Flume(一) —— 启动与基本使用
基础架构
Flume is a distributed, reliable(可靠地), and available service for efficiently(高效地) collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
Flume是一个分布式、高可靠、高可用的服务,用来高效地采集、聚合和传输海量日志数据。它有一个基于流式数据流的简单、灵活的架构。
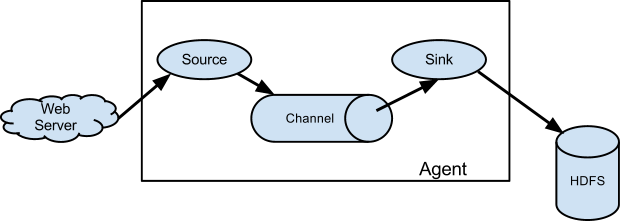
A Flume source consumes events delivered to it by an external source like a web server. The external source sends events to Flume in a format that is recognized by the target Flume source. For example, an Avro Flume source can be used to receive Avro events from Avro clients or other Flume agents in the flow that send events from an Avro sink. A similar flow can be defined using a Thrift Flume Source to receive events from a Thrift Sink or a Flume Thrift Rpc Client or Thrift clients written in any language generated from the Flume thrift protocol.When a Flume source receives an event, it stores it into one or more channels. The channel is a passive store that keeps the event until it’s consumed by a Flume sink. The file channel is one example – it is backed by the local filesystem. The sink removes the event from the channel and puts it into an external repository like HDFS (via Flume HDFS sink) or forwards it to the Flume source of the next Flume agent (next hop) in the flow. The source and sink within the given agent run asynchronously with the events staged in the channel.
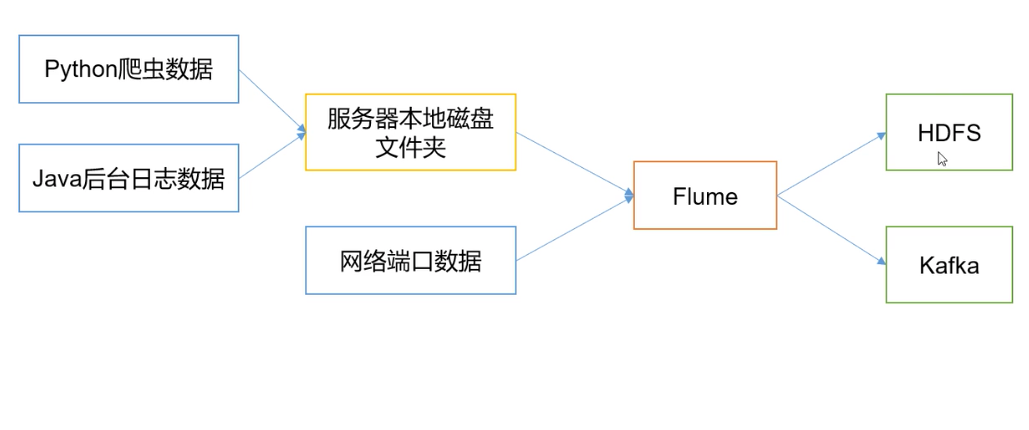
Flume在下图中的作用是,实时读取服务器本地磁盘的数据,将数据写入到HDFS中。
Agent
是一个JVM进程,以事件的形式将数据从源头送至目的地。
Agent的3个主要组成部分:Source、Channel、Sink。
Source
负责接收数据到Agent。
Sink
不断轮询Channel,将Channel中的数据移到存储系统、索引系统、另一个Flume Agent。
Channel
Channel是Source和Sink之间的缓冲区,可以解决Source和Sink处理数据速率不匹配的问题。
Channel是线程安全的。
Flume自带的Channel:Memory Channel、File Channel、Kafka Channel。
