spark2.2.1安装、pycharm连接spark配置
一、单机版本Spark安装
Win10下安装Spark2.2.1
1. 工具准备
JDK 8u161 with NetBeans 8.2:
http://www.oracle.com/technetwork/java/javase/downloads/jdk-netbeans-jsp-142931.html
spark: spark-2.2.1-bin-hadoop2.7:
https://spark.apache.org/downloads.html
winutils.exe:下载的是针对hadoop-2.7的64位的winutils.exe
hadoop-2.7.3:
https://archive.apache.org/dist/hadoop/common/
scala-2.11.8可到官网自行下载
2. Java双击安装
3. spark, hadoop解压到你想保存的目录,hadoop解压过程发生提示需要以管理身份运行(载好安装包之后解压安装包,把文件夹名改成hadoop,并和Spark一样)。解决方案
4. 环境变量设置
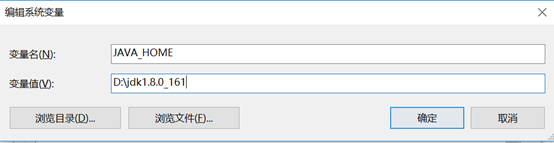
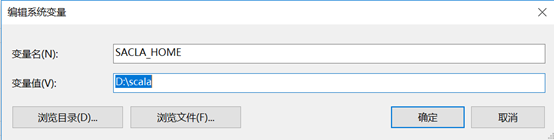
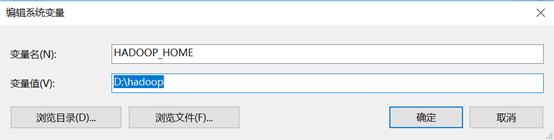


编辑系统变量PATH的值,将java,spark,Hadoop,scala的相关bin路径添加进去
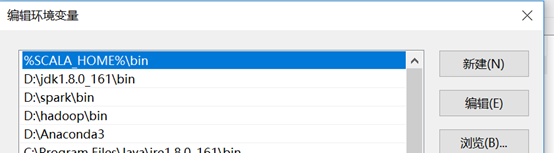
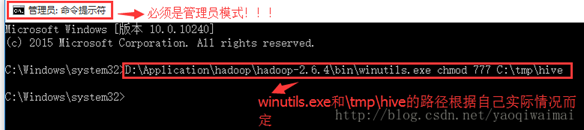
5. winutils.exe拷贝到hadoop解压后的bin目录下,打开C:\Windows\System32目录,找到cmd.exe,单击选中后右键,菜单中选择“以管理员身份运行”。以管理员模式进入cmd中输入 D:\hadoop-2.7.5\hadoop-2.7.5\bin\winutils.exe chmod 777 /tmp/hive


二、pycharm连接Spark配置
pip install pyspark
http://blog.csdn.net/clhugh/article/details/74590929
pyspark配置
step1.在cmd命令行里面进入python
step2.输入findspark模块,import findspark
pip install findspark
findspark.init()
step3.初始化findspark模块,输入 findspark.init()
然后配置好SPARK_HOME环境变量
PYTHONPATH环境变量


三、通过IDEA搭建scala开发环境开发
主要通过了两个网站
https://www.cnblogs.com/wcwen1990/p/7860716.html
https://www.jianshu.com/p/a5258f2821fc
https://www.cnblogs.com/seaspring/p/5615976.html
bug1:
找了好久才找到原因:http://blog.csdn.net/fransis/article/details/51810926
Bug2:

解决方法:http://blog.csdn.net/shenlanzifa/article/details/42679577
四、通intellij idea打包可运行scala jar包
https://blog.csdn.net/freecrystal_alex/article/details/78296851

 浙公网安备 33010602011771号
浙公网安备 33010602011771号