20199105 《网络攻防实践》 综合实践
综合实践期末大作业
课程 : 网络攻防实践
论文: Manipulating Machine Learning: Poisoning Attacks and Countermeasures for Regression Learning
源代码: https://github.com/jagielski/manip-ml
会议: 2018 IEEE Symposium on Security and Privacy(IEEE安全与隐私研讨会)
关键词: 机器学习 线性回归 中毒攻击
一、研究概述
1.1前言
1.1.1会议简介
IEEE安全与隐私研讨会(IEEE Symposium on Security and Privacy)是介绍计算机安全和电子隐私发展的主要论坛,实践论文摘自2018年第39届研讨会“机器学习”板块,如图所示。


1.1.2论文简介
机器学习被广泛的应用于自动化决策,许多机器学习模型需要定期更新,以解释连续的数据,随之也出现了一系列安全漏洞,攻击者可操纵由机器学习算法生成的结果和模型,从而影响决策。
例如,本文主要研究的中毒攻击,可以理解为攻击者通过在训练数据(Training data) 中注入攻击点,影响更新的机器学习模型,操纵预测模型的结果(Prediction),这类攻击已经在蠕虫签名生成、垃圾邮件过滤、Dos攻击检测、手写数字识别、情感分析等应用中实现。
本文针对上述问题,对线性回归模型的中毒攻击及对策进行了系统性研究,一方面站在攻击者的角度,提出了一种对学习过程要求最小知识的快速统计攻击;另一方面,站在防御者的角度,提出了一种防御算法,提供了高鲁棒性和抵御大规模中毒攻击的能力。
1.2 机器学习基础知识
1.2.1监督学习
传统的机器学习分类中通常是:监督学习(Supervised learning) 和无监督学习(Unsupervised learning),还有一种结合监督学习和无监督学习的中间类别,称之为半监督学习(Semi-supervised Learning)。监督学习与无监督学习根区别在于据源标注的完整度,输入数据有标签,则为有监督学习,没标签则为无监督学习。
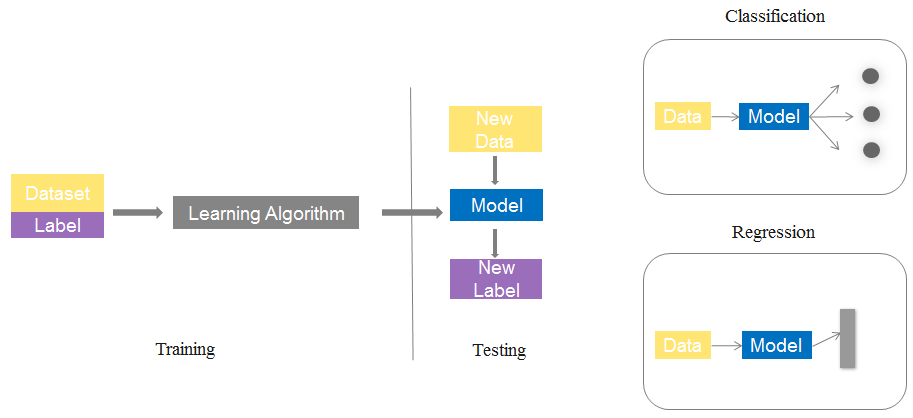
监督学习的过程如下图所示。主要分为训练阶段与测试阶段,通常将数据集分为训练集与测试集,训练集数据经过学习算法生成模型,测试集使用模型进行预测或分类。
1.2.2线性回归
线性回归是回归问题中的一种,线性回归假设目标值与特征之间线性相关,即满足一个多元一次方程。通过构建损失函数,来求解损失函数最小时的参数w和b。通长我们可以表达成如下公式:
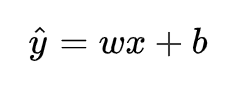
损失函数(loss function)是用来估量模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数 , 通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。
