使用deepseek实现本地or远程部署搭建自己的AI
@[TOC](使用deepseek实现本地or远程部署搭建自己的AI )
# 一. 使用deepseek实现本地or远程部署搭建自己的AI
## 访问 Ollama 官方地址,并下载软件
- [Ollama官网地址](https://ollama.com/download)
> 建议下载最新版本 Ollama,个人踩坑经历:旧版本安装 R1 后可能无法正常使用。

## 选择自己要安装的模型
> 双击运行 Ollama 后,打开命令行,运行需要安装的模型(参数越大,显存要求越高)
- [模型下载地址](https://ollama.com/library/deepseek-r1)
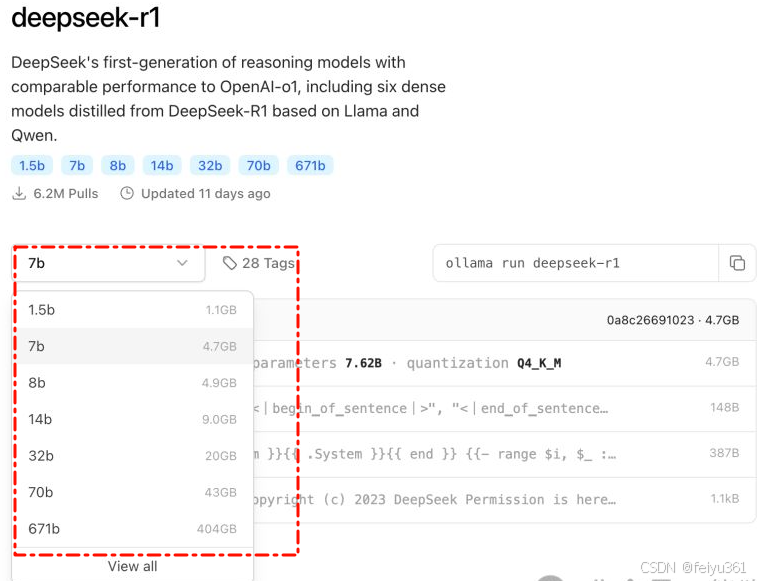
### 下载模型选择建议
> 如果没有 GPU,建议选择 1.5B,运行相对轻量。我这 4G 显存 勉强能跑 8B,但速度较慢。
