

ARM硬件汇编指令
指令格式(后缀) 硬件汇编指令
扯淡☕️
ARM是一家公司名字、一种CPU架构名字、一种汇编(指令)名等等,很多时候口语中说ARM时我们并没有细分具体指代是什么,比如资料常见的armv7,这是一种「CPU架构」,是架构的代号,在这种架构下可以有不同的指令集,并且随着时间推移这种架构会新增更多的指令。像armv7这种架构就支持Thumb指令集和arm指令集,而Thumb(2)指令集又有16bits和32bits两种指令长度之分,arm指令集只有一种指令长度32bits。
今天我们主要讨论armv7系列的一些汇编指令,集中在基本的指令格式说明,以及常见常用指令说明(毕竟arm汇编指令实在太过丰富)。
在开始聊指令之前我们需要知道一些armv7架构的「常识」。arm指令不能直接操作内存,所有的行为都发生在寄存器里,因此arm有很多的寄存器,armv7这种架构就一共有16个寄存器(32bits大小的),其中r0~r12是通用寄存器,r13~r15是特殊寄存器。其实这16个寄存器(名字)r0~r16更应该被认为是「一个名字」,而非「一个实体」;类似高级编程语言中「接口或抽象类」与派生类的关系。
CPU中的寄存器就在那,叫什么并不那么重要,那只是一个指代而已,在armv7架构中它们的名字被隐藏在r0~r16中,实际上这些寄存器有40多个(以后或许更多😲,谁知道呢)
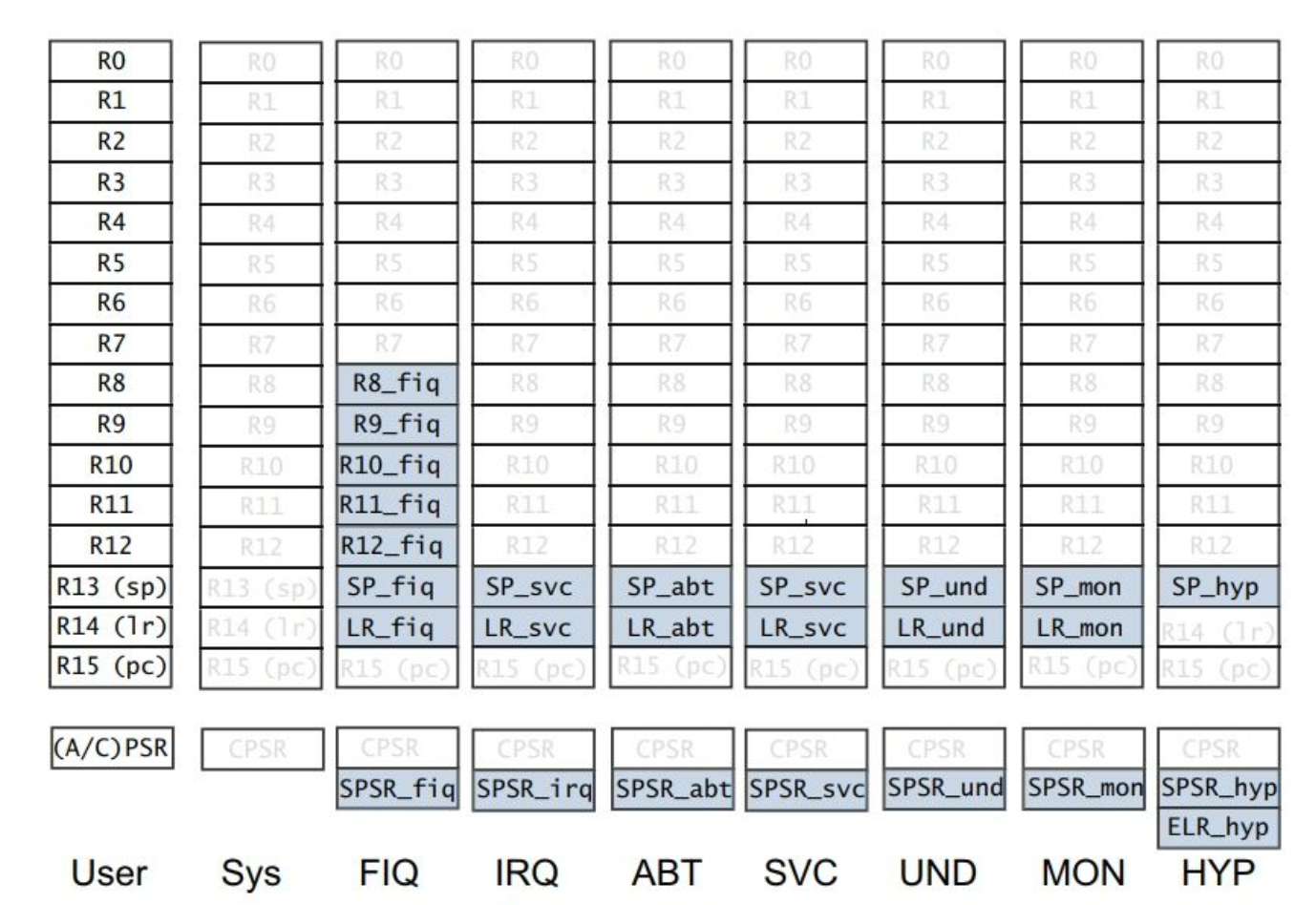
armv7中定义了8种不同的处理器模式,工作在不同的模式下虽然可能都是用的r13寄存器,但实质用的「真正」寄存器并不相同。如图2中,工作在user模式下和svc模式下的R13就是同名不同种的寄存器。通常,R0~R12被称为通用寄存器,因为这些寄存器的「用处」,没有特定的用法,当需要使用寄存器时可以用来存放数据,通常这些数据也不具备额外的特性,而R13~R15则存在一些特殊的使用场景,也被称为「特殊寄存器」,存在里面的值有特殊含义。
r13别名sp 寄存器(stack pointer),所谓的栈顶指针,保存着栈顶的位置r14别名链接寄存器lr(linker),用于保存返回地址,用于执行流的跳转返回r15别名程序计数器pc(program counter),保存下一条取指指令的地址
⚠️需要特别注意的是,arm系列架构的CPU采用的是经典的3级流水线取址(fetch) 译码(decode) 执行(excute) ,因此,123456这些指令,当此时执行2指令时,此刻的pc寄存器指向地址是4指令的地址。也就是Thumb指令集下,pc = current_excute_addr + 4,arm指令集下,pc = current_excute_addr + 8,即使某些处理器能达到 8 级流水线甚至更多,但是 pc 指针总是和前三个步骤相关。
对于函数调用除了有sp指针外,通常还可能存在帧指针,即fp(frame pointer),实际中一般使用r7作为fp,用来保存栈底。
指令格式🖼
在开始聊指令格式之前需要先说说几个arm架构指令的「常识」问题
