Redis的安装与配置与基础知识点
Redis入门
Redis是一个高性能的开源的、C语言写的NoSQL(非关系型数据库),数据保存在内存中(快,容易丢失),以key-value的形式存储
特点
- 数据保存在内存中,存取速度快,并发能力强
- 支持多种存储的数据类型,包括string(字符串),list(链表),set(集合),zset(有序集合)和hash(哈希类型)
- 提供了多种语言的客户端,使用起来很方便
- 支持集群(主从同步),数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器
- 支持持久化,可以将数据保存在硬盘中
- 支持订阅发布功能
使用场景
-
中央缓存
经常查询的数据,不经常变化的数据,放到读取速度很快的内存中,以便下次访问减少时间,减轻数据库的压力
-
计数器应用
-
排行榜
-
设定有效期的应用
设定一个数据,到了一定的时间失效。自动解锁,购物券
-
自动去重应用
-
队列
构建队列系统,使用list可以构建队列系统
秒杀:可以把名额放到内存队列,内存能够处理高并发访问
-
消息订阅
Redis的安装
-
下载源码
wget http://download.redis.io/releases/redis-6.0.3.tar.gz -
解压
tar -zxf redis-6.0.3.tar.gz -
进入redis安装的根目录执行
make install注:新版本的redis需要较高的gcc版本,make前先升级gcc
-
安装gcc
yum -y install gcc -
安装centos-release-scl
yum install centos-release-scl -
安装devtoolset
yum install devtoolset-9-gcc* -
激活
scl enable devtoolset-9 bash
-
-
为了启动方便可以配置环境变量
export PATH=/usr/local/redis-6.0.3/bin:$PATH -
启动redis
redis-server -
启动客户端
redis-cli注:这样启动服务会直接卡在界面,所以需要配置后台启动
-
在redis目录中找到redis.conf配置文件
prorectd-mode no #开放所有IP bind 0.0.0.0 #后台启动 daemonize yes #密码 requirepass root123 -
启动
redis-server redis.conf
数据类型
- string(字符串)
- List(列表)
- Set(集合)
- Zset(有序集合)
- Hash(哈希)
持久化
RDB(Redis Database)
