算法篇——线性查找
前面《有序表查找》中的几种比较高效的查找方法都是基于有序队列的,但日常生活中这种队列比较少,使用局限性也很多;往往遇到的数据集不是变动频繁就是增长很快,比如:微博、微信或者论坛帖子每天的数据量都是千万级别的,如果还想让这些数据按照某种关键字排序,他的代价非常高,所以一般情况下这些数据集就不太适合有序表查找算法。
对于这种数据集我们用什么方法实现查找呢? 答案就是——索引。
索引就是把关键字与他所在记录相关联的过程。
索引分为:线性索引、树形索引和多级索引,我们这次主要说的就是线性索引。线性索引就是将索引项集合组织为线性结构,也称为索引表。这儿重点介绍三种线性索引:稠密索引、分块索引和倒排索引。
稠密索引
稠密索引指在线性索引中,把数据集中的每一个数据项都抽象出一个关键码对应一个索引项。这些索引项按照有序表排列,生成稠密索引。如下图所示:
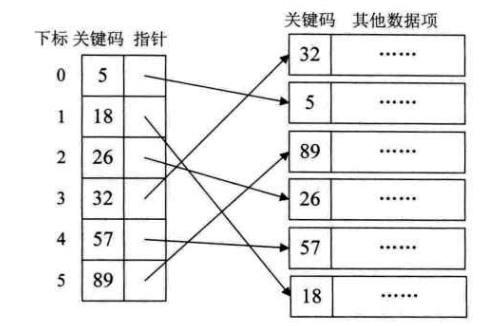
左侧是稠密索引队列,右侧是数据项,索引通过指针和唯一的数据项关联起来。当需要查找时,只需要搜索左侧索引项即可。
如果需要查找关键码是18的数据项
1、通过索引队列找到18的索引位置[1]中存储的指针
2、通过指针找到关键码18所在的数据项
通过这种方式可以有效的减少磁盘访问次数,大大提高数据项的查找效率。
不过通常情况下稠密索引要对应的数据可能上万甚至几十万的量级,所以索引项也会比较大,要想达到理想的查找效果,索引项一定是按照关键码排序的有序队列。这也意味着,我们要查找关键字时,可以使用折半、插值和婓波那契等有序插值算法可以大大提高效率。所以稠密索引的时间复杂度由索引项的算法决定。
但是,当数据集非常大的时候,比如上亿,也就意味着索引有相当大的规模,对于内存有限的计算机来说,可能需要反复访问磁盘,查找性能反而大大降低。
分块索引
分块索引指,把数据集分为有序的若干块,对每一个数据块建立一个索引,这种方法叫做分块索引。
稠密索引因为索引项与数据集的记录个数相同,当数据量大的时候所需要的空间代价也很大。为了减小索引项大小,分块索引就诞生了。
具体思想就是:把数据集分块,使分块有序,然后再对每一块数据建立索引,从而减少索引项的个数。
数据块需要满足下面两个条件:
1、块内无序,即每一块内的数据项不要求有序。如果做块内有序也可以,但必须考虑付出的代价是否合适。
2、块间有序,即后面块内的数据项都大于/小于前一块内的数据项。比如:第二块内的所有数据项都大于第一块内的所有数据项,依次类推。因为只有块间有序,才能在查找时带来效率。
为了提高索引项检索效率,我们定义的分块索引项结构如下:
1、最大关键码,存储每一块中的最大关键字。
2、块中的记录个数,便于循环。
3、块中首数据项的指针,便于定位。

比如上图,要查找57所在数据项。
1、在分块索引中查找57所属的索引块位置[1]。由于索引块是有序的,所以可以使用有序队列的查找算法。
2、在索引块中找到关键码57,进而找到对应的数据项。由于索引块中的关键码不是有序的,所以只能按照顺序查找。
再来看看顺序查找下分块索引的时间复杂度。假设n个记录的数据集被平均分次m块,每块记录有t条,则n=m*t。 再假设索引块的平均查找长度为 (m+1)/2,因为最好和最坏查找长度分别是m和1,所以平均下来就是(m+1)/2。 同理,块内记录的平均查找长度 (t+1)/2。这样,分块索引的查找长度:
ASL = (m+1)/2 + (t+1)/2 = (m+t)/2 + 1 = (n/t + t)/2 +1
上面算式的最佳情况就是 m = t,这样可以推导出 n = m*t = t^2,带入上面得到:
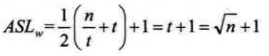
由此可见,通过顺序查找算法时,分块索引的时间复杂度比不使用分块要强不少。但是聪明的你一定会想到,分块索引既然有序为啥还要用顺序查找? 对了,这就是分块索引可以优化的地方,可以使用折半查找或插值查找算法来提高效率。
总的来说,分块索引在兼顾了细分块不需要有序的情况下大大提升整体查找速度,所以普遍被用于数据表查找等技术中。
倒排索引
倒排索引就是,在关键码索引中记录所有包含该关键字的数据项指针的索引方法叫倒排索引(inverted index)。
不懂 ? 没明白 ?
这就对了!
倒排索引定义是我根据自己理解总结的,当然不好懂啦……
举个例子吧,有两句话:
1、A good book is a good friend
2、This is my friend’s book
要查找good在那句话里面?
首先想到的办法就是一行一行取出数据,再比较数据字符串中是否包含good单词,这种办法可以找到在第一句里面。但是,当数据量比较大的时候,这种办法的查找效率是不能忍受。那我们的倒排索引开始登场了……
把上面两句话的所有单词都提取出来,排重后作为关键码做成一个有序表,关键码对应的编号就是包含该单词的文章编号,生成下表。
|
单词 |
文章编号 |
|
A |
1 |
|
Book |
1,2 |
|
Friend |
1,2 |
|
Good |
1 |
|
Is |
1,2 |
|
My |
2 |
|
This |
2 |
有了这张表,当需要查找good时,首先在单词列查找是否有该单词,找到后将他对应的文章编号1、2的地址返回,再通过地址直接获取记录即可。如此以来查找的速度就非常快。
倒排索引源于实际应用中需要根据属性(字段、次关键码)的值来查找记录。这种索引表中的每一项都包含一个属性和具有该属性的各记录的地址。由于不是由记录来确定属性,而是有属性来确定记录的位置,因而称为倒排索引。
倒排索引的优点和缺点都很明显。优点:速度快,效率高;缺点:因为每个单词都对应相当多的编号,当文章变动时索引表的变动成本很高。
ps:《大话数据结构》读书笔记
————————————————————————————————————————
一个人的时候,总是在想
我的生活到底在期待什么……

 浙公网安备 33010602011771号
浙公网安备 33010602011771号