第一次个人编程作业
第一次个人编程作业
一、作业提交
代码Github链接
二、PSP表格

总体来说在开发和需求分析部分的时间占比较多
一开始选择的是gensim里的TfidfModel模型,但使用情况与作业不符合,不是一对一分析。调试了半天的时间没写出结果,最后取巧加入一个空文本,可以得到结果,但每个文本的相似度都高的离谱。最后放弃重来,使用jieba库里的extract_tags函数生成关键词-词频字典,再使用余弦向量法计算相似度,效果是不错的。
而其实在进行软工实践时,找资料、搞其他花里胡哨 专业人士该做的事情(比如写博客等)的时间占比是非常高的。
三、计算模块接口的设计与实现
1.流程图:
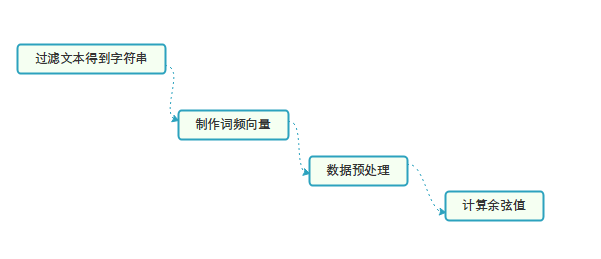
-
使用jieba将传入的文本字符串分割,并根据词频和关键词数产生关键词-词频字典。使用jieba.analyse.extract_tags函数
-
分别获取两个文本的词频向量,并整合,使两个向量的元素对应的关键词相同。
-
对特征值进行预处理:数据中每个数值减去最小值,除以极差。
-
计算向量的余弦相似度。
2.代码组织(函数关系):
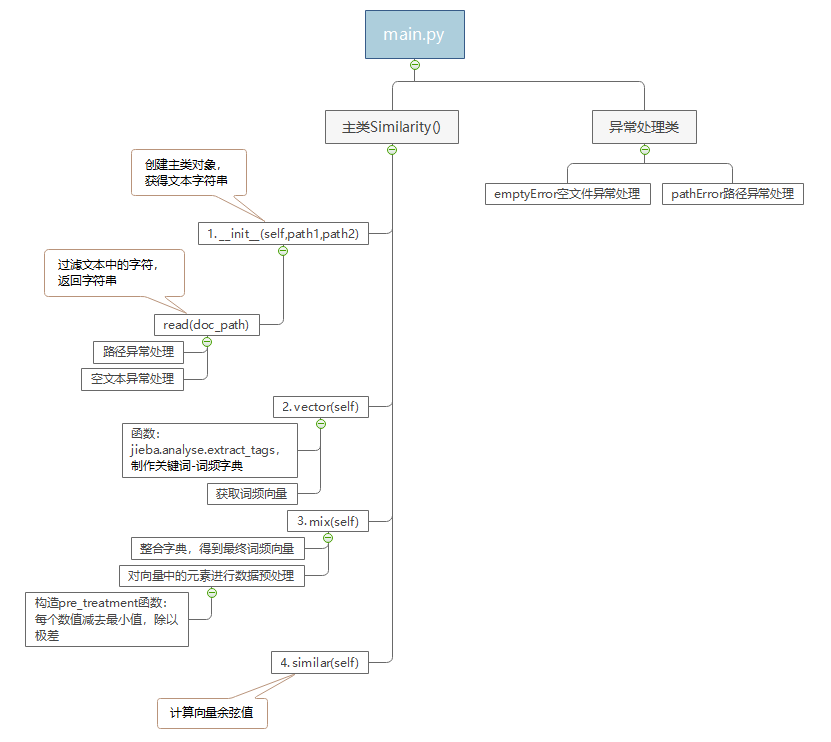
