Go-Mutex(互斥锁)解读
互斥锁是并发程序中对共享资源进行访问控制的主要手段,Go提供了Mutex(互斥锁)结构体类型
并且使用简单:对外暴露两个方法 Lock() 和 Unlock() 分别用于加锁和解锁
1.Mutex使用
开启10个Goroutine来计算count的结果
package main import ( "fmt" "sync" ) // 开启10个协程 计算10个(1+2+3+...+10 = 55) 综合count 应该是550 var syncMut sync.Mutex var wg sync.WaitGroup func main() { wg.Add(10) count := 0 for i := 0; i < 10; i++ { fmt.Println("i==", i) go func() { defer wg.Done() for j := 1; j <= 10; j++ { syncMut.Lock() count += j syncMut.Unlock() } }() } wg.Wait() fmt.Println(count) /* i== 0 i== 1 i== 2 i== 3 i== 4 i== 5 i== 6 i== 7 i== 8 i== 9 550 */ }
sync.Mutex匿名嵌入到结构体
可以使用匿名嵌入字段的方式,将 sync.Mutex 直接嵌入到 Counter 结构体中,然后在需要进行并发控制的方法中使用 Lock() 和 Unlock() 方法进行锁操作。这样可以使代码更加简洁,同时也可以保证并发安全。这个方法的代码示例如下:
type Counter struct { sync.Mutex count uint64 } func (c *Counter) Incr() { c.Lock() c.count++ c.Unlock() } func (c *Counter) Count() uint64 { c.Lock() defer c.Unlock() return c.count }
sync.Mutex命名进行调用
(推荐使用上面匿名方式)
type Counter struct { mu sync.Mutex count uint64 } func (c *Counter) Incr() { c.mu.Lock() c.count++ c.mu.Unlock() } func (c *Counter) Count() uint64 { c.mu.Lock() defer c.mu.Unlock() return c.count }
2.Mutex源码解读
Mutex设计核心是通过「位压缩状态」+「双模式切换」平衡性能与公平性
核心逻辑:“快速路径→自旋→阻塞→唤醒”
关键字段
-
Mutex的核心是state字段(状态标记)和sema字段(信号量,用于阻塞 / 唤醒 goroutine)
-
state字段的位压缩设计
type Mutex struct { state int32 // 锁的核心状态(32位整数,不同位段表示不同含义) sema uint32 // 信号量,用于 goroutine 的阻塞/唤醒(依赖 runtime 调度) }