> 有朋友用 RTX 4090 测试 32B,效果和速度都不错。大家可以参考这个梯度,根据自己的硬件选择合适的模型。。
### 复制官网的命令即可,模型比较大,静静等待即可
> 注意
- 7B模型:至少8GB空闲内存
- 33B模型:至少32GB空闲内存

**DeepSeek-R1-Distill-Qwen-1.5B**
```js
ollama run deepseek-r1:1.5b
```
**DeepSeek-R1-Distill-Qwen-7B**
```js
ollama run deepseek-r1:7b
```
**DeepSeek-R1-Distill-Llama-8B**
```js
ollama run deepseek-r1:8b
```
**DeepSeek-R1-Distill-Qwen-14B**
```js
ollama run deepseek-r1:14b
```
**DeepSeek-R1-Distill-Qwen-32B**
```js
ollama run deepseek-r1:32b
```
**DeepSeek-R1-Distill-Llama-70B**
```js
ollama run deepseek-r1:70b
```
**DeepSeek-R1-Distill-Llama-671B**
```js
ollama run deepseek-r1:671b
```
### 查看已安装模型
```js
ollama list # 查看已安装模型
```

### 运行模型
```js
ollama run qwen2.5-coder:7b
ollama run deepseek-r1:7b
```
### 退出聊天框
```js
Ctrl+d
/bye
```
### 删除 模型
```js
ollama rm qwen2.5-coder:7b
```
## 搭配 Cherry Studio 的软件
- [Cherry Studio下载地址](https://cherry-ai.com/download)

