Ragflow配置参数解释
Ragflow部署好以后,创建知识库及助理时,有一些配置参数,新手可能不知道如何配置,可以参考下面解释。
1. 知识库配置
1.1. 文档解析器
建议保持默认选项DeepDoc。
如果文档格式简单、内容常规,追求快速解析,可考虑选择 “简易” 。
1.2. 嵌入模型
在Ragflow中,嵌入模型发挥着两个关键作用,一是把知识库中的文档数据转换为向量,二是在聊天场景下将用户输入的自然语言转换为向量。这些向量能够在向量空间中体现文本的语义特征,为后续的相似度对比提供依据。
当用户进行提问时,Ragflow会基于混合相似度计算来判断二者的相关性。筛选出与问题相似度高的内容后,RAGFlow会根据这些文档的内容,结合自身的语言生成能力,生成合适的回答输出给用户。
在这里,主要是发挥其第一个作用。
如果知识库是基于中文的,可以选择:BAAI/bge-large-zh-v1.5。
多语言的可以视情况而定。
1.3. 解析方法
目前支持以下这几种解析方法:General、Q&A、Resume、Manual、Table、Paper、Book、Laws。
选择不同的解析方法后,右侧均有说明。
这里简单说明下可能用得比较多的解析方法。
General主要是根据文本的排版、格式、语义关联等因素来确定分割点,结合块Token数来将文本切换为适合大小的文本块。
Q&A主要是问答对数据,即表格中只有两列,一列是问题,一列是答案,每行一个问答对,格式建议EXCEl或CSV。
Manual会按章节将文档分割为大小不等的文本块,这个比较考验文档格式,如果每个章节内容联系紧密、最好主题比较单一、且各章节长度比较均匀,可以考虑使用这种方法,比较大的章节会消耗过多的token,也不利于精准回答。
Table即表格,如果文档内容能被整理表格这种更接近结构化的格式,可以考虑使用这种解析方法,这种行列的关系,通常能比较准确地体现数据之间的关系,有利于内容的解析及后续提升问答准确度。
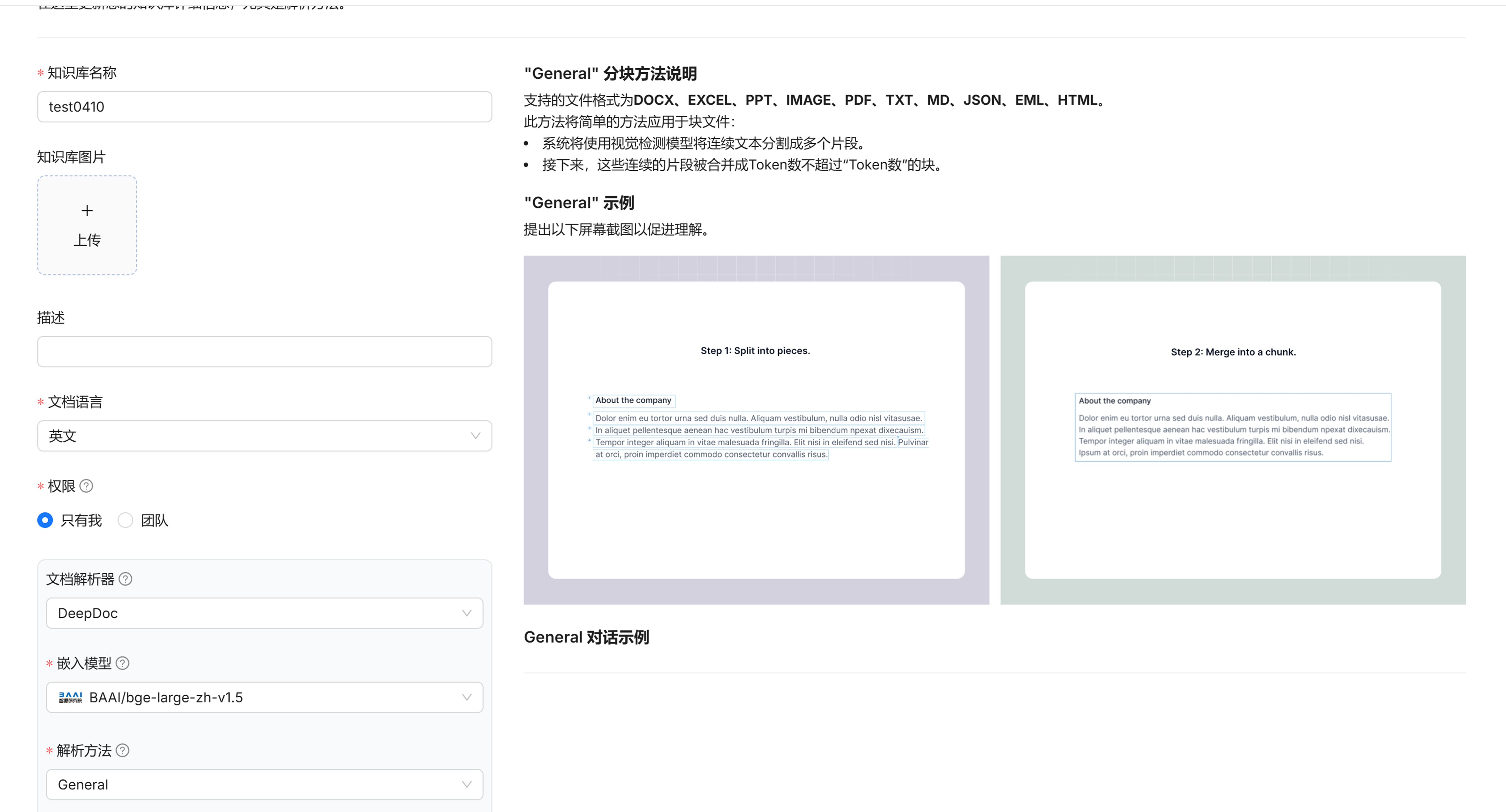
1.4. 块Token数
当解析方法选择General时需要设置此参数的值。
一般建议大小在128至512之间,实际的值需要经过多次测试,大模型回答问题既不会截断、也不会有太多相关性不强的内容时比较合适。
1.5. 分段标识符
选择General解析方法时,会基于分段标识符进行文本分割,再根据块token大小对分割的文本进一步分块。
1.6. 页面排名