state 是一个 32 位整数,不同位段表示不同状态,从低到高依次为:
-
第 0 位(
mutexLocked):锁定标记(1 = 被锁定,0 = 未锁定)。 -
第 1 位(
mutexWoken):唤醒标记(1 = 有等待者已被唤醒,避免重复唤醒)。 -
第 2 位(
mutexStarving):饥饿模式标记(1 = 处于饥饿模式,0 = 正常模式)。 -
第 3~31 位:等待队列长度(记录阻塞在该锁上的 goroutine 数量)。
const ( mutexLocked = 1 << iota // 0b0001(锁定位) mutexWoken // 0b0010(唤醒位) mutexStarving // 0b0100(饥饿位) mutexWaiterShift = iota // 3(等待者数量的位移,即从第3位开始) )
我们看到Mutex.state是32位的整型变量,内部实现时把该变量分成四份,用于记录Mutex的四种状态。
下图展示Mutex的内存布局:
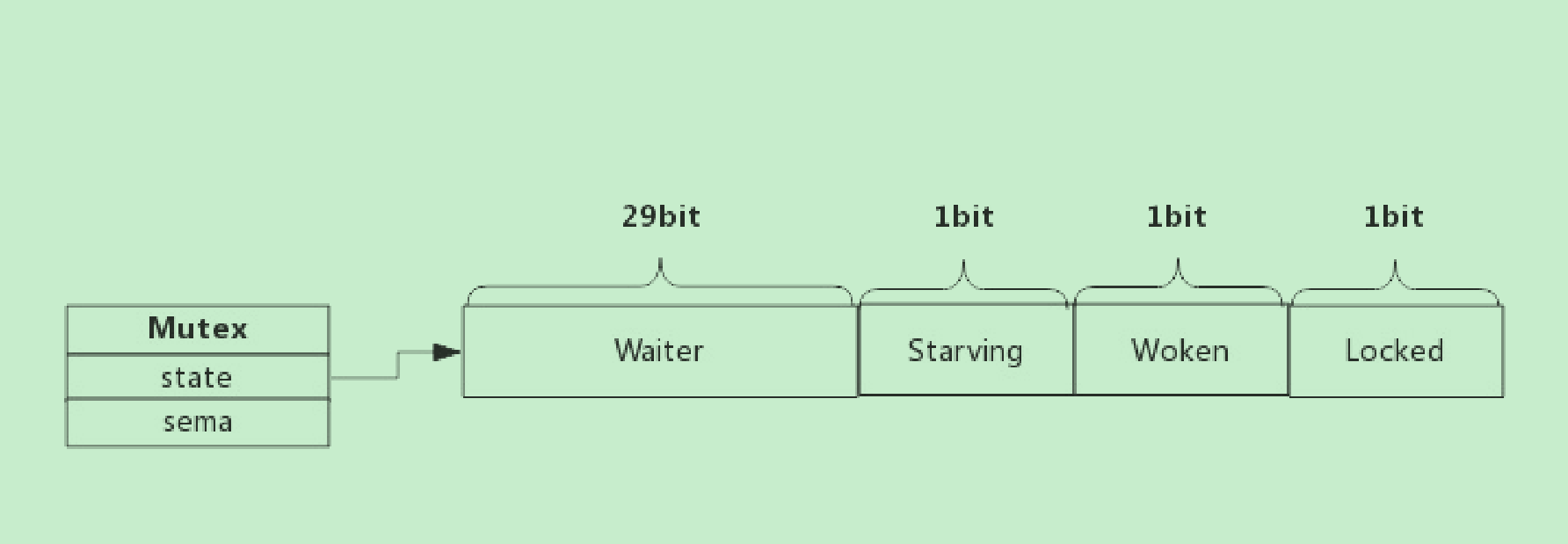
-
Locked: 表示该Mutex是否已被锁定,0:没有锁定 1:已被锁定。
-
Woken: 表示是否有协程已被唤醒,0:没有协程唤醒 1:已有协程唤醒,正在加锁过程中。
-
Starving:表示该Mutex是否处理饥饿状态, 0:没有饥饿 1:饥饿状态,说明有协程阻塞了超过1ms。
-
Waiter: 表示阻塞等待锁的协程个数,协程解锁时根据此值来判断是否需要释放信号量。
协程之间抢锁实际上是抢给Locked赋值的权利,能给Locked域置1,就说明抢锁成功。抢不到的话就阻塞等待 Mutex.sema信号量,一旦持有锁的协程解锁,等待的协程会依次被唤醒。 Woken和Starving主要用于控制协程间的抢锁过程
加锁 / 解锁的核心流程
每个 Goroutine(G)加锁 / 解锁的核心流程
-
快速尝试:先通过 CAS 抢锁(无竞争时直接成功,最高效);
-
自旋探测:抢不到锁时,先自旋 4 次(短期等待,避免频繁阻塞),期间持续探测
locked位是否为 0; -
阻塞排队:自旋后仍抢不到(
locked还是 1),就进入等待队列,让出 CPU; -
释放唤醒:持有锁的 G 解锁时,会更新锁状态(把
locked设为 0),并唤醒等待队列里的 G,让它再尝试抢锁。
-
加锁分「快速路径」(无竞争,低开销)和「慢速路径」(有竞争,复杂处理)
-
整体是「CAS 尝试 → 自旋优化 → 阻塞等待 → 唤醒获取」的流程
直接通过 CAS 尝试获取锁,成功则立即返回(仅 1 次 CAS 操作,开销极小):
func (m *Mutex) Lock() { // 尝试通过CAS直接获取锁:如果state为0(未锁定),则设置锁定位为1 if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) { return // 成功获取锁,直接返回 } // 有竞争,进入慢速路径 m.lockSlow() }
假定当前只有一个协程在加锁,没有其他协程干扰,那么过程如下图所示:

加锁过程会去判断Locked标志位是否为0,如果是0则把Locked位置1,代表加锁成功。从上图可见,加锁成功后, 只是Locked位置1,其他状态位没发生变化。