### 添加模型
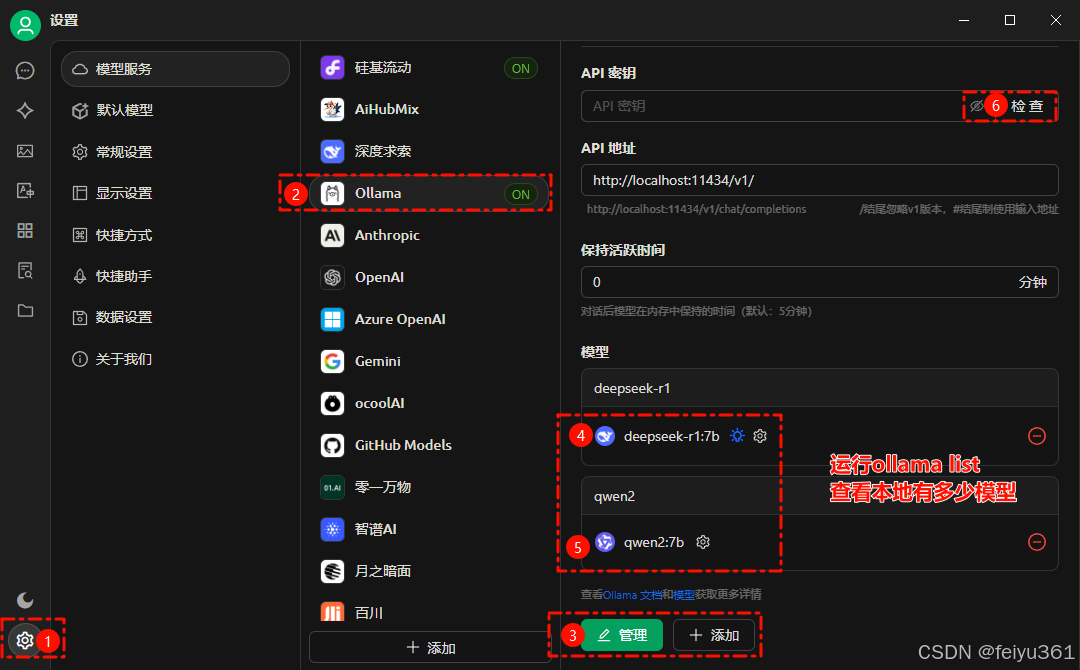
### 最后点击检查,测试下网络连通性,出现连接成功即可。
### 接下来就可以在添加助手时,选择本地部署的 R1 模型啦。
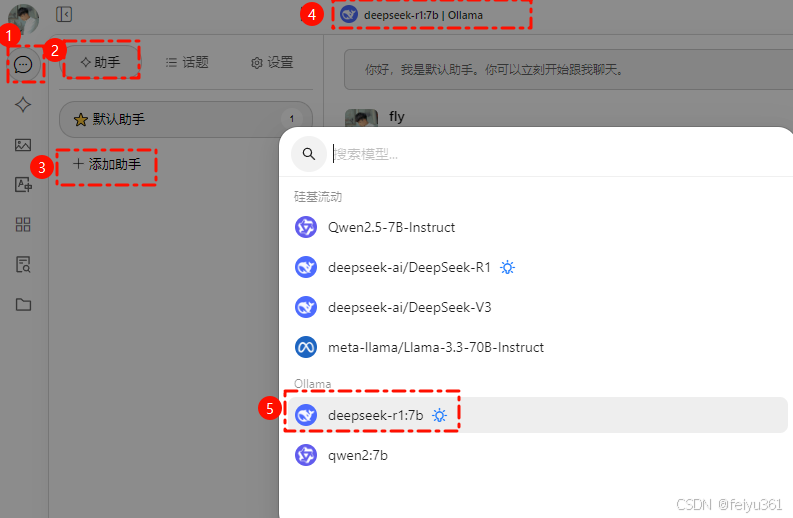
### 再测试使用一下,搞定 ~
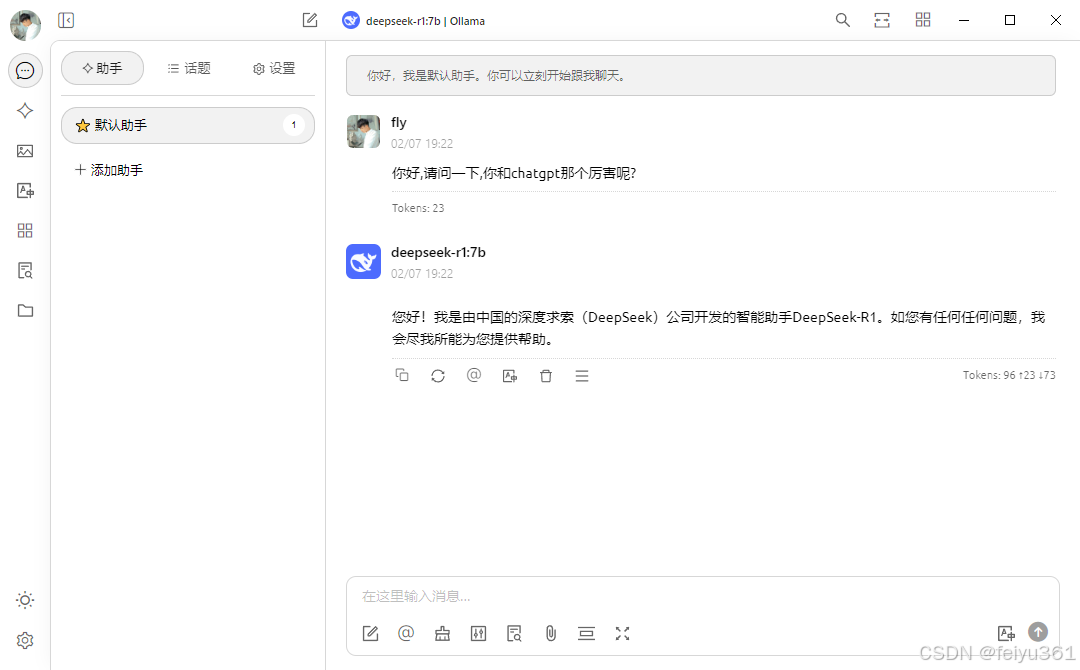
# 二. 实现远程部署使用
## 搭配 Cherry Studio 的软件
- [Cherry Studio下载地址](https://cherry-ai.com/download)
## 注册一个能够免费试用2000Token的邀请码
- [邀请注册地址](https://cloud.siliconflow.cn/i/3mxJyoH6)
- 或者填写邀请码: 3mxJyoH6