当检索对象为多个知识库、且需要指定优先检索的知识库时,可以使用此参数,计算相似度得分后分加上此指标的值,这会提高这个知识库内容的相似度得分。
1.7. 自动关键词
在解析文档时,根据算法识别出出现频率较高且对语义贡献大的词汇作为关键词,这些关键词能提升在知识库中检索相关内容的效率。
1.8. 自动问题
类似于自动关键词,在解析文档时生成相关问题,能为问答系统提供更多预设问题及答案对,提升系统回答问题的全面性和准确性。
1.9. 使用召回增强 RAPTOR 策略
现在的大多数检索增强语言模型,仅从检索语料库中检索短的连续文本块,这限制了对文档上下文的全面理解。
为了解决这个问题,引入这种方法,反复对文本块进行嵌入(放到特定表示空间)、聚类(把相似文本块放一起 )和总结,自下而上构建一棵有不同层次的树。
在推理时, RAPTOR 模型从这棵树中检索,整合不同抽象层次的长文档信息。以提高回答的准确率。
1.9.1. 最大token数
含义:Token 是模型处理文本时的基本单元,比如把一句话拆分成一个个小的词块等 。最大 token 数就是模型一次能处理文本量的上限。
设置建议:如果处理简短文本(如一句话、短新闻摘要 ),可以设置小一些,比如 128 。处理长文档(如长篇论文、书籍章节 ),可适当调高,如 512 甚至更高,但也不是越高越好,过高会占用大量计算资源,还可能影响处理速度。
1.9.2. 阈值
含义:一般用于判断某种相似性、匹配度等指标的临界值。比如在聚类中,用来判断文本块是否相似到能归为一类 。
设置建议:通常在 0 - 1 之间。如果希望聚类更精细,让类别内文本相似度高,可设置小一些,如 0.05 - 0.1 ;若想类别宽泛些,包含更多有一定差异的文本,可设置大些,如 0.3 - 0.5 。也可根据多次实验效果来调整。
1.9.3. 最大聚类数
含义:指将文本数据划分成类别的最大数量。
设置建议:如果文本主题比较单一,类别少,可设置小一点,如 10 - 20 ;文本主题丰富多样,可适当增大,如 50 - 100 。还可以参考文本中明显的主题数量预估,比如文档涉及 5 个明显主题,可从略大于 5 的数值开始尝试。
1.9.4. 随机种子
含义:是一个初始值,用于确定随机数生成的起始状态。当算法有随机成分时,相同随机种子能保证每次运行结果一致,不同种子则结果不同。
设置建议:如果希望每次运行结果稳定可重复(比如调试、对比实验 ),设置一个固定整数,如 0、1 。如果追求每次不同随机效果(如探索不同可能性 ),可以不固定,每次设置不同整数。