2.1自旋优化(正常模式专属)
自旋条件(缺一不可,避免浪费 CPU):
-
锁处于「正常模式」(非饥饿)且已被锁定(
old&(mutexLocked|mutexStarving) == mutexLocked); -
CPU 核心数 > 1(单核心自旋无意义,只会浪费时间);
-
自旋次数较少(默认最多 4 次,避免长期空转)。
自旋目的:短期持有锁的场景下,通过空循环等待锁释放,避免「阻塞 - 唤醒」的高开销(阻塞需切换内核态,成本比自旋高)。
2.2计算新状态(状态变更逻辑)
根据当前状态(old)计算要更新的新状态(new):
-
非饥饿模式:尝试设置「锁定位」(
new |= mutexLocked),争取获取锁; -
有竞争(锁被占 / 饥饿模式):增加「等待者数量」(
new += 1 << mutexWaiterShift); -
当前 goroutine 等待超 1ms:标记「饥饿位」(
new |= mutexStarving),触发公平模式。
2.3CAS 更新状态 + 阻塞等待
通过 CAS 原子更新 state:
-
若 CAS 成功:若锁空闲则直接获取;否则通过
runtime_SemacquireMutex(&m.sema)阻塞(加入等待队列,释放 CPU)。 -
若 CAS 失败:重新读取
state,循环重试。
2.4唤醒后处理(饥饿模式专属)
被唤醒后,若处于「饥饿模式」:
-
锁直接传递给当前 goroutine(无需 CAS,保证公平性,避免新 goroutine 插队);
-
若当前是最后一个等待者:清除「饥饿位」,切回正常模式。
当快速路径失败(锁已被占用或有竞争),会进入 lockSlow(),处理以下场景:
-
锁被其他 goroutine 持有(正常模式或饥饿模式)。
-
等待队列中有其他 goroutine 在排队。
func (m *Mutex) lockSlow() { var waitStartTime int64 // 记录等待开始时间(用于判断是否进入饥饿模式) starving := false // 当前goroutine是否处于饥饿状态 awoke := false // 当前goroutine是否被唤醒 iter := 0 // 自旋次数(正常模式下尝试自旋获取锁) old := m.state // 记录当前锁状态 for { // 情况1:锁处于正常模式(非饥饿)且被锁定,尝试自旋(spin)获取锁 // 自旋条件:CPU核心数>1、当前自旋次数较少(避免浪费CPU)、有其他线程在运行 if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) { // 尝试设置唤醒位(避免被Unlock唤醒其他等待者) if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 && atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) { awoke = true } runtime_doSpin() // 执行自旋(空循环,消耗CPU时间片) iter++ old = m.state // 重新读取状态 continue } // 情况2:处理锁状态(计算新状态) new := old // 非饥饿模式下,尝试获取锁(设置锁定位) if old&mutexStarving == 0 { new |= mutexLocked } // 如果锁已被锁定或处于饥饿模式,增加等待者数量 if old&(mutexLocked|mutexStarving) != 0 { new += 1 << mutexWaiterShift } // 情况3:当前goroutine处于饥饿状态,且锁被锁定,则将锁标记为饥饿模式 if starving && old&mutexLocked != 0 { new |= mutexStarving } // 情况4:如果当前goroutine已被唤醒,清除唤醒位 if awoke { if new&mutexWoken != 0 { panic("sync: inconsistent mutex state") } new &^= mutexWoken // 清除唤醒位 } // 通过CAS更新状态,如果成功则跳出循环 if atomic.CompareAndSwapInt32(&m.state, old, new) { // 锁未被占用且非饥饿模式,成功获取锁 if old&(mutexLocked|mutexStarving) == 0 { break } // 处理等待逻辑(之前已在等待队列,现在重新排队) queueLifo := waitStartTime != 0 if waitStartTime == 0 { waitStartTime = runtime_nanotime() } // 阻塞等待信号量(通过sema等待,进入等待队列) runtime_SemacquireMutex(&m.sema, queueLifo, 1) // 被唤醒后,检查是否需要进入饥饿模式(等待超过1ms) starving = starving || runtime_nanotime()-waitStartTime > 1e6 old = m.state // 如果锁处于饥饿模式,直接获取锁(无需CAS,饥饿模式下锁直接传递) if old&mutexStarving != 0 { if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 { panic("sync: inconsistent mutex state") } // 减少等待者数量并获取锁 delta := int32(mutexLocked - 1<<mutexWaiterShift) if !starving || old>>mutexWaiterShift == 1 { delta -= mutexStarving // 最后一个等待者,退出饥饿模式 } atomic.AddInt32(&m.state, delta) break } awoke = true iter = 0 } else { old = m.state // CAS失败,重新读取状态 } } }
核心逻辑要点
-
自旋优化:正常模式下,锁被短暂持有时,当前 goroutine 会自旋几次(空循环),避免立即阻塞(阻塞 / 唤醒开销比自旋大)。