在指定的时间间隔内生成数据集的快照并写入到磁盘中,恢复的时候直接将快照文件从磁盘读到内存中,这是redis默认配置的方案
Redis会单独创建一个子进程来进行持久化,会先将数据写到一个临时文件中,待持久化过程结束了,再用这个临时文件替代上次持久化好的文件,整个过程,主进程是不进行任何IO操作的
触发机制
- 配置文件中sava规则满足的情况下会自动触发rdb规则
- 执行save bgsave,flushall命令,也会触发
- 退出redis时也会产生rdb文件
恢复rdb文件
只需要将rdb文件放到redis启动目录就可以,redis启动的时候会自动检查dump.rdb恢复其中的数据
优点
- 适合大规模的数据恢复
- 对数据的完整性要求不高
缺点
如果redis意外宕机了,这个最后一次修改的数据就没有了,只能保留最后一个save的地方
AOF(Append Only File)
以日志的形式来记录每个写操作,将redis执行过的所有写操作都记录下来,只许追加文件,但不可以改写文件,redis启动的时候会根据日志文件的内容将写指令再执行一遍,默认不开启,需要手动配置
appendonly yes
注:
- 如果aof文件有错位,这时候redis是启动不起来的,需要使用redis提供的工具进行修复 redis-check-aof-fix
- 如果aof文件大于64m,redis会对文件进行重写,重写是绝对安全的
优点:
- 每一次修改都会同步:数据的完整会更加好,每秒同步一次:可能会丢失一秒的数据,默认:从不同步,效率最高
缺点:
- 相对于数据文件来说,aof远远大于rdb,修复的速度也比rdb慢
- aof运行效率也要比rdb慢,所以redis默认为rdb持久化
集群
主从复制模式
主从复制模式中包含一个主数据库实例(master)和多和从数据库实例(slave),数据库可以对主数据库进行读写操作,从数据库进行读操作,主数据库写入的数据实时同步到从数据库中

工作机制:
- slave启动后,向master发送SYNC命令,master接收到SYNC命令后通过bgsave保存快照,并使用缓冲区记录保存快照这段时间内执行的写的命令
- master将保存的快照文件发送给slave,并继续记录执行的写的命令
- slave接收到快照文件后,加载快照文件,载入数据
- master快照发送完后开始向slave发送缓冲区的写命令,slave接受命令并执行,完成复制初始化
- 此后master每次执行一个写命令都会同步发送给slave,保持master与slave之间的数据一致性
优点:
- master能自动将数据同步到slave,可以进行读写分离,分担master读的压力
- master,slave之间的同步是以非阻塞的方式进行的,同步期间,客户端仍然可以提交查询或更新请求