-
指令后缀,很多时候你看到一条指令
XYz不知道意思,去官网也查不到对应的指令,这是因为这是指令XY与指令后缀z组合而成的,通常这个后缀用来形成「副作用」,意味着执行XY指令时,会「额外」的产生某些影响 -
条件执行,
armv7的arm指令集中每一条指令的最高4位为cond位,表示当前指令的「条件执行」,大部分指令都可以通过指示指令条件来决定当前指令是否执行,这需要与状态寄存器(CPSR)配合,大部分情况状态寄存器都不会被更新,一般指令的执行也不会影响到状态寄存器,对于这些指令需要添加后缀s来影响CPSR,比如mov r0,r0,r1,这条指令可能会产生溢出、结果为0等,但并不会影响到状态寄存器,需要movs r0,r0,r1才会影响更新状态寄存器。 -
指定指令长度,
armv7架构支持Thunb和arm2种指令集,这2个指令集的指令长度不相同,同一个指令(如mov r0,#1)既可以是Thumb指令(16bit)也可以是arm指令(32bit),这时候汇编器会采用简单的实现(16bit)。如果添加后缀.W(wide)则强制使用 32 位指令,相对应的如果使用.N(narrow),则强制使用 16 位指令,在arm指令集中使用.w后缀等于没加,如果添加.n后缀则直接报错。 -
立即数合法性,无论是
16bits还是32bits的指令,都无法完整编码一个32bits的立即数,必定有一些立即数是无法「直接」放入寄存器的,这些立即数被称为无效立即数,但可以通过其他方式(如通过movw和movt指令组合,甚至直接从内存加载)实现将立即数放入寄存器。以上,
指令后缀,条件执行,指定指令长度,立即数合法性就是我们在讨论指令格式前需要知晓的「常识」。
汇编指令格式描述📚
我们讨论一下汇编指令格式,(注意,不是在讨论机器码指令格式)。
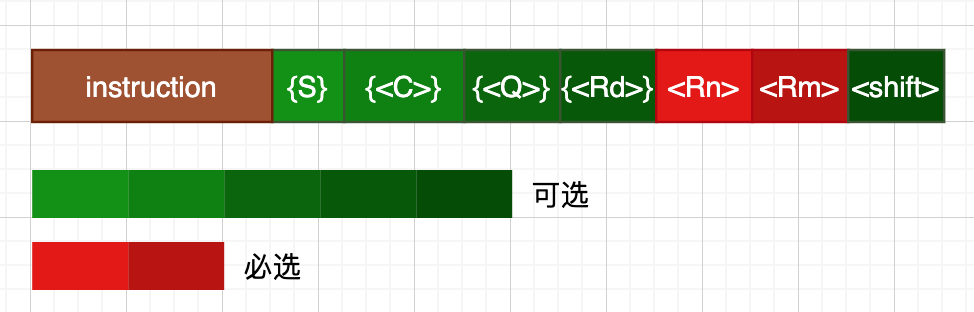
instruction{S}{<c>}{<q>} {<Rd>,} <Rn>, <Rm> {, <shift>}
-
instruction:标准汇编指令,比如add,sub,mov等 -
{ }:被大括号括起来表示可选 -
< >:对于参数列表而言,尖括号表示必须的参数 -
S:可选的后缀,表示是否更新CPSR -
c:条件执行后缀 -
q:指令宽度后缀,.w或者.n,在thumb模式下指定指定宽度 -
Rd:目的寄存器,对于armv7的汇编指令而言,第一个参数必定是一个寄存器 -
Rn:第一个操作数寄存器(n = 0,1,2,3...) -
Rm:第二个操作数寄存器(n = 0,1,2,3...) -
Rs:用于位移的寄存器(s =》shift)add r0, r0, r1, lsl #12 #还有其他位置标志如LRL(逻辑左移)/ASR(算术右移)/LSR(逻辑右移)
常用硬件汇编指令 🔆
🔆mov,movt,movw
movw:将一个 16 位数据移动到寄存器的低 16 位,并把高 16 位清零movt:将一个 16 位数据移动到寄存器的高 16 位,低 16 位不处理