-
饥饿模式:当一个 goroutine 等待锁超过 1ms,会触发饥饿模式,此时锁会直接传递给等待时间最长的 goroutine,避免被新到来的 goroutine “插队”(解决公平性问题)。
-
等待队列:通过
sema信号量管理等待的 goroutine,runtime_SemacquireMutex会将 goroutine 加入等待队列并阻塞。
假定加锁时,锁已被其他协程占用了,此时加锁过程如下图所示:
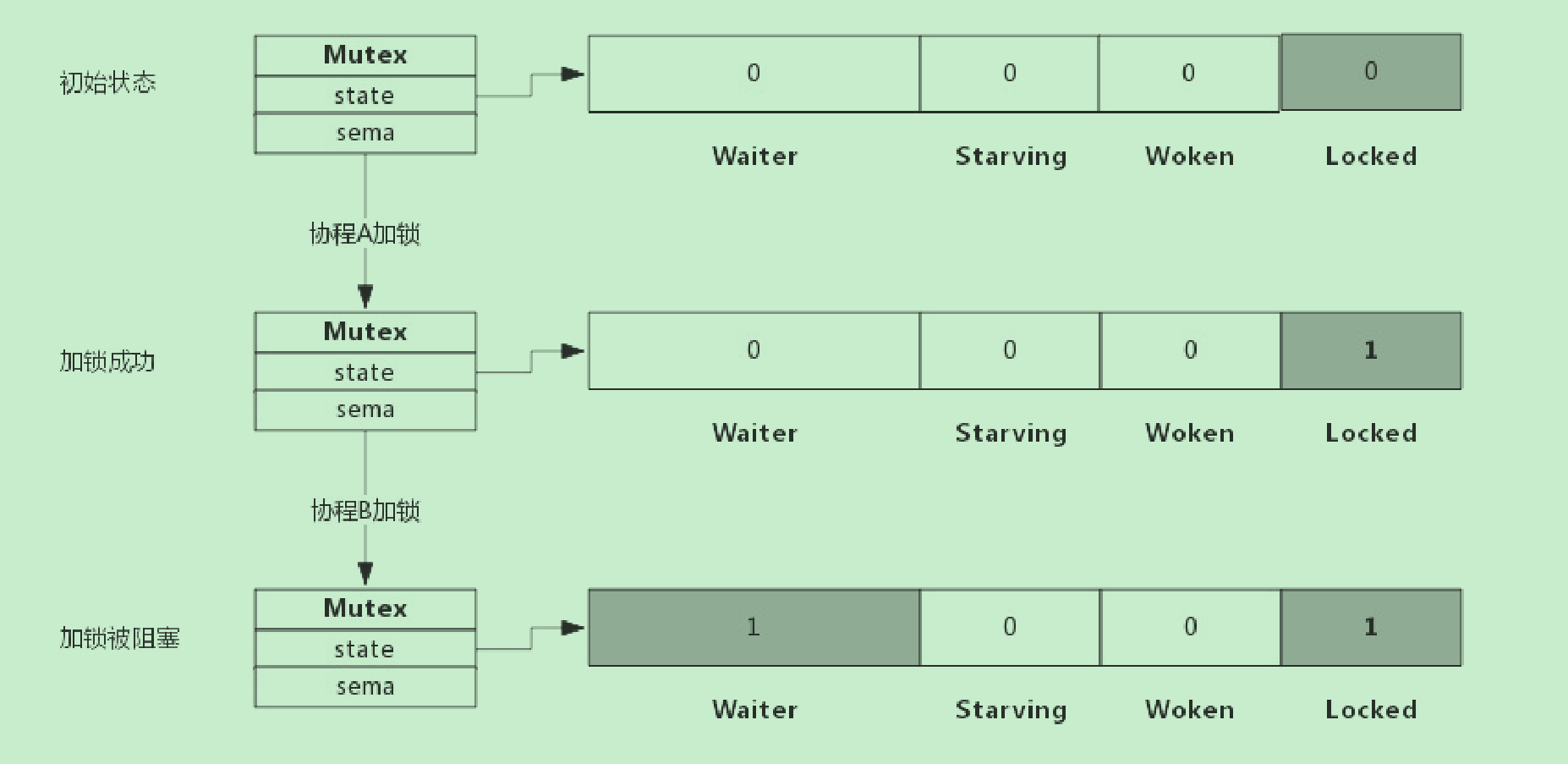
从上图可看到,当协程B对一个已被占用的锁再次加锁时,Waiter计数器增加了1,此时协程B将被阻塞,直到 Locked值变为0后才会被唤醒。
4.解锁流程(Unlock()方法)
-
Unlock()负责释放锁,并根据状态唤醒等待的 goroutine -
解锁分「快速路径」(无等待者)和「慢速路径」(有等待者),核心是「释放锁 + 唤醒等待者」
直接原子清除「锁定位」,若结果为 0(无等待者、无其他状态),则解锁完成:
func (m *Mutex) Unlock() { // 快速释放锁:清除锁定位 new := atomic.AddInt32(&m.state, -mutexLocked) if new != 0 { // 有等待者或状态异常,进入慢速路径 m.unlockSlow(new) } }
假定解锁时,没有其他协程阻塞,此时解锁过程如下图所示:
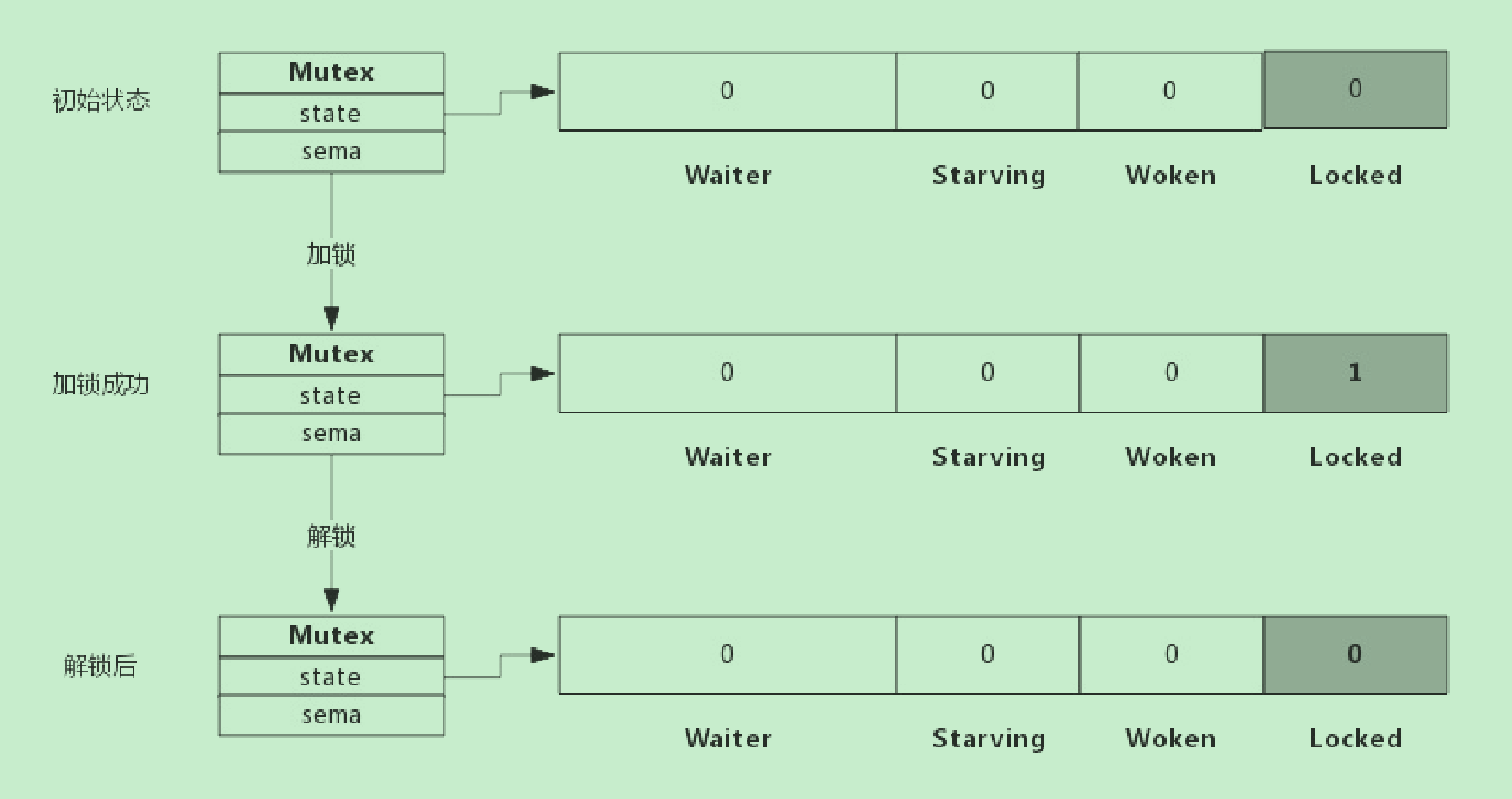
由于没有其他协程阻塞等待加锁,所以此时解锁时只需要把Locked位置为0即可,不需要释放信号量。
2.1 重复解锁检查(容错)
若解锁一个未锁定的锁((new+mutexLocked)&mutexLocked == 0),直接 panic(避免错误使用)。
2.2 分模式唤醒等待者
-
正常模式:优先性能,唤醒一个等待者(减少等待者数量,设置「唤醒位」避免重复唤醒),调用
runtime_Semrelease(&m.sema)唤醒; -
饥饿模式:优先公平,直接唤醒等待队列的第一个 goroutine(锁所有权直接传递,不允许新 goroutine 插队,解决「等待者饿死」问题)。
当释放锁后仍有等待者或状态异常时,进入 unlockSlow() 处理:
func (m *Mutex) unlockSlow(new int32) { if (new+mutexLocked)&mutexLocked == 0 { panic("sync: unlock of unlocked mutex") // 重复解锁,触发panic } if new&mutexStarving == 0 { // 正常模式 old := new for { // 无等待者,直接返回 if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 { return } // 唤醒一个等待者(减少等待者数量,设置唤醒位) new := (old - 1<<mutexWaiterShift) | mutexWoken if atomic.CompareAndSwapInt32(&m.state, old, new) { runtime_Semrelease(&m.sema, false, 1) // 唤醒等待的goroutine return } old = m.state } } else { // 饥饿模式 // 直接唤醒等待队列的第一个goroutine(锁所有权直接传递) runtime_Semrelease(&m.sema, true, 1) } }