1.10. 提取知识图谱
创建知识库时,开启“提取知识图谱”,并添加实体后,解析文件时会由 ragflow 提取知识图谱。
解析完成后,该知识库会生成知识图谱,用于提高问答准确度。
1.10.1. 实体类型
对文档中的实体进行归类,用于构建知识图谱各个节点之间的关系。
如我要整理的是一份设备故障代码知识库,那么实体类型可能包含:一级分类、子分类、设备、子设备、配件、故障现象、故障原因、解决方法等。
如我要整理的是一份系统操作问答知识库,那么实体类型可能包含:模块、菜单、子菜单、页面、功能、操作步骤等。
1.10.2. 方法
若注重成本和提取速度,Light较合适;若追求知识图谱高质量,愿承担更高成本,General更优 。
Light:简单快速的检索增强生成。
项目地址:https://github.com/HKUDS/LightRAG
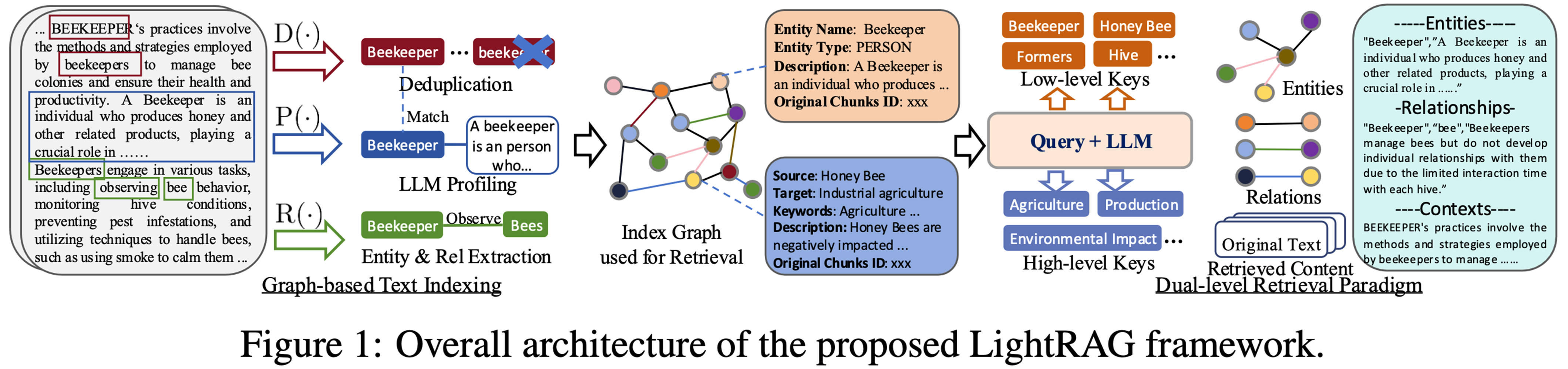
上图是 LightRAG 的工作过程。整个框架旨在通过对文本的处理、索引构建和双级检索,有效管理和提取文本中的知识信息。
这张图展示了 LightRAG 框架的总体架构,主要步骤和内容如下:
第一步:原始文档处理,原始文本中包含与“养蜂人(Beekeeper )”相关内容,通过三种操作进行处理:
D(·)去重(Deduplication ):对文本中重复的养蜂人相关表述进行去重处理。
P(·)大语言模型分析(LLM Profiling ):利用大语言模型分析养蜂人相关文本信息。
R(·)实体与关系提取(Entity & Rel Extraction ):提取文本中的实体(如养蜂人 )和关系(如养蜂人观察蜜蜂 ) 。
第二步:索引构建与检索
Index Graph 用于检索(Index Graph used for Retrieval ):经过上述处理后,将信息构建成索引图。图中的节点代表不同实体等信息,边代表实体间关系。
索引图中的节点包含实体信息,如实体名称(Entity Name )为养蜂人,实体类型(Entity Type )为“人(PERSON )” ,还有相关描述(Description )等。同时也有其他实体如蜜蜂(Honey Bee ) 、蜂巢(Hive )等。
第三步:双级检索范式
Query + LLM(查询 + 大语言模型 ):结合用户查询,利用大语言模型进行处理。
双级检索(Dual - level Retrieval Paradigm ):
低级关键词(Low - level Keys ):如养蜂人、蜜蜂等具体实体。
