1、继承的实现原理:经典类:深度优先(一路到底),新式类:广度优先
只有在python2中才分新式类和经典类,python3中统一都是新式类
2.在python2中,没有显式的继承object类的类,以及该类的子类,都是经典类3.在python2中,显式地声明继承object的类,以及该类的子类,都是新式类4.在python3中,无论是否继承object,都默认继承object,即python3中所有类均为新式类print(F.__mro__)


class A(object): def test(self): print('from A') class B(A): def test(self): print('from B') class C(A): def test(self): print('from C') class D(B): def test(self): print('from D') class E(C): def test(self): print('from E') class F(D,E): # def test(self): # print('from F') pass f1=F() f1.test() print(F.__mro__) #只有新式才有这个属性可以查看线性列表,经典类没有这个属性 #新式类继承顺序:F->D->B->E->C->A #经典类继承顺序:F->D->B->A->E->C #python3中统一都是新式类 #pyhon2中才分新式类与经典类
1.1、子类调用父类,指名道姓与super()的区别
#指名道姓 class A: def __init__(self): print('A的构造方法') class B(A): def __init__(self): print('B的构造方法') A.__init__(self) class C(A): def __init__(self): print('C的构造方法') A.__init__(self) class D(B,C): def __init__(self): print('D的构造方法') B.__init__(self) C.__init__(self) pass f1=D() #A.__init__被重复调用 ''' D的构造方法 B的构造方法 A的构造方法 C的构造方法 A的构造方法 ''' #使用super() class A: def __init__(self): print('A的构造方法') class B(A): def __init__(self): print('B的构造方法') super(B,self).__init__() class C(A): def __init__(self): print('C的构造方法') super(C,self).__init__() class D(B,C): def __init__(self): print('D的构造方法') super(D,self).__init__() f1=D() #super()会基于mro列表,往后找 ''' D的构造方法 B的构造方法 C的构造方法 A的构造方法 '''
1.2、多重继承的执行顺序,请解答以下输出结果是什么?并解释。
class A(object): def __init__(self): print('A') super(A, self).__init__() class B(object): def __init__(self): print('B') super(B, self).__init__() class C(A): def __init__(self): print('C') super(C, self).__init__() class D(A): def __init__(self): print('D') super(D, self).__init__() class E(B, C): def __init__(self): print('E') super(E, self).__init__() class F(C, B, D): def __init__(self): print('F') super(F, self).__init__() class G(D, B): def __init__(self): print('G') super(G, self).__init__() if __name__ == '__main__': g = G() print(g.__class__.mro()) print('----------') f = F() print(f.__class__.mro()) G D A B [<class '__main__.G'>, <class '__main__.D'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>] ---------- F C B D A [<class '__main__.F'>, <class '__main__.C'>, <class '__main__.B'>, <class '__main__.D'>, <class '__main__.A'>, <class 'object'>] Process finished with exit code 0
2、组合指,在一个类中以另外一个类的对象作为数据属性
3、抽象类:从一堆类中抽取相同的内容而来的,包括数据属性和函数属性,只能被继承,不能被实例化,------归一化设计
import abc class All_file(metauclass=abc.ABCmeta): all_file='file' @abc.abctractmethod def read(self): pass
4、封装的概念--1封装数据;2隔离复杂度
将数据隐藏起来这不是目的。隐藏起来然后对外提供操作该数据的接口,然后我们可以在接口附加上对该数据操作的限制,以此完成对数据属性操作的严格控制。
5、多次序列化到文件,读取出来是怎么样
dump 几次到文件,反序列化时,要想全部读取出来就得 load几次:
参考:https://blog.csdn.net/wx1314320tj/article/details/53539155 import os import pickle data1 = {'a': [1, 2.0, 3, 4+6j], 'b': ('string', u'Unicode string'), 'c': None} data2 = {'aa': [1, 2.0, 3, 4+6j], 'bb': ('string', u'Unicode string'), 'cc': None} pkfile=open("testfile.txt",'ab') pickle.dump(data1,pkfile) pickle.dump(data2,pkfile) pkfile.close() pkfile2=open("testfile.txt",'rb') pkf=pickle.load(pkfile2) pkf1=pickle.load(pkfile2) print(pkf) print(pkf1) ---------------------
所以解决方法如下: Pickle 每次序列化生成的字符串有独立头尾,pickle.load() 只会读取一个完整的结果,
所以你只需要在 load 一次之后再 load 一次,就能读到第二次序列化的 [‘asd’, (‘ss’, ‘dd’)]。
如果不知道文件里有多少 pickle 对象,可以在 while 循环中反复 load 文件对象,直到抛出异常为止。
使用try … except语句即可。 -----
with open("testfile.txt",'rb') as f: while True: try: pkf=pickle.load(f) print(pkf) except Exception as e: print(e) break
6、instance(obj,cls)检查是否obj是类cls的对象
7、反射的概念
8、元类的概念
9、网络编程中解决粘包问题的两种形式:
9.1、远程执行服务端系统命令:
(1)引入subprocess模块与系统交互---引入管道的知识
(2)引入struct模块,先发报头的长度,再发报头(客户端根据接受完整的报头得到里面存储的文件长度)
obj = subprocess.Popen(cmd.decode('utf-8'), shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
stdout=obj.stdout.read() # 字节类型
stderr=obj.stderr.read() # 字节类型
#3、把命令的结果返回给客户端
#第一步:制作固定长度的报头
header_dic={
'filename':'a.txt',
'md5':'xxdxxx',
'total_size': len(stdout) + len(stderr) # 字节的长度 -------- 文件的大小
}
header_json=json.dumps(header_dic)
header_bytes=header_json.encode('utf-8')
#第二步:先发送报头的长度
conn.send(struct.pack('i',len(header_bytes))) # len(header_bytes)发送信息给客户端的字节长度
#第三步:再发报头
conn.send(header_bytes) # 客户端发两次
#第四步:再发送真实的数据
conn.send(stdout)
conn.send(stderr)
可以直接打包 发送数据的长度-----客户端解压依次即可
也可以间接发送数据的长度 先发head_dic报头长度,再发报头,,客户端解压报头 得到报头里面的数据长度
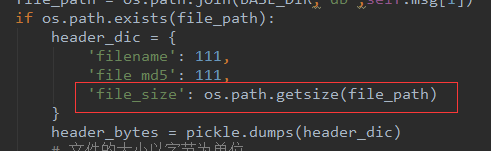
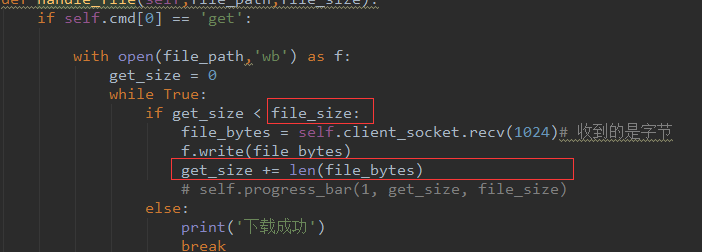
9.2、上传下载文件os.path.getsize(pt_path),文件的大小--字节的长度 --<class 'int'>
file_size = os.path.getsize(pt_path)
print(file_size,type(file_size))
290 <class 'int'>
悟已往之不谏,知来者之可追。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号