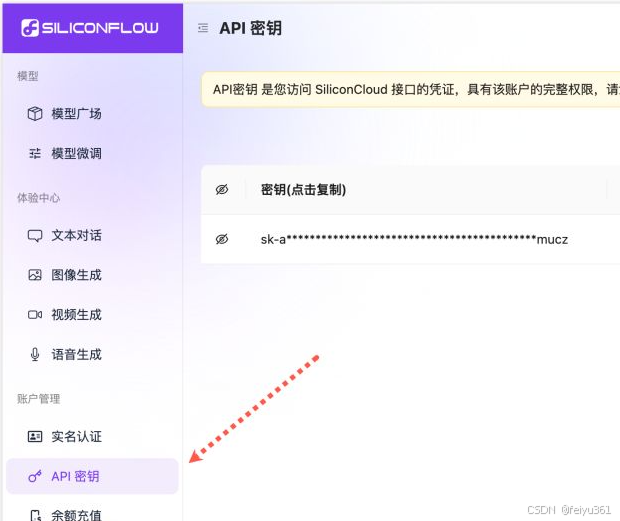
### 进入到页面进行api密钥的生成
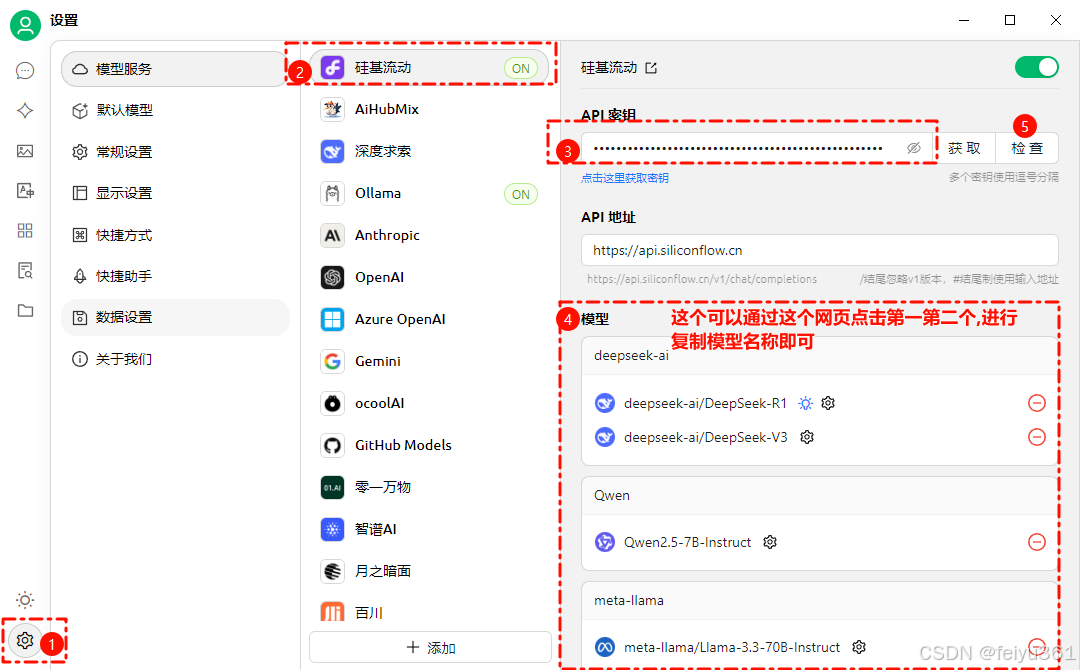
### 来到 Cherry Studio,配置 API Key
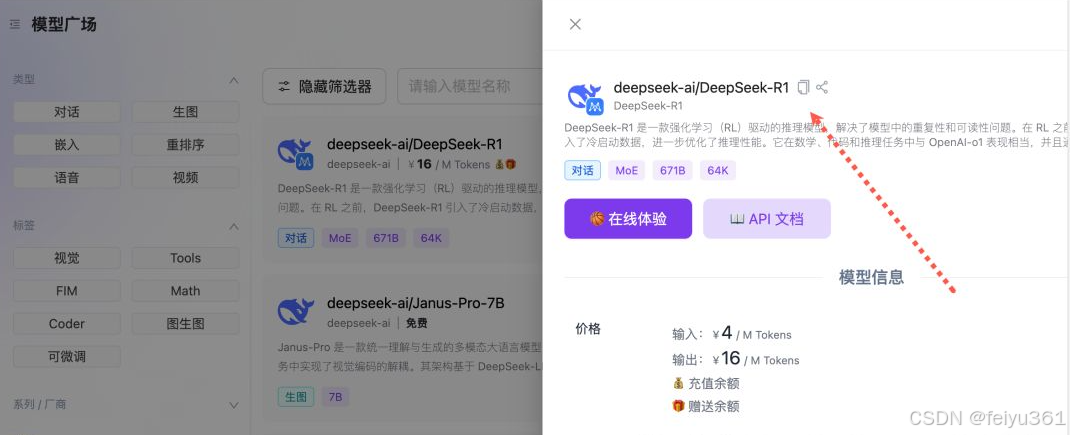
### 在模型广场首页,排在前两位的就是「硅基流动」和「华为云」合作发布的 DeepSeek R1 / V3 模型。
### 在模型服务的硅基流动下方,添加 R1 模型。
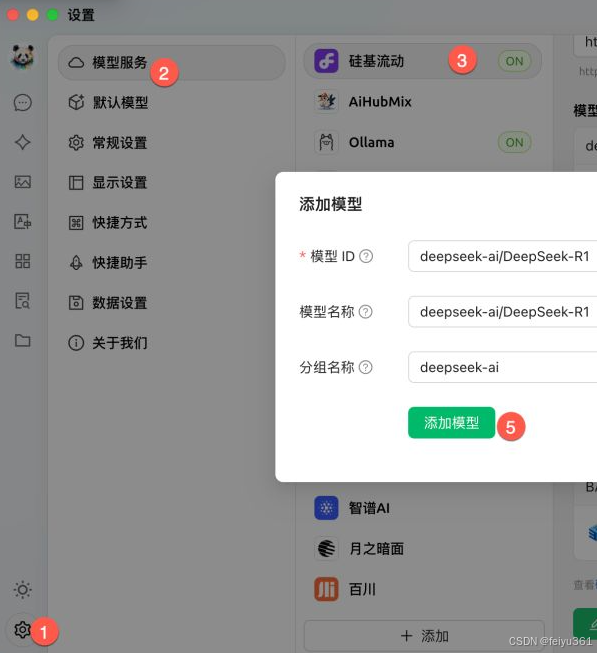
### 记得点击检查,测试下 API 是否可以正常访问。
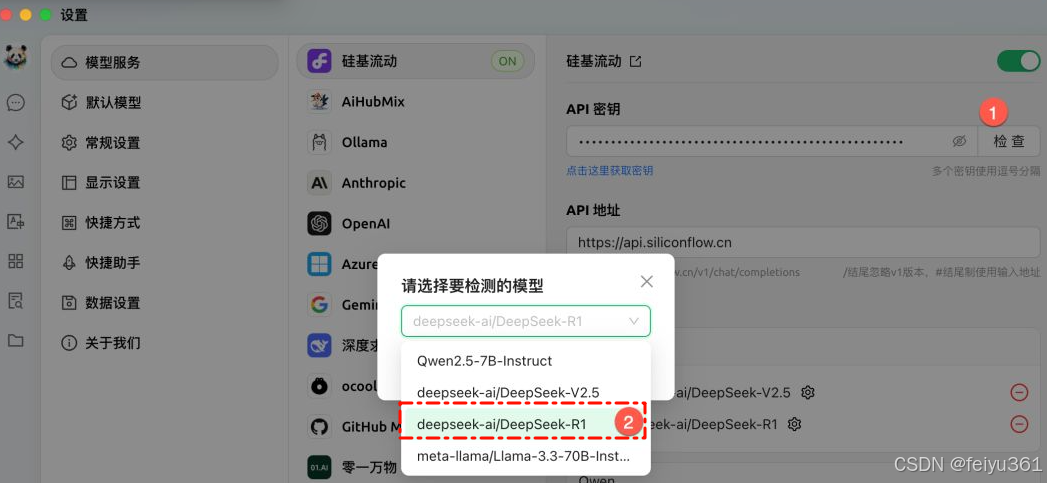
### 现在对话模型有了 R1,还缺少一个嵌入模型
> 嵌入模型的主要作用是将本地文件的内容转换成有意义的数字,存储到向量数据库中。
