跟我一起读postgresql源码(十四)——Executor(查询执行模块之——Join节点(下))
3.HashJoin 节点
postgres=# explain select a.*,b.* from test_dm a join test_dm2 b on a.xxx = b.xxx;
QUERY PLAN
--------------------------------------------------------------------------------
Hash Join (cost=34846.00..305803.23 rows=1000000 width=137)
Hash Cond: ((b.xxx)::text = (a.xxx)::text)
-> Seq Scan on test_dm2 b (cost=0.00..223457.17 rows=10000017 width=69)
-> Hash (cost=22346.00..22346.00 rows=1000000 width=68)
-> Seq Scan on test_dm a (cost=0.00..22346.00 rows=1000000 width=68)
(5 行)
Hashjoin节点实现了Hash连接算法,它能够实现前面说到的六种连接方式。
以下我们以表R(左关系)与表S(右关系)连接为例,说明Hash连接的实现过程。
1)对一个表(例如S)进行Hash时,其块和桶数量的确定和划分方法如下:
①首先对S分块(batch),估算存储S所占用的空间(inner_rel_bytes), Hash所使用的内存空间被定义为 1 兆(hash_table_bytes),则分块的数量 nbatch = ceil(inner_rel_bytes/hash_table_bytes)。
②在内存中,每一个块又被划分为大小为10个元组的桶,因此,个数为nbucket = (hash_table_bytes/tuplesize)/10,其中tuplesize为元组大小的估计值。
③对于一个Hash值为hashvalue的元组,其所属的分块号为(hashvalue/nbucket)%nbatch,其对应的桶号为hashvalue%nbucket。
④在PostgreSQL实现中,为了能够使用位操作(位与和移位)实现取模和取余操作,将nbatch和nbucket取为不小于计算值的2的n次,并使得2^log2_nbuckets = nbucket,则块号的计算方法为(hashvalue >> log2_nbuckets)&(nbatch - 1),桶号计算式为hashvalue&(nbucket - 1)。
2)执行HashJoin的算法:
①顺序获取S中的所有元组,对每一条元组进行Hash,并通过Hash结果获取块号和桶号。对于块号为0的元组,放人内存对应的桶内;否则放入为右关系每个块分别建立的临时文件中。此时,标记当前在内存中的块号curbatch为0。
②从R中获取元组,进行Hash,获取元组块号和桶号。当块号等于当前在内存中的块号时,直接扫描对应的桶,找寻满足条件的元组并进行连接;否则,将其存人为左关系每个块分别建立的临时文件中。执行过程,直到R被扫描完毕。
③从S的块号curbatch + 1对应的临时文件中读取所有存储的元组,将其Hash到相应的桶内,并将curbatch加1。
④从R的块号curbatch对应的临时文件中依次读取所存储的元组,计算其桶号,并扫描桶中S的元组,寻找满足连接条件的元组进行连接。
⑤重复步骤3和4,直到所有的块都被扫描为止。
为了实现上述过程,Hashjoin定义结构如下所示,其中扩展定义了计算左右关系Hash值和Hash值比较的表达式。执行状态节点中存储了各种执行过程中用到的数据结构。和NestLoop节点类似,HashJoinState节点也定义了与NestLoop相同的几个属性。特别需要介绍的是,hj_CurBucketNo用于标记当前放人内存的块号,CurHashValue用于保存当前扫描的左子树元组计算得到的Hash值。此外,hj_CurBucketNo用于标记另一个优化结构对应的桶号,针对于会生成多个块的右关系,当左关系比较大且无序时,PostgreSQL在内存中分配了另一块内存空间,专门用于存储左关系在Hash属性上出现频率较高的Hash值所对应的右关系元组,每个桶对应一个Hash值,这样可以提高连接的效率。至于左关系中哪些Hash值的出现频率较高,可以从pg_statistic系统表中记录的统计信息中获取。这种方式被称为skew方法。
HashJoinState的数据结构
typedef struct HashJoinState
{
JoinState js; /* its first field is NodeTag */
List *hashclauses; // list of ExprState nodes ,original form of the hashjoin condition
List *hj_OuterHashKeys; // list of ExprState nodes ,the outer hash keys in the hashjoin condition
List *hj_InnerHashKeys; // list of ExprState nodes ,the inner hash keys in the hashjoin condition
List *hj_HashOperators; // list of operator OIDs ,the join operators in the hashjoin condition
HashJoinTable hj_HashTable; // hash table for the hashjoin
uint32 hj_CurHashValue; // hash value for current outer tuple
int hj_CurBucketNo; // regular bucket# for current outer tuple
int hj_CurSkewBucketNo; // skew bucket# for current outer tuple
HashJoinTuple hj_CurTuple; // last inner tuple matched to current outer tuple, or NULL if starting search (hj_CurXXX variables are undefined if
// variables are undefined if OuterTupleSlot is empty!)