#无论Thumb还是arm下,都能将0x12345678放入寄存器r0,不存在指令长度不够问题
movw r0,0x5678
movt r0,0x1234
🔆add,adc
adc表示add with carry,即进位加法,与add指令唯一的区别在于它会加上CPSR的carry位,在 64 位的加法中,低 32 位数据产生carry位,高 32 位在相加的同时就需要使用adc指令添加上carry位,相当于数学计算中的添加进位。
🔆sub,sbc, rsb, rsc
sbc为带借位的减法指令,在减法指令的操作后减去!C,C是CPSR中的carry位rsb为reverse sub版本的减法指令,它和sub的区别在于这是第2操作数减去第1操作数,将结果放在目的寄存器中(这个的意义在于,armv7架构中,第1个操作数必须是寄存器,因此使用sub指令就注定是「寄存器-{寄存器|立即数},而不能是「立即数-{寄存器|立即数}」」,此时rsb就有了用武之地。)rsc为reverse sbc版本的减法指令,同样是第二操作数减去第一操作数,同时减去!C,结果放在目的寄存器中。
🔆and,bic,orr,eor
-
and即「位与」AND<c> <Rdn>, <Rm> #Rdn = Rdn & Rm AND{S}<c> <Rd>, <Rn>, <Rm>{, <shift>} #Rd = Rn & (<Rm>{, <shift>}) -
bic为 清除指定的位,清除源寄存器中给定的位BIC<c> <Rdn>, <Rm> #Rdn = Rdn & ~Rm BIC{S}<c> <Rd>, <Rn>, <Rm>{, <shift>} #Rd = Rn & ~(<Rm>{, <shift>})可以直接使用目的寄存器作为源操作数,清除位由寄存器或者移位寄存器给出
-
orr表示位或,两个值位或,结果放在目的寄存器ORR<c> <Rdn>, <Rm>#Rdn = Rdn | Rm ORR{S}<c> <Rd>, <Rn>, <Rm>{, <shift>}#Rd = Rn | <Rm>{, <shift>} -
eor表示异或,两个值异或,结果放在目的寄存器EOR<c> <Rdn>, <Rm>#Rdn = Rdn ^ Rm EOR{S}<c> <Rd>, <Rn>, <Rm>{, <shift>}#Rd = Rn ^ <Rm>{, <shift>}
🔆cmp,cmn,teq,tst
测试指令,与其它指令不同的是,这些指令会自动将结果更新到状态寄存器中,而不需要选择条件执行
cmp:compare比较指令,实际的操作是将第一操作数减去第二操作数cmn:compare Negative,与 compare 执行相反的操作,将第一操作数加上第二操作数tst:test指令,将两个操作数位与teq:test equivalence,测试相等,将两个操作数异或
状态寄存器 CPSR 更新的原理是根据运算结果进行更新,如果结果为负,则N置位;为 0,则 Z 置位;产生进位,C 置位;产生溢出,V 置位