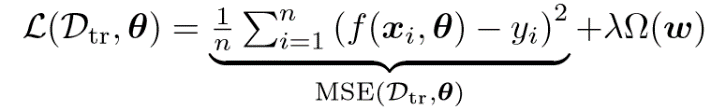
1.2.3 机器学习攻击分类
从攻击目标可分为中毒攻击、规避攻击和隐私攻击三类。
①中毒攻击:在训练时对模型进行完整性攻击,故意影响训练数据集来操纵预测模型的结果。
②规避攻击:在推理时对模型进行完整性攻击,模型训练完之后,在推理阶段影响输入,常用方法是计算对抗性样本,以操纵模型的结果。
③隐私攻击:攻击者的目的通常是恢复一部分训练机器学习模型所用的数据,或者通过观察模型的预测来推断用户的某些敏感信息。
从攻击环境来说,可以分为黑盒攻击,白盒攻击或者灰盒攻击:
-
黑盒攻击:攻击者对攻击的模型的内部结构,训练参数,防御方法(如果加入了防御手段的话)等等一无所知,只能通过输出输出与模型进行交互。
-
白盒攻击:与黑盒模型相反,攻击者对模型一切都可以掌握。目前大多数攻击算法都是白盒攻击。
1.3论文概述
该论文的主要工作有:
- 对线性回归模型的中毒攻击及其对策进行了第一次的系统性研究
- 从现有的中毒攻击分类入手,提出了一个专门针对回归模型的优化框架
- 设计了一种快速统计攻击,对学习过程的知识要求低
- 设计一种新的鲁棒防御算法(TRIM),该算法在很大程度上优于现有的稳健回归方法,具有很强的鲁棒性和恢复能力,且保证收敛性
- 在四个回归模型(OLS、LASSO、岭回归、弹性网络回归)和三个不同领域(医疗保健、贷款、房地产)的数据集上广泛评估我们的攻击和防御
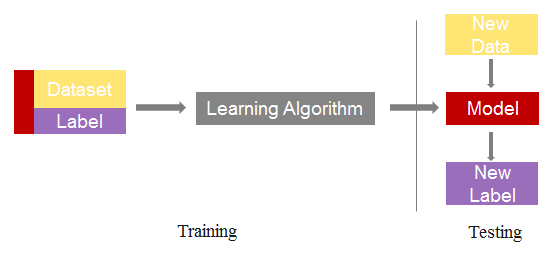
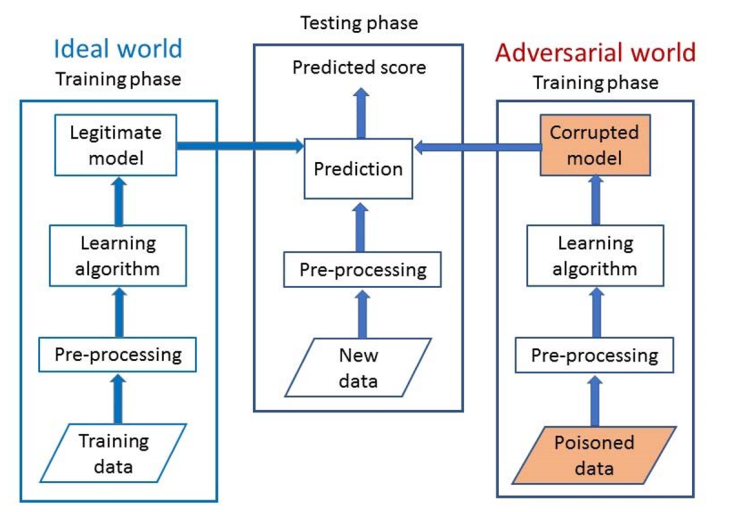
作者针对线性回归模型的中毒攻击过程提出了一个系统模型,主要分为三个部分。
- 理想世界
学习过程包括数据预处理阶段(完成数据清理与归一化),训练阶段,应用学习算法生成回归模型。 - 测试阶段
测试数据在经过数据预处理阶段后,使用回归模型生成数据预测值。 - 对抗世界
攻击者将攻击点注入训练数据,经过数据预处理和训练阶段,应用学习算法生成错误的回归模型,最终影响预测结果。
二、攻击方法论
2.1主要工作
在攻击维度,作者的主要工作有:
设计了一个线性回归中毒攻击的优化框架,通过调整初始化策略、目标函数、优化变量三方面参数,实现对特定数据集与模型的最大化攻击。
提出一种快速统计攻击方法,可以用极小的学习知识训练模型。
2.1.1 线性回归中毒攻击优化框架
在针对线性回归的优化框架中,x表示特征向量,y表示x对应的响应变量,且有 x ∈[0,1],y ∈[0,1] 。初始化策略随机在数据集中选择一组点作为中毒点,通过修改点的响应变量注入攻击,具体分为两种策略:
-
InvFlip策略设置 yc= 1-y
-
BFlip策略设置 yc=round( 1-y)
其中round()函数表示四舍五入计算。目标函数(损失函数)根据是否设置正则项又分为图中两种。
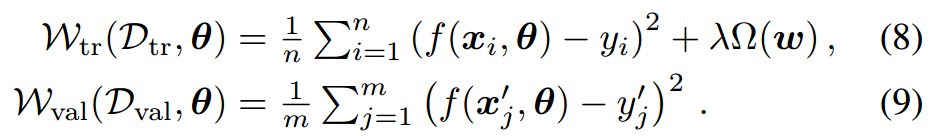