两个关键函数:
# 制作 关键词-词频 字典,获取词频向量
def vector(self):
self.vdict1 = {}
self.vdict2 = {}
# 参数含义:待提取文本,关键词数量(按重要性降序),是否同时返回权重
# 返回值:关键词 词频
top_keywords1 = jieba.analyse.extract_tags(self.str1, topK=1200, withWeight=True)
top_keywords2 = jieba.analyse.extract_tags(self.str2, topK=1200, withWeight=True)
for k, v in top_keywords1:
# print(k,v)
self.vdict1[k] = v
# 获取词频向量
for k, v in top_keywords2:
# print(k,v)
self.vdict2[k] = v
# 整合关键词,数据预处理
def mix(self):
# 整合两个字典
for key in self.vdict1:
self.vdict2[key] = self.vdict2.get(key, 0)
# 若vdict2的值存在,则返回dict[key],不存在则返回0;
for key in self.vdict2:
self.vdict1[key] = self.vdict1.get(key, 0)
# vdict1和vdict2中分别包含文本1和2的关键词及其特征值
def pre_treatment(vdict):
# 对特征值进行预处理:数据中每个数值减去最小值,除以极差
min_ = min(vdict.values())# 返回字典中最小值
max_ = max(vdict.values())# 返回最大值
mid_ = max_ - min_# 极差
for key in vdict:
vdict[key] = (vdict[key] - min_) / mid_
return vdict
3.算法核心思想(简单叙述):
将文本制作成向量例如v[0,10,25,10,1,2,5],v[0]代表下标为0所指的关键词的词频。
通过计算两个向量的余弦值,可以表示两个向量的夹角。余弦值越大,夹角越小,说明重合度越高。
而问题是如何选取关键词制作词频向量,词频应该怎么处理更为合理。
因此,
1)使用jieba库中的jieba.analyse.extract_tags函数提取关键词和词频。(此处有设计TF-IDF算法思想)