高级关键词(High - level Keys ):如农业(Agriculture )、生产(Production ) 、环境影响(Environmental Impact )等宏观概念。
最终输出实体(Entities )、关系(Relationships )和上下文(Contexts )相关信息,例如养蜂人的定义、养蜂人与蜜蜂的关系,以及原始文本和检索到的内容等。
General:使用的是微软开源的 GraphRAG 项目,该项目是一个数据管道和转换套件,旨在利用大型语言模型(LLMs)的力量从非结构化文本中提取有意义的结构化数据。
项目地址:https://github.com/microsoft/graphrag
文档地址:https://microsoft.github.io/graphrag/
GraphRAG 是一种结构化、分层的检索增强生成(RAG)方法,与使用纯文本片段的简单语义搜索方法不同。GraphRAG 流程包括从原始文本中提取知识图谱,构建社区层次结构,为这些社
区生成摘要,然后在执行基于 RAG 的任务时利用这些结构。
其处理步骤大致如下。
1、将输入语料库分割成一系列的“文本单元”,这些文本单元作为后续处理过程中的可分析单元,并在我们的输出中提供精细的引用。
2、从文本单元中提取所有实体、关系和关键声明。
3、使用 Leiden 技术对图进行分层聚类。
4、自下而上地生成每个社区及其成员的摘要。这有助于全面理解数据集。
5、在查询时,这些结构用于为 LLM 上下文窗口提供材料以回答问题。
GraphRAG 索引器默认有一些用于知识发现的提示(prompts)。但为满足特定需求,可通过编写自定义提示文件来覆盖默认设置。GraphRAG 推荐使用自动调优。
手工调优比较麻烦,如下。
假设输入文本是:“猫喜欢睡觉,狗很忠诚,猫爱干净。”
优化为:“猫 | 喜欢睡觉;猫 | 爱干净;狗 | 很忠诚;END”。
在这个输出结果里,以 “|” 作为{tuple_delimiter} ,将动物实体与对应的特征分隔开;用 “;” 作为{record_delimiter} ,把不同动物的记录分开;
“END” 则作为{completion_delimiter} ,表示提取结束。
这样的输出结构清晰,方便后续对文本中动物实体及其特征信息进行解析和使用,能更高效地从文本中提取关键信息,满足特定场景下对文本信息处理和分析的需求。
1.10.3. 实体归一化