变量优化在以往研究中通常只考虑对特征变量x的优化,作者在此基础上添加了优化(x,y)的可能。
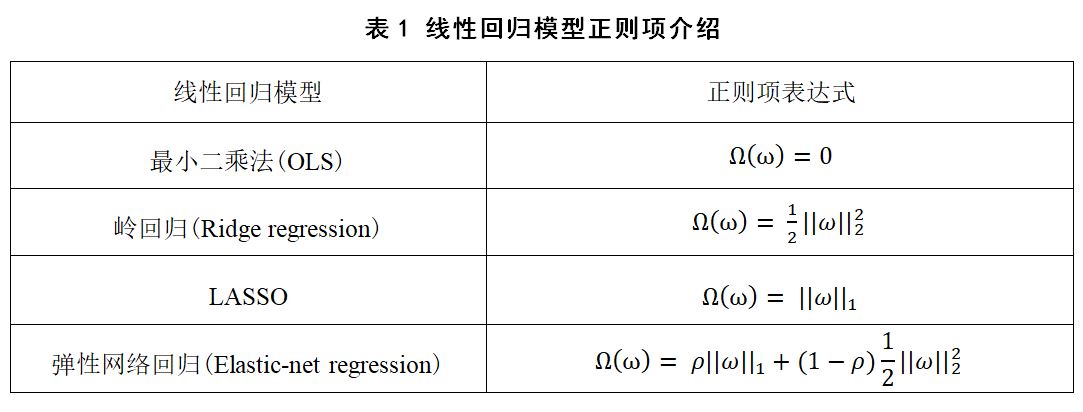
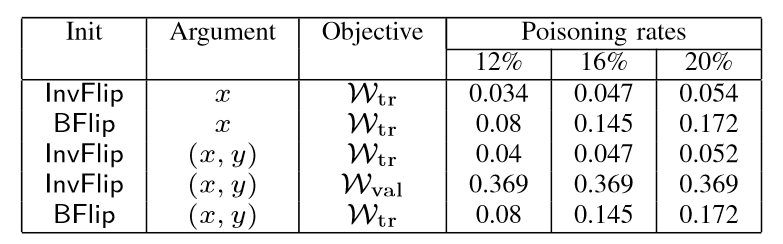
为防止模型过拟合,提高模型的泛化能力,通常会在损失函数的后面添加一个正则化项,即公式(8)中的Ω(ω),以减弱特征对模型的影响。在实验评估中,作者使用了最小二乘法(OLS)、岭回归(Ridge regression)、LASSO、弹性网络回归(Elastic-net regression)四种常用线性回归模型,它们的主要区别就在于正则项的不同,如表1所示。
2.1.2 基于优化的中毒攻击Optp
Optp攻击属于白盒攻击,本质上是一种基于线搜索的梯度上升算法,通过迭代求得最大损失值,实现攻击最大化。
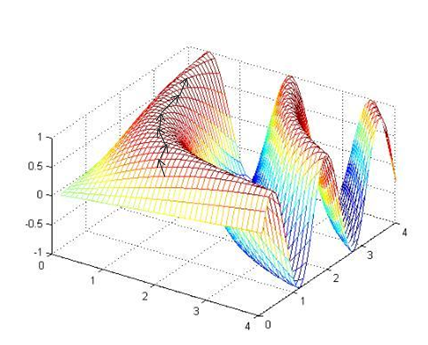
线搜索是一种迭代的求得某个函数的最值的方法,对于每次迭代,线搜索会计算得到搜索的方向,用pk表示,以及沿这个方向移动的步长αk。而梯度上升的原理是:沿梯度上升方向求解极大值。首先,随机选择一个参数组合(θ1, θ2,…,θn),计算损失函数,然后寻找下一个能让损失函数值下降最多的参数组合,变换方向。重复上述过程直到得到一个局部最小值(local minimum),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值,如下图所示。
中毒攻击的算法如图所示。其中 xc 表示攻击点的特征向量,yc 表示响应变量,ω 表示损失值。

2.1.2 基于统计的中毒攻击StatP
作者设计了一种快速统计攻击,通过产生与训练数据分布相似的中毒点注入攻击。在StatP中,我们简单地从一个多变量正态分布中采样,并从训练数据中估计出均值和协方差。生成的这些点将特征值设置在拐角周围,选择响应变量在边界处的值(0或1),使损失最大化。StatP攻击只对模型进行黑盒攻击,它不需要知道具体的回归算法、参数和训练集。
在概率论和统计学中,协方差用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。期望值分别为E(X)= μ与 E(Y)=ν 的两个实数随机变量X与Y之间的协方差定义为:
cov(X,Y) =E[(X-E(X))(Y-E(Y))]
其中,E是期望值。
2.1.3 BGD基线中毒攻击
作者在实验评估部分引用了第32届机器学习国际会议(ICML 2015)中的《Is Feature Selection Secure against Training Data Poisoning?》,该论文提出了一种基线中毒攻击算法,算法原理与本文基于优化的中毒攻击类似,可以将OptP理解在BGD攻击基础上结合了作者设计的优化框架后的新的攻击。换言之,BGD攻击在作者的优化框架中使用了InvFlip初始化策略,以特征向量x为优化变量,损失函数为考虑正则项的ωtr.
