
计算机底层是如何访问显卡的?
其实你可以把显卡想象成另外一台机器。那么控制另外一台机器的办法,就是往它的内存里面写指令和数据。往一块内存里面写东西的办法无非就几种,1, 用CPU去做,那么就是用MMIO(Memory Mapped IO)把'显存' map到CPU寻址空间,然后去读写,2, 用DMA控制器去做,这里面有系统自带的DMA控制器或者显卡带的,不管哪种你可以把DMA控制器再一次看作另外一台机器,那么其实就是向DMA控制器写指令让它帮你传一些东西到显存去,传的这些东西就是显卡要执行的命令和数据。显卡上的内存控制器,原来AGP的时候叫GART,现在不知道叫啥名了,另外SoC里面也有类似的概念,不过大多数SoC只有一个内存控制器,所以不分显存和内存。
把显卡想象成另外一台机器。它要工作,无非也是“程序存储”原理,上电之后,从特定的内存(显存)地址去取指,然后执行指令。显卡的工作逻辑比CPU简单多了,它一般就从一个环形buffer不断的取指令,然后执行,CPU就不断的去往环形buffer填指令。
很多时候同一个动作既可以用MMIO,也可以用DMA,比如flip framebuffer。只要把flip framebuffer的指令正确传到环形buffer就好了。但是MMIO需要CPU参与,传大数据的时候,打乱CPU GPU并行性,划不来。
驱动程序其实也是围绕着这件事情来做的,Vista以前,显卡的驱动全都是kernel mode执行的,因为只有kernel mode才能访问的物理地址,但是kernel mode的坏处是一旦有问题,系统就崩溃,而且kernel mode有很多局限性,比如没有C库支持,浮点运算很难,代价很大等等。所以Vista之后,显卡驱动都分两部分,kmd负责需要访问物理地址的动作,其他事情都放到umd去做,包括API支持等等。所以一个3D程序执行的过程是这样的,app generate command, call D3D runtime,D3D runtime call driver umd, driver umd system call driver kmd, kmd send command to ring buffer, graphic card exeute.
至于显卡驱动要完成什么部分,这个就是所谓HAL(hardware abstraction layer)层,也就是说HAL以下由厂商提供,以上就是操作系统自带,在HAL层以上,所有的操作都是统一的,比如画一个点,画一条线,驱动来对应具体的某一款芯片生成真正的命令,比如画点,需要0x9指令,把绝对坐标放到地址0x12345678(举例)。微软管的比较宽,umd, kmd都有HAL层,意思是即使kmd你也不能乱写,能统一的尽量统一,比如CPU GPU external fence读写同步机制就是微软统一做的。
流处理器就是说,那些处理器可以执行很多的指令,而不是就几个固定的功能,比如原来我把几个矩阵的乘法固定成一个操作(比如T&L单元),现在我把这个操作拆了,改成更基本的指令,比如,取矩阵元素,加乘,这样更灵活。不过你就得多费心思去组合这些指令了,组合这些指令有个高大上的名字,shader。至于为什么叫shader,越来越长了,不说了。
***************************************************************************************************************************************************
在回答这个问题之前,必须要有一些限定。因为显卡是有很多种,显卡所在平台也很多种,不能一概而论。我的回答都是基于Intel x86平台下的Intel自家的GEN显示核心单元(也就是市面上的HD 4000什么的)。操作系统大多数以Linux为例。
>>> Q1. 显卡驱动是怎么控制显卡的, 就是说, 使用那些指令控制显卡, 通过端口么?