把具有相同含义的实体合并,比如文本中 “电脑”“计算机”“PC” 等不同表述,经实体归一化后都统一为 “计算机” 这一标准形式。
建议开启此选项。
1.10.4. 生成社区报告
GraphRAG 旨在通过两个主要步骤来解决这些问题:索引和查询。索引引擎首先将一组文本文档分解为段落,然后将这些段落聚类为具有实体和关系的分层社区,这些实体和关系通过更高层次
的抽象将每个段落连接起来。然后,我们使用 LLM 生成每个社区的摘要,称为社区报告。
在查询步骤中,GraphRAG 利用这种结构化知识为大语言模型提供额外的上下文,以帮助回答问题。
这个选项,应该是当选择“General”方法时,需要开启,因为他是属于 GraphRAG 提出的概念,和 Light 方法似乎没多大关系。
2. 聊天设置
2.1. 显示引文
在聊天信息中显示回答内容出自哪个文档哪个片段。
2.2. 关键词分析
开启此选项后,会运用大语言模型(LLM )分析用户提问,提取出在相关性计算中需重点关注的关键词。
开启关键词分析会增加计算量,使 LLM 多一步关键词提取和分析操作,从 LLM 接收答复时间会增加,模型响应速度变慢。
其作用如下。
精准匹配知识:能更精准地从知识库中筛选出与用户问题相关的内容。比如用户提问 “如何提高玫瑰的开花质量” ,开启关键词分析后,系统能准确提取 “玫瑰”“开花质量” 等关键词,快速定位知识库中关于玫瑰种植养护、提升开花质量的相关知识片段,提升回答准确性和相关性 。
优化检索效果:对用户输入问题进行深度语义理解,避免因表述差异导致的检索偏差。像用户问 “电脑运行慢咋整” ,系统能识别出 “电脑”“运行慢” 等关键语义,即便知识库中表述是 “计算机性能降低的解决方法” ,也能有效匹配,提升检索召回率和准确率 。
2.3. 相似度阈值及关键字相似度权重
Ragflow 使用混合相似度得分来评估两行文本之间的距离,以生成回复内容。
影响计算结果的两个因子,其一是加权关键字相似度,另一个是矢量余弦相似性得分或 Rerank 得分(当选择 Rerank 模型后以 Rerank 得分计算)。
混合相似度得分 = 关键字相似度得分 * 关键字相似度权重 + 矢量余弦相似性得分 * (1 - 关键字相似度权重)
或,混合相似度得分 = 关键字相似度得分 * 关键字相似度权重 + Rerank 得分 * (1 - 关键字相似度权重)
其中,关键字相似度权重与余弦相似度权重(或 Rerank 得分权重)的和为 1。
如果查询和块之间的相似度小于此阈值,则该块将被过滤掉。