三、防御算法
3.1主要工作
在防御维度,作者的主要工作是提出了一个具有高鲁棒性和抵御大规模中毒攻击能力的TRIM防御算法。
3.2已有防御方案
-
噪声弹性回归算法:识别和去除数据集中的离群点。具体方法为随机选择样本子集,将模型拟合到样本时,设置误差阈值,高于阈值则为离群点。显然,这种回归算法对考虑到数据分布的攻击点不具有鲁棒性。
-
逆向弹性回归算法:假设特征集矩阵满足XTX = I,数据具有亚高斯分布;假设特征矩阵具有低秩,并且可以投射到低维空间。这些方法都具有可证明的鲁棒性保证,但在实际应用中往往不能满足它们所依赖的假设条件。
3.3 TRIM防御算法
作者针对线性回归的中毒攻击问题提出了TRIM防御算法。在理想情况下,若某数据集已遭受中毒攻击,我们想要识别出所有p个中毒点,然后基于剩余的n个合法点来训练回归模型。但是,合法的训练数据的真实分布是明显未知的,因此很难准确地分离出合法的攻击点和攻击点。为了缓解这种情况,作者提出的防御方法尝试识别一组相对于回归模型具有最低残差的训练点(这些点可能也包括攻击点,但只包括那些“接近”合法点并且不会对模型造成太大毒害的训练点)。具体算法如下图。

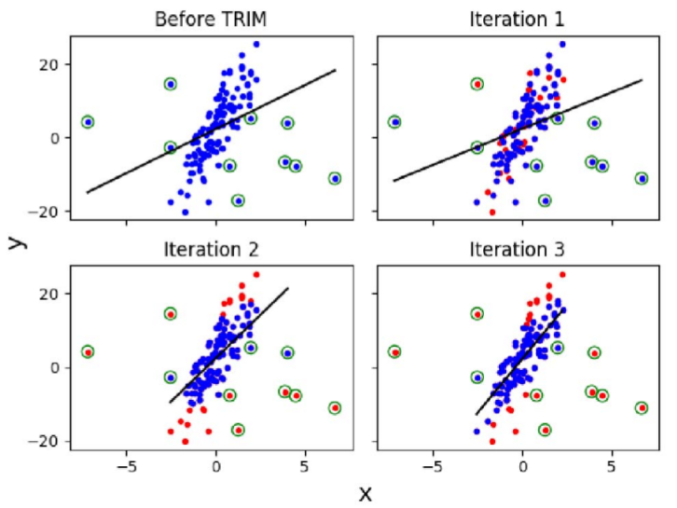
这里通过一实例阐述TRIM防御算法的原理。在下方图Before TRIM中,初始中毒数据以画圈显示。Iteration 1图以红色显示了从优化目标中删除的初始随机选择的点。在接下来的两个迭代中(Iteration 2和Iteration 3),对高残差点集进行了细化,红色点为删除的点,模型变得更加健壮。
四、实验与分析
4.1 数据集介绍
作者在实验中使用了三个公开的线性回归数据集,分别涉及医疗保健、贷款和房地产应用领域。(注:作者并没对数据集来源做任何介绍)
-
医疗保健数据集。该数据集包括5700例患者,其目标是使用人口统计学信息、华法林使用指示、个体VKORC1和CY2C9基因型数据以及使用受相关VKORC1和CYP2C9多态性影响的其他药物来预测抗凝药物华法林的剂量。该数据集具有67个特征,经过编码并进行数值规格化包含167个特征。
-
贷款数据集包含有关借贷俱乐部对等贷款平台贷款的信息。预测变量描述贷款属性,包括贷款总额、利率和本金偿付额等信息,以及借款人的信息,如信用额度的数量和居住地。响应变量是贷款的利率。该数据集具有75个特征,经过编码并进行数值规格化包含89个特征。
-
房地产数据集用于预测房屋销售价格,作为预测变量的函数,如面积、房间数量和位置,该数据集具有82个特征,经过编码并进行数值规格化包含275个特征。
在实验评估中,作者使用标准交叉验证方法划分数据,1/3作为训练集、1/3作为测试集、1/3作为验证集。攻击与防御算法的评估指标有均方误差MSE与中毒攻击运行时间。其中均方误差MSE在数理统计中的定义是指参数估计值与参数真值之差平方的期望值,公式如下。MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。
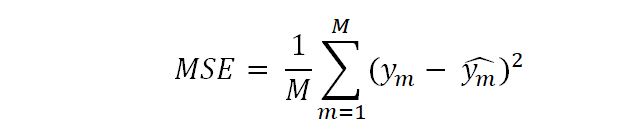
在实验评估中,实验结果取5次运行的平均值,在中毒攻击中中毒率在4%-20%,间隔为4%。
4.2 评估优化框架
4.2.1 问题1:哪种优化策略对中毒回归最有效?
