笔试题汇总一(网易)
2018-03-27
一、选择题
1. 数字图像颜色空间中,常被彩色显像管采用的是哪一种:A
A、RGB B、HIS C、CMYX D、YUV
2. 用1*3的瓷砖密铺3*20的地板有几种方式:A
A、1278 B、595 C、406 D、872
3. 以下算法中未用到贪心算法思想的是:C
A、迪杰斯特拉(Dijkstra) B、普里姆算法(Prim) C、KMP D、库鲁斯卡尔(Kruskal)
(说明:贪心策略在图论中有着极其重要的应用。诸如Kruskal、 Prim、 Dijkstra等体现“贪心”思想的图形算法更是广泛地应用于树与图的处理。)
4. 字符串zmnzizi用哈夫曼编码来编码,共有多少位:C
A、11 B、12 C、13 D、14
(说明:z出现3次,i出现2次,m和n都只出现1次,用哈夫曼编码后为——z(1),i(01),m(000),n(001),所以编码为——1000001101101,共13位。)
5. 下列关于核函数描述正确的是:
A、核函数即特征的映射关系
B、高斯核函数将特征映射到无穷维
C、使用线性核函数的SVM是非线性分类器
D、多项式核函数只是将原始核函数映射,并没有升维
6. 下面C++代码的输出:B
A、3 3 B、2 3 C、3 2 D、2 2
1 int main() 2 { 3 int arr[] = {1,2,3,4,5,6,7}; 4 int *p = arr; 5 *(p++) += 89; 6 printf("%d,%d\n", *p,*(++p)); 7 return 0; 8 }
7. 随机变量X和Y的Pearson相关系数ρ取得最大值的充要条件是:B
A、X和Y独立 B、X和Y正相关 C、X和Y不相关 D、X等于Y
(说明:相互独立,协方差为0,相关系数为0。
当![]() 较大时,通常说X 和Y相关程度较好;当
较大时,通常说X 和Y相关程度较好;当![]() 较小时,通常说X 和Y相关程度较差。
较小时,通常说X 和Y相关程度较差。
相关系数的取值范围为(-1,+1)。当相关系数小于0时,称为负相关;大于0时,称为正相关;等于0时,称为零相关。)
8. 已知中序遍历的序列为abcdef,高度最小的不可能的二叉树前序遍历是:C
A、dbacfe B、cbaedf C、cabefd D、dbacef
9. 某地区每个人的年收入是右偏的,均值为5000元,标准差为1200元。随机取900人记录年收入,则样本的分布:A
A、近似正态分布,均值为5000元,标准差为40元
B、右偏分布,均值为5000元,标准差为40元
C、近似正态分布,均值为5000元,标准差为1200元
D、左偏分布,均值为5000元,标准差为1200元
10. 一个完全二叉树节点数为200,则叶子节点个数为:C
A、98 B、99 C、100 D、101
(说明:假设n0是度为0的结点总数(即叶子结点数),n1是度为1的结点总数,n2是度为2的结点总数,则 ①n= n0+n1+n2 (其中n为完全二叉树的结点总数);
又因为一个度为2的结点会有2个子结点,一个度为1的结点会有1个子结点,除根结点外其他结点都有父结点,所以②n= 1+n1+2*n2 ;
由①、②两式把n2消去得:n= 2*n0+n1-1,由于完全二叉树中度为1的结点数只有两种可能0或1,由此得到n0=n/2 或 n0=(n+1)/2。)
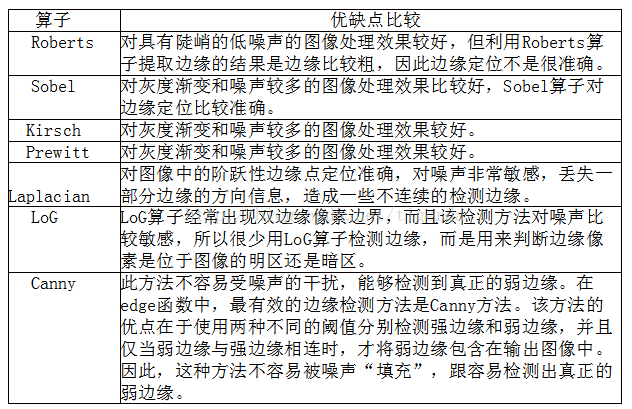
11. 如下边缘检测算子中,时间复杂度最高的是:C
A、Sobel算子 B、Prewitt算子 C、Canny算子 D、Roberts算子
(说明:常见边缘检测算子:Roberts 、Sobel 、Prewitt、Laplacian、Log/Marr、Canny、Kirsch、Nevitia
一阶微分算子:Roberts 、Sobel 、Prewitt
二阶微分算子:Laplacian、Log/Marr
非微分边缘检测算子:Canny
方向算子Kirsch(8个3*3模板),Nevitia (12个5*5模板))

12. 下列选项中,不可能是快速排序第二趟排序结果的是:B
A、4 14 10 12 8 6 18 B、6 4 10 8 14 12 18 C、8 4 6 10 12 14 18 D、4 6 10 8 12 14 18
(说明:快排第n趟排序结果校验——每趟排序就有一个元素排在了最终的位置上。那么就是说,第n趟结束,至少有n个元素已经排在了最终的位置上。)
13. python是用C语言写成的,根据名字空间特性,以下代码经过python编辑器编译后,一共得到几个PyCodeObject对象:D
A、=A() Fun() B、1 C、2 D、3
(说明:给个链接,写的很详细——https://www.cnblogs.com/fortwo/archive/2013/05/10/3071699.html)
(Python编译器在对Python源码进行编译的时候,对代码中的一个Code Block,会创建一个PyCodeObject对象与这段代码对应。
Python中确定Code Block的规则:当进入一个新的名字空间或作用域时,就算进入了一个新的Code Block了。
即:一个名字空间对应一个Code Block,它会对应一个PyCodeObject。
现在暂且认为名字空间就是符号的上下文环境,是名字到对象的映射。名字空间以后会详述。