TupleTableSlot *hj_OuterTupleSlot; // tuple slot for outer tuples
TupleTableSlot *hj_HashTupleSlot; // tuple slot for inner (hashed) tuples
TupleTableSlot *hj_NullOuterTupleSlot; // prepared null tuple for right/full outer joins
TupleTableSlot *hj_NullInnerTupleSlot; // prepared null tuple for left/full outer joins
TupleTableSlot *hj_FirstOuterTupleSlot; // first tuple retrieved from outer plan
int hj_JoinState; // current state of ExecHashJoin state machine
bool hj_MatchedOuter; // true if found a join match for current outer
bool hj_OuterNotEmpty; // true if outer relation known not empty
} HashJoinState;
HashJoin的数据结构:
typedef struct HashJoin
{
Join join;
List *hashclauses;
} HashJoin;
HashJoin是与Hash节点配合使用的,Hashjoin节点的右子节点一定是Hash节点。Hash节点主要完成Hashjoin算法的步骤1以及Hash表的管理。HashJoin节点则负责处理Hash连接算法的其他步骤和功能。
HashJoin的初始化函数ExecInitHashJoin除了做一些基础性的工作外,还要:
-
1.根据需要构造HashJoinState节点的outer join相关的数据结构hj_NullInnerTupleSlot和hj_NullInnerTupleSlot(例如为LEFT JOIN和ANTI JOIN构造hj_NullInnerTupleSlot以满足对于那些找不到可连接T2元组的T1元组);
-
2.初始化hash节点、hashstate节点和存放inner tuple的hj_HashTupleSlot;
-
3.解析HashJoinState中的hashclauses列表,并初始化HashJoinState的其它字段。
值得一提的是inner tuple的hj_HashTupleSlot并不是通过执行ExecProcNode函数从下层节点获取的,HashJoin的inner tuple对应的下层节点是hash节点。hash节点从下层节点一次性整个获取所有的inner tuple,并保存在自有的hashtable中。因此我们通过ExecScanHashBucket函数从该hashtable中获取元组。
hashjoin的执行过程(调用ExecHashJoin)在上面说过了,主要就是一个大循环,在循环里我们:1.构造Hashtable,2.执行HashJoin算法。
下面是hashjoin的执行状态机的状态(前面说到的两个join也用到了状态机模型)。有关状态机的原理学习过编译原理的同学们应该很清楚,这是第一章的内容,小case,洒洒水啦。
/*
* States of the ExecHashJoin state machine
*/
#define HJ_BUILD_HASHTABLE 1
#define HJ_NEED_NEW_OUTER 2
#define HJ_SCAN_BUCKET 3
#define HJ_FILL_OUTER_TUPLE 4