> 在用户提问时,利用 RAG 技术在数据库中搜索到相似答案,最终回复用户。
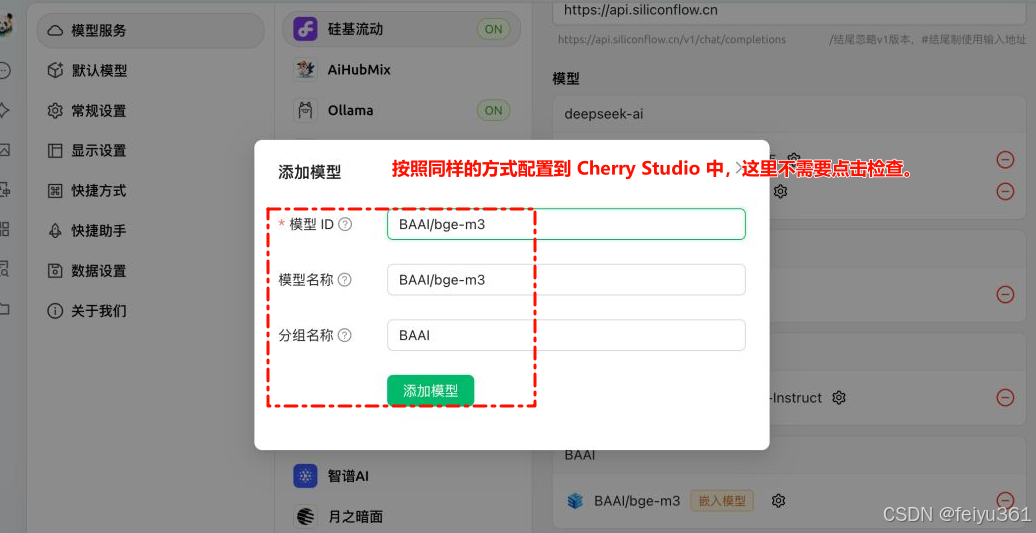
#### 我们再配置一个向量模型:BAAI/bge-m3。如果希望搜索的精准度更高,可以选择 Pro/BAAI/bge-m3。

#### 按照同样的方式配置到 Cherry Studio 中,这里不需要点击检查。
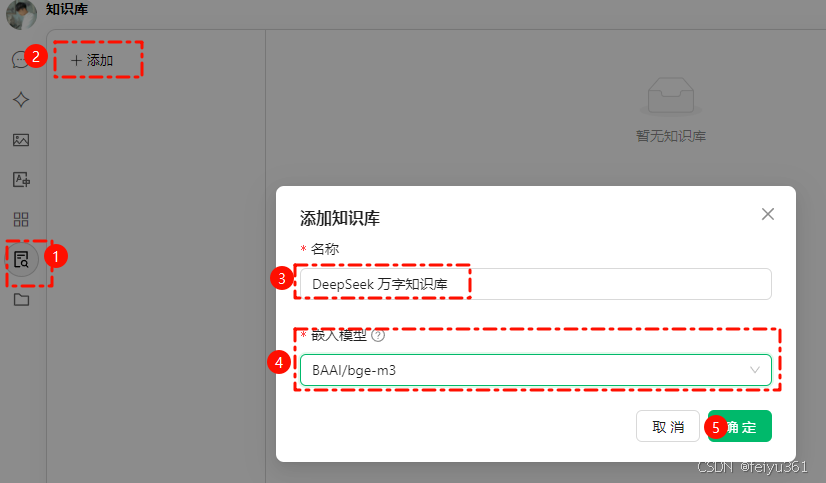
### 在 Cherry Studio 创建知识库,选择刚才配置的嵌入模型,这样就会自动利用对应的模型来向量化数据。
### 上传本地文件进行向量化。
> 注意: 如果本地 PDF 文件是 扫描件、手写件,或者带有复杂的表格 和 数学公式,解析效果会很差,甚至无法解析。如何解决呢?
#### PDF 转结构化文档 的方案来使用
- [doc2x进行注册并上传pdf文件](https://doc2x.noedgeai.com/)