在Python中,类、函数和module都对应着一个独立的名字空间,因此都会对应一个PyCodeObject对象。)
1 class A: 2 pass 3 def Fun(): 4 pass 5 a = A() 6 Fun()
14. 已知有4个矩阵大小分别为M1(5*3)、M2(3*4)、M3(4*2)、M4(2*7),下面组合计算所需要的乘法次数最优为:C
A、(M1(M2(M3M4))) B、(M1((M2M3)M4)) C、((M1(M2M3))M4)
D、(((M1M2)M3)M4) E、((M1M2)(M3M4))
(说明:若A是一个p×q的矩阵,B是一个q×r的矩阵,则其乘积C=AB是一个p×r的矩阵。其标准计算公式为:
![]()
由该公式知计算C=AB总共需要pqr次的数乘。
编程题:动态规划--矩阵连乘的最优乘法顺序——https://blog.csdn.net/sixtyfour/article/details/12250415)
15. 下列哪个不是SVM的优势:B
A、可以与核函数结合 B、训练速度快
C、泛化能力好 D、通过调参往往可以得到很好的分类效果
16. 对于线性表(13,25,22,35,54,57,63)进行散列存储时,若选用H(K)=K%7作为散列函数,则散列地址为1的元素有:C
A、0 B、1 C、2 D、3
17. 想实现用装饰器来计时,空白处应填写什么:A
A、无需填写 B、@time(fn) C、@functools.wraps(fn) D、@functools
import time,functools def metric(fn): #empty def wrapper(*args,**kw): startTime = time.time() tmp = fn(*args,**kw) endTime = time.time() print('%s executed in %s s' % (fn.__name__, endTime-startTime)) return tmp return wrapper
18.下面C++代码的输出是:D
A、12 12 B、随机数 随机数 C、12 随机数 D、随机数 12
class base1{ private: int a,b; public: base1(int i):b(i+1),a(b){} base1():b(0),a(b){} int get_a(){return a;} int get_b(){return b;} }; int main() { base1 obj1(11); cout<<obj1.get_a()<<endl<<obj1.get_b()<<endl; return 0; }
19. 大津法(OSTU算法)阈值分割中,阈值自动选择的思路是:B
A、由直方图灰度分布选择阈值 B、最大化类间方差选择阈值
C、最大最小灰度值二分迭代逼近法选择阈值 D、双峰法选择阈值
(说明:OTSU算法又称为最大类间方差法。)
(图像单阈值分割方法:
1. 双峰法——图像由前景和背景组成,在灰度直方图上,前后二景都形成高峰,在双峰之间的最低谷处就是图像的阈值所在。
2. 迭代法(基于逼近的思想)——求出图象的最大灰度值和最小灰度值,分别记为ZMAX和ZMIN,令初始阈值T0=(ZMAX+ZMIN)/2;根据阈值TK将图象分割为前景和背景,分别求出两者的平均灰度值ZO和ZB;求出新阈值TK+1=(ZO+ZB)/2;若TK=TK+1,则所得即为阈值;否则转2,迭代计算。
3. 大津法(OTSU法)——对图像Image,记t为前景与背景的分割阈值,前景点数占图像比例为w0, 平均灰度为u0;背景点数占图像比例为w1,平均灰度为u1。图像的总平均灰度为:u=w0*u0+w1*u1。从最小灰度值到最大灰度值遍历t,当t使得值g=w0*(u0-u)2+w1*(u1-u)2 最大时t即为分割的最佳阈值。对大津法可作如下理解:该式实际上就是类间方差值,阈值t分割出的前景和背景两部分构成了整幅图像,而前景取值u0,概率为w0,背景取值u1,概率为w1,总均值为u,根据方差的定义即得该式。因方差是灰度分布均匀性的一种度量,方差值越大,说明构成图像的两部分差别越大,当部分目标错分为背景或部分背景错分为目标都会导致两部分差别变小,因此使类间方差最大的分割意味着错分概率最小。
4. 灰度拉伸的增强大津法——在大津法的基础上通过增加灰度的级数来增强前后景的灰度差,从而解决问题。灰度增加的方法是用原有的灰度级乘上同一个系数,从而扩大灰度的级数,特别地,当乘上的系数为1时,这就是大津法的原型。
5. Kirsh算子——对数字图像的每个像素i,考虑它的八个邻点的灰度值,以其中三个相邻点的加权和减去剩下五个邻点的加权和得到差值,令三个邻点绕该像素点不断移位,取此八个差值的最大值作为Kirsh算子。即:设Si为三邻点之和,Ti为五邻点之和,则Kirsh算子定义为K(i)=max{1,max〔5Si-3Ti〕}如取阈值THk,则当K(i)>THk时,像素i为阶跃边缘点。
)
20. 函数y=x^x,(x>0)的极小值点为:C
A、1 B、(√2)^(√2) C、(1/e)^(1/e) D、√2
(说明:y=x^x,lny=xlnx,求导,函数在x=1/e时,取最小值y=(1/e)^(1/e))
二、编程题
贴一个博客地址,他总结的比较好:https://blog.csdn.net/q295657451

 浙公网安备 33010602011771号
浙公网安备 33010602011771号