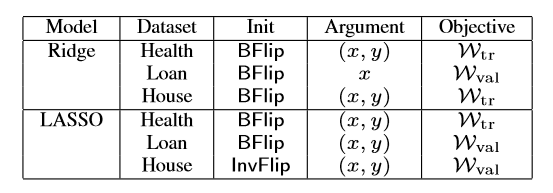
作者设计的优化框架针对不同的模型、不同的数据集具有不同的优化策略。如之前介绍的,优化框架分为初始化策略、损失函数和变量优化三个部分,作者尝试了所有模型与数据集搭配的可能性,并找到了最佳优化攻击。图9展示了岭回归模型和LASSO模型与三个数据集组合下的最佳优化策略。
以LASSO为例,下图分别展示了LASSO模型在贷款数据集和房地产数据集中不同优化策略的中毒攻击,中毒率分别指设置12%、16%、20%,实验结果为MSE值。在第二张图中对比前两行数据可以看出,BFlip比InvFlip策略的攻击明显有效性高,最高MSE可达3.18倍。
第二张图中第一行数据相当于使用BGD攻击,可以发现,任何其他使用BFlip初始化策略或以(x,y)作为优化变量的组合评估结果均好于BGD攻击的结果。(论文原文作者说BGD攻击结果均好于其他优化策略,我认为这里他写反了,因为在攻击实验评估中,MSE值越大表示攻击效果越好)。
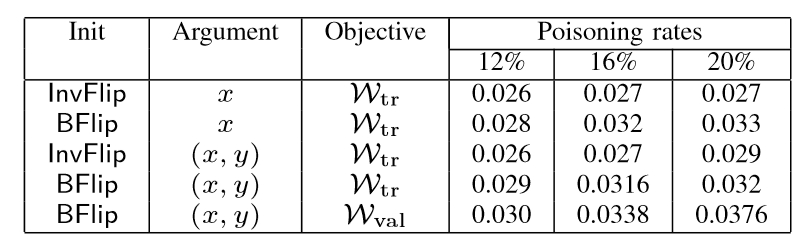
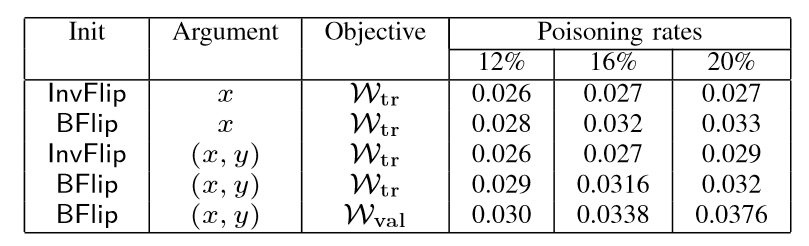
根据实验结果评估,初始化策略BFlip攻击效果优于InvFlip,优化变量(x,y)攻击效果优于只优化特征向量x,不考虑正则项的损失函数ωval攻击效果要优于ωtr.由此可见三个因素对攻击的优化均有影响。但是,对于非线性的数据集,例如实验中的贷款数据集,原始的MSE值就很高了,采用作者提出的攻击训练模型后,反而会降低MSE,未起到攻击效果,这可是由于原始数据在特征空间中已经更均匀、非线性地分布,攻击点的注入失效。
4.3 评估OptP与StatP攻击
4.3.1 问题2:优化和统计攻击如何在有效性和性能方面做比较?
通过分析下图的实验结果可知,基于优化的攻击(BGD和OptP)优于基于统计的攻击StatP的有效性。这对于我们来说并不奇怪,因为StatP使用更少的关于训练过程的信息来确定攻击点。有趣的是,实验中有一个案例(LASSO回归模型贷款数据集),其中StatP和OptP执行结果类似,如图(b)。这些情况表明,当攻击者对学习系统的知识有限时,StatP是一种合理的攻击。