核心逻辑要点
-
正常模式:释放锁后,若有等待者,唤醒其中一个(通过
runtime_Semrelease),并设置唤醒位避免重复唤醒。 -
饥饿模式:锁直接传递给等待队列的第一个 goroutine(不允许新 goroutine 插队),确保公平性。
-
重复解锁检查:通过状态校验,若解锁一个未锁定的锁,直接 panic(避免错误使用)。
假定解锁时,有1个或多个协程阻塞,此时解锁过程如下图所示:
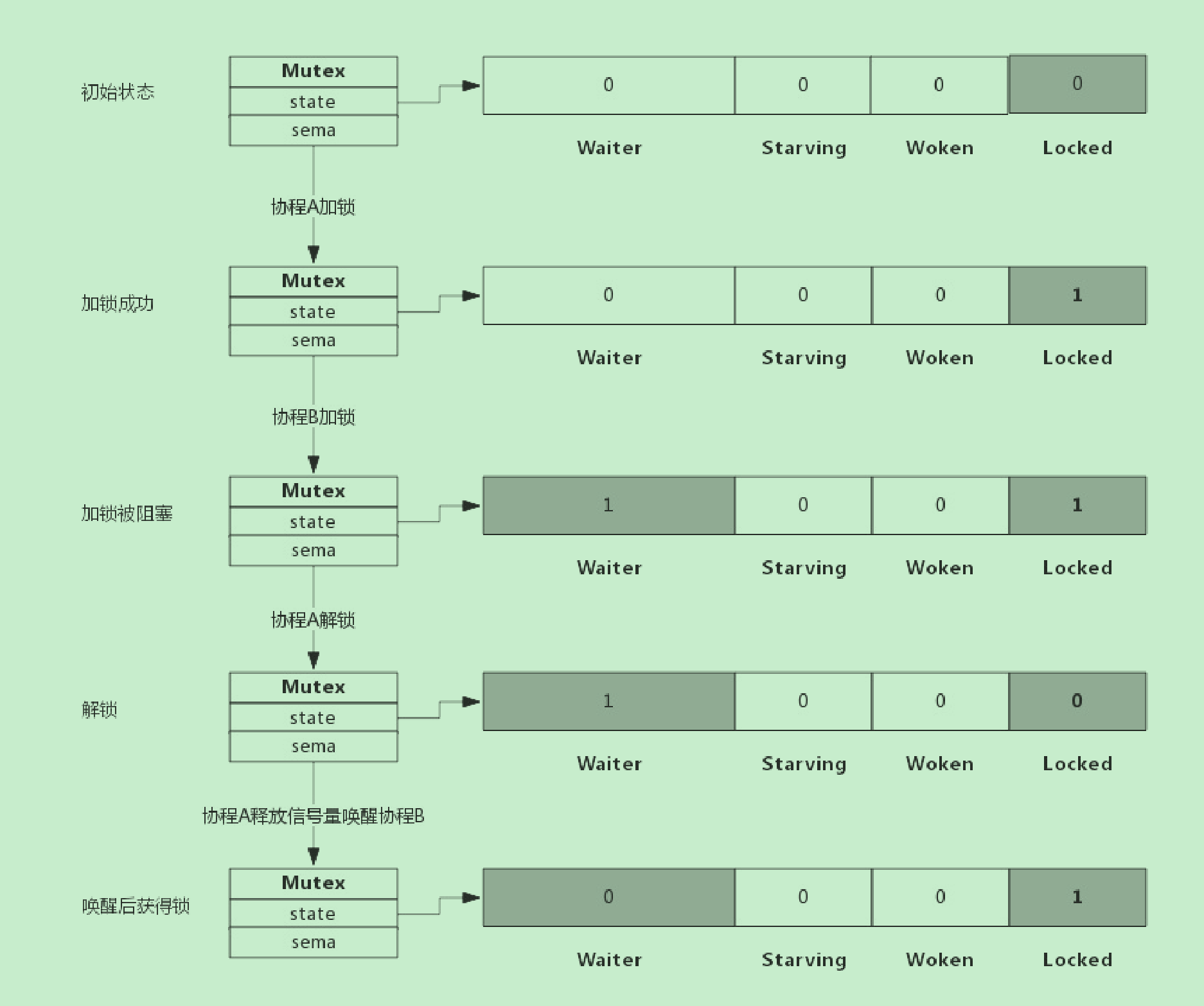
协程A解锁过程分为两个步骤,一是把Locked位置0,二是查看到Waiter>0,所以释放一个信号量,唤醒一个阻塞的 协程,被唤醒的协程B把Locked位置1,于是协程B获得锁。
5.CAS
CAS 是 Compare And Swap(比较并交换) 的缩写,是 CPU 提供的原子操作指令,也是实现无锁编程(如 Go 的
atomic包、sync.Mutex)的核心技术。
核心价值
-
无锁安全:无需加互斥锁,就能保证多 Goroutine 操作共享变量的线程安全(避免锁的开销);
-
轻量高效:是 CPU 级指令,操作开销远小于 Goroutine 阻塞 / 唤醒(这也是 Mutex 自旋优化的基础)。
核心原理(3 步原子执行)
CAS 操作针对一个「内存地址」,需传入 3 个参数:
-
旧值(Old Value):预期内存地址中当前存储的值;
-
新值(New Value):若内存值与旧值一致,要写入的新值;
-
内存地址(Addr):要操作的目标内存位置。
执行逻辑(原子不可打断):
-
读取
Addr地址中的「当前值」; -
比较「当前值」与「旧值」是否相等;
-
若相等:将「新值」写入
Addr,返回true(操作成功);若不相等:不做任何修改,返回false(操作失败)。
举个实际例子(结合 Go Mutex)
在 sync.Mutex 加锁的「快速尝试」步骤中,就用到了 CAS:
-
Mutex 用一个
int32存储状态(低 1 位是locked标志,0 = 未锁,1 = 已锁); -
加锁时,先读取该
int32的「当前值」(假设为 0,即未锁); -
执行 CAS:旧值 = 0,新值 = 1,目标地址是状态变量的内存地址;
-
若 CAS 成功(返回
true):说明没人抢锁,直接加锁成功; -
若 CAS 失败(返回
false):说明锁已被持有,进入后续自旋 / 排队逻辑。
-
什么是 ABA:内存值先从 A 变成 B,再变回 A。CAS 比较时会认为「值没变化」,但实际中间发生过修改(可能引发逻辑错误,如链表节点复用场景)。
-
解决方案:用「值 + 版本号」组合代替纯值(如
atomic.Value内部逻辑),CAS 时同时比较「值 + 版本号」,版本号每次修改都递增,避免误判。
局限性
-