缺点:
- 不具备自动容错与恢复功能,master或slave的宕机都可能导致客户端请求失败,需要等待机器重启或手动切换客户端IP才能恢复
- master宕机,如果宕机前数据没有同步完,则切换ip会存在数据不一致的问题
- 难以支持在线扩容,redis的容量受限于单机配置
Sentinel哨兵模式
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行,其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例

哨兵作用:
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器
- 当哨兵检测到master宕机,会自动将slave切换成为master,通过发布订阅模式通知其他的从服务器修改配置文件,让他们切换主机
一个哨兵进程对Redis服务器进行监控可能会出现问题,为此我们可以使用多个哨兵进行监控,各个哨兵之间还会进行监控,这样就形成了多哨兵模式,哨兵个数一般为奇数个
故障切换过程:
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行故障切换,仅仅是哨兵1主观的任为主服务器不可用,这个现象称为主观下线,当后面的哨兵也检测到主服务器不可用,并且达到一定值的时候,哨兵之间会进行一次投票选举领导,投票的结果由一个哨兵发起,进行故障切换,切换成功后就会通过发布订阅模式,让各个哨兵把自己监控的服务器实现切换主机,这个过程称为客观下线
优点:
- 哨兵模式基于主从复制模式,所以主从复制模式有的优点,哨兵模式也有
- 哨兵模式下,master挂掉可以自动进行切换,系统可用性更高
缺点:
- 同样也继承了主从模式难以在线扩容的缺点,Redis的容量受限于单机配置
- 需要额外的资源来启动sentnel进程,实现相对复杂一点,同时slave节点作为备份节点不提供服务
Cluster集群模式
哨兵模式解决了主从复制不能自动故障转移,达不到高可用的问题,但还是存在难以在线扩容,Redis容量受限于单机配置的问题,Cluster模式实现了Redis的分布式存储,即每台节点存储不同的内容,来解决在线扩容的问题

特点:
- 所有的redis节点彼此互联,内部使用二进制协议优化传输速度和带宽
- 节点的fail是通过集群中超过半数的节点检测失效时才生效
- 客户端与redis的节点直连,不需要中间代理层,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
工作机制:
- 在redis的每个节点上,都会有一个插槽(slot),取值范围为0-16383