2)使用数值减最小值除以极差的方式进行词频预处理。
整个计算模块的处理整理为Similarity类
四、性能分析
1.性能分析图
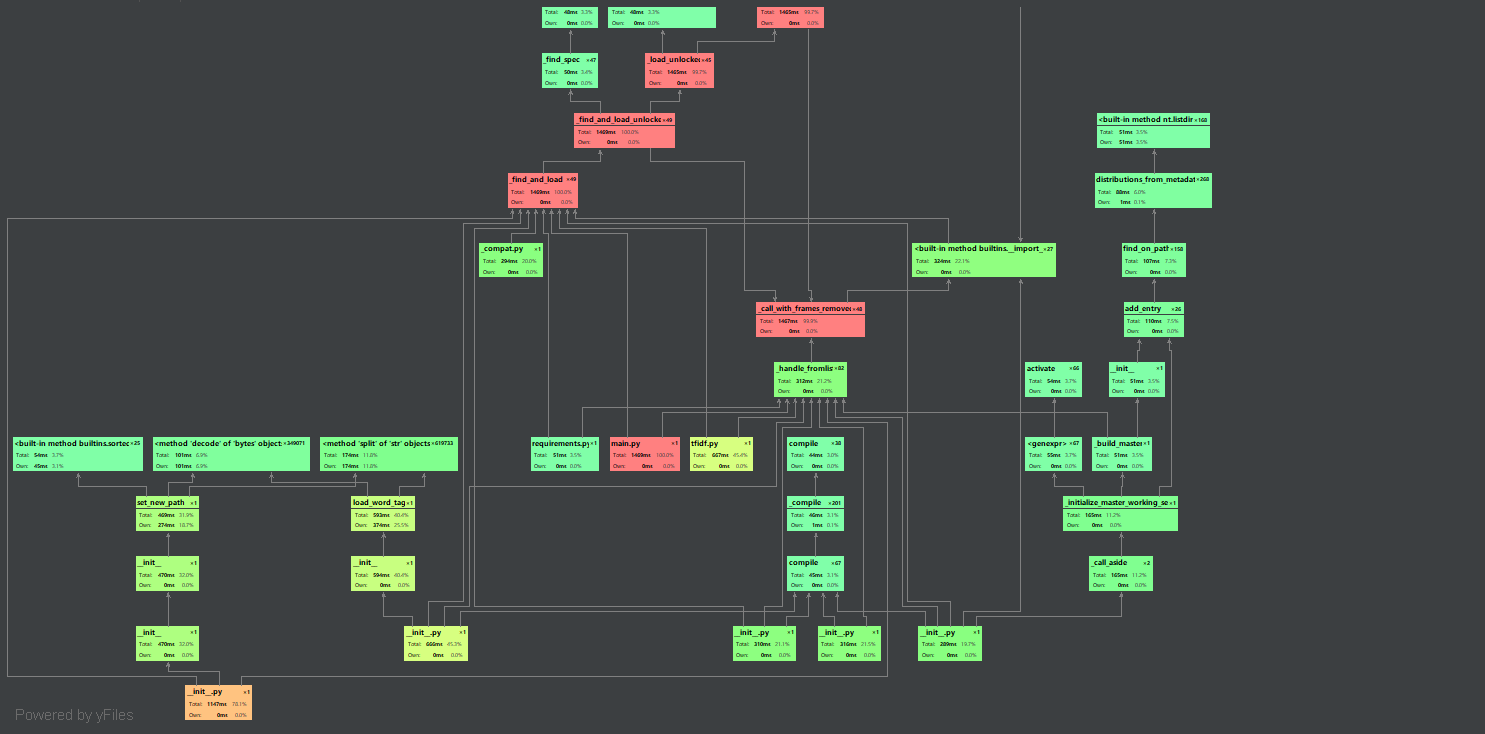
总耗时1.5s左右,性能还可以
2.各函数消耗时间:
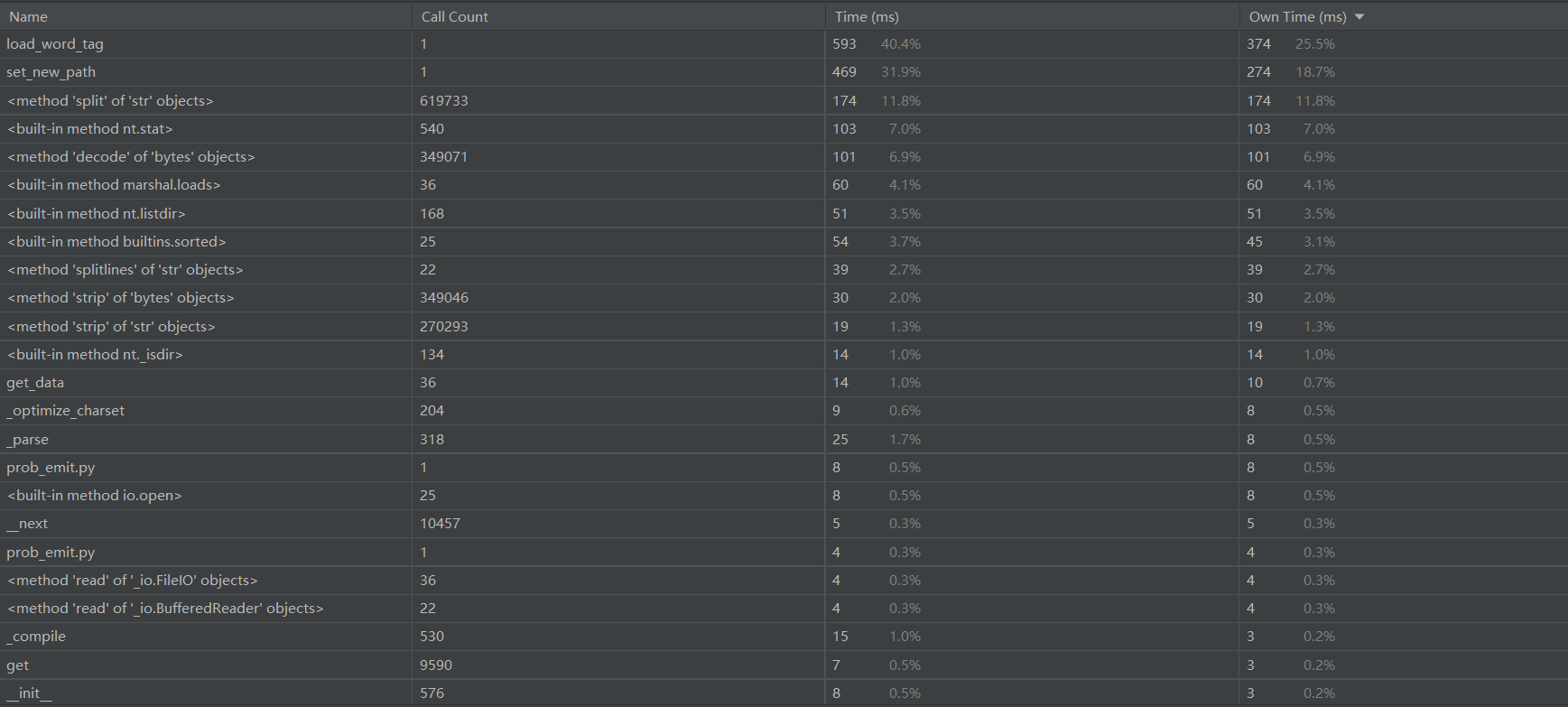
Load_word_tag和set_new_path 函数是消耗最多的两个函数
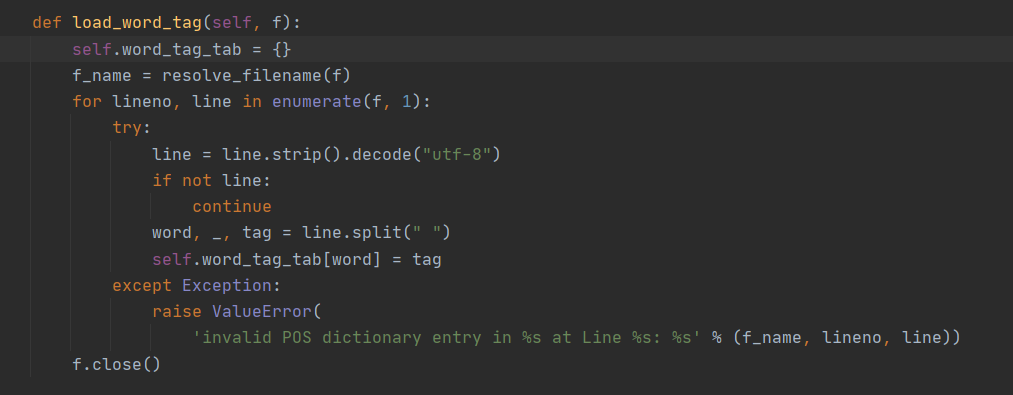
Load_word_tag加载分词情况:
set_new_path与计算TFIDF值有关:
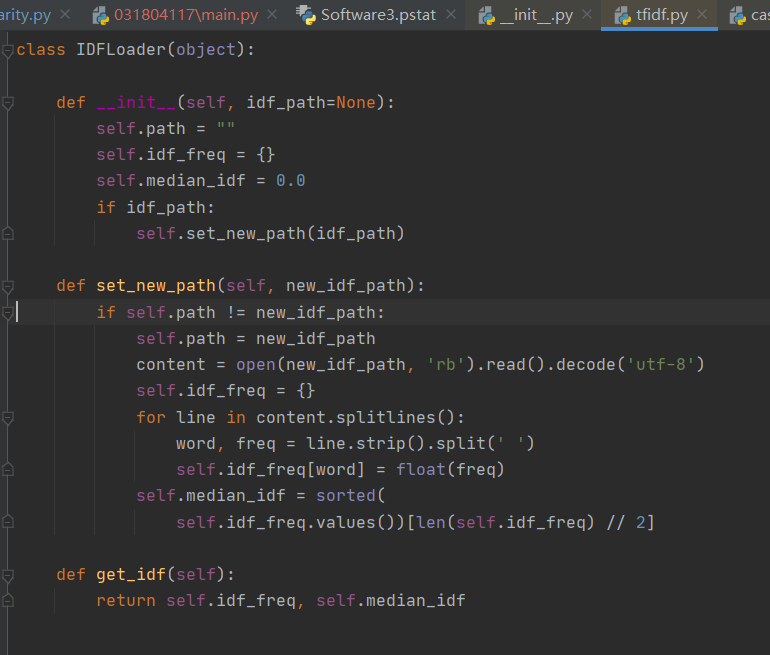
两个函数的消耗是为了得到关键词字典,必不可少。而其他可改进的地方暂时也想不到了
性能分析也到此结束。
五、单元测试
单元测试这块也调试了很久。主要是异常处理模块的问题。
1.单元测试部分代码:
class TestSimilarity(unittest.TestCase):
def setUp(self):
self.path1 = "./orig.txt"
def tearDown(self):
print("over!")
