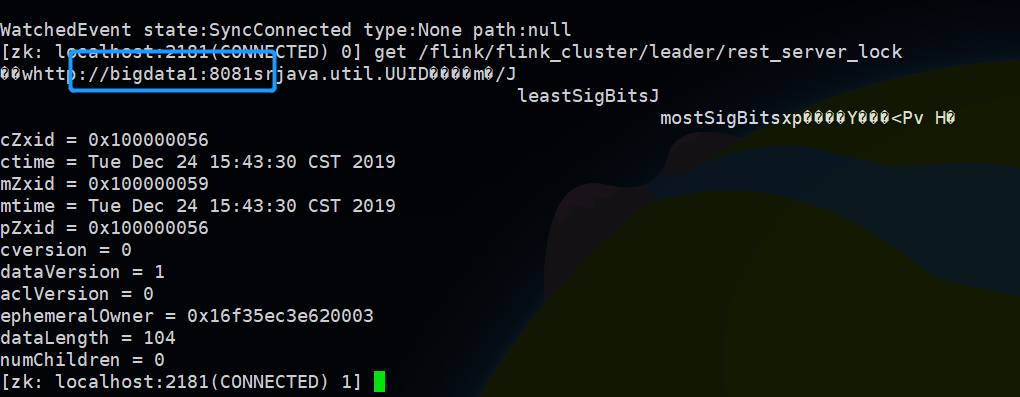
然后可以尝试将bigdata1上面的StandaloneSessionClusterEntrypoint进程kill掉,通过bigdata4:8081访问web ui,这个时候故障转移flink日志可能会报错,稍微等待一段时间,然后界面就会加载成功,正常看到slots和task managers以及详细的任务,说明这个时候jobmanager成功进行了故障转移,实现了高可用,同时查看zookeeper上面的节点也会切换成bigdata4了
另外注意配置高可用之后,之前的flink-conf.yaml中的配置项jobmanager.rpc.port就不再生效,这个配置项只针对之前的单个jobmanager的独立集群,现在这个端口会自动选择并且多个jobmanager都是不一样的,但是我们不用去关心他,对使用flink没有任何影响.
以上就是flink jobmanager高可用的配置,配置起来还是比较简单的,推荐在生产环境中使用,集群稳定性更好.
参考文档: https://ci.apache.org/projects/flink/flink-docs-release-1.9/zh/ops/jobmanager_high_availability.html
对于新版的flink有时候可能是偶然的原因导致第一次启动flink集群的时候报一些莫名其妙的错误死活启动不起来,这个时候可以尝试重启zookeeper集群,删除对应的/flink节点或者调大zookeeper tickTime,再启动flink集群一般就正常了.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号