- 当我们存取key的时候,redis会根据CRC16的算法得到一个结果,然后把结果对16384取模,这样每一个key都会对应一个编号在0-16383之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
- 为了保证高可用,Cluster模式也引入了主从复制,一个主节点对应多个从节点,当主节点宕机的时候,就会启用从节点
- 当其他主节点ping一个主机点A时,如果半数以上的主节点与A通信超时,那么任务主节点A宕机了,如果A节点和他的从节点都宕机了,那么该集群就无法再提供服务了
Cluster模式中集群节点最小配置6个节点(3主3从),其中主节点提供读写操作,从节点作为备用节点。不提供请求,只作为故障转移使用
优点:
- 无中心架构,数据按照slot分布在多个节点
- 集群汇总的每个节点都是平等的关系,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他的所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据
- 可线性扩展到1000多个节点,节点可以动态添加或者删除
- 能够实现故障自动转移
缺点:
- 客户端实现复杂,驱动要求实现SmartClient,缓存slots mapping信息并及时更新,提高开发难度
- 节点会因为某些原因发生阻塞(阻塞时间大于 cluster-node-timeout)被判断下线,这种failover是没有必要的
- 数据通过异步复制,不保证数据的强一致性
- slave充当“冷备”,不能缓解读压力
- 批量操作限制,目前只支持具有相同slot值的key执行批量操作,对mset、mget、sunion等操作支持不友好
- key事务操作支持有线,只支持多key在同一节点的事务操作,多key分布不同节点时无法使用事务功能
- 不支持多数据库空间,单机redis可以支持16个db,集群模式下只能使用一个,即db 0
缓存穿透
当客户端查询某个redis中不存在的数据时,就会去数据库中查询,如果有大量恶意的请求查询这个数据,就会给后端的数据库造成很大的压力
解决办法:
- 对后端数据库查询到的空结果也进行缓存
- 使用布隆过滤器
服务雪崩
在某个时间节点,redis中有大量的数据都在同一个时间过期,这个时候又有很多的请求去访问这次数据
解决办法:
对数据设置过期时间的时候随机分散一点
缓存击穿
在某个时间点,有一个热点数据突然过期,这个时候大量请求会请求数据库,造成数据库很大的压力
解决办法:
- 设置热点数据永不过期
- 使用互斥锁,当缓存失效的时候不会立即去查询数据库,而是先使用缓存工具中某些带成功操作返回值的操作,当操作返回成功时,再去查询数据库并回设缓存