1.测试函数中把每一个单元的path1定义为原文本,其他每个单元给出一个文本路径进行测试。
2.共测试了12组
其中作业给出的测试样例共10组,再加上异常测试2组
整体调试情况:
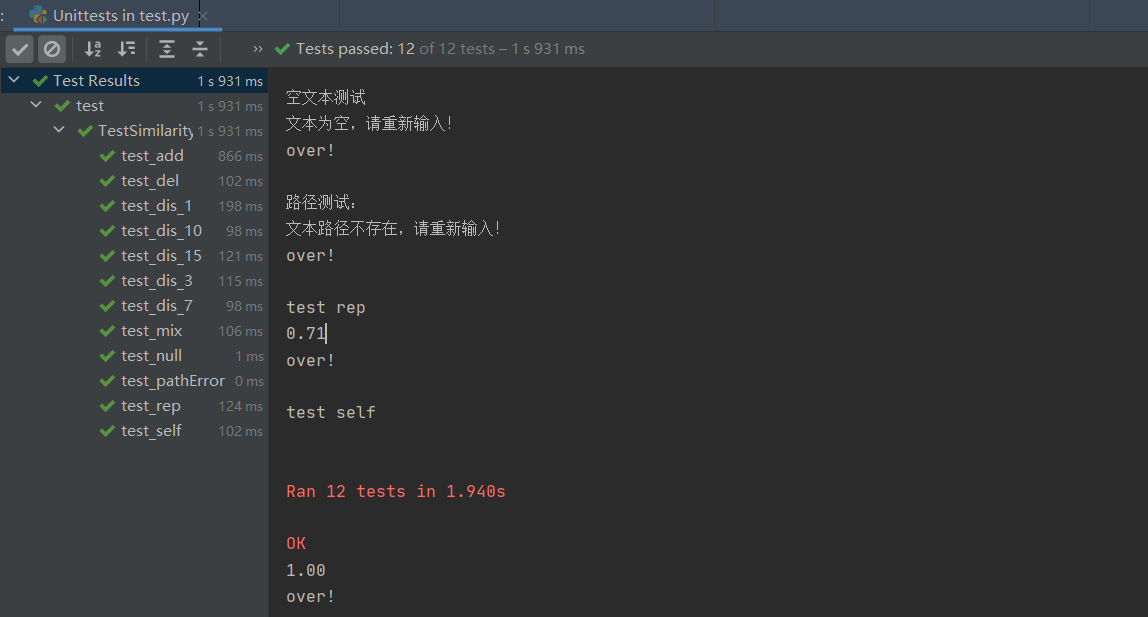
2.正常测试组:
def test_rep(self):
print("\ntest rep")
path2 = "./orig_0.8_rep.txt"
s = similarity.Similarity(self.path1, path2).similar()
print('%.2f' % s)
# 对比判断测试是否正确
self.assertGreaterEqual(s, 0)
self.assertLessEqual(s, 1)
3.异常测试组:
def test_null(self):
print("\n空文本测试:")
path2 = "./null.txt"
similarity.Similarity(self.path1, path2)
self.assertRaises(similarity.emptyError)
def test_pathError(self):
print("\n路径测试:")
path2 = "./error_path.txt"
self.assertRaises(similarity.pathError,similarity.Similarity,self.path1,path2)
*(第二个异常测试老是测试不成功,后来发现是assertRaises函数的参数设置出错了,
1-正确执行原文件应该抛出的异常类,2-原文件的主类,3、4-传入主类的测试参数,以上为我的理解,具体请参考使用文档)
4.测试覆盖率截图
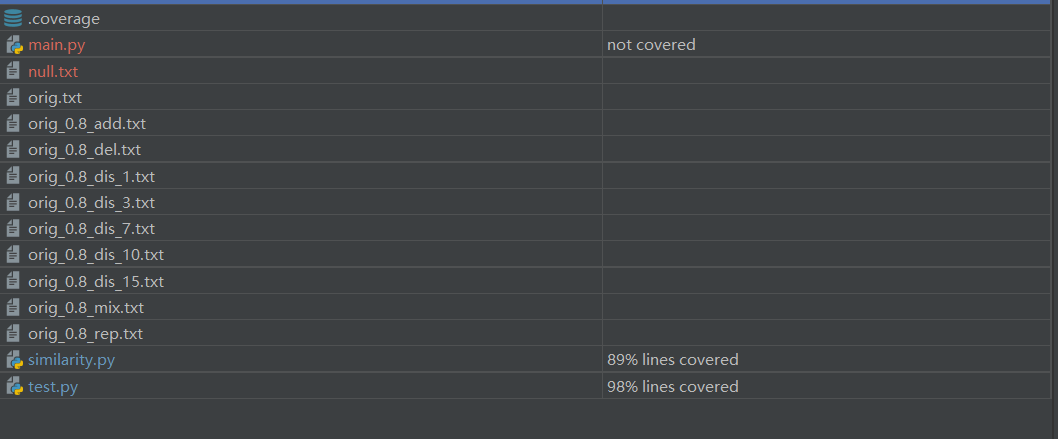
*说明:我的测试文档载入的是similarity.py,这是当初写代码的时候使用的名称。后面发现要用main.py作为入口文件名,便新建了main.py,两个文档内容完全一致。
六、模块异常处理
1.共设计了两个异常模块
# 异常处理类
class emptyError(Exception) :
def __init__(self):
print("文本为空,请重新输入!")
class pathError(Exception) :
def __init__(self):
print("文本路径不存在,请重新输入!")
2.主类里的使用情况:
def read(doc_path):
# 过滤文本:除去字符,返回字符串
#路径异常处理
if os.path.exists(doc_path) ==False:
#print("路径异常,请重新输入!")
