
fesh个人实践,欢迎经验交流!本文Blog地址:http://www.cnblogs.com/fesh/p/3775343.html
本文编译方法所支持的hadoop环境是Hadoop-2.2.0,YARN是2.2.0,JAVA版本为1.8.0_11,操作系统Ubuntu14.04
cd spark-1.0.1 ./make-distribution.sh --hadoop 2.2.0 --with-yarn --tgz
--tgz: Additionally creates spark-$VERSION-bin.tar.gz
--hadoop VERSION: Builds against specified version of Hadoop.
--with-yarn: Enables support for Hadoop YARN.
--with-hive: Enable support for reading Hive tables.
--name: A moniker for the release target. Defaults to the Hadoop verison.
如果一切顺利,会在$SPARK_HOME/assembly/target/scala-2.10目录下生成目标文件
(好像Java版本1.8在这里有版本问题?默认在1.6环境下,但我居然编译成功了,呵呵)
(注:之前加了--with-tachyon 我总是编译成功,但生成tgz部署包失败,不知道为什么。今天我在JDK1.7.0_51环境(应该与JDK版本无关)下,去掉了--with-tachyon ,编译成功,并且生成了spark-1.0.1-
bin-2.2.0.tgz部署包)
编译结果:
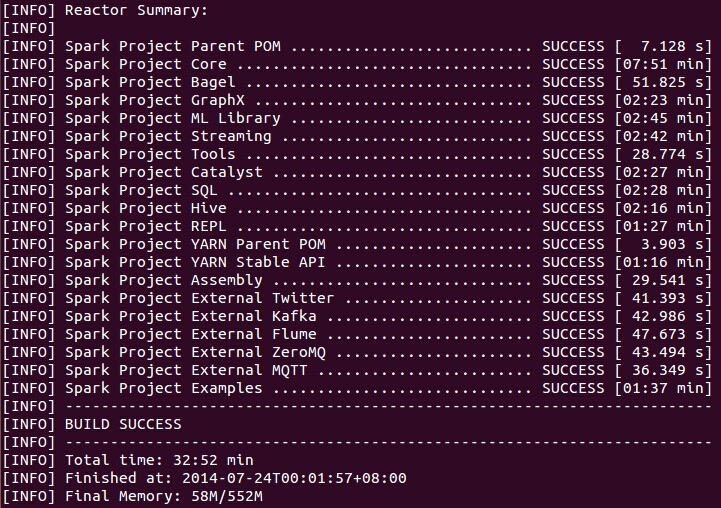
tar -zxvf spark-1.0.0.tar.gz
cd spark-1.0.1
SPARK_HADOOP_VERSION=2.2.0 SPARK_YARN=true ./sbt/sbt assembly
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
[INFO] Compiling 203 Scala sources and 9 Java sources to /Users/me/Development/spark/core/target/scala-2.10/classes... [ERROR] PermGen space -> [Help 1] [INFO] Compiling 203 Scala sources and 9 Java sources to /Users/me/Development/spark/core/target/scala-2.10/classes... [ERROR] Java heap space -> [Help 1]
2)指定Hadoop版本并编译
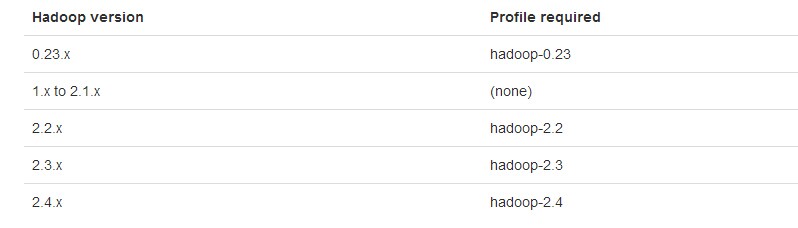
# Apache Hadoop 2.2.X
mvn -Pyarn -Phadoop-2.2 -Dhadoop.version=2.2.0 -DskipTests clean package
如果是其他版本的YARN和HDFS,则按下面编译:
# Different versions of HDFS and YARN.
mvn -Pyarn-alpha -Phadoop-2.3 -Dhadoop.version=2.3.0 -Dyarn.version=0.23.7 -DskipTests clean package
)
编译结果为:
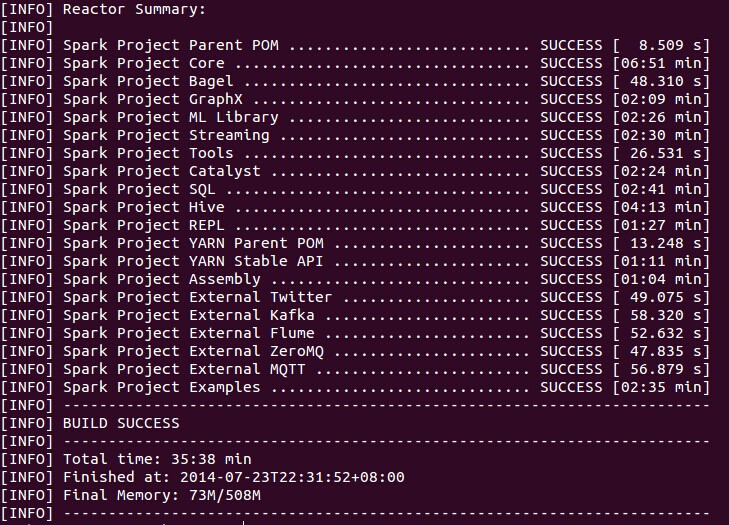
另外,这篇文章的编译讲得也很详细,也可以参考:http://mmicky.blog.163.com/blog/static/1502901542014312101657612/
以及文章 http://www.cnblogs.com/hseagle/p/3732492.html
Spark源码和编译后的源码、部署包我分享在: http://pan.baidu.com/s/1c0y7JKs 提取密码: ccvy

 浙公网安备 33010602011771号
浙公网安备 33010602011771号