目前的显卡驱动,不是单纯的一个独立的驱动模块,而是几个驱动模块的集合。用户态和内核态驱动都有。以Linux桌面系统为例,按照模块划分,内核驱动有drm/i915模块, 用户驱动包括libdrm, Xorg的DDX和DIX,3D的LibGL, Video的Libva等等,各个用户态驱动可能相互依赖,相互协作,作用各不相同。限于篇幅无法一一介绍。如果按照功能划分的话,大概分成5大类,display, 2D, 3D, video, 以及General Purpose Computing 通用计算。Display是关于如何显示内容,比如分辨率啊,刷新率啊,多屏显示啊。2D现在用的很少了,基本就是画点画线加速,快速内存拷贝(也就是一种DMA)。3D就复杂了,基本现在2D的事儿也用3D干。3D涉及很多计算机图形学的知识,我的短板,我就不多说了。Video是指硬件加速的视频编解码。通用计算就是对于OpenCL,OpenCV,CUDA这些框架的支持。
回到问题,驱动如何控制显卡。
首先,操作硬件的动作是敏感动作,一般只有内核才有权限。个别情况会由用户态操作,但是也是通过内核建立寄存器映射才行。
理解驱动程序最重要的一句话是,寄存器是软件控制硬件的唯一途径。所以你问如何控制显卡,答案就是靠读写显卡提供的寄存器。
通过什么读写呢?据我所知的目前的显卡驱动,基本没有用低效的端口IO的方式读写。现在都是通过MMIO把寄存器映射的内核地址空间,然后用内存访问指令(也就是一般的C语言赋值语句)来访问。具体可以参考”内核内存映射,MMIO“的相关资料。
>>>Q2.2. DirectX 或 OpenGL 或 CUDA 或 OpenCL 怎么找到显卡驱动, 显卡驱动是不是要为他们提供接口的实现, 如果是, 那么DirectX和OpenGL和CUDA和OpenCL需要显卡驱动提供的接口都是什么, 这个文档在哪能下载到? 如果不是, 那么DirectX, OpenGL, CL, CUDA是怎么控制显卡的?
这个问题我仅仅针对OpenGL和OpenCL在Linux上的实现尝试回答一下。
a.关于如何找到驱动?首先这里我们要明确一下驱动程序是什么,对于OpenGL来说,有个用户态的库叫做LibGL.so,这个就是OpenGL的用户态驱动(也可以称之为库,但是一定会另外再依赖一个硬件相关的动态库,这个就是更狭义的驱动),直接对应用程序提供API。同样,OpenCL,也有一个LibCL.so.。这些so文件都依赖下层更底层的用户态驱动作为支持(在Linux下,显卡相关的驱动,一般是一个通用层驱动.so文件提供API,然后下面接一个平台相关的.so文件提供对应的硬件支持。比如LibVA.so提供视频加速的API,i965_video_drv.so是他的后端,提供Intel平台对应libva的硬件加速的实现)。 下面给你一张大图: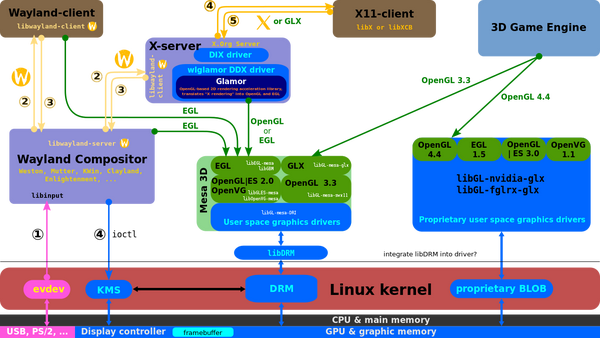 如图可见,最上层的用户态驱动向下依赖很多设备相关的驱动,最后回到Libdrm这层,这一层是内核和用户态的临界。一般在这里,想用显卡的程序会open一个/dev/dri/card0的设备节点,这个节点是由显卡内核驱动创建的。当然这个open的动作不是由应用程序直接进行的,通常会使用一些富足函数,比如drmOpenByName, drmOpenByBusID. 在此之前还会有一些查询的操作,查询板卡的名称或者Bus ID。然后调用对应的辅助函数打开设备节点。打开之后,他就可以根据DRI的规范来使用显卡的功能。我说的这一切都是有规范的,在Linux里叫DRI(Direct Rendering Infrastructure)。
如图可见,最上层的用户态驱动向下依赖很多设备相关的驱动,最后回到Libdrm这层,这一层是内核和用户态的临界。一般在这里,想用显卡的程序会open一个/dev/dri/card0的设备节点,这个节点是由显卡内核驱动创建的。当然这个open的动作不是由应用程序直接进行的,通常会使用一些富足函数,比如drmOpenByName, drmOpenByBusID. 在此之前还会有一些查询的操作,查询板卡的名称或者Bus ID。然后调用对应的辅助函数打开设备节点。打开之后,他就可以根据DRI的规范来使用显卡的功能。我说的这一切都是有规范的,在Linux里叫DRI(Direct Rendering Infrastructure)。