🔆 ldr,str,stmda,stmdb,stmib
ldr 和 str 是内存操作指令,因为 arm 不支持内存数据的直接操作,所以它们执行内存和寄存器之间的操作,因此这两条指令非常常用!
而对内存的操作往往伴随着流水线冒险等操作影响性能,因此需要考虑实际的效率影响,而对内存的操作通常有几种操作模式:
- 使用寄存器寻址
- 使用寄出去+偏移地址寻址
- 先偏移,取地址值,再对偏移的操作数赋上操作后的值
- 先取地址值,再偏移,然后再对偏移的操作数赋上操作后的值
直接上指令:
将当前 sp 地址处的数据加载到 r0 中
ldr r0,[sp]
将当前 sp+4 地址处的数据加载到 r0 中
ldr r0,[sp,#4] #[sp,#4] 表示 sp+4,其中立即数可以为负数
取 sp+4 处的地址值,然后将 sp 更新为 sp + 4
ldr r0,[sp,#4]!#感叹号(!)表示回写 sp = sp+4
取 sp 地址上的值,再将 sp 更新为 sp + 4.
ldr r0,[sp],#4
之所以设计成多重寻址模式,比如回写等等之类,主要还是考虑到操作效率问题,arm在一条指令里既实现了从内存加载值到寄存器,又实现了寄存器(另一个寄存器)的赋值,一举两得,缩减了多余指令,提高了效率。
ldr为取,而对于存str寻址模式是一样的,都是:
<{str|ldr}> Rn,Rm{,<shift>} #表示将 Rm 中地址处的数据加载到 Rn 中。
🔖除了常用的 str 和 ldr 之外,还有连续的内存操作指令:stmda,stmdb,stmia,stmib.
stmXY表示在执行动作Y,然后执行动作X;Y表示某个时机状态,X表是增减状态
STMDA<c> <Rn>{!}, <registers>
表示将一系列的寄存器值保存在 Rn 所表示的连续地址处
⭐️stmda:d:Decrement a:After,操作完一个寄存器之后将 Rn 中保存的地址递减 4.
⭐️stmdb:d:Decrement b:Before,操作寄存器之前将 Rn 中保存的地址递减 4
⭐️stmia: i:Increment a:After,操作完一个寄存器之后将 Rn 中保存的地址递增 4
⭐️stmib:i:Increment b:before,操作寄存器之前将 Rn 中保存的地址递增 4
这种操作通常在切换处理器模式时用于保存现场,将所有寄存器的值保存在当前栈上或者某个内存地址处
🔆pop,push
POP<c> <registers>
PUSH<c> <registers>
push {r0,r1,r2}
pop {r0,r1,r2}
林林总总大差不差,以上指令基本支撑起armv7架构下的汇编指令框架,此外更多的指令都在汇编手册中,不再赘述。
posted on 2021-12-27 23:57 shadow_fan 阅读(650) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号