- [使用pdf_to_markdown进行转换](https://www.textin.com/market/detail/pdf_to_markdown)
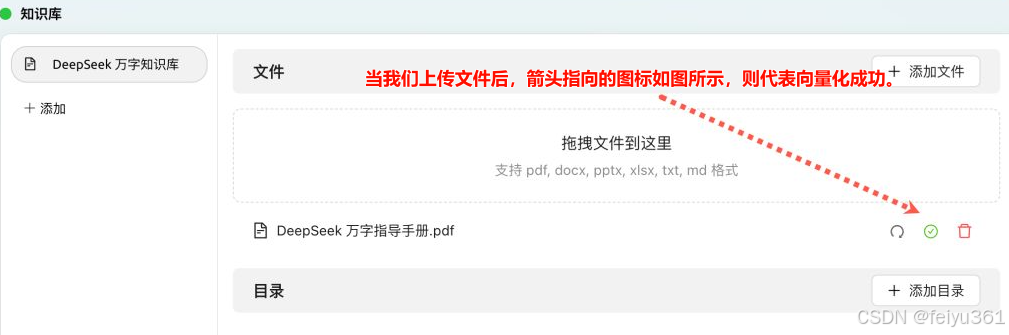
### 当我们上传文件后,箭头指向的图标如图所示,则代表向量化成功。
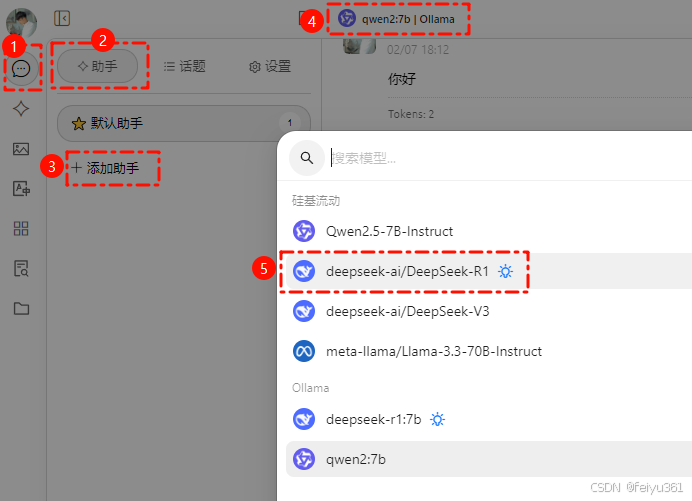
### 开始测试使用,, 开始添加助手,并选择刚配置的 满血 R1 模型
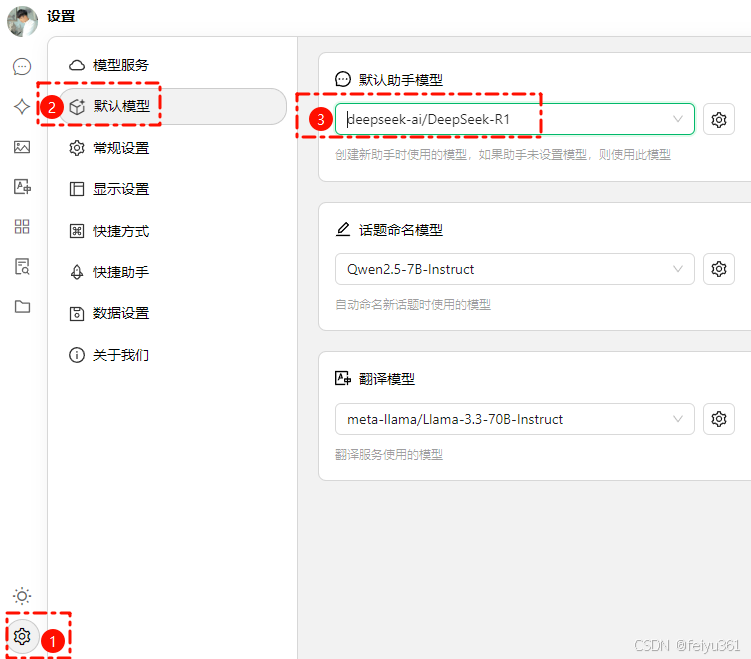
### 如果不想每次在添加助手时选择模型,可以将它设置为 默认模型。
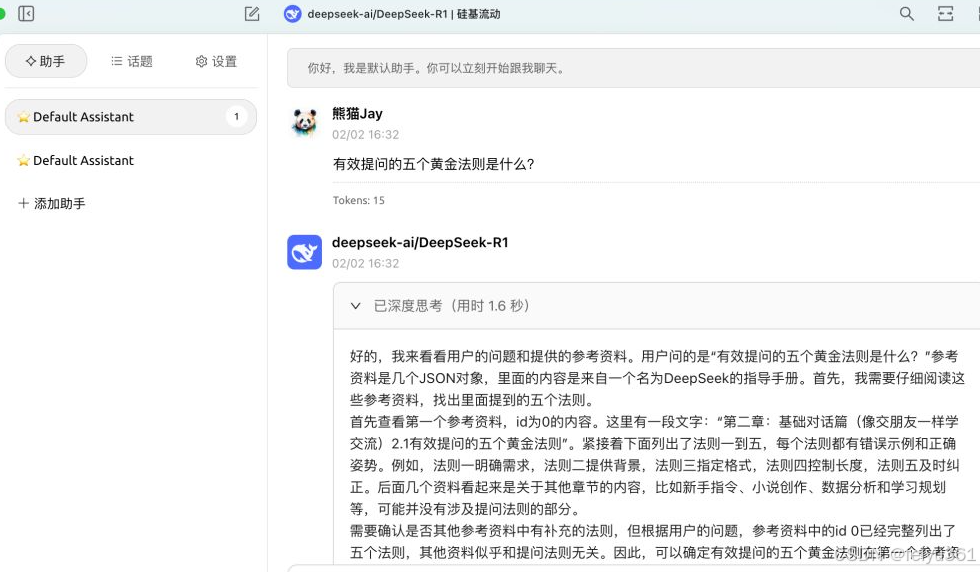
### 我们来测试一下,发现 DeepSeek 已经开始深度思考了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号