优化攻击的运行时间与收敛所需的迭代次数成正比。在最高维度的数据集——房价数据集中,实验观察OptP攻击使用岭回归模型约337秒完成,使用LASSO模型408秒完成。在贷款数据集中,OptP攻击使用LASSO模型平均106秒完成攻击注入。正如预期的那样,统计攻击非常快。因此,作者提出的攻击在有效性和运行时间之间表现出明显的折衷,OptP攻击比StatP攻击更有效,代价是更高的计算开销。
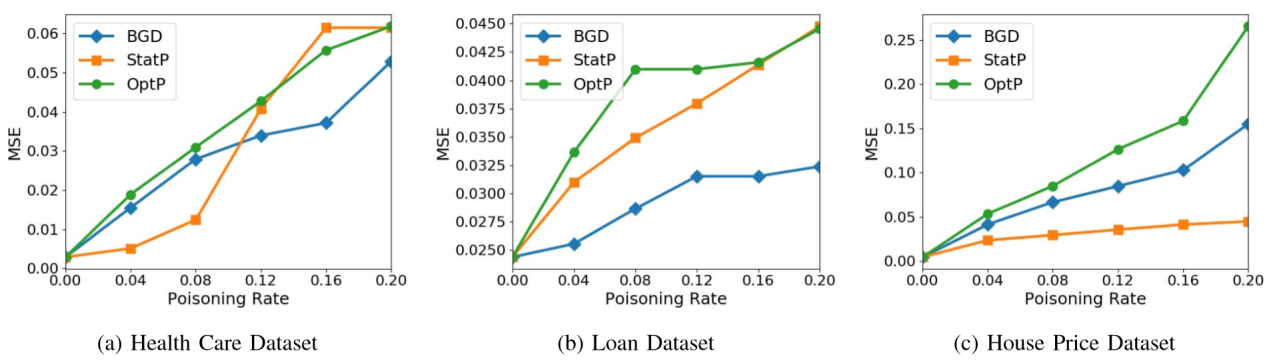
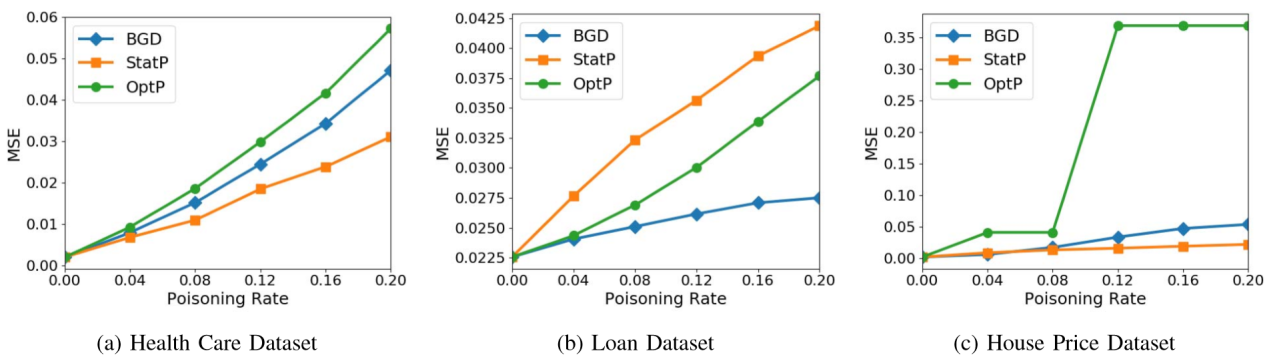
其中第一排三个图表表示岭回归模型在三个数据集上的实验结果,第二排三个图表表示LASSO回归模型在三个数据集上的实验结果。实验采用了BGD攻击作为对比对象,以评估作者提出的OptP和StatP攻击。
4.3.2 问题3:在实际应用中,中毒攻击的危害是什么?
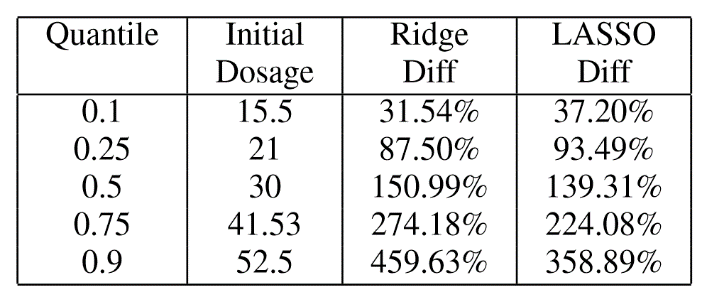
在医疗保健应用中,其目标是预测抗凝药物华法林的药物剂量。如图所示,我们首先显示由原始回归模型预测的药物剂量(Initial Dosage),然后在OptP中毒攻击后计算规定剂量的绝对差异。我们发现所有线性回归模型均中毒,在LASSO模型中,75%的患者剂量改变了93.49%,一半的患者剂量改变了139.31%。对于10%的患者,MSE的增加是破坏性的,差异达到最大359%。这些结果基于20%的中毒率,但实验结果表明,在较小的中毒率下,这种攻击也是有效的。例如,在8%的中毒率中,半数患者的剂量变化为75.06%。因此,结果证明了我们新的中毒攻击的有效性,它对大多数患者的剂量产生了显著的改变。
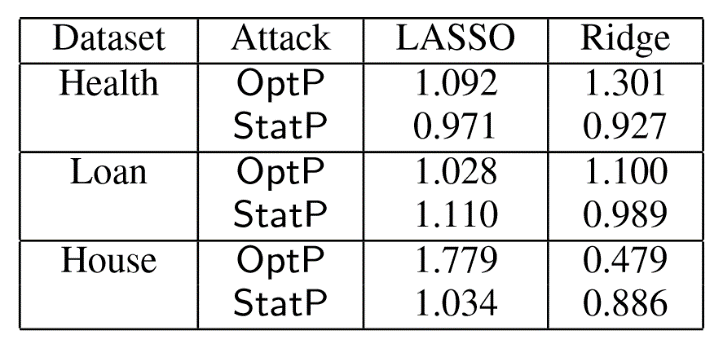
4.3.3 问题4:攻击可迁移性是什么?