#define HJ_FILL_INNER_TUPLES 5
#define HJ_NEED_NEW_BATCH 6
通过设置状态的处理逻辑和状态间的转移关系,程序在既有的逻辑下按部就班地执行,最后输出我们要的JOINed tuple。
我还是上一张图好了,我也回忆一下过去的学生生涯,画一个编译原理课程上第一章的有限状态机(DFA)模型。
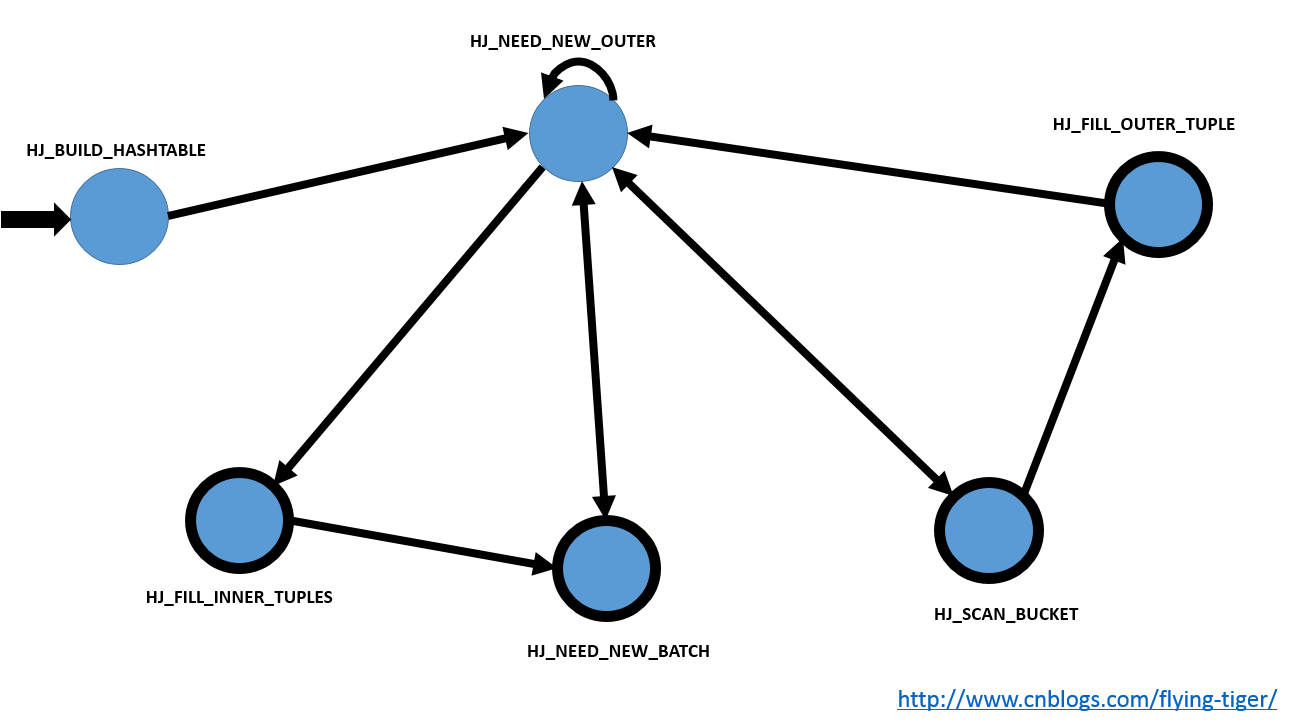
稍微说明下,其中单箭头是指箭头尾巴的状态在一定条件下会转移到箭头状态,双箭头指的是这两个状态可以互相转化,指向自身的箭头是只自身在做一些处理之后继续回到自身状态,此时内部会再次check是否满足转移条件。粗粗的黑圈指的是终结状态,也就是说在这个状态下程序可以结束并且输出JOINed tuple。而且这个DFA应该也是从一个复杂的NFA化简而来的,所以看起来可能会有一点别扭。
-
我们可以看到第一步当然是HJ_BUILD_HASHTABLE节点,我们要为inner tuples构造hashtable呢;
-
有了第一步,即有了inner tuples的hashtable, 这个时候我们自然就需要outer tuples了。所以我们到了HJ_NEED_NEW_OUTER节点。在这个节点我们会去获取outer tuple,如果获取不到,那么我们就要根据情况,或者去HJ_FILL_INNER_TUPLES节点,要么去HJ_NEED_NEW_BATCH节点。反之,如果获取到了outer tuple的话,也并不是就一定万事大吉,万事大吉的话就跳转至HJ_SCAN_BUCKET;不能吃鸡的话,那么自身先做一下处理,再走一波本状态(HJ_NEED_NEW_OUTER);
-
接下来再说HJ_SCAN_BUCKET节点,到这个节点的话,outer tuple都搞定了,那么我们需要inner tuple(第一步只是构建了hashtable,我们还没从里面取数据),没取到?看来没有匹配的,那麻烦来下一个outer tuple吧,我们要去HJ_FILL_OUTER_TUPLE(为什么不去HJ_NEED_NEW_OUTER?)。取到了的话?满足连接条件么?如果你不是ANTI JOIN的话(ANTI JOIN 丢弃inner 和outer匹配的连接),差不多就可以到此结束返回JOINed tuple了。
-
然后是HJ_FILL_OUTER_TUPLE节点,到了这里说明inner 和outer没有匹配上,那么我们肯定要去获取下一个outer tuple了,也就是说,要去HJ_NEED_NEW_OUTER,但是我们要知道,如果我们要是可以返回T1 join NULL这种元组的话(满足left join),也是要返回的,这也是我们需要的结果集。也就是说,我们是一定要去HJ_NEED_NEW_OUTER的,但是如果当前情况可以返回的话,还是先返回,下一次再从这里再来就是。
-
上面说的都是outer,这里就到inner了,这里要说到HJ_FILL_INNER_TUPLES节点了。这里我们要知道如果是右连接或者全连接的话,我们是需要用左边的NULL连接所有的inner的,这里我们就一直获取batch中的inner tuple。直到这个batch用完了,我们要在进入下一个batch,所以最后进入HJ_NEED_NEW_BATCH节点。这个节点不断地获取下一个batch。当我们获取完了。说明这一波刷完了。那么我们进入下一波,又到了HJ_NEED_NEW_OUTER。周而复始。
上面只是说个大致,至于状态之间转化的详细,诸君自己看代码吧(当然了,图中并没有画出出错处理,出错处理这里都是异常结束,异常结束状态节点我就不画了,影响美观。)。
最后,我们做一些清理工作,由于建立了hashtable,所以我们要记得将其销毁。
join节点完~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号