越高的阈值,筛选出的文本块越少。
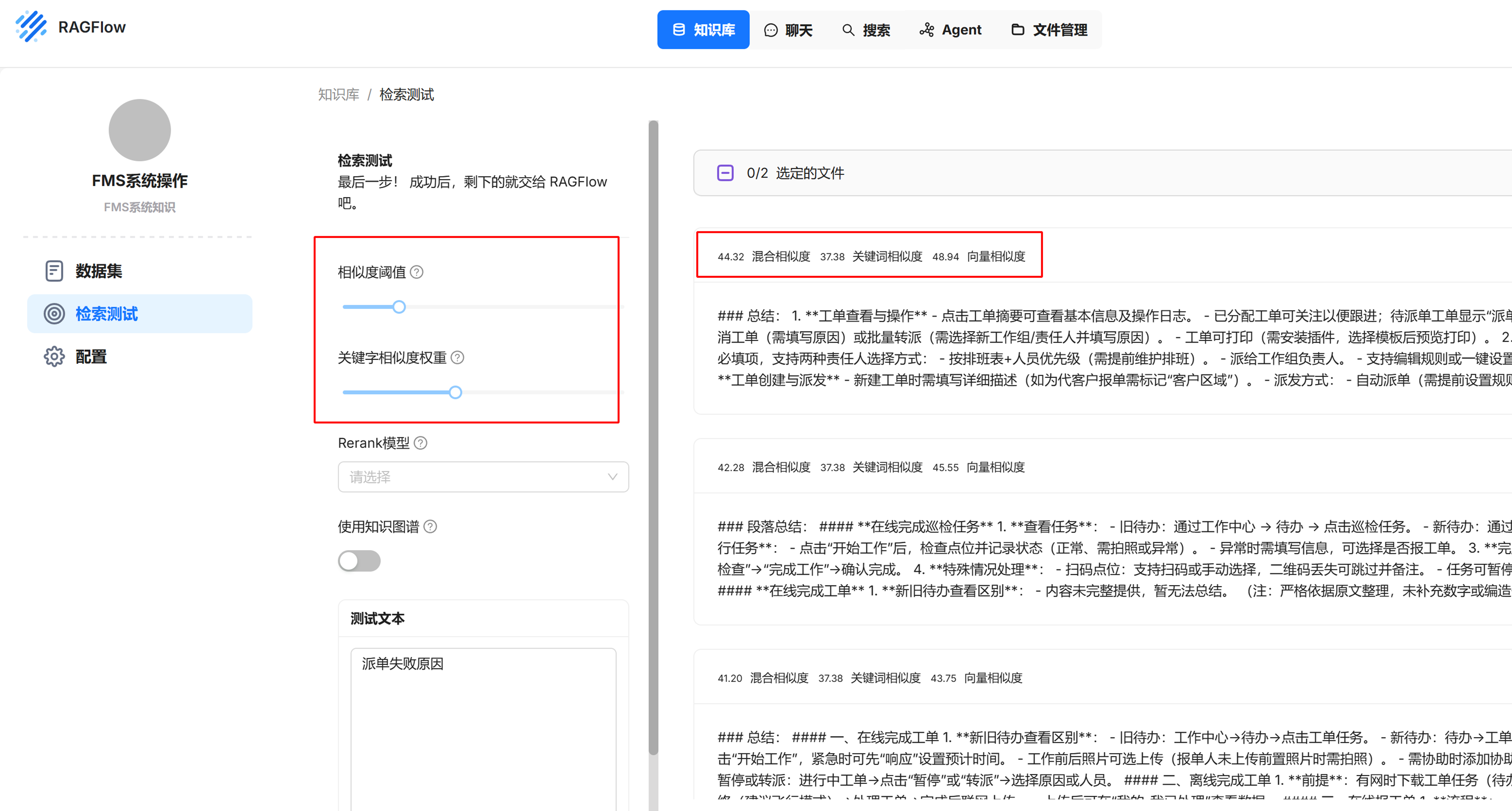
具体的阈值,可以到知识库中的“检索测试”中进行测试,根据测试选择一个合适的阈值。使回复结果中能包含期望的答案,又不会有太多不必要的信息。
如下图,可以通过调整相似度阈值,来测试查询出的文本块,文本块左上角会显示混合相似度,相似度 40.85 相当于阈值 0.4085。
注意,这里(知识库 -> 检索测试)只是进行测试,实际还是需要在聊天配置中进行设置。
本例中,相似度阈值设置为 0.2,将筛选出混合相似度大于 20 的文本块。
关键字相似度权重设置为 0.4。
混合相似度 = 37.38 * 0.4 + 48.94 * (1 - 0.4)= 14.952 + 29.364 = 44.316 ≈ 44.32
聊天配置中,如果选择 Rerank 模型,向量相似度处的值将会显示 Rerank 得分。
选择 Rerank 模型有助于提升查询准确度,具体可见 7. 重排序:让检索结果更有条理1
2.4. Top N
相对于前一个概念,“相似度阈值及关键字相似度权重”中的相似度阈值。
设置 Top N 后,当高于相似度阈值的文本块数量大于 N 时,将只会过滤出前 N 条。
可结合测试情况设置。
2.5. 多轮对话优化
在多轮对话的中,对去知识库查询的问题进行优化。会调用大模型额外消耗 token。
可视情况决定是否开启。
2.6. 开启知识图谱
知识库中开启“提取知识图谱”后,这里可以选择是否开启。
良好的知识图谱有利于提高回答的准确性,建议开启。
2.7. 推理
开启此选项后,会触发像 Deepseek R1 一样的推理过程。
作为知识库问答,可以不开启此选项。
2.8. Rerank 模型
选择 Rerank 模型可能有助于提高回答准确性,但会消耗额外的算力。
建议选择服务商提供的模型,如通义的 gte-rerank,不要选择本地模型,如 BAAI/bge-reranker-v2-m3,会导致回答速度变慢,特别是知识库中文档比较多的时候。
2.9. 温度
控制生成文本的随机性和创造性。数值越高,模型输出越随机、有创意。
对于知识库问答,一般需要严谨一点,保持默认值即可。
2.10. Top P
在大模型生成文本时,对于下一个要输出的单词,模型会为词汇表中的每个单词计算一个概率。Top P(核心采样)做的是,从概率最高的单词开始,依次累加这些单词的概率,当累加概率达到设定的阈值(即 Top P 的值 )时,就把这些单词构成一个集合。然后,模型只从这个集合里随机选择下一个要输出的单词 。通过这种方式,它摒弃了那些概率极低的单词,聚焦在更有可能出现的单词上,能在一定程度上平衡生成文本的多样性和合理性 。