通过计算一个模型生成的对抗样本能被另一个模型正确分类或预测的百分比,来衡量攻击的迁移性,百分比即准确率,越低越好。在本论文中,作者使用一个替代训练集来生成中毒样本,然后与目标模型进行测试,成为迁移攻击。使用迁移攻击与原始攻击MSE的比率作为评估指标。若>1,表示迁移攻击优于原始攻击;若<1,表示原始攻击优于迁移攻击。迁移攻击由于原始攻击则表示攻击的迁移性好。
4.4 评估TRIM防御算法
4.4.1 现有防御算法 —— Huber Loss
Huber Loss 是一个用于回归问题的带参损失函数, 优点是能增强平方误差损失函数(MSE, mean square error)对离群点的鲁棒性。当预测偏差小于δ时,它采用平方误差,当预测偏差大于δ时,采用的线性误差,公式如下。相比于最小二乘的线性回归,HuberLoss降低了对离群点的惩罚程度,所以HuberLoss是一种常用的鲁棒的回归损失函数。
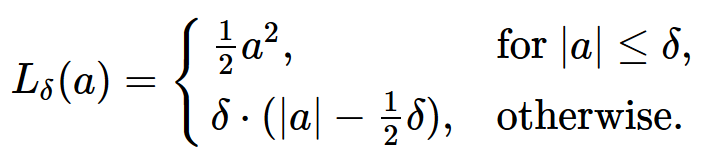
4.4.2 现有防御算法 —— RANSAC
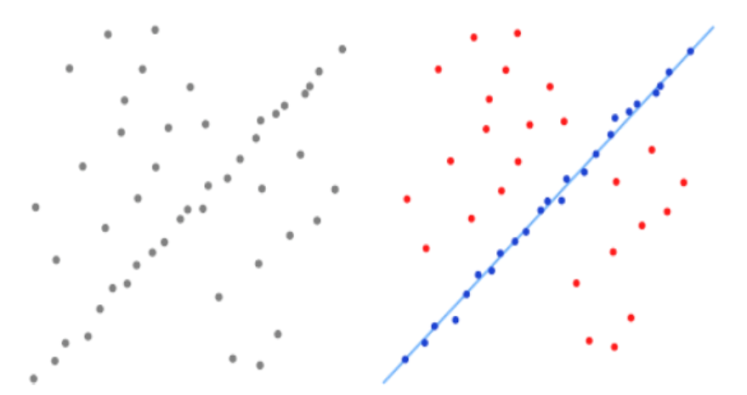
Random Sample Consensus在数据集的随机样本上建立模型,通过迭代估计模型参数,并计算该模型的离群点的数量。如果有太多的离群点,则模型无效,在不同的随机数据集样本上计算新的模型。
以下图为例,首先我们先从左图中灰色点中随机选取一部分为初始值作为初始数据集。用初始数据集拟合一个模型,此模型适应于该数据集。用该模型去测试所有的其它数据,如果某个点适用于估计的模型,认为它也是没中毒的点,将其扩充到数据集。如果有足够多的点加入数据集,那么估计的模型就足够合理,如右图蓝色点,红色点为不适用模型的可疑中毒点。最后,用最终得到的数据集去重新估计模型。若是适用于模型的点过少,则放弃模型,重新随机选择初始数据集。
4.4.3 现有防御算法 —— RONI
RONI (Negative Impact Reject)是在垃圾邮件过滤器的背景下提出的,它试图通过观察带有和不带有每个点的训练模型的性能来识别异常值。如果在采样的验证集(它本身可能包含异常值)上性能下降太多,则将该点标识为异常值,不包含在模型中。作者将验证集的大小设置为50,从5次实验中选择平均最好的点.
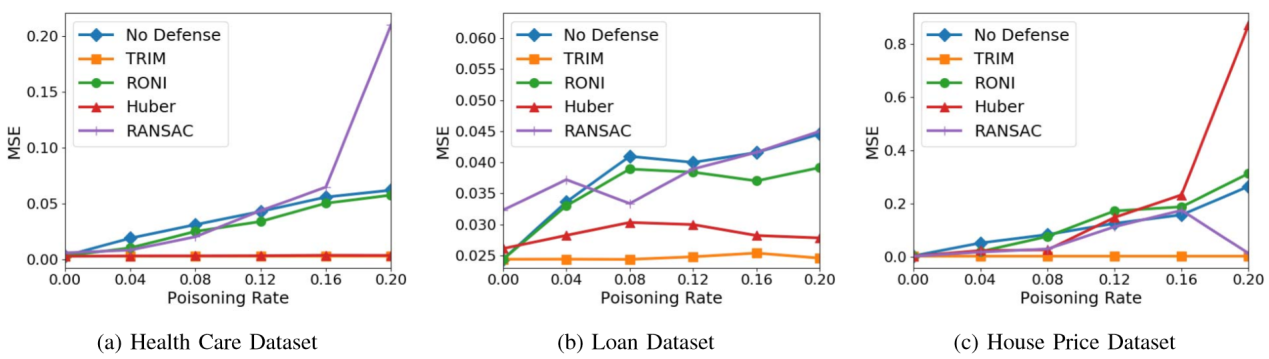
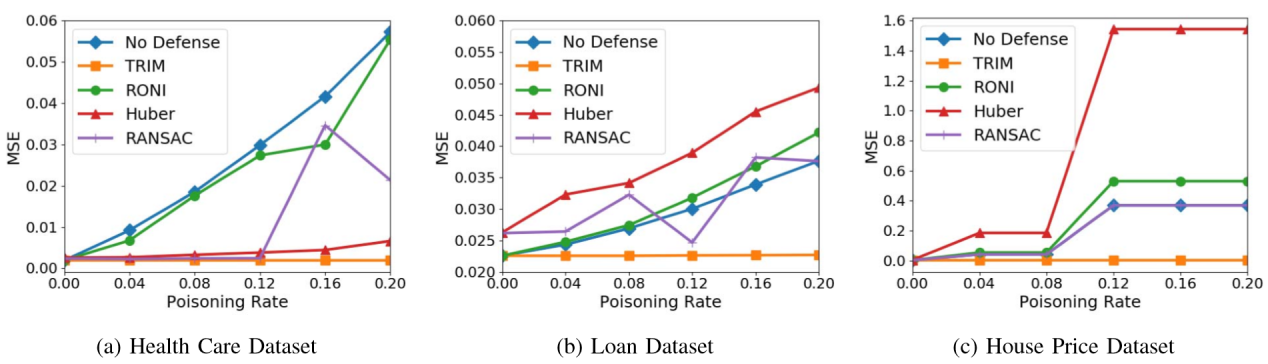
4.4.4 实验结果分析
如下图所示,现有防御技术(胡贝尔回归、RANSAC和RONI)在预防作者所提出的攻击方面并不是一贯有效的。例如,Huber回归算法不仅未起到防御作用,在岭回归模型与房地产数据集实验中,还使MSE 增加了3.28倍。RONI算法也比未防御模型的MSE增加了 18.11%。RANSAC算法能够减少MSE,但它仍然比原始模型高4.66倍。这种表现不佳的原因是鲁棒统计方法被设计为去除或减少数据中离群点的影响,而RONI只能识别对训练模型具有高影响的离群值。作者的攻击产生与训练数据类似的分布点,使得以前的防御无效。