Redis分布式锁原理
初步实现:
Redis锁只要利用Redis的setnx命令
- 加锁命令:SETNX key value, 当键不存在时,对键进行设置操作并返回成功,否则返回失败,KEY是锁的唯一标识,一般按照业务来决定命名
- 解锁命令:DEL key,通过删除键值对释放锁,以便其他线程可以通过SETNX命令来获取锁
- 锁超时:EXPIRE key timeout,设置key的超时时间,以保证即使锁没有被显示释放,锁也可以在一定时间后自动释放,避免资源被永远锁住
if (setnx(key, 1) == 1){
expire(key, 30)
try {
//TODO 业务逻辑
} finally {
del(key)
}
}
上述实现方式会存在一些问题:
- SETNX和EXPIRE非原子性
如果SETNX成功,在设置锁超时后,服务器挂掉,导致EXPIRE没有执行,导致死锁
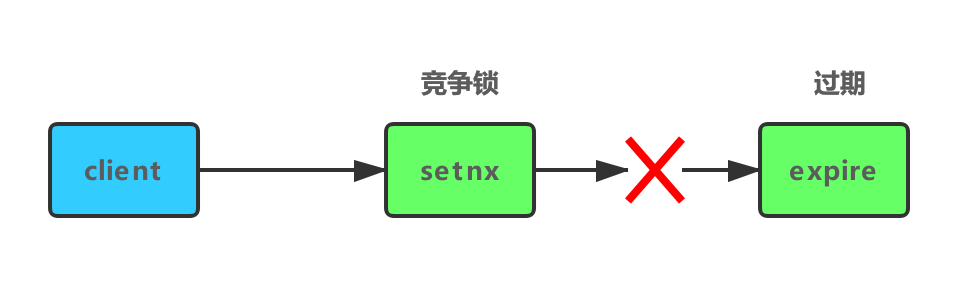
- 锁误解除
A、B两个线程来尝试给key mylock加锁,A线程先拿到锁,B就会等待,这个时候如果A的锁在业务逻辑执行完之间先过期了,B就会获得锁,此时A线程业务逻辑执行完,删除了锁会把B线程的锁也给释放了
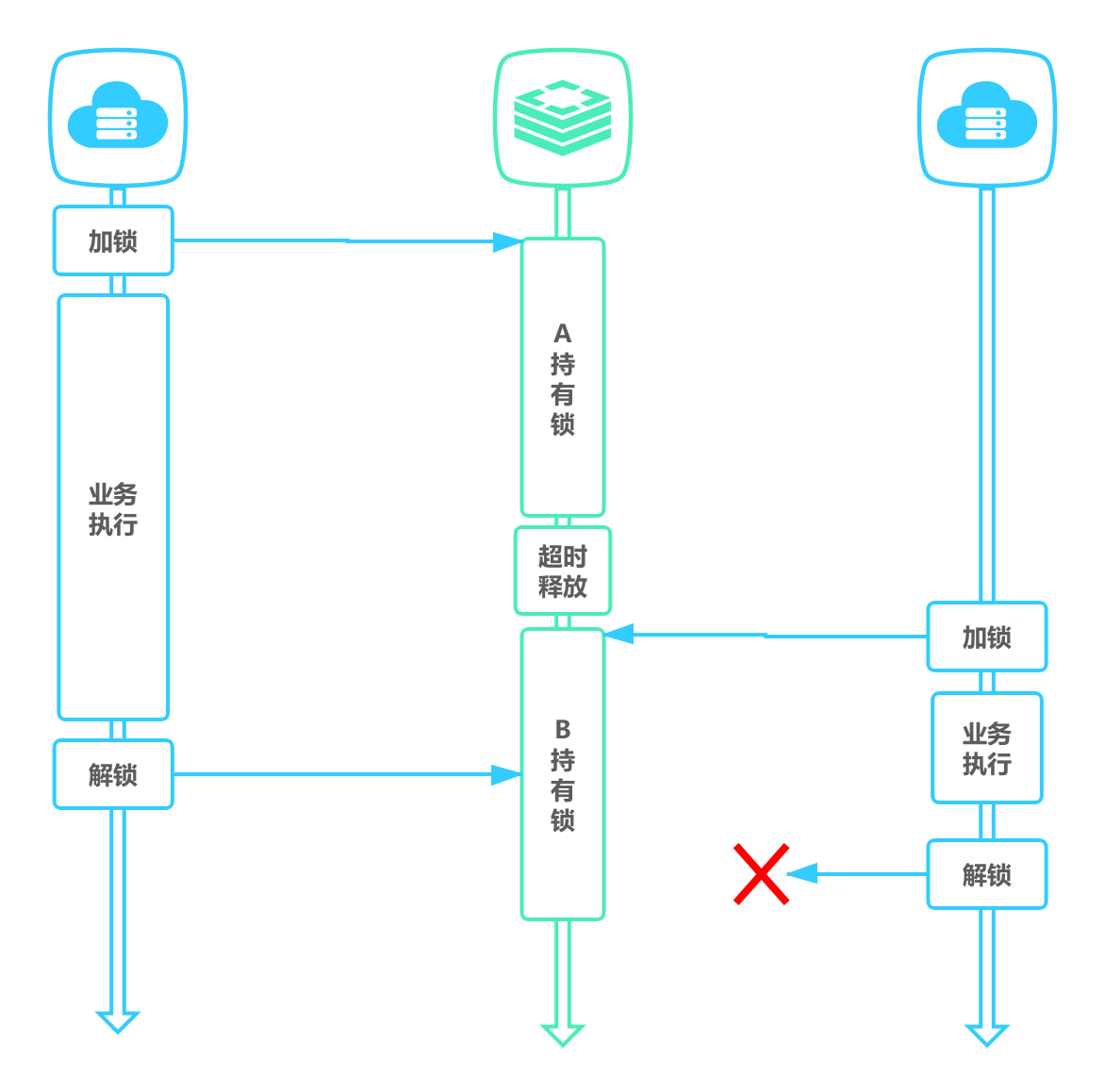
解决办法:
给每个线程加锁时都要带上自己独有的value值来标识,释放的时候只释放指定value的key,否则就会出现释放锁的混乱场景
// 加锁
String uuid = UUID.randomUUID().toString().replaceAll("-","");
SET key uuid NX EX 30
// 解锁
if (redis.call('get', KEYS[1]) == ARGV[1])
then return redis.call('del', KEYS[1])
else return 0
end
- 超时解锁导致并发
如果线程A成功获取锁并设置过期时间30秒,但线程A执行时间超过了30s,此时B线程获取到了锁,A和B就会同时并发执行
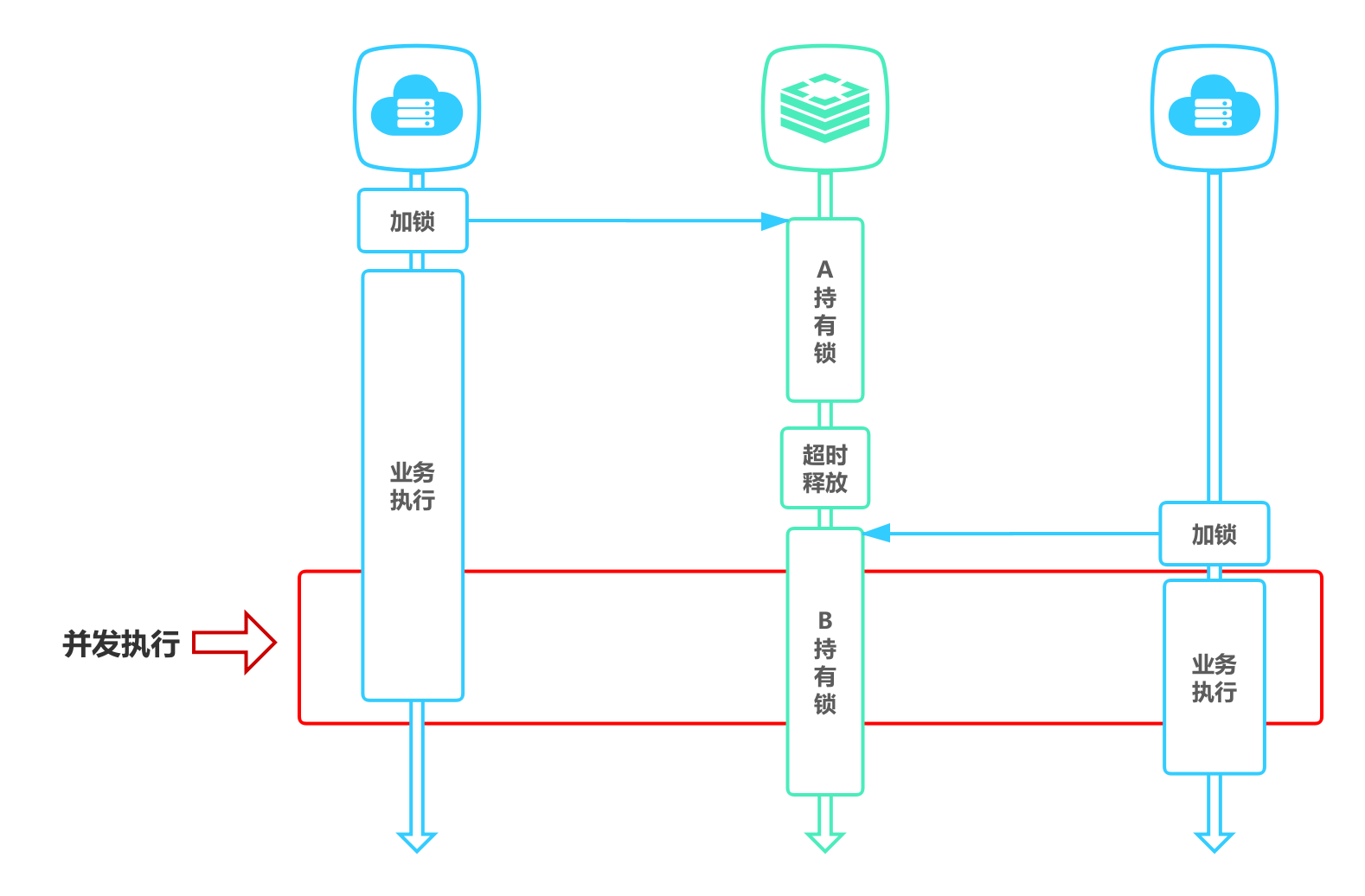
解决办法:
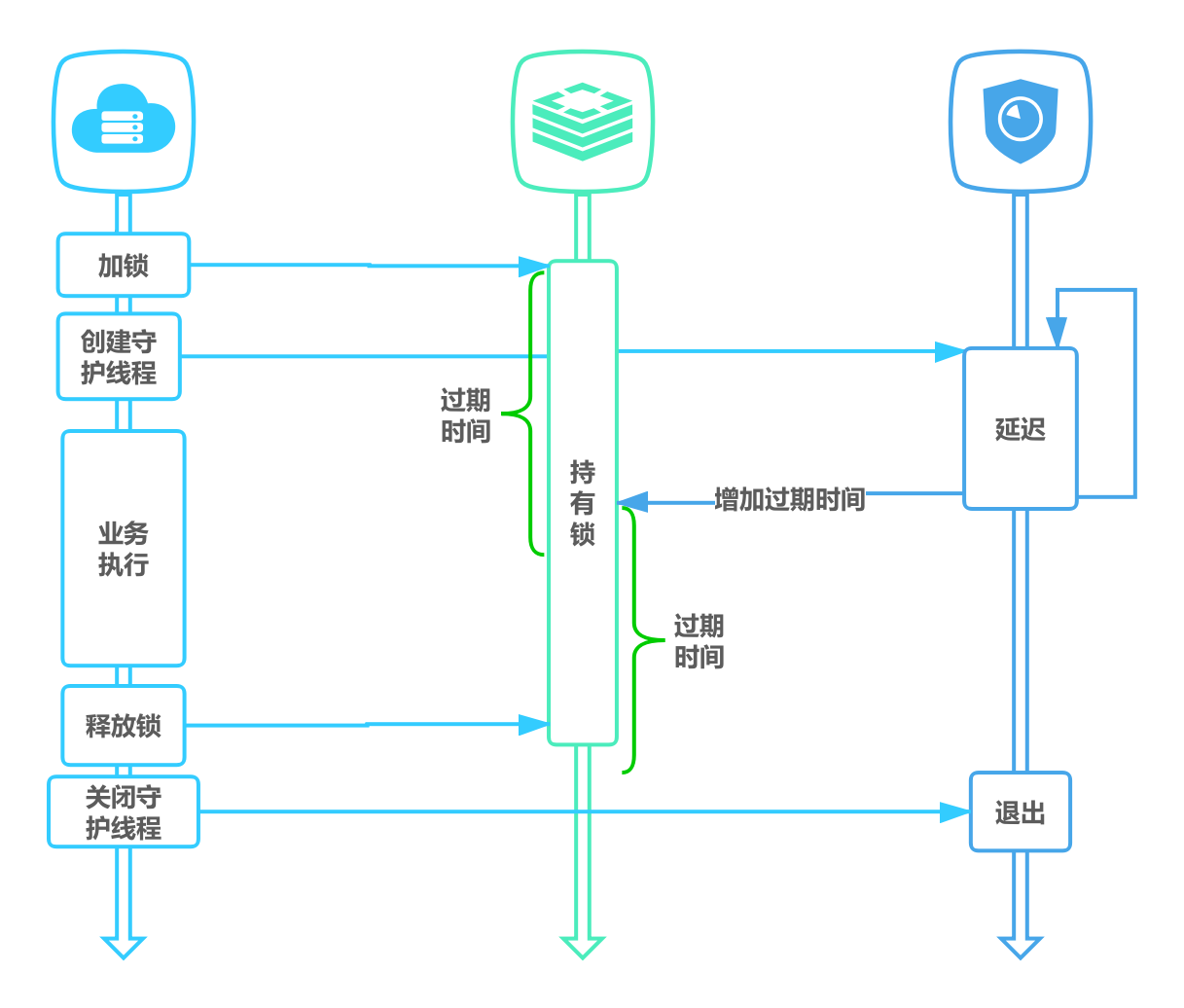
- 将过期时间设置足够长,确保代码逻辑在锁释放之前能够执行完成
- 为获取锁的线程增加守护线程,为将要过期但未释放的锁增加有效时间
- 不可重入
当线程在持有锁的情况下再次请求加锁,如果一个锁支持一个线程多次加锁,那么这个锁就是可重入的。如果一个不可重入锁被再次加锁,由于该锁已被持有,再次加锁会失败。Redis可以通过对锁进行计数,加锁时+1,解锁时-1,当计数器归0时释放锁