假设模型的词汇表中有 10 个单词,分别是 A、B、C、D、E、F、G、H、I、J ,模型计算出它们生成下一个单词的概率依次为:
A:0.3
B:0.2
C:0.15
D:0.1
E:0.08
F:0.05
G:0.04
H:0.03
I:0.02
J:0.01
如果 Top P 的值设为 0.8 ,从概率最高的单词 A 开始累加概率:
选 A 时,累加概率为 0.3 ;再选 B ,累加概率变为 0.3 + 0.2 = 0.5 ;选 C 后,累加概率是 0.5 + 0.15 = 0.65 ;选 D 后,累加概率为 0.65 + 0.1 = 0.75 ;选 E 后,累加概率达到 0.75 + 0.08 = 0.83 ,此时已经超过了阈值 0.8 。
那么就得到一个由 A、B、C、D、E 这 5 个单词组成的集合,模型只会从这 5 个单词里随机选择一个作为下一个输出的单词,而不会考虑 F、G、H、I、J 这些单词 。这样,通过 Top P 的设置,就缩小了单词的选择范围,聚焦在更可能出现的单词上,让生成过程更合理 。
设置较低的阈值时,模型优先从常用且相关度高的词中选择,保证回答在专业领域的准确性。
暂时建议保持默认值 0.3 不修改,后续可以根据回答质量决定是否调整此参数。
2.11. 存在处罚
对对话中已经出现过的单词进行惩罚,降低其再次出现的概率,防止模型重复表述,让回答更丰富多样。
一般可设为 0.2 - 0.5 。若回答重复性严重,可适当调高,如 0.4 ;若文本较短且不希望过度抑制词汇出现,可适当调低。
2.12. 处罚频率
与存在处罚类似,抑制模型输出相同内容,但它是根据单词出现频率惩罚,出现频率越高,惩罚力度越大 。
通常设为0.5 - 1.0。如果希望更严格控制高频词重复,可设为0.7 - 1.0,如 0.7 ;若文本较简短或希望一定程度保留高频核心词,可设为0.5 - 0.7。
2.13. 最大token数
限制模型生成回复的最大长度,token 是模型处理文本时的基本单元 。
一般简单问答可设为 128 - 256 ;复杂解释、长文本生成场景可设为 512 或更高,但注意不要超过模型支持的最大上下文长度,否则可能截断回答或报错 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号