只能操作单个变量(无法原子操作多个变量,需用其他方案如
sync.Mutex); -
可能出现「自旋循环」(如 CAS 一直失败,会反复尝试,消耗 CPU;需设置合理重试次数或退出逻辑)。
自旋过程
加锁时,如果当前Locked位为1,说明该锁当前由其他协程持有,尝试加锁的协程并不是马上转入阻塞,而是会持续 的探测Locked位是否变为0,这个过程即为自旋过程。 自旋时间很短,但如果在自旋过程中发现锁已被释放,那么协程可以立即获取锁。此时即便有协程被唤醒也无法获取 锁,只能再次阻塞。 自旋的好处是,当加锁失败时不必立即转入阻塞,有一定机会获取到锁,这样可以避免协程的切换。
什么是自旋
自旋对应于CPU的”PAUSE”指令,CPU对该指令什么都不做,相当于CPU空转,对程序而言相当于sleep了一小段时 间,时间非常短,当前实现是30个时钟周期。 自旋过程中会持续探测Locked是否变为0,连续两次探测间隔就是执行这些PAUSE指令,它不同于sleep,不需要将 协程转为睡眠状态。
Go 中控制自旋次数上限的逻辑在 runtime/proc.go 源码中,通过 active_spin 常量定义了默认最大自旋次数为 4 次。以下是具体位置和代码解析:
1. 源码位置(以 Go 1.25 为例)
-
文件路径:
src/runtime/proc.go -
核心常量与函数:
active_spin(自旋次数上限)和runtime_canSpin(判断是否允许自旋)。
// src/runtime/proc.go // 最大主动自旋次数(默认 4 次) const active_spin = 4 // 表示每次自旋时,执行的循环迭代次数 const active_spin_cnt = 30 // runtime_canSpin 决定当前是否可以进行自旋 // iter:当前已自旋的次数 func runtime_canSpin(iter int) bool { // 条件 1:自旋次数未超过上限(iter < active_spin → 最多 4 次) // 条件 2:CPU 核心数 > 1(单核心自旋无意义) // 条件 3:当前 P 的本地队列有其他 G 在运行(避免独占 CPU) // 条件 4:当前机器处于多线程模式(非单线程) return iter < active_spin && runtime_ncpu() > 1 && gomaxprocs > 1 && sched.nmspinning.Load() < uint32(gomaxprocs-1) && atomic.Load(&sched.npidle) == 0 }
-
active_spin = 4
表示sync.Mutex在尝试获取锁而失败后,最多允许的自旋次数。当 goroutine 尝试加锁但锁已被占用时,会先进行自旋(而非立即阻塞),每次自旋后重新检查锁状态。如果自旋次数达到active_spin(即 4 次)仍未能获得锁,则进入阻塞等待。 -
active_spin_cnt = 30
表示每次自旋时,执行的循环迭代次数。sync_runtime_doSpin会调用汇编函数procyield(active_spin_cnt),该函数执行active_spin_cnt次PAUSE指令(或等效的空循环),让 CPU 核心在此期间保持忙等待,同时降低功耗和避免流水线冲突。这样可以在锁被短暂持有时,避免昂贵的线程上下文切换和调度开销。