在本地记录记录重入次数,如 Java 中使用 ThreadLocal 进行重入次数统计,简单示例代码:
private static ThreadLocal<Map<String, Integer>> LOCKERS = ThreadLocal.withInitial(HashMap::new);
// 加锁
public boolean lock(String key) {
Map<String, Integer> lockers = LOCKERS.get();
if (lockers.containsKey(key)) {
lockers.put(key, lockers.get(key) + 1);
return true;
} else {
if (SET key uuid NX EX 30) {
lockers.put(key, 1);
return true;
}
}
return false;
}
// 解锁
public void unlock(String key) {
Map<String, Integer> lockers = LOCKERS.get();
if (lockers.getOrDefault(key, 0) <= 1) {
lockers.remove(key);
DEL key
} else {
lockers.put(key, lockers.get(key) - 1);
}
}
SET key value[EX seconds][PX milliseconds][NX|XX]
- EX seconds: 设定过期时间,单位为秒
- PX milliseconds: 设定过期时间,单位为毫秒
- NX: 仅当key不存在时设置值
- XX: 仅当key存在时设置值
首先线程先尝试获取锁,即判断锁是否以及存在,不存在就创建锁存入redis,存在即等待,当线程拿到锁后 会在redis中存储一个有过期时间的唯一值,当业务逻辑处理完之后先判断锁是否是自己的锁,如果是则释放锁,删除redis中存储的锁,释放完锁之后其他的线程就可以获得锁了,如果不是就不要释放
- Redis主从复制的坑
redis cluster集群环境下,假如现在A客户端想要加锁,他会根据路由规则选择一台master节点写入key mylock,在加锁成功后,master节点会把key异步复制给对应的slave节点,如果这个时候redis 的master节点宕机,为保证集群高可用性,会进行主备切换,slave变成了master,B客户端在新的master上加锁成功,而A客户端也以为自己还是成功加锁了的,此时就会导致各种脏数据的产生

 浙公网安备 33010602011771号
浙公网安备 33010602011771号