raise pathError
#文本处理
doc = open(doc_path, encoding='UTF-8')
punch = '~`!#$%^&*()_+-=|\';:/.,?><~·!@#¥%……&*()——+-=“”:’;、。,?》《{} \n'
doc_txt = re.sub(r"[%s]+" % punch, "", doc.read())
doc.close()
# 空文本异常
try:
if len(doc_txt) == 0 :
raise emptyError
except emptyError:
pass
return doc_txt
self.str1 = read(path1)
self.str2 = read(path2)
3.说明:
1)空文本异常处理:输入的文本内容为空时,读取到的doc_txt长度为0,抛出emptyError异常,输出提示。
2)路径异常处理:输入的历经不存在时,抛出pathError异常,输出提示。
4.测试样例:
def test_null(self):
print("\n空文本测试:")
path2 = "./null.txt"
similarity.Similarity(self.path1, path2)
self.assertRaises(similarity.emptyError)
def test_pathError(self):
print("\n路径测试:")
path2 = "./error_path.txt"
self.assertRaises(similarity.pathError,similarity.Similarity,self.path1,path2)
5.结果:

七、个人总结
1.绝对绝对不要拖作业!!尤其是软工实践!!血的教训o(╥﹏╥)o
错过周末黄金时期;周一电脑突然出故障,幸好当晚修好;周二开始写代码,算法和模型与作业要求不符,调试不出结果;周三继续调试,仍旧不行;周三下午换算法,重写程序;周三晚上编写单元测试;周四下午异常处理;周四晚上码博客,就是现在,被ddl追着打字【泪目】
2.我变强了,也变秃了xx
重新拾起python,我还是那个小白= =不过这次的作业让我对python的熟悉程度更高了些
对GitHub的基本操作和Git的使用也有了一定了解(虽然还是不得不面对一堆英文,但经过这几天,看GitHub的界面都觉得亲切许多了ne)
3.作业感受:
不得不说,这次的作业调试代码不是最难的,而是做单元测试、性能分析(虽然我也没分析出个啥)、使用GitHub、写博客等这些事情比较繁琐。
总之,算是接触了更多编程的衍生事务了吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号