4.5 代码复现
作者在Github中给出了完整的数据集和代码,但是没有任何文件说明,给代码复现带来了一定困难。论文代码使用了python编程语言,因此我使用了Pycharm2019版并使用anconda python环境,其中包含了很多package,十分便捷。代码设计的package并不多,主要有numpy、matplotlib、argparse等,因此环境搭建配置比较顺利。但在复现过程中,我仍遇到了一些问题。
问题一:部分参数未定义或定义错误?
解决方法:单步调试找到匹配的参数,加以修改。例如这段代码中的self.trnx未定义,通过观察代码发现,应添加self.trnx=x

问题二:终端输入参数运行,文件间函数引用报错?
解决方法:作者很善良的使用python的命令行解析模块argparse,可以在终端直接输入参数设置一运行使用pycharm运行文件,在edit configurations中也可设置参数。

问题三:代码没有任何文件说明,注释也很少?
解决方法:全靠猜!
代码运行格式:
代码运行结果:
5 总结
5.1 研究总结
总体来说,作者在本文中对线性回归模型的中毒攻击及其对策进行了第一次系统研究;提出了一个针对中毒攻击和快速统计攻击的新优化框架,该框架考虑了初始化策略、算是函数和变量优化三个方面;作者还设计了一种新的鲁棒防御算法TRIM,该算法在很大程度上优于现有的回归防御方法。
作者在医疗保健,贷款和房地产领域的三个数据集上广泛评估提出的攻击和防御算法,在案例研究医疗保健应用中证明了中毒攻击的真实含义。作者终于相信,作者的工作将激发未来的研究,以开发更安全的中毒攻击学习算法。
5.2 研究方向
在机器学习安全社区中,蠕虫签名生成、垃圾邮件过滤、情感分析等已经证明了实际的中毒攻击,随着更多的应用和社会需求在很大程度上依赖于机器学习的自动化决策,中毒攻击带来的潜在风险与漏洞会日益严重。例如,阿里曾对外分享过一个案例,阿里的有些端口每天都会有很多爬虫,大量低级爬虫会被模式识别并及时消灭,但这些低级爬虫会影响模型识别特征,从而使少数的高级爬虫无法被模式识别,以达到攻击者目标。另一个案例是问答机器人(如微软小冰),它们通过学习庞大语料库来模拟人与人直接的对话,通过对话不断更新语料库。攻击者可以通过大量“恶意”对话影响语料库,实现机器人说脏话或是敏感言论的目标。
目前针对中毒攻击的研究方向主要在深度学习领域,例如图片篡改等,研究内容也多以“分类”为主,对监督学习方法和回归问题的中毒攻击研究不多。作者第一次系统地研究了线性回归的中毒攻击问题,本论文主要针对的是一元线性回归模型,下一步可以考虑攻击与预防方法是否同样适用于多元线性回归问题。并且线性回归是许多更先进学习方法(如SVM、逻辑回归)的基础,未来可以在作者的研究工作上,将其针对中毒攻击及其预防的方法推广和扩展到更多类别的监督学习方法中。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号