为什么是 4 次?
7.关键设计点
-
-
正常模式:优先性能,允许新 goroutine 自旋插队(短期锁场景高效);
-
饥饿模式:等待超 1ms 触发,优先公平,锁直接传递给等待最久的 goroutine(避免饿死);
-
平衡了「高并发性能」和「长期等待公平性」。
-
-
快速路径优化 无竞争场景下,加锁 / 解锁仅需 1-2 次 CAS 操作(用户态操作,无内核态切换),开销极低。
-
自旋 + 阻塞结合 短期锁用自旋减少阻塞开销,长期锁用阻塞避免 CPU 空转,兼顾效率与资源利用率。
-
位压缩状态 用 1 个 32 位整数存储「锁状态 + 唤醒标记 + 饥饿标记 + 等待者数量」,减少内存占用(Mutex 仅 8 字节),提升缓存命中率。
8.注意点
-
Mutex 为什么设计双模式? 正常模式优先性能(允许插队),饥饿模式优先公平(避免等待者饿死),平衡不同场景需求。
-
自旋的条件是什么?为什么要自旋? 条件:正常模式、锁被持有、CPU>1、自旋次数少;目的:避免短期锁的「阻塞 - 唤醒」高开销。
-
如何判断 Mutex 被重复解锁? 解锁时原子减
mutexLocked后,若(new+mutexLocked)&mutexLocked == 0(说明锁原本就未锁定),触发 panic。 -
饥饿模式的触发条件? goroutine 等待锁的时间超过 1ms,会标记「饥饿位」,切换到饥饿模式。
- 加锁后立即使用defer对其解锁,可以有效的避免死锁。
- 加锁和解锁最好出现在同一个层次的代码块中,比如同一个函数。 重复解锁会引起panic,应避免这种操作的可能性。
9.Mutex模式
前面分析加锁和解锁过程中只关注了Waiter和Locked位的变化,现在我们看一下Starving位的作用。 每个Mutex都有两个模式,称为Normal和Starving。下面分别说明这两个模式。
normal模式
默认情况下,Mutex的模式为normal。 该模式下,协程如果加锁不成功不会立即转入阻塞排队,而是判断是否满足自旋的条件,如果满足则会启动自旋过程,尝试抢锁。
starvation模式
自旋过程中能抢到锁,一定意味着同一时刻有协程释放了锁,我们知道释放锁时如果发现有阻塞等待的协程,还会释 放一个信号量来唤醒一个等待协程,被唤醒的协程得到CPU后开始运行,此时发现锁已被抢占了,自己只好再次阻塞, 不过阻塞前会判断自上次阻塞到本次阻塞经过了多长时间,如果超过1ms的话,会将Mutex标记为”饥饿”模式,然后 再阻塞。 处于饥饿模式下,不会启动自旋过程,也即一旦有协程释放了锁,那么一定会唤醒协程,被唤醒的协程将会成功获取 锁,同时也会把等待计数减1。
Woken状态
Woken状态用于加锁和解锁过程的通信,举个例子,同一时刻,两个协程一个在加锁,一个在解锁,在加锁的协程可 能在自旋过程中,此时把Woken标记为1,用于通知解锁协程不必释放信号量了,好比在说:你只管解锁好了,不必释 放信号量,我马上就拿到锁了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号