Event
Flume数据传输的基本单元。
安装&部署
下载
下载1.7.0安装包
修改配置
修改flume-env.sh配置中的JDK路径
创建 job/flume-netcat-logger.conf,文件内容如下:
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
## 事件容量
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
## channel 与 sink 的关系是 1对多 的关系。1个sink只可以绑定1个channel,1个channel可以绑定多个sink。
a1.sinks.k1.channel = c1
启动、运行
启动flume
bin/flume-ng agent --conf conf --conf-file job/flume-netcat-logger.conf --name a1 -Dflume.root.logger=INFO,console
使用natcat监听端口
nc localhost 44444
运行结果

监控Hive日志上传到HDFS
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe / configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /usr/local/logs/hive/hive.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
a1.sinks.k1.type = hdfs
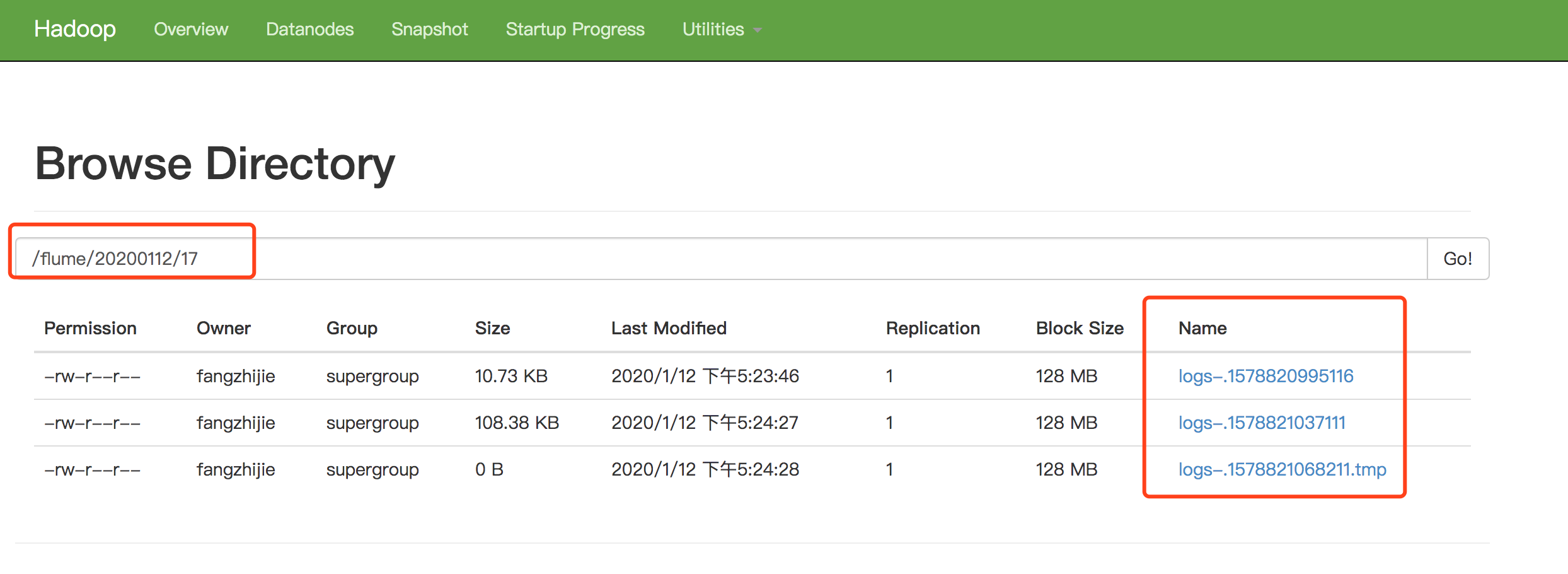
a1.sinks.k1.hdfs.path = hdfs://localhost:9000/flume/%Y%m%d/%H
a1.sinks.k1.hdfs.filePrefix = logs-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 1
a1.sinks.k1.hdfs.roundUnit = hour
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.batchSize = 1000
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 30
a1.sinks.k1.hdfs.rollSize = 13417700
a1.sinks.k1.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
执行命令bin/flume-ng agent -c conf/ -f job/file-flume-logger.conf -n a1
数据通过Flume传到Kafka
使用natcat监听端口数据通过Flume传到Kafka
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe / configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = payTopic
a1.sinks.k1.kafka.bootstrap.servers = 127.0.0.1:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
运行结果


参考文档
Flume官网
Flume 官网开发者文档
Flume 官网使用者文档
尚硅谷大数据课程之Flume
FlumeUserGuide
关于作者
后端程序员,五年开发经验,从事互联网金融方向。技术公众号「清泉白石」。如果您在阅读文章时有什么疑问或者发现文章的错误,欢迎在公众号里给我留言。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号