所有这些图片文档都可以Direct Rendering Infrastructure 和 freedesktop上的页面DRI wiki找到DRI Wiki
显卡驱动的结构很复杂,这里有设计原因也有历史原因。
b.关于接口的定义,源代码都可以在我上面提供的链接里找到。这一套是规范,有协议的。
c.OpenGL, OpenCL或者LibVA之类的需要显卡提供点阵运算,通用计算,或者编解码服务的驱动程序,一般都是通过两种途径操作显卡。第一个是使用DRM提供的ioctl机制,就是系统调用。这类操作一般包括申请释放显存对象,映射显存对象,执行GPU指令等等。另一种是用户态驱动把用户的API语意翻译成为一组GPU指令,然后在内核驱动的帮助下(就是第一种的执行GPU指令的ioctl)把指令下达给GPU做运算。具体细节就不多说了,这些可以通过阅读源代码获得。
>>>Q4. 显卡 ( 或其他设备 ) 可以访问内存么? 内存地址映射的原理是什么, 为什么 B8000H 到 C7FFFH 是显存的地址, 向这个地址空间写入数据后, 是直接通过总线写入显存了么, 还是依然写在内存中, 显卡到内存中读取, 如果直接写到显存了, 会出现延时和等待么?
a..可以访问内存。如果访问不了,那显示的东西是从哪儿来的呢?你在硬盘的一部A片,总不能自己放到显卡里解码渲染吧?
b.显卡访问内存,3种主要方式。
第一种,就是framebuffer。CPU搞一块内存名叫Framebuffer,里面放上要显示的东西,显卡有个部件叫DIsplay Controller会扫描那块内存,然后把内容显示到屏幕上。至于具体如何配置成功的,Long story, 这里不细说了。
第二种,DMA。DMA懂吧?就是硬件设备直接从内存取数据,当然需要软件先配置,这就是graphics driver的活儿。在显卡驱动里,DMA还有个专用的名字叫Blit。
第三种,内存共享。Intel的平台,显存和内存本质都是主存。区别是CPU用的需要MMU映射,GPU用的需要GPU的MMU叫做GTT映射。所以共享内存的方法很简单,把同一个物理页既填到MMU页表里,也填到GTT页表里。具体细节和原理,依照每个人的基础不同,需要看的文档不同。。。
c.为什么是那个固定地址?这个地址学名叫做Aperture空间,就是为了吧显存映射到一个段连续的物理空间。为什么要映射,就是为了显卡可以连续访问一段地址。因为内存是分页的,但是硬件经常需要连续的页。其实还有一个更重要的原因是为了解决叫做tiling的关于图形内存存储形势和不同内存不一致的问题(这个太专业了对于一般人来说)。
这地址的起始地址是平台相关,PC平台一般由固件(BIOS之流)统筹规划总线地址空间之后为显卡特别划分一块。地址区间的大小一般也可以在固件里指定或者配置。
另外,还有一类地址也是高位固定划分的称为stolen memory,这个是x86平台都有的,就是窃取一块物理内存专门为最基本的图形输出使用,比如终端字符显示,framebuffer。起始地址也是固件决定,大小有默认值也可以配置。
d. 刚才说了,Intel的显存内存一回事儿。至于独立显卡有独立显存的平台来回答你这个问题是这样的:任何访存都是通过总线的,直接写也是通过总线写,拷贝也是通过总线拷贝;有时候需要先写入临时内存再拷贝一遍到目标区域,原因很多种;写操作都是通过PCI总线都有延迟,写谁都有。总线就是各个设备共享的资源,需要仲裁之类的机制,肯定有时候要等一下。
>>>Q5. 以上这些知识从哪些书籍上可以获得?
Intel Graphics for Linux*, 从这里看起吧少年。这类过于专业的知识,不建议在一般经验交流的平台求助,很难得到准确的答案。你这类问题,需要的就是准确答案。不然会把本来就不容易理解的问题变得更复杂。
references:
http://www.zhihu.com/question/20722310

 浙公网安备 33010602011771号
